基于特征对齐域的SP-CTA图像冠脉分割方法及装置
基于特征对齐域的sp-cta图像冠脉分割方法及装置
技术领域
1.本发明涉及医用图像处理的技术领域,尤其涉及一种基于特征对齐域的sp-cta图像冠脉分割方法,以及基于特征对齐域的sp-cta图像冠脉分割装置。
背景技术:
2.ct检查在临床中应用十分广泛,ct以其扫描速度快,对骨头及钙化敏感而具有部分优势。cta是ct血管成像,是ct临床应用中一个非常重要的部分,由于血管及其背景软组织自然对比差,常规ct平扫往往难以显示血管。在行cta检查的时候,需要引入对比剂,改变血管与背景组织的影像对比,从而突显血管。cta广泛的应用在头颈部血管、心脏冠状动脉、肺动静脉、胸主动脉、腹主动脉、下肢动静脉中。
3.目前sp-cta图像冠脉分割面临的问题如下:
4.1.具有标注的sp-cta图像较少,缺少用于训练网络的数据集,若直接使用sp-cta数据来训练网络,则可能会导致网络难以收敛,模型的鲁棒性以及学习的特征有效性也会受限;2.相较于一般的cta图像,sp-cta图像伪影较为严重,血管结构较为模糊,手工标注分割图像较困难;3.一般sp-cta都会有与之配对的cta数据,但由于成像设备及成像方式的差异,导致cta与sp-cta两者之间的物理信息基本不同(包括图像层数、空间spacing、origin、图像灰度分布等与分割任务相关的信息),因此若想使用特征对齐的方法将源域cta图像的特征与sp-cta共享,则必须先对图像进行预处理,尽量使二者物理信息匹配。
技术实现要素:
5.为克服现有技术的缺陷,本发明要解决的技术问题是提供了一种基于特征对齐域的sp-cta图像冠脉分割方法,其能够对未标记的目标域数据给出更可靠的预测,进而减小域分布差异。
6.本发明的技术方案是:这种基于特征对齐域的sp-cta图像冠脉分割方法,其包括以下步骤:
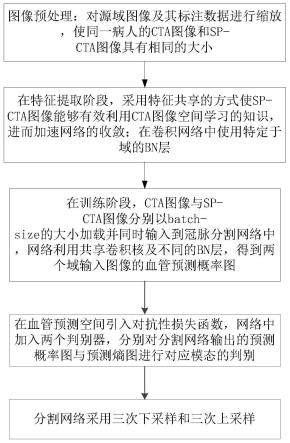
7.(1)图像预处理:对源域图像及其标注数据进行缩放,使同一病人的cta图像和sp-cta图像具有相同的大小;
8.(2)在特征提取阶段,采用特征共享的方式使sp-cta图像能够有效利用cta图像空间学习的知识,进而加速网络的收敛;在卷积网络中使用特定于域的bn层;
9.(3)在训练阶段,cta图像与sp-cta图像分别以batch-size的大小加载并同时输入到冠脉分割网络中,网络利用共享卷积核及不同的bn层,得到两个域输入图像的血管预测概率图;
10.(4)在血管预测空间引入对抗性损失函数,网络中加入两个判别器,分别对分割网络输出的预测概率图与预测熵图进行对应模态的判别;
11.(5)分割网络采用三次下采样和三次上采样;卷积块由两个卷积核大小为3
×3×
3的卷积层,bn层以及leakyrelu激活函数构成,卷积层的通道数分别设置为16,32,64,128,
提取特征后,利用最大池化进行下采样;上采样阶段采用3d反卷积操作,通过学习相关参数恢复与原始图像大小相同的特征图;为了恢复下采样丢失的部分信息,在解码阶段通过跳连接融合低维特征;在最后的预测阶段,采用两个不同的卷积操作以预测不同域的血管概率。
12.本发明网络的特征提取器参数是源域和目标域共享的,目的是提取与冠脉分割任务相关的域不变特征;由于源域和目标域的数据整体的灰度分布具有一定差异,特征提取器将利用特定于域的归一化层;由于源域数据具有标注信息,在训练过程中使用完全监督方式使网络学习冠脉血管分割相关的特征;由于目标域没有标注数据监督网络的学习,为了使网络更好的学习sp-cta图像的有效特征,采用对抗学习的方式实现,使网络对目标域数据的预测结果与对源域数据的预测结果特征分布相似;通过加入判别器监督两个域的预测结果分布相似,保证特征提取器学习的特征具有域不变性;由于源域数据相较于目标域数据的学习有最为直接的监督方式,网络将对cta图像中冠脉的预测有更高的置信度,对sp-cta的预测结果置信度较低,通过对齐两个域的预测结果的熵图使网络对未标记的目标域数据给出更可靠的预测,进而减小域分布差异。
13.还提供了基于特征对齐域的sp-cta图像冠脉分割装置,其包括:
14.图像预处理模块,其配置来对源域图像及其标注数据进行缩放,使同一病人的cta图像和sp-cta图像具有相同的大小;
15.特征提取模块,其配置来在特征提取阶段,采用特征共享的方式使sp-cta图像能够有效利用cta图像空间学习的知识,进而加速网络的收敛;在卷积网络中使用特定于域的bn层;
16.训练模块,其配置来在训练阶段,cta图像与sp-cta图像分别以batch-size的大小加载并同时输入到冠脉分割网络中,网络利用共享卷积核及不同的bn层,得到两个域输入图像的血管预测概率图;
17.损失引入模块,其配置来在血管预测空间引入对抗性损失函数,网络中加入两个判别器,分别对分割网络输出的预测概率图与预测熵图进行对应模态的判别;
18.分割网络模块,其配置来采用三次下采样和三次上采样;卷积块由两个卷积核大小为3
×3×
3的卷积层,bn层以及leakyrelu激活函数构成,卷积层的通道数分别设置为16,32,64,128,提取特征后,利用最大池化进行下采样;上采样阶段采用3d反卷积操作,通过学习相关参数恢复与原始图像大小相同的特征图;为了恢复下采样丢失的部分信息,在解码阶段通过跳连接融合低维特征;在最后的预测阶段,采用两个不同的卷积操作以预测不同域的血管概率。
附图说明
19.图1是根据本发明的基于特征对齐域的sp-cta图像冠脉分割方法的流程图。
具体实施方式
20.如图1所示,这种基于特征对齐域的sp-cta图像冠脉分割方法,其包括以下步骤:
21.(1)图像预处理:对源域图像及其标注数据进行缩放,使同一病人的cta图像和sp-cta图像具有相同的大小;
22.(2)在特征提取阶段,采用特征共享的方式使sp-cta图像能够有效利用cta图像空间学习的知识,进而加速网络的收敛;在卷积网络中使用特定于域的bn层;
23.(3)在训练阶段,cta图像与sp-cta图像分别以batch-size的大小加载并同时输入到冠脉分割网络中,网络利用共享卷积核及不同的bn层,得到两个域输入图像的血管预测概率图;
24.(4)在血管预测空间引入对抗性损失函数,网络中加入两个判别器,分别对分割网络输出的预测概率图与预测熵图进行对应模态的判别;
25.(5)分割网络采用三次下采样和三次上采样;卷积块由两个卷积核大小为3
×3×
3的卷积层,bn层以及leakyrelu激活函数构成,卷积层的通道数分别设置为16,32,64,128,提取特征后,利用最大池化进行下采样;上采样阶段采用3d反卷积操作,通过学习相关参数恢复与原始图像大小相同的特征图;为了恢复下采样丢失的部分信息,在解码阶段通过跳连接融合低维特征;在最后的预测阶段,采用两个不同的卷积操作以预测不同域的血管概率。
26.本发明网络的特征提取器参数是源域和目标域共享的,目的是提取与冠脉分割任务相关的域不变特征;由于源域和目标域的数据整体的灰度分布具有一定差异,特征提取器将利用特定于域的归一化层;由于源域数据具有标注信息,在训练过程中使用完全监督方式使网络学习冠脉血管分割相关的特征;由于目标域没有标注数据监督网络的学习,为了使网络更好的学习sp-cta图像的有效特征,采用对抗学习的方式实现,使网络对目标域数据的预测结果与对源域数据的预测结果特征分布相似;通过加入判别器监督两个域的预测结果分布相似,保证特征提取器学习的特征具有域不变性;由于源域数据相较于目标域数据的学习有最为直接的监督方式,网络将对cta图像中冠脉的预测有更高的置信度,对sp-cta的预测结果置信度较低,通过对齐两个域的预测结果的熵图使网络对未标记的目标域数据给出更可靠的预测,进而减小域分布差异。
27.优选地,所述步骤(1)中,通过调整图像z轴方向的spacing对图像进行插值操作实现重采样,插值操作首先根据目标图像和原图像的大小求出两张图像像素点的对应关系,坐标变换计算公式为:
[0028][0029]
其中,(x
src
,y
src
,z
src
)为原图像中某个像素点m的空间坐标,(x
dst
,y
dst
,z
dst
)为插值后的图像中与原图像点m对应像素点的坐标,w
src
,h
src
,l
src
为原图像的宽度,高度和长度,w
dst
,h
dst
,l
dst
为变换后图像的宽度,高度和长度;
[0030]
分割金标准使用最邻近插值采样方式,m(x,y)为原图像中第x行第y列的像素,假设重采样后的图像中的某一像素点通过公式(1)映射到原图的p点,由于p点的坐标值为小数,不同于最邻近插值法的四舍五入取整,通过计算p点与其邻近的四个已知像素值的点之间的距离,然后利用四个点的灰度值以距离为权重的方式叠加计算出p点的像素值,计算公
式表示为:
[0031]
p=u*v*src(x,y)+u*(1-v)*src(x+1,y)+(1-u)*v*src(x,y+1)+(1-u)*(1-v)*src(x+1,y+1)
ꢀꢀ
(2)。
[0032]
优选地,所述步骤(1)中,源域图像经过重采样后,对两个域的数据进行标准化操作,采用3d的卷积神经网络,采用沿着z轴剪切的方式,实验中切片的个数为8。
[0033]
优选地,所述步骤(3)中,假设在某一特定的层具有k个通道,其中某个特定通道的一个mini-batch的数据表示为β={x1,x2,x3,
…
,xm},首先通过公式(3)与(4)分别计算此通道数据的平均值和方差,然后根据平均值和方差并利用式(5)对所有数据进行标准化,最后对变换后的数据进行平移和缩放处理以恢复网络初始所要学习的特征分布,计算公式为式(6)所示
[0034][0035][0036][0037][0038]
采用全部训练数据的均值和方差,均值和方差计算公式如(7)和(8)
[0039]
所示,在训练阶段将利用移动平均法来获取全局统计量
[0040]
e[x]=e
β
[μb]
ꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(7)
[0041][0042]
在测试阶段经过bn层处理后的数据分布如式(9)所示
[0043][0044]
优选地,所述步骤(4)中,给定标注的源域冠脉cta数据集优选地,所述步骤(4)中,给定标注的源域冠脉cta数据集与无标注的目标域sp-cta数据集其中ns与n
t
分别表示源域和目标域的训练样本数量,两个域的图像经过分割网络后得到对应的血管预测概率图与其中c代表的是分割类别数,c=2,包含血管和背景两个类别;由于在源域空间具有标注信息,网络对cta图像的学习将采用有监督的方式,通过最小化混合损失监督网络学习cta图像中与冠脉相关的特征,分割损失的定义如式(10)所示
[0045]
[0046]
其中,混合损失的第一项为交叉熵损失,第二项为dice损失,
[0047]
优化分割网络整体的目标函数表示为
[0048][0049]
其中,λ1与λ2为超参数,平衡不同意义的优化网络的损失函数项。
[0050]
优选地,所述步骤(5)中,判别器d
p
与de均采用patchgan结构,通过5个卷积块将输入图像映射为n*n的矩阵,网络最后输出的每一个像素对应输入图像中感受野大小的patch,
[0051]
patchgan中3d卷积操作采用的卷积核的大小为4
×4×
4,前三层的卷积步长设置为2,后两层的卷积步长为1,特征图通道数分别为64,128,256,512,1;输入的图像的大小为512
×
512
×
8,整个网络的感受野为70
×
70
×
8;前四个卷积块由卷积层,instance normalization层和leakyrelu激活函数组成,instance normalization是指单张图片的单个通道进行归一化操作,leakyrelu激活函数是relu函数的改进版,两个函数的定义为
[0052]
relu(x)=max(0,x)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(20)
[0053][0054]
本领域普通技术人员可以理解,实现上述实施例方法中的全部或部分步骤是可以通过程序来指令相关的硬件来完成,所述的程序可以存储于一计算机可读取存储介质中,该程序在执行时,包括上述实施例方法的各步骤,而所述的存储介质可以是:rom/ram、磁碟、光盘、存储卡等。因此,与本发明的方法相对应的,本发明还同时包括一种基于特征对齐域的sp-cta图像冠脉分割装置。如图1所示,该装置包括:
[0055]
图像预处理模块,其配置来对源域图像及其标注数据进行缩放,使同一病人的cta图像和sp-cta图像具有相同的大小;
[0056]
特征提取模块,其配置来在特征提取阶段,采用特征共享的方式使sp-cta图像能够有效利用cta图像空间学习的知识,进而加速网络的收敛;在卷积网络中使用特定于域的bn层;
[0057]
训练模块,其配置来在训练阶段,cta图像与sp-cta图像分别以batch-size的大小加载并同时输入到冠脉分割网络中,网络利用共享卷积核及不同的bn层,得到两个域输入图像的血管预测概率图;
[0058]
损失引入模块,其配置来在血管预测空间引入对抗性损失函数,网络中加入两个判别器,分别对分割网络输出的预测概率图与预测熵图进行对应模态的判别;
[0059]
分割网络模块,其配置来采用三次下采样和三次上采样;卷积块由两个卷积核大小为3
×3×
3的卷积层,bn层以及leakyrelu激活函数构成,卷积层的通道数分别设置为16,32,64,128,提取特征后,利用最大池化进行下采样;上采样阶段采用3d反卷积操作,通过学习相关参数恢复与原始图像大小相同的特征图;为了恢复下采样丢失的部分信息,在解码阶段通过跳连接融合低维特征;在最后的预测阶段,采用两个不同的卷积操作以预测不同域的血管概率。
[0060]
优选地,所述图像预处理模块中,通过调整图像z轴方向的spacing对图像进行插值操作实现重采样,插值操作首先根据目标图像和原图像的大小求出两张图像像素点的对
应关系,坐标变换计算公式为:
[0061][0062]
其中,(x
src
,y
src
,z
src
)为原图像中某个像素点m的空间坐标,(x
dst
,y
dst
,z
dst
)为插值后的图像中与原图像点m对应像素点的坐标,w
src
,h
src
,l
src
为原图像的宽度,高度和长度,w
dst
,h
dst
,l
dst
为变换后图像的宽度,高度和长度;
[0063]
分割金标准使用最邻近插值采样方式,m(x,y)为原图像中第x行第y列的像素,假设重采样后的图像中的某一像素点通过公式(1)映射到原图的p点,由于p点的坐标值为小数,不同于最邻近插值法的四舍五入取整,通过计算p点与其邻近的四个已知像素值的点之间的距离,然后利用四个点的灰度值以距离为权重的方式叠加计算出p点的像素值,计算公式表示为:
[0064]
p=u*v*src(x,y)+u*(1-v)*src(x+1,y)+(1-u)*v*src(x,y+1)+(1-u)*(1-v)*src(x+1,y+1)
ꢀꢀꢀ
(2)。
[0065]
优选地,所述图像预处理模块中,源域图像经过重采样后,对两个域的数据进行标准化操作,采用3d的卷积神经网络,采用沿着z轴剪切的方式,实验中切片的个数为8。
[0066]
优选地,所述训练模块中,假设在某一特定的层具有k个通道,其中某个特定通道的一个mini-batch的数据表示为β={x1,x2,x3,
…
,xm},首先通过公式(3)与(4)分别计算此通道数据的平均值和方差,然后根据平均值和方差并利用式(5)对所有数据进行标准化,最后对变换后的数据进行平移和缩放处理以恢复网络初始所要学习的特征分布,计算公式为式(6)所示
[0067][0068][0069][0070][0071]
采用全部训练数据的均值和方差,均值和方差计算公式如(7)和(8)所示,在训练阶段将利用移动平均法来获取全局统计量
[0072]
e[x]=e
β
[μb]
ꢀꢀꢀꢀꢀꢀꢀꢀ
(7)
[0073]
[0074]
在测试阶段经过bn层处理后的数据分布如式(9)所示
[0075][0076]
以下更详细地说明本发明的具体实施例。
[0077]
本发明的方法包括如下步骤:
[0078]
1、图像预处理
[0079]
由于在临床上对病人冠脉结构狭窄情况的诊断一般会首先采用cta成像方式,当对因狭窄引起的血流变化分析时会进行心肌血流灌注成像,因此采集的cta和sp-cta图像往往是配对的。但由于成像设备及成像方式存在差异,cta和sp-cta图像的物理信息基本不同,其中包括与分割任务相关的图像spacing,图像层数等。由于两个域对应的同一病人的数据空间层数不同,单帧图像之间无法较好的配对。因此,首先对源域图像及其标注数据进行缩放,使同一病人的cta图像和sp-cta图像具有相同的大小。两个域图像的每个切片的大小是相同的,只有切片数量是不同的,本章通过调整图像z轴方向的spacing对图像进行插值操作实现重采样,插值操作首先根据目标图像和原图像的大小求出两张图像像素点的对应关系,具体的坐标变换计算公式如式(1)所示。
[0080][0081]
其中,(x
src
,y
src
,z
src
)为原图像中某个像素点m的空间坐标,(x
dst
,y
dst
,z
dst
)为插值后的图像中与原图像点m对应像素点的坐标。w
src
,h
src
,l
src
为原图像的宽度,高度和长度,w
dst
,h
dst
,l
dst
为变换后图像的宽度,高度和长度。然而通过公式映射的原图像坐标值往往是小数,而图像坐标均为正数,因此无法找到明确的对应点,不同的近似方式决定最终插值图像的不同。
[0082]
最简单的一种近似方式是将映射到原图的坐标值进行四舍五入近似,然后将近似后坐标的像素值映射到目标图像,称为最邻近插值法。由于原图像和目标图像的宽度和高度相同,只需在z轴方向插值,在边缘处将不存在灰度缓慢变化的区域,可能造成采样后的图像出现锯齿现象。然而对于二值图像,不需要灰度渐进变化,因此近插值的方法适合二值图像的重采样,本文分割金标准使用最邻近插值采样方式。
[0083]
最邻近插值法的近似方式对于灰度图像误差较大,线性插值方法是一种以距离为权重考虑多个像素点的插值方式,像素值映射更合理更准备,以二维空间为例描述具体的计算流程,m(x,y)为原图像中第x行第y列的像素。假设重采样后的图像中的某一像素点通过式(1)映射到原图的p点,由于p点的坐标值为小数,不同于最邻近插值法的四舍五入取整,通过计算p点与其邻近的四个已知像素值的点之间的距离,然后利用四个点的灰度值以距离为权重的方式叠加计算出p点的像素值。计算公式可表示为:
[0084]
p=u*v*src(x,y)+u*(1-v)*src(x+1,y)+(1-u)*v*src(x,y+1)+(1-u)*(1-v)*src(x+1,y+1)
ꢀꢀꢀ
(2)
[0085]
线性插值方式考虑了多个点的影响,并且遵循了距离越近的点影响越大的图像灰度分布规律,能够有效避免锯齿形状的出现,因此利用线性插值方式对原图像重采样。
[0086]
源域图像经过重采样后,对两个域的数据进行标准化操作,方式与上一章的图像预处理中的归一化方法相同。由于处理的图像是三维的,空间信息的学习非常重要,因此,本文采用3d的卷积神经网络。然而,3d图像的体积较大,受限于显存大小,网络的输入只能是原图像的patch,随机剪切的patch很有可能破坏血管本身的结构,血管的相对位置信息也可能被损坏。因此,本文采用沿着z轴剪切的方式,实验中切片的个数为8。
[0087]
2、特征共享与独立归一化
[0088]
由于在目标域空间没有标注信息,为了使网络能够有效提取图像中与冠脉结构相关的特征,将利用cta图像辅助sp-cta的学习。受限于标注图像的缺少,如果在目标域从头开始学习,那网络将会难以收敛,学习的特征有效性和鲁棒性也难以保证。更重要的是,cta图像和sp-cta图像具有非常多明显相似的特征结构,比如血管的结构,空间分布,背景结构等。因此,在特征提取阶段,采用特征共享的方式使sp-cta图像能够有效利用cta图像空间学习的知识,进而加速网络的收敛。利用特征共享还有一个非常重要的原因是共用特征提取器可以使网络提取与两个域均相关的域不变特性,能够提升网络的鲁棒性,并且还能够排除部分与分割任务非相关特征的学习。但由于源域图像与目标域图像的灰度分布存在差异,使用相同的bn层将会误导网络对特定空间数据分布的准备记忆,因此,在卷积网络中将使用特定于域的bn层。
[0089]
batch normalization已经在卷积神经网络领域被广泛应用,bn层通过使网络每层的数据分布一致进而加快网络的训练和收敛速度。除此之外,bn层的引入还能在一定程度上防止网络梯度爆炸和梯度消失,而且经实验验证还能够有效防止网络过拟合。bn层的归一化的主要方式是沿着输入数据的通道(channel)维度计算数据的均值和标准差进行白化预处理,然后引入可学习参数γ,β对标准化的特征进行仿射变换以还原本身的特征分布。假设在某一特定的层具有k个通道,其中某个特定通道的一个mini-batch的数据可以表示为β={x1,x2,x3,
…
,xm},首先通过公式(3)与(4)分别计算此通道数据的平均值和方差,然后根据平均值和方差并利用式(5)对所有数据进行标准化,最后对变换后的数据进行平移和缩放处理以恢复网络初始所要学习的特征分布,计算如式(6)所示。
[0090][0091][0092][0093][0094]
其中(5)式中的∈非常小,避免标准差为0时出现学习崩溃的情况。由于在测试阶段经常是对单一样本的预测,没有batch的概念,将采用全部训练数据的均值和方差,均值
和方差计算公式如(7)和(8)所示。因此,在训练阶段将利用移动平均法来获取全局统计量。
[0095]
e[x]=e
β
[μb]
ꢀꢀꢀꢀꢀꢀꢀꢀ
(7)
[0096][0097]
在测试阶段经过bn层处理后的数据分布如式(9)所示。
[0098][0099]
由于cta图像与sp-cta图像的数据分布存在差异,本文设计的网络对每个模态采用单独的bn层。如果使用相同的bn层,很有可能对两个域本身学习的特征产生明显的干扰,最终造成卷积层难以学习通用及鲁棒的特征。除此之外,在测试阶段bn层需要使用全部训练数据的平均值和方差,将两个域数据的均值和方差直接作用于目标域会造成数据分布偏移,导致网络分割性能退化。例如,如果在某一层输入的源域和目标域的数据分布满足μ
cta
=μ
sp-cta
,那两个域数据的整体平均值为0,在这种情况下bn层是无意义的。因此,采用特定于域的bn层可以有效的避免多模态学习中的此类问题。
[0100]
在训练阶段,cta图像与sp-cta图像分别以batch-size的大小加载并同时输入到冠脉分割网络中,网络利用共享卷积核及不同的bn层,最终得到两个域输入图像的血管预测概率图。
[0101]
3、基于概率与熵的对抗学习
[0102]
给定标注的源域冠脉cta数据集与无标注的目标域sp-cta数据集其中ns与n
t
分别表示源域和目标域的训练样本数量,两个域的图像经过分割网络后得到对应的血管预测概率图与其中c代表的是分割类别数,本章任务中c=2,包含血管和背景两个类别。由于在源域空间具有标注信息,网络对cta图像的学习将采用有监督的方式。通过最小化混合损失监督网络学习cta图像中与冠脉相关的特征,分割损失的定义如式(10)所示。
[0103][0104]
其中,混合损失的第一项为交叉熵损失,第二项为dice损失,两种损失的具体计算方式分别如式(11)和式(12)所示,两式中的表示源域训练样本的所有像素点的集合。dice损失在医学图像处理领域广泛应用,能有效解决类别不平衡的问题,但训练中可能会存在不稳定的现象,加入交叉熵损失能维持网络训练的稳定性,使预测图的熵较小。
[0105][0106]
[0107]
为了使分割网络提取域不变特征,本文利用基于对抗学习的方法实现源域与目标域的特征对齐。一般实现不同域之间的特征对齐最直接的方法是在特征空间利用对抗学习,使判别器无法区分提取的特征来自于哪个空间域。然而,高维的特征空间难以实现对齐。本章通过低维空间的对抗性学习增强特征分布的域不变性,具体来说,在血管预测空间引入对抗性损失函数。网络中加入两个判别器,分别对分割网络输出的预测概率图与预测熵图进行对应模态的判别。
[0108]
由于源域和目标域的图像中待分割的冠脉结构非常相似,源域因标注信息的监督结构提取结果较好,因此,当网络对目标域的预测图与源域相似度高时,证明网络对目标域的预测结果也较为理想。在本章任务中,引入判别器d
p
以区分概率图是对源域数据还是目标域数据的预测,分割网络与判别器在训练阶段是一种对抗关系,因而促使分割网络在目标域生成与源域预测结果相近的概率分布图。判别器的输出是二值化的,当预测输入的概率图来自于源域时输出为1,当预测为目标域时输出为0。通过最小化交叉熵损失优化判别器d
p
,损失函数如公式(13)所示。
[0109][0110]
基于对抗学习的网络生成器和判别器是分开训练的,当在训练分割网络时,目标域通过对抗损失影响网络的优化,对抗损失的计算如式(14)所示。
[0111][0112]
由于血管分割面临着严重的类别不平衡问题,基于预测概率图的对抗学习得到的结果可能会出现严重的过分割或欠分割,因为欠分割或者过分割的血管响应图与源域预测的结果特征分布也非常相似,可以通过提高网络预测的置信度在一定程度上解决此问题。由于源域具有标注图像的监督,网络对源域的预测结果置信度较高,因而概率图的熵较小,然而由于目标域没有直接的冠脉标注监督,网络对目标域的预测置信度较低,从而造成概率图的熵较大。因此,网络引入另一个判别器de对齐源域和目标域的预测熵图鼓励分割模型对未标记的目标域数据给出可靠的预测,进而减小域之间的分布差异,最终在目标域上取得良好的分割性能。源域和目标域的熵图基于预测概率图通过式(15)和式(16)计算得到。
[0113][0114][0115]
判别器de的训练目标函数同样采用交叉熵损失,通过最小化损失函数更新优化判别器,损失函数如式(17)所示。
[0116]
[0117]
当输入的熵图来自源域时,z=0,相反的,如果输入的是目标域的熵图,则z=1。
[0118]
在训练判别器de的同时,分割网络也会学习生成置信度相似的预测图来欺骗判别器。分割网络的对抗目标函数为
[0119][0120]
因此,通过上述的描述分析,优化分割网络整体的目标函数可以表示为
[0121][0122]
其中,λ1与λ2为超参数,平衡不同意义的优化网络的损失函数项。
[0123]
4、网络构建
[0124]
本文的网络结构主要由三部分组成:分割网络s,基于预测概率图的判别器d
p
与基于预测熵图的判别器de。为了更有效的处理三维图像,本章网络的计算均采用3d操作。分割网络采用3d unet框架,一个经典的编码器-解码器以及跳连接结构,编码器用来提取与目标任务相关的域不变特征,解码器用来对高维特征进行上采样恢复图像原始的分辨率,并最终得到图像的预测概率图。由于血管尺度变化大,血管末端及细小血管的半径较小,如果采用过多的下采样操作,在高维特征空间将去缺失小血管信息,在解码阶段也难以恢复。因此,分割网络采用三次下采样和三次上采样。卷积块由两个卷积核大小为3
×3×
3的卷积层,bn层以及leakyrelu激活函数构成,卷积层的通道数分别设置为16,32,64,128,提取特征后,利用最大池化进行下采样。上采样阶段采用3d反卷积操作,通过学习相关参数更好的恢复与原始图像大小相同的特征图。为了恢复下采样丢失的部分信息,在解码阶段通过跳连接融合低维特征。在最后的预测阶段,采用两个不同的卷积操作以预测不同域的血管概率。
[0125]
判别器d
p
与de均采用patchgan结构,通过5个卷积块将输入图像映射为n*n的矩阵,网络最后输出的每一个像素对应输入图像中感受野大小的patch。原始gan的判别器是对整个输入图像输出一个评价值,这种情况下网络更关注全局的相似性,将忽略图像的细节特征。相比之下,patchgan能够关注更丰富的局部区域,能够促使分割网络生成更准确的细节。由于血管像素点在图像空间占比较小,在整个图像中属于细节信息,patchgan结构的引入对血管概率图及其熵图的判别优化非常重要。
[0126]
patchgan中3d卷积操作采用的卷积核的大小为4
×4×
4,前三层的卷积步长设置为2,后两层的卷积步长为1,特征图通道数分别为64,128,256,512,1。输入的图像的大小为512
×
512
×
8,整个网络的感受野为70
×
70
×
8。前四个卷积块由卷积层,instance normalization层和leakyrelu激活函数组成,instance normalization是指单张图片的单个通道进行归一化操作,广泛应用于对抗生成网络中,这是由于网络关注的是生成的图像实例,不适合多张图片之间进行归一化操作。leakyrelu激活函数是relu函数的改进版,两个函数的定义如式(20)和式(21)所示。
[0127]
relu(x)=max(0,x)
ꢀꢀꢀꢀꢀꢀꢀ
(20)
[0128][0129]
relu函数在大于0的部分是线性的,计算速度较快,relu能够使一部分神经元的输
出为0,增强了网络的稀疏性,能在一定程度上避免过拟合。然而当网络的输出小于0时,神经元将永远不会被激活,leakyrelu的提出是专门解决此问题的,在负半区引入梯度a,patchgan中的a设置为0.2。
[0130]
以上所述,仅是本发明的较佳实施例,并非对本发明作任何形式上的限制,凡是依据本发明的技术实质对以上实施例所作的任何简单修改、等同变化与修饰,均仍属本发明技术方案的保护范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1