一种基于分散聚合流水线实现MDS阵列码的IP核架构的制作方法
一种基于分散聚合流水线实现mds阵列码的ip核架构
技术领域
1.本发明涉及计算机应用技术和网络编码领域,具体涉及一种基于分散聚合流水线实现mds阵列码的ip核架构。
背景技术:
2.随着社会的发展,存储系统的规模不断扩大,复杂性不断增加,这就导致数据的存储传送变得愈发困难。根据google公司的统计数据,在该公司的存储系统,平均每个mapreduce在操作过程中就有5个存储节点发生失效,由此,使用带有容错技术的存储系统已经成为必然。如今,mds编码技术普遍应用在分布式存储系统中。
3.目前,应用于分布式存储系统的传统mds纠删码主要有reed-solomon(rs)码和阵列码;rs码是现存唯一一种满足任意数据磁盘个数和冗余磁盘个数的mds码;但rs码需要在galois域gf(2w)上进行多项式运算,运算比较复杂。与之相比,阵列码编解码复杂度很低,且修复过程中下载的数据量和计算复杂度均低于rs码。为此有必要提出一种基于mds阵列码的纠删技术,并为其设计了硬件实现。
技术实现要素:
4.为了解决上述现有技术中存在的技术问题,本发明提供了一种基于分散聚合流水线实现mds阵列码的ip核架构,拟实现一种高效的纠删码,并实现丢失数据包的还原。
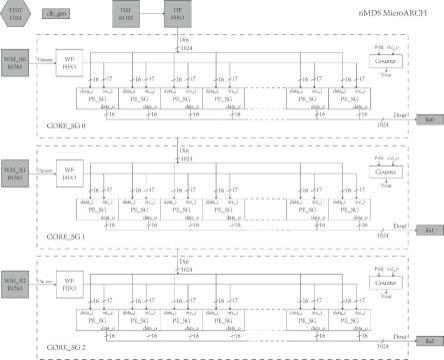
5.本发明采用的技术方案如下:一种基于分散聚合流水线实现mds阵列码的ip核架构,包括由weight fifo单元以及r个core_sg单元组成的编码ip核模块,所述core_sg单元由dw个pe_sg子单元组成;所述pe_sg子单元采用五级流水线的方式,依次进行补位运算、分散运算、聚集运算、销位运算以及累加运算;每个所述pe_sg子单元并行处理l bits的输入数据;所述core_sg单元中包括配置周期和编码周期,在配置周期core_sg单元存储上位软件下载的配置系数,并暂存在weight memory中;在编码周期core_sg单元先将weight memory循环导入weight fifo单元,再由weight fifo单元按先入先出扇出至pe_sg子单元进行编码,各pe_sg子单元将计算结果逐一传递到dout端口;所述编码ip核模块中设置有用于还原原始数据包的编译码算法结构。
6.本发明所述的一种基于分散聚合流水线实现mds阵列码的ip核架构中,各个单元由底层到顶层对原始数据包逐级处理,得到所需冗余包,得到的冗余包可在解码环节用来还原原始数据包;由r个core_sg单元所构成的编码ip核架构,每个core_sg单元可以通过配置不同的控制系数,对同一个输入数据并行计算,得到r个不同的冗余包。
7.本发明的core_sg单元集成了dw个pe_sg子单元并行计算,提升了编码核数据通路带宽,各pe_sg子单元分别处理l比特的输入数据。
8.并且本发明在求解冗余包r时,使用循环位移代替矩阵乘法;每个冗余包需要k个原始数据包参与计算,运算可分为k
×
r个部分进行;若数据包一次进行运算,在单个数据包的处理中,也存在以l个比特(l是循坏移位操作的数据位宽)为基本数据单元的多种并行性;对于l bits基本数据单元的多种循环移位和通过异或达到缩位聚集的效果,可以采用分散聚集流水线技术,根据控制系数分散得到移位结果,并通过异或进行缩位。算法串行部分是对 l bits基本数据单元的补位、循环右移、销位、异或操作,可采用流水线技术优化,重叠(overlapping)处理不同数据单元,提升计算吞吐率。
9.优选的,所述编译码结构如下:确定编码方式:基于给定的编码系数矩阵k
1j
,...,k
kj
对原始数据包m1,...,mk线性组合,生成冗余包rj:;式中:k表示原始数据包的个数,表示原始数据包m1,...,mk;表示编码系数矩阵k
1j
,...,k
kj
;确定译码方式:基于译码系数矩阵计算出丢失的原始数据包m1,...,mr,将剩余的k-r个已知原始数据包信息分别从校验包r1,...,rr中消除得到新的校验包,然后通过下式还原出原始数据包m1,...,mk: ;其中:m为新校验包所对应的编码系数矩阵。
10.优选的,所述core_sg单元中还设置有计数器子单元,用于记录输入数据包的个数,并初始化循环次数寄存器cycle_max。在所述core_sg单元中还设置计数器子单元记录输入数据包的个数,会派生出vout和trig信号。当vin信号无效时,编码流水线被插入空泡,不影响运算正确性;当vout无效时,dout输出全0。
11.优选的,所述补位运算根据接口输入的系数设定补位内容和补位位置,将输入的l bits扩增为l+1 bits;计算结果为padded并传给分散运算;所述分散运算根据控制系数src_i对l+1 bits分散进行l+1种移位操作,不同位的src_i表示不同的循环移位结果,并将结果输出给聚集运算;所述聚集运算对 l+1种分散计算结果执行异或,通过异或达到聚集效果,得到l+1bits运算结果并输出给销位运算;所述销位运算根据设定的销位方式和销位位置,将l+1 bits缩位到l bits;所述累加运算将属于同一冗余包的部分结果逐次累加。
12.本发明从底层到上层依次为:处理l bits 基本数据的pe_sg子单元、依次处理k个数据包得到单个冗余包的编码核core_sg单元;本发明集成了多个core_sg单元,针对单个输入数据流并行编码,得到r个冗余包的编码ip和rmds。pe_sg子单元采用五级流水线模式,包括补位运算、分散运算、聚集运算、销位运算以及累加运算;pe_sg子单元流水处理各数据包,随路处理无需存储,当某周期无输入数据时,流水线中允许存在空泡,不影响最终计算结果。
13.优选的,所述编码ip核模块连接有dm rom模块、df fifo模块以及test fsm模块。
14.本发明的有益效果包括:本发明在求解冗余包r时,使用循环位移代替矩阵乘法;每个冗余包需要k个原始数据包参与计算,运算可分为k
×
r 个部分进行;若数据包一次进行运算,在单个数据包的处理中,也存在以l个比特(l是循坏移位操作的数据位宽)为基本数据单元的多种并行性;对于l bits基本数据单元的多种循环移位和通过异或达到缩位聚集的效果,可以采用分散聚集流水线技术,根据控制系数分散得到移位结果,并通过异或进行缩位。算法串行部分是对 l bits基本数据单元的补位、循环右移、销位、异或操作,可采用流水线技术优化,重叠(overlapping)处理不同数据单元,提升计算吞吐率。
15.本发明所述的一种基于分散聚合流水线实现mds阵列码的ip核架构中,各个单元由地层到顶层对原始数据包逐级处理,得到所需冗余包,得到的冗余包可在解码环节用来还原原始数据包。
附图说明
16.图1为本发明中基于分散聚合编码ip的硬件微架构图。
17.图2为本发明中pe_sg五级流水线时序图。
18.图3为本发明中pe_sg子单元微架构图。
19.图4为本发明中功能正确性仿真性验证图。
20.图5为本发明中拨码开关与mode设置图。
21.图6为本发明中芯片版图。
22.图7为本发明中资源利用率概述图。
23.图8为本发明中按模块资源使用详细统计图。
24.图9为本发明中功耗估计图。
25.图10为本发明中硬件功能正确性波形验证图。
具体实施方式
26.为使本技术实施例的目的、技术方案和优点更加清楚,下面将结合本技术实施例中附图,对本技术实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅是本技术一部分实施例,而不是全部的实施例。通常在此处附图中描述和示出的本技术实施例的组件可以各种不同的配置来布置和设计。因此,以下对在附图中提供的本技术的实施例的详细描述并非旨在限制要求保护的本技术的范围,而是仅仅表示本技术的选定实施例。基于本技术的实施例,本领域技术人员在没有做出创造性劳动的前提下所获得的所有其他实施例,都属于本技术保护的范围。
27.下面结合附图1-10对本发明作进一步的详细说明:参见附图1到附图3,一种基于分散聚合流水线实现mds阵列码的ip核架构,包括由weight fifo单元以及r个core_sg单元组成的编码ip核模块,所述core_sg单元由dw个pe_sg子单元组成;所述pe_sg子单元采用五级流水线的方式,依次进行补位运算、分散运算、聚集运算、销位运算以及累加运算;每个所述pe_sg子单元并行处理l bits的输入数据;所述core_sg单元中包括配置周期和编码周期,在配置周期core_sg单元存储上位
软件下载的配置系数,并暂存在weightmemory中;在编码周期core_sg单元先将weightmemory循环导入weightfifo单元,再由weightfifo单元按先入先出扇出至pe_sg子单元进行编码,各pe_sg子单元将计算结果逐一传递到dout端口;所述编码ip核模块中设置有用于还原原始数据包的编译码算法结构。
28.所述编译码结构如下:定义(n,k,r)数据包结构,其中k表示原始数据包个数,r表示冗余包个数,n表示数据包总数,n=k+r;对于k个原始数据包,每个原始数据包mj均包含m
×
l个比特,用一个m
×
l的二元矩阵表示;每个冗余包rj包含m
×
l个比特,用m
×
l的二元矩阵表示;通过基于给定的编码系数矩阵k
1j
,...,k
kj
对原始数据包m1,...,mk线性组合,生成冗余包rj:;(1)确定译码方式:基于译码系数矩阵计算出丢失的原始数据包m1,...,mr,将剩余的k-r个已知原始数据包信息分别从校验包r1,...,rr中消除得到新的校验包,然后通过下式还原出原始数据包m1,...,mk:;(2)其中:m为新校验包所对应的编码系数矩阵。
29.所述core_sg单元中还设置有计数器子单元,用于记录输入数据包的个数,并初始化循环次数寄存器cycle_max。在所述core_sg单元中还设置计数器子单元记录输入数据包的个数,会派生出vout和trig信号。当vin信号无效时,编码流水线被插入空泡,不影响运算正确性。当vout无效时,dout输出全0。
30.所述补位运算根据接口输入的系数设定补位内容和补位位置,将输入的lbits扩增为l+1bits;计算结果为padded并传给分散运算;所述分散运算根据控制系数src_i对l+1bits分散进行l+1种移位操作,不同位的src_i表示不同的循环移位结果,并将结果输出给聚集运算;所述聚集运算对l+1种分散计算结果执行异或,通过异或达到聚集效果,得到l+1bits运算结果并输出给销位运算;所述销位运算根据设定的销位方式和销位位置,将l+1bits缩位到lbits;所述累加运算将属于同一冗余包的部分结果逐次累加。
31.本发明从底层到上层依次为:处理lbits基本数据的pe_sg子单元、依次处理k个数据包得到单个冗余包的编码核core_sg单元;本发明集成了多个core_sg单元,针对单个输入数据流并行编码,得到r个冗余包的编码ip和rmds。pe_sg子单元采用五级流水线模式,包括补位运算、分散运算、聚集运算、销位运算以及累加运算;pe_sg子单元流水处理各数据包,随路处理无需存储,当某周期无输入数据时,流水线中允许存在空泡,不影响最终计算结果。
32.为了增强ip核的可拓展性,所述编码ip核模块连接有dmrom模块、dffifo模块以及testfsm模块,根据ip核不同的集成环境可以替换。比如通过apb总线接口配置mode等状态和控制寄存器,通过axi总线接口输入输出数据,或者通过pcle集成在桌面或服务器系统中。以3mds的算法为例,ip至少集成3个core_sg单元,不需要额外存储。通过在ip核中集成
更多编码核,可以支持更高的输入数据位宽或更多的冗余包配置。
33.本发明使用软件离线计算控制系数src,也即ip核从外部导入控制系数。src共有l+1 bits,每个bit控制数据包的一种移位方式。
34.本发明所述的一种基于分散聚合流水线实现mds阵列码的ip核架构中,各个单元由底层到顶层对原始数据包逐级处理,得到所需冗余包,得到的冗余包可在解码环节用来还原原始数据包;有r个core_sg单元所构成的编码ip核架构,每个core_sg单元可以通过配置不同的控制系数,对同一个输入数据并行计算,得到r个不同的冗余包。
35.本发明的core_sg单元集成了dw个pe_sg子单元并行计算,提升了编码核数据通路带宽,各pe_sg子单元分别处理l比特的输入数据。
36.并且本发明在求解冗余包r时,使用循环位移代替矩阵乘法;每个冗余包需要k个原始数据包参与计算,运算可分为k
×
r 个部分进行;若数据包一次进行运算,在单个数据包的处理中,也存在以l个比特(l是循坏移位操作的数据位宽)为基本数据单元的多种并行性;对于l bits基本数据单元的多种循环移位和通过异或达到缩位聚集的效果,可以采用分散聚集流水线技术,根据控制系数分散得到移位结果,并通过异或和聚集进行缩位。算法串行部分是对l bits基本数据单元的补位、循环右移、销位、异或操作,可采用流水线技术优化,重叠(overlapping)处理不同数据单元,提升计算吞吐率。
37.下面对本发明的具体实施方式做进一步的描述:本发明首先在算法层面的分析,规定系统各个参数。若想恢复传输、存储时损坏的原始数据包,需要先在编码环节计算出r个冗余包,在解码环节,只要损失的数据包不超过r,就能由冗余包求解出k个原始数据。为了具体化分析,取r=3,k《=255。由公式(1)可知冗余包r是由原始数据包mj和编码系数k复合而成。原始数据包mj已知,为了方便介绍k,先定义如下变量:1) l+1为任意素数,表示l
×
l维单位阵;2) 0与1(粗体)分别表示l维全0与全1列向量;3) 为(l+1)
×
(l+1)的gf(2)-循环移位矩阵;4) g表示l
×
(l+1)的gf(2)-矩阵;5) h表示(l+1)
×ꢀ
l的gf(2)-矩阵;则对于一l维行向量,向量乘矩阵等价于对向量做右循环移位j比特操作。
38.本发明确定编码系数的步骤如下:在循环移位mds向量码中,编译码所需的系数矩阵k主要由以下四类构成。其中b代表由奇数,且最多l/2个cl的不同次幂相加形成的l
×
l矩阵(包括单位阵il =cl0),a代表由偶数个cl的不同次幂相加形成的l
×
l矩阵:1)k = gbh,即对于(l
–
1)维输入向量m,mk的乘法操作可以通过下列步骤实现:
①ꢀ
先在m的末尾补一位零比特形成l+1维向量(实现 mg 操作);
②
对进行b所设定的一次或多次循环移位操作,再将循环移位后的结果逐位异或,形成新的l+1维向量(实现操作);
③
将的前l位比特分别与最后一位比特进行异或(实现操作),得到最终的l维输出向量mk。
39.2)k=h
t
bg
t
。
40.3)k=h
t
bh。
41.4)k=gag
t
。
42.在分布式存储应用中,由于编码操作要比译码操作频繁的多,因此本发明的编码系数矩阵为k=gag
t
,译码系数矩阵为k=h
t
bh。
43.以下通过本发明的实现步骤进行具体说明。
44.步骤一,软件计算编码系数。循环移位的控制系数共有l+1个bit,每1个bit控制数据包的一种移位方式:当bit为0时,不需要该移位操作;当第i个bit为1时,需要进行i次移位。控制系数src更适合使用软件离线计算,编写c程序,接受数据包个数k,冗余包r,计算生成r个控制系数矩阵,用来分配给r个编码核core_sg单元。单个系数矩阵宽为l+1,高为k。
45.该算法根据k和r计算出r个配置文件,每个文件包含k个配置系数,每个配置系数由l+1 bits,具有良好的算法兼容性,方便后续算法的提升。
46.步骤二,硬件实施框架分析。确定算法之后,接下来由整体到局部,逐步解析数据的处理方式和模块的作用。基于循环移位编码的rmds算法存在多种并行性:k个数据包得到r个冗余包,运算可分为k
×
r 个部分进行;若数据包依次到来,在单个数据包的处理中,也存在以l比特为基本数据单元的多种并行性;对l比特的基本数据单元的多种循环移位和缩位异或操作,可以采用(scatter-gather)分散聚集技术,根据控制系数分散得到移位结果,并通过异或达到聚集效果来进行缩位。算法串行部分是对l比特基础数据单元的补位、循环右移、销位、异或操作,这样就能采用流水线技术优化,重叠(overlapping)处理不同数据单元,提升吞吐率。
47.循环移位的控制系数(src,shift right circular parameters)决定各数据包在计算各冗余包时循环右移操作的数量和位数。rmds算法有多种版本,通过上位软件离线计算控制系数,并配置在硬件weignt fifo中,sr_src可以支持基于循环移位的多种rmds算法的加速。
48.步骤三,硬件处理微架构core_sg单元。所述core_sg单元部分接口信息见下表。
49.表 2-1 core_sg单元部分接口
bits;累加运算(accumulation):将属于同一冗余包的部分结果逐次累加。
52.为了方便表述,下面给出pe_sg子单元关键接口的定义:表 2-2 pe_sg子单元部分接口从信号和数据流通的角度,mode控制padding和trimming两个流水级补位和销位的方式;trig信号为1时,重置data_o累加寄存器,当vld_i同时有效时,data_o寄存data_i,否则清零;src_i来自配置后的weight fifo,src_i的各比特位分别控制一个分散后的循环移位结果:当某位为0时,表示不需要循环移位,当某位为1时,表示循环移位对应位数次,循环移位结果用固定连线获得。比如说:当weight fifo中传出的sci_i=17’h5,也即0101时,则sci_0为循环右移0位,src_2为循环右移2位,其他scr_1,scr_3~scr_16都为0,等价于数据包在scattering流水级进行了乘i+c
2l
操作。在gathering流水级,将17个src寄存器通过异或进行缩进。
53.pe_sg子单元的微架构如附图3所示,可以看出各级流水线的工作方式。
54.步骤五,软件离线计算控制系数src;循环移位控制系数src共有l+1个bits,每个bit控制对应数据包的一种移位方式:当此位为0,不需要移位操作;此位为1时,需要进行对应的移位操作。可见上文中的举例。软件根据数据包索引k,冗余包索引r,计算生成共r个控制系数矩阵,分配给r个core_sg单元。
55.步骤六,仿真验证。微架构与设计环节分析结束,下面先对rtl级设计进行仿真验证。测试数据由循环移位网络编码算法标准matlab程序代码计算生成,生成128个1024bits的数据包,以及3个1024bits的冗余包。仿真软件使用的是modelsim,将rtl,tb文件和原始数据包导入工程,仿真生成的波形如附图4所示。testbench使用128个周期完成3个core_sg单元的配置,然后用128个周期并行计算得到3个冗余包。如附图4,可以看到仿真结果与matlab计算结果相同。
56.步骤七,fpga上板测试。仿真测试验证了rtl设计文件无误后,即可生成比特流文件进行上板验证。本次选择的是xilinx zcu106开发板,该开发板搭载xilinx 16nm台积电工艺的ultrascale + mpsoc zu7ev fpga。移植工作包括:(1)选用300mhz的差分时钟输入,通过mmcm综合频率得到200mhz的用户时钟;(2)将weight fifo用fpga的宏部件block ram实现;(3)用 block ram 实现片上rom存储data.txt和3个系数矩阵用来提供测试激励;(4)在数据输入端实现data fifo,作为循环缓冲区提供计算需要的无限数据;(5)输入数据总位宽1024 bits;单个pe_sg子单元的位宽为16 bits;单个core_sg单元集成64个pe_sg子单元;(6)使用硬件逻辑分析仪ila抓取计算结果,验证功能正确性;(7)设计测试状态机,完成weight fifo配置,data fifo加载,启动运算等步骤;(8)8颗led以gb为单位展示ip的实际计算速度,吞吐率约为25.6gbps。
57.使用开发板上的sw13拨码开关控制mode的配置,如附图5所示。布局布线后的芯片版图和资源使用摘要可见附图6和附图7,更加精确的ip资源占用情况可见附图8;布局布线后fpga的功耗估计可见附图9,动态功耗约为1.014w,外围驱动模块dm rom、df fifo等大量bram资源,根据资源净占用比例对bram和logic动态功耗修正后,静态功耗约为0.73。fpga通过内置逻辑分析仪ila抓取3个core_sg单元的dout,并使用vout上升沿触发,抓取结果如附图10所示,可以看到上板运行结果与软件生成的结果一致,验证了功能的正确性。
58.以上所述实施例仅表达了本技术的具体实施方式,其描述较为具体和详细,但并不能因此而理解为对本技术保护范围的限制。应当指出的是,对于本领域的普通技术人员来说,在不脱离本技术技术方案构思的前提下,还可以做出若干变形和改进,这些都属于本技术的保护范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1