基于注意力机制和CNN-BiGRU的负荷预测方法与流程
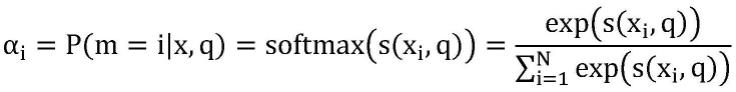
基于注意力机制和cnn-bigru的负荷预测方法
技术领域
1.本发明涉及短期负荷预测领域,特别是涉及基于注意力机制和cnn-bigru的负荷预测方法。
背景技术:
2.短期负荷预测一直是电力系统给用户提供合格可靠电能的重要保障。南宁电网短期负荷预测主要预测未来一周左右的电力负荷。预测精度严重影响着电力系统的规划、计划、营销、市场交易、调度等部门的工作人员的工作。短期电力负荷预测工作的关键取决于其负荷预测模型的建立,然而由于短期电力负荷的不确定性及其随机性,使其对负荷预测模型的要求越来越高。而影响短期负荷预测精度的因素也随着用户的用电需求趋于多样性而变得更加复杂。
3.根据影响负荷预测精度的因素,设计特征提取模型和预测模型。通常设计短期负荷预测模型需要考虑的因素有:历史负荷数据特性;气象因素;日期类型;恰当的数据特征提取和预测算法;容错能力。传统的负荷预测方法由两部分组成:数据预处理;构建负荷预测模型;模型训练;模型参数微调;测试。
4.近年来,随着人工智能算法的发展,短期负荷预测模型建立的关注点主要在预测模型的建立上。如人工神经网络、长短时记忆、极限学习机、支持向量机等,而对于前期的数据预处理部分关注较少,往往前期的数据预处理对后期的预测结果影响颇大。恰当的负荷数据处理手段不仅可以改善预测结果,更能通过简化预测模型的复杂度而节约计算机迭代成本。
5.例如,一种在中国专利文献上公开的“一种短期负荷预测方法和短期负荷预测装置”,其公告号cn111382891a;包括:获取过去时段的负荷数据和预测时段的外部参数;通过小波分解将过去时段的负荷数据分解为第二级细节分量、第三级近似分量和第三级细节分量;基于第二级细节分量,获取预测时段的预测负荷数据的第二级细节分量;基于过去时段的负荷数据的第三级近似分量和第三级细节分量以及所述外部参数,获取预测时段的预测负荷数据的第三级近似分量和第三级细节分量;通过小波重构将预测负荷数据的第二级细节分量、预测负荷数据的第三级近似分量和第三级细节分量重构为预测时段的预测负荷数据。根据短期负荷预测方法和短期负荷预测装置,能够准确地预测短期负荷。然而该方法通过拆分细节量完成对每段细节量进行预测,缺少对所拆分数据的预处理过程,往往前期的数据预处理对后期的预测结果影响颇大。恰当的负荷数据处理手段不仅可以改善预测结果,更能通过简化预测模型的复杂度而节约计算机迭代成本。
技术实现要素:
6.本发明主要针对上述问题;提供了基于注意力机制和cnn-bigru的负荷预测方法;在历史负荷的预处理阶段添加双向gru算法和注意力机制来提取负荷特征,改进负荷数据特征提取方法以提高短期负荷预测模型的预测精度,采用卷积神经网络算法实现短期负荷
预测模型的建立,实现对短期负荷的准确预报。
7.本发明的上述技术问题主要是通过下述技术方案得以解决的:一种基于注意力机制和cnn-bigru的负荷预测方法,包括:s1、数据采集:采集电网历史负荷数据,并将其储存为时间序列数据;s2、数据预处理:将数据输入cnn层做特征提取;所述cnn层包括输入层、卷积层、激励层、池化层和全连接fc层;在输入预测模型前,提前消除数据量纲差异对模型的影响,即对数据进行归一化处理;s3、建立预测模型:搭建attention模块;搭建bigru模块;进行模型性能验证;s4、负荷预测:将处理好的数据输入预测模型,输出负荷预测曲线。
8.在历史负荷的预处理阶段添加双向gru算法和注意力机制来提取负荷特征,改进负荷数据特征提取方法以提高短期负荷预测模型的预测精度,采用卷积神经网络算法实现短期负荷预测模型的建立,实现对短期负荷的准确预报。
9.作为优选,所述卷积层定义为:s(i,j)=(x
×
w)(i,j)=∑m∑nx(i+m,j+n)w(m,n);其中,w为卷积神经网络的卷积核,x为输入,x的维度和矩阵w的维度一致。卷积层是cnn区别于其他神经网络算法的模块,作用是将通过该层的数据做一次特征提取,能够从数据中挖掘出深层次的特征。
10.作为优选,所述激励层用作映射神经元卷积的映射,该映射是非线性的,采用relu函数作为卷积神经网络的激励函数;所述函数如下:relu(x)=max(0,x)。为了使模型的迭代速度更快,一般采用relu函数作为卷积神经网络的激励函数。
11.作为优选,所述步骤s2中,归一化公式为:其中:x
max
为数据最大值,x
min
为数据最小值,x为经过归一化处理后的数据集矩阵,x为输入的数据集样本矩阵。在输入预测模型前,需要提前消除数据量纲差异对模型的影响。
12.作为优选,所述步骤s3中、搭建attention模块的方法包括:s51、对输入信息进行注意力值分配;s52、基于注意力分布值计算输入信息的加权平均值。
13.attention机制的作用是给cnn层输出的特征分配权值,给关键特征分配更高的权值,而给非关键的特征赋予更小的权值,从而提高模型的预测精度。
14.作为优选,所述注意力值分配包括:设置向量q,引入函数,通过计算输入向量和q的相关性,来进行注意力值的分配,其过程如下:αi表示为第i个向量的注意力分布,s(xi,q)为注意力筛选函数。通过计算输入向量和q的相关性,来进行注意力值的分配,即相关性越大注意力就越大,反之则越小。
15.作为优选,所述加权平均值的计算过程如下:ai
为第i个向量所受到的注意力程度。通过对注意力加权平均,将关键特征权重提高,加权平均后可以得到特征更鲜明的向量数据,方便后续对模型进行训练调整。
16.作为优选,所述bigru模块为双向门控循环单元,包括分别为向后学习历史数据特征和向前学习未来数据特征的两个gru模型。即在模型训练过程中可以同时利用历史和未来数据信息,并对其进行融合处理,表现出了更优越的性能。
17.作为优选,步骤s3中,将数据预处理阶段处理好的数据拆分成训练集和测试集,分别采用训练数据和测试数据对模型的损失函数和迭代速度进行实验验证;可以通过该过程验证模型是否符合预期要求。
18.本发明的有益效果是:基于注意力机制和cnn-bigru的负荷预测方法;在历史负荷的预处理阶段添加双向gru算法和注意力机制来提取负荷特征,改进负荷数据特征提取方法以提高短期负荷预测模型的预测精度,采用卷积神经网络算法实现短期负荷预测模型的建立,实现对短期负荷的准确预报。
附图说明
19.图1为attention机制结构图;图2为bigru模型结构图;图3为本方法流程图;图4为预测模型图;图5为模型损失值图;图6为短期负荷预测曲线图。
具体实施方式
20.应理解,实施例仅用于说明本发明而不用于限制本发明的范围。此外应理解,在阅读了本发明讲授的内容之后,本领域技术人员可以对本发明作各种改动或修改,这些等价形式同样落于本技术所附权利要求书所限定的范围。
21.下面通过实施例,对本发明的技术方案作进一步具体的说明。
22.一种基于注意力机制和cnn-bigru的负荷预测方法需要分为以下几个部分来实现。
23.1:数据预处理。
24.步骤一:数据采集。
25.收集8天的电网历史负荷数据,并将其存储为时间序列数据。数据长度为:8*96=768个,时间单位为分钟(m),采样周期t为15分钟。
26.步骤二:特征提取。
27.将步骤一中采集好的数据输入cnn层做特征提取。cnn模型由输入层、卷积层、激活层、池化层和全连接fc层组成。其中卷积层是cnn区别于其他神经网络算法的模块。其定义为:s(i,j)=(x
×
w)(i,j)=∑m∑nx(i+m,j+n)w(m,n);
其中,w为卷积神经网络的卷积核,x则为输入,x的维度和矩阵w的维度是一致的,卷积层的作用是将通过该层的数据做一次特征提取,能够从数据中挖掘出深层次的特征。
28.激励层的作用就是映射神经元卷积的映射,该映射是非线性的。为了使模型的迭代速度更快,一般采用relu函数作为卷积神经网络的激励函数。其定义为:relu(x)=max(0,x)。
29.池化层是结构相对简单的模块,其作用是对卷积层提取的数据特征进行选择,通过在一定程度上降低数据运算量,并且有效避免过拟合现象,经过池化层处理后可以有效提高模型的容错性。
30.全连接fc层的作用类似于多分类器,该模块包含cnn模型中大部分计算过程。该模块主要对数据进行线性和非线性的处理,线性运算主要针对输入数据,非线性运算主要针对各层级之间数据的映射。该层还起着存储器的作用,卷积层提取的数据特征,池化后的数据以及需要模型输出的数据都存储于此。
31.步骤三:归一化处理。
32.在输入预测模型前,需要提前消除数据量纲差异对模型的影响。归一化公式为:其中:x
max
为数据最大值,x
min
为数据最小值,x为经过归一化处理后的数据集矩阵,x为输入的数据集样本矩阵。
33.2:建立预测模型。
34.步骤一:搭建attention模块。
35.attention机制的作用是给cnn输出的特征分配权值,给关键特征分配更高的权值,而给非关键的特征赋予更小的权值,从而提高模型的预测精度。
36.计算attention机制的步骤分为两步:对输入信息进行注意力分布值通过设置一个向量q,引入一个函数,通过计算输入向量和q的相关性,来进行注意力值的分配,即相关性越大注意力就越大,反之则越小。其定义如下:αi表示为第i个向量的注意力分布,s(xi,q)为注意力筛选函数。
37.基于1)计算输入信息的加权平均值。
38.计算加权平均:ai为第i个向量所受到的注意力程度。
39.附图1为attention机制结构图,其中x=[x1,x2,
…
xn]为输入向量,hn表示隐藏层的输出,an表示attention机制对隐藏层输出的注意力概率分布值,y为attention机制的输出值。
[0040]
步骤二:搭建bigru模块。
[0041]
bigru是双向门控循环单元,由两个gru模型构成,一个向后学习历史数据特征,另
一个向前学习未来数据特征,即在模型训练过程中可以同时利用历史和未来数据信息,并对其进行融合处理,表现出了更优越的性能。其模型结构如附图2所示。
[0042]
步骤三:模型性能验证。
[0043]
基于注意力机制和cnn-bigru的负荷预测模型建立好后根据如附图3的流程对模型进行调参。完整的预测模型如附图4所示。
[0044]
将数据预处理阶段处理好的数据按照7:3拆分成训练集和测试集,分别采用训练数据和测试数据对模型的损失函数和迭代速度进行实验验证,验证结果如附图5所示,其中loss曲线是训练集的损失迭代曲线,vol-loss是测试集的损失迭代曲线。
[0045]
步骤四:负荷预测将处理好的数据长度为:8*96,时间单位为分钟(m),采样周期t为15分钟,输入预测模型,输出负荷预测曲线如附图6所示。其中实际负荷的曲线波动较大,幅值变化净值较大,然而前端预测曲线基本拟合实际负荷变化曲线。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1