一种文件导入方法、设备和存储介质与流程
1.本技术涉及软件开发技术领域,特别是涉及一种文件导入方法、设备和存储介质。
背景技术:
2.在多文件在线开发平台中,常会遇到跨文件导入的情形,其中,跨文件导入表示在当前的文件中导入其他的文件,在一些场景中,会对被导入的文件进行修改,但被导入的文件在修改后,并不会在当前文件中自动更新,需要手动执行相关命令或者重启才会进行更新,使跨文件导入繁琐且效率低下。
3.因此,被导入的文件在修改后,如何在当前文件中快速更新意义重大。
技术实现要素:
4.本技术主要解决的技术问题是提供一种文件导入方法、设备和存储介质,能够提高被修改文件在当前python执行器中的更新效率。
5.为解决上述技术问题,本技术采用的一个技术方案是:提供一种文件导入方法,该方法包括:获取导入到当前python执行器中的目标文件;将该目标文件存储至存储模块;响应于目标文件存在变动,更新当前python执行器中目标文件。
6.其中,在获取导入到当前python执行器中的目标文件之前,还包括:将用于导入目标文件的包文件自动加载至当前python执行器,包文件中包括自定义文件查找器、自定义文件加载器和监控器,监控器用于监控目标文件是否存在变动。
7.其中,获取导入到当前python执行器中的目标文件的步骤,包括:利用自定义查找器查找待导入python执行器的目标文件;利用自定义加载器加载目标文件至当前python执行器。
8.其中,将自定义查找器插入在钩子函数的首位或前端,自定义查找器和自定义加载器的数量为多个,各自定义查找器用于查找的文件类型相同或不同。
9.其中,在利用自定义查找器查找待导入python执行器的目标文件之前,还包括:查找存储模块中是否存在目标文件;响应于存储模块中不存在目标文件,执行利用自定义查找器查找目标文件及其后续步骤。
10.其中,响应于目标文件存在变动,更新当前python执行器中目标文件,包括:清除存储模块中的目标文件;利用自定义加载器加载变动后的目标文件至当前python执行器,更新目标文件。
11.其中,在响应于目标文件存在变动,更新当前python执行器中目标文件之后,还包括:将变动后的目标文件存储于存储模块。
12.其中,文件导入方法用于相对引用和多级引用文件的导入;和/或,文件导入方法用于不同的python执行环境。
13.为解决上述技术问题,本技术采用的另一个技术方案是:提供一种电子设备,包括相互耦接的存储器和处理器,存储器存储有程序指令;处理器用于执行存储器中存储的程
序指令,以实现上述方法。
14.为解决上述技术问题,本技术采用的又一个技术方案是:提供一种计算机可读存储介质,计算机可读存储介质用于存储程序指令,程序指令能够被执行以实现上述方法。
15.上述方案,在获取导入到当前python执行器中的目标文件后,将目标文件存储至存储模块,响应于目标文件存在变动,更新当前python执行器中的目标文件。与现有技术相比,本技术方案在被导入到当前python执行器中的目标文件发生变动后,无需手动执行相关命令或重启被变动文件对应的执行器等,可使当前python执行器中的目标文件跟随目标文件的变动而更新变动,能够提高被修改文件在当前文件的更新效率。
附图说明
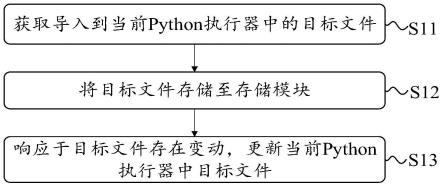
16.图1是本技术提供的文件导入方法一实施例的流程示意图;
17.图2是图1所示步骤s11一实施例的流程示意图;
18.图3是图1所示步骤s13一实施例的流程示意图;
19.图4是本技术提供的文件导入方法另一实施例的流程示意图;
20.图5是本技术提供的电子设备一实施例的框架示意图;
21.图6是本技术提供的计算机可读存储介质的框架示意图。
具体实施方式
22.下面结合本技术实施例中的附图,对本技术实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本技术一部分实施例,而不是全部实施例。基于本技术中的实施例,本领域普通技术人员在没有做出创造性的劳动前提下所获得的所有其他实施例,都属于本技术保护的范围。
23.在本文中提及“实施例”意味着,结合实施例描述的特定特征、结构或特性可以包含在本发明的至少一个实施例中。在说明书中的各个位置出现该短语并不一定均是指相同的实施例,也不是与其它实施例互斥的独立的或备选的实施例。本领域技术人员显式地和隐式地理解的是,本文所描述的实施例可以与其它实施例相结合。
24.需要说明的是,本技术提供的文件导入方法可用于任何需要跨文件导入其他文件的场景,可以但不限于是jupyterlab或jupyterhub开发环境。为便于理解本技术方案,下文均是以jupyter环境为例进行叙述,但可以理解的是,本文只是以jupyter环境为例,并不因此限制本技术方案。
25.请参阅图1,图1是本技术提供的文件导入方法一实施例的流程示意图。需注意的是,若有实质上相同的结果,本实施例并不以图1所示的流程顺序为限。如图1所示,本实施例包括:
26.s11:获取导入到当前python执行器中的目标文件。
27.本实施例的方法用于在被导入的目标文件发生变动后,可使当前python执行器中目标文件跟随原目标文件的变动而更新变动,以能够提高被修改文件在当前文件的更新效率。
28.目标文件可以为从另一个python执行器导入到当前python执行器中的文件,也可以是将网络资料导入到当前python执行器中的文件,还可以是系统固有文件等,导入的文
件可以但不限于是ipynb文件、py文件等。其中,本文所述的“导入”和“引用”意思相同,导入(引用)到当前python执行器中的目标文件可以是目标文件的全部内容,也可以是目标文件的部分内容,具体关于导入的目标文件的内容和文件的类型可根据实际场景的需要进行确定,此处不做具体限定。
29.s12:将目标文件存储至存储模块。
30.本实施例中,在导入目标文件后,需要将目标文件存储至一存储模块,该存储模块用于存储包括目标文件在内的文件,目标文件存储至该存储模块表示该目标文件已被导入(已被加载),也就是说,该存储模块存放着当前python执行器所有已经导入的目标文件。其中,该存储模块可以是sys.modules,还可以是其他专门用于存储目标文件的模块,此处不做具体限定。
31.s13:响应于目标文件存在变动,更新当前python执行器中目标文件。
32.在一些实施例中,在获取导入到当前python执行器中的目标文件后,受各种因素的影响,例如在代码调试中,在发现代码有异常时,会修改代码,使原目标文件存在变动,故在获取导入到当前python执行器中的目标文件后,原目标文件会存在变动,其中,目标文件存在变动是指目标文件中的内容存在增加或删减或替换等被修改的情形,本实施例中,在原目标文件存在变动的情况下,可使当前python执行器中目标文件跟随原目标文件的变动而更新变动。
33.考虑到每一个文件均对应有一个python执行器,每打开一个文件,则启动一个python执行器,各文件对应的各python执行器之间相互隔离,不能相互通讯,故需要将多个文件加载到同一个python执行器里,以实现文件导入,同时,需要监控目标文件的变动,在原目标文件存在变动的情况下,还需要将变动后的目标文件重新加载至当前的python执行器,使当前python执行器中目标文件跟随原目标文件的变动而实时更新变动。基于上述考虑,故要达到上述跟随原目标文件的变动而实时更新变动的目的,需要在导入目标文件之前,具体地,在启动当前的python执行器时,可将上述能够用于将多个文件加载到同一个python执行器里的查找器和加载器以及用于监控目标文件变动的监控器注册到当前的python执行器中,以在需要导入目标文件时,利用查找器查找标准文件,利用加载器加载目标文件,利用监控器监控目标文件的变化,以使在监测到目标文件存在变化的情况下,可将变动后的目标文件重新加载至当前的python执行器中,使当前python执行器中目标文件跟随原目标文件的变动而实时更新变动。
34.在一些实施例中,考虑到一般要导入的文件为个人编写的文件或者网上查询的资料等,很少需要导入系统文件,故可预先编写用于查找目标文件的自定义查找器,并将该编写的自定义的查找器插入到钩子函数的首位或前面位置,以在查找目标文件时可优先使用自定义查找器进行查找。其中,需要说明的是,若使用各自定义查找器均未找到对应的目标文件,说明要找的目标文件并非是个人编写文件或网上的资料等文件,可能是系统固有文件,则需要利用系统自带的查找器继续进行查找,若系统查找器找到目标文件,则返回对应的系统加载器加载目标文件至当前的python执行器,以实现文件导入和实时更新,若未找到,则进行报错(例如报告文件异常)。
35.在一些实施例中,可利用预先编写自定义的文件查找器和文件加载器共同实现跨文件的导入功能,再结合监控器实现实时更新目标文件的目的。其中,监控器用于监控目标
文件是否存在变动,以在监控器监控到目标文件存在变动的情况下,利用查找器查找变动后的目标文件,查找到变动后目标文件后,返回对应的加载器加载变动后的目标文件至当前python执行器中,使当前python执行器中目标文件跟随目标文件的变动而实时更新变动。其中,目标文件存在的变动表示该目标文件存在内容修改、内容删减、内容增加等任一种情况或任一种情况的组合。
36.其中,编写的自定义的文件查找器定义有文件(模块)查找机制,该查找机制表达了如何利用该自定义查找器找到对应的文件,例如定义一个实现了find_module或者find_loader方法的类,其中,如果查找器找到模块文件,就返回一个加载器,否则就返回none,系统会用其他查找器继续查找文件。在一些实施例中,自定义的查找器可支持相对路径和绝对路径的导入,例如要导入xxx.module文件,可利用以下3种导入方式,from xxx.module import a、from.module import a或import xxx.module,其中xxx.表示包文件,module表示一个具体的文件,a是module中的一个变量或者函数,from xxx.module import a表示文件路径。
37.编写的自定义文件加载器定义有文件加载机制,该加载机制表达了如何利用该自定义加载器加载已找到的模块文件,其中,自定义加载器需要定义一个实现了load_module方法的类对与导入有关的属性进行校验,创建模块对象并绑定所有与导入相关的属性变量(如loader、file、path、package等变量)到该模块(文件)上,将此模块(文件)保存到存储模块如sys.modules中(其中,上述顺序很重要,避免递归导入),然后加载模块文件,若加载出错,需要抛出异常(importerror),若加载成功,则返回模块文件。
38.在一实施例中,为了在启动python执行器时,能够自动加载自定义查找器、自定义的加载器和监控器,可预先编写用于导入目标文件的一个包文件,例如编写import_notebook.pth文件,其中,文件内容为imp ort import_notebook,该包文件中包括有自定义查找器、自定义的加载器和监控器,在一具体实施方式中,可将预先编写的用于导入目标文件的包文件在安装时被安装到jupyter环境中,如果jupyter环境中有其他的python执行环境,也需要在对应的python执行环境安装import_note book包,以使上述文件导入方法能够用于不同的python执行环境,具体地,可安装在python的包安装目录(例如,site-packages)下,其中,在python执行器启动时,会在python的包安装目录(site-packages)下加载包文件(import_notebook.pth文件),并向当前python环境中注册自定义的文件查找器、自定义的加载器和监控器,以使加载了该包文件后的当前python环境中具备自定义的文件查找器、自定义的加载器和监控器的功能环境,故可实现跨文件导入和目标文件的实时更新。也就是说,在获取入到当前python执行器中的目标文件之前,可将预先编写的用于导入目标文件的包文件自动加载至当前的python执行器中,以使加载了该包文件的当前的python执行器具备该包文件中各包含文件所具备的功能环境,进而实现跨文件导入和当前python执行器中目标文件的实时更新,进一步提高了更新效率。
39.本实施例中,在获取导入到当前python执行器中的目标文件后,将目标文件存储至存储模块,响应于目标文件存在变动,更新当前python执行器中的目标文件。本实施例方案在被导入到当前python执行器中的目标文件发生变动后,可使当前python执行器中的目标文件跟随目标文件的变动而更新变动,能够提高被修改文件在当前文件中的更新效率。
40.请参阅图2,图2是图1所示步骤s11一实施例的流程示意图,需注意的是,若有实质
上相同的结果,本实施例并不以图2所示的流程顺序为限。如图2所示,获取导入到当前python执行器中的目标文件的步骤包括:
41.s21:利用自定义查找器查找待导入python执行器的目标文件。
42.本实施例的方法用于利用自定义加载器将查找到的目标文件加载到当前的python执行器中,以利用自定义加载器实现文件的导入。
43.s22:利用自定义加载器加载目标文件至当前python执行器。
44.在一些实施例中,用于导入目标文件的包文件中包含至少一个自定义查找器和至少一个自定义加载器。其中,至少一个自定义查找器中各查找器用于查找的文件类型是相同的或是不同的。例如,各自定义查找器可以分别用来查询网络上的资料、ipynb类型的文件和py文件等,也可以是至少一个自定义查找器中的至少部分用于查找相同的文件类型例如均是用于查找ipynb类型的文件。在一些实施例中,该至少一个自定义查找器和至少一个自定义加载器数量相同,且一一对应,也就是说,当其中一个自定义查找器查找到目标文件后,会对应返回一个自定义加载器加载该目标文件至当前的python执行器。当然,在一些实施例中,该至少一个自定义查找器和至少一个自定义加载器数量也可以不同,例如,至少一个自定义查找器中的两个查找器对应一个自定义的文件加载器,具体可根据实际应用场景需要进行确定,此处不做具体限定。
45.其中,在自定义文件查找器查找到目标文件以后,会返回一个对应的加载器,故可通过返回的加载器将目标文件导入到当前的python执行器,从而实现文件的跨文件导入。
46.在一些实施例中,上述文件导入方法能够用于相对引用和多级引用文件的导入。例如,当前python执行器对应的文件为a,a需要引用文件b,而b引用了文件c,故在将目标文件b导入a时,查找器会先找到文件b,在加载文件b时发现文件b引用了文件c的代码,故会继续通过查找器查找到文件c并加载文件c,直到把所有被引用的文件找到为止。又如,当前python执行器对应的文件为a,a引用文件b,当引用的文件b的名称发生变化,该文件名称的变化对引用的内容是没有影响的,故可通过路径找到对应的被引用文件。
47.在一些实施例中,可能每次待导入到当前python执行器的目标文件均不同,也可能在导入了目标文件之后,在当前python执行器的其他位置还需要用到该已经导入的目标文件,由步骤s12可知:存储模块存放着当前python执行器所有已经导入的目标文件,因此,在导入目标文件之前,具体地,在步骤s21利用自定义查找器查找待导入python执行器的目标文件之前,需要先确定存储模块中是否已经存在待导入的目标文件,以确定待导入的目标文件先前是否已经被导入过。
48.在一实施方式中,存储模块中不存在目标文件,表明待导入的目标文件之前未被加载(导入)过,则在存储模块中不存在目标文件的情况下,需要执行上述利用自定义查找器查找目标文件及其后续步骤(即步骤s21和步骤s22)。
49.在另一实施方式中,存储模块中存在目标文件,表明该目标文件已经被加载(导入)过,则直接返回该目标文件,而不需要重复执行上述利用自定义加载器查找目标文件,以及利用自定义加载器加载目标文件的步骤。
50.在一些实施例中,在监控器通过实时监控发现已导入到当前python执行器中的原目标文件存在变动,其中,在将该变动的目标文件更新至当前python执行器之前,需要将存储模块中存储的变动前的目标文件清除掉,然后再启动上述利用加载器加载变动后目标文
件的步骤。
51.具体地,请参阅图3,图3是图1所示步骤s13一实施例的流程示意图。需注意的是,若有实质上相同的结果,本实施例并不以图3所示的流程顺序为限。如图3所示,本实施例步骤包括:
52.s31:清除存储模块中的目标文件。
53.本实施例方法用于在已导入到当前python执行器中的原目标文件发生变动后,清除存储模块中的原目标文件,然后利用自定义加载器加载变动后的目标文件至当前python执行器中,使当前python执行器中目标文件跟随原目标文件的变动而实时更新变动。
54.需要说明的是,python在导入文件时,一般是先判断待导入的目标文件是否已被加载(即存储模块中是否存在目标文件,存在表示已加载,不存在表示未加载),如果已加载就直接返回,返回该已经加载过的目标文件;如果未加载,就通过注册的各种查找器去查找目标文件,找到后再通过加载器去加载目标文件,实现文件的导入。
55.因此,若利用监控器监测到导入的原目标文件存在变动,为避免在存储模块中存在目标文件,直接返回变动前的原目标文件,故在监测到目标文件变动后,需清除存储模块中的目标文件,也就是说,要将先前加载过的目标文件清除掉,以使存储模块中不存在变动前的原目标文件,在存储模块中不存在变动前的原目标文件的情况下,python则会通过加载器将变动后的目标文件重新加载至当前的python执行器中。
56.s32:利用自定义加载器加载变动后的目标文件至当前python执行器,更新目标文件。
57.在一实施方式中,在清除存储模块中的目标文件之后,直接返回一个自定义加载器将变动后的目标文件加载至当前的python执行器中,使当前python执行器中的目标文件跟随目标文件的变动而实时更新变动。
58.在另一实施例中,在清除存储模块中的目标文件之后,也可先利用自定义的文件查找器查找到目标文件,然后返回一个对应的自定义加载器将变动后的目标文件加载至当前的python执行器中,使当前python执行器中的目标文件跟随目标文件的变动而实时更新变动。
59.在一些实施例中,在步骤s13和步骤s32在当前python执行器中更新变动后的目标文件之后,还需要将变动后的目标文件进行存储,存储到存储模块,以表示该变动后的目标文件已被加载(导入)。可以理解的是,后续在当前变动后的目标文件再次变动后,需将当前存储的变动后的目标文件进行清除,加载再次变动后的目标文件至当前的python执行器中,以进行再次更新。
60.在一具体实施例中,如图4所示,在启动python执行器时,会自动加载import_notebook.pth文件,并将该import_notebook.pth文件中的自定义查找器、自定定义加载器和能够实施对目标文件进行监控的监控器注册到当前的python执行器中,在需要导入目标文件时,优先使用自定义查找器查找目标文件,若找到目标文件,则返回对应的自定义加载器加载该目标文件至当前的python执行器中,实现文件的导入,并将该目标文件存储至存储模块(例如存储至sys.modules中)。
61.请继续参阅图4,在一实施方式中,先利用自定义查找器查找目标文件,若所有注册的自定义查找器均不能找到对应的目标文件,则利用系统查找器进行查找,若系统查找
器找到目标文件,则返回对应的系统加载器加载目标文件到当前的python执行器中,若系统查找器找不到目标文件,则进行报错(例如报告文件异常)。
62.请继续参阅图4,在一实施方式中,若监控器监测到目标文件存在变动,则清除存储模块中的目标文件,并返回对应的自定义加载器加载变动后的目标文件至当前的python执行器中,实现目标文件的实时更新。
63.应理解,上述实施方式中各步骤的序号的大小并不意味着执行顺序的先后,各过程的执行顺序应以其功能和内在逻辑确定,而不应对本发明实施例的实施过程构成任何限定。
64.请参阅图5,图5是本技术提供的电子设备一实施例的框架示意图。本实施方式中,电子设备50包括存储器51和处理器52。
65.处理器52还可以称为cpu(central processing unit,中央处理单元)。处理器52可能是一种集成电路芯片,具有信号的处理能力。处理器52还可以是通用处理器、数字信号处理器(dsp)、专用集成电路(asic)、现场可编程门阵列(fpga)或者其他可编程逻辑器件、分立门或者晶体管逻辑器件、分立硬件组件。通用处理器可以是微处理器或者该处理器52也可以是任何常规的处理器52等。
66.电子设备50中的存储器51用于存储处理器52运行所需的程序指令。
67.处理器52用于执行程序指令以实现上述方法中任一实施例及任意不冲突的组合所提供的方法。
68.请参阅图6,图6是本技术提供的计算机可读存储介质的框架示意图。本技术实施例的计算机可读存储介质60存储有程序指令61,该程序指令61被执行时实现上述方法中任一实施例以及任意不冲突的组合所提供的方法。其中,该程序指令61可以形成程序文件以软件产品的形式存储在上述计算机可读存储介质60中,以使得一台计算机设备(可以是个人计算机,服务器,或者网络设备等)执行本技术各个实施方式方法的全部或部分步骤。而前述的计算机可读存储介质60包括:u盘、移动硬盘、只读存储器(rom,read-only memory)、随机存取存储器(ram,random access memory)、磁碟或者光盘等各种可以存储程序代码的介质,或者是计算机、服务器、手机、平板等终端设备。
69.上述方案,在获取导入到当前python执行器中的目标文件后,将目标文件存储至存储模块,响应于目标文件存在变动,更新当前python执行器中的目标文件。故本技术方案在被导入到当前python执行器中的目标文件发生变动后,可使当前python执行器中的目标文件跟随目标文件的变动而实时更新变动,能够提高被修改文件在当前文件的更新效率。
70.可选的,可将编写的自定义查找器、自定义加载器和监控器编写进import_notebook.pth文件,整合成一个用于导入目标文件的包文件,其中,import_notebook.pth文件的文件内容为import import_notebook,并将该包文件安装到jupyter环境中,同时在jupyter环境中有其他python环境的情况下,将该包文件安装到对应的其他python环境中,进而使上述文件导入方法可用于不同的python环境中。
71.上文对各个实施例的描述倾向于强调各个实施例之间的不同之处,其相同或相似之处可以互相参考,为了简洁,本文不再赘述。
72.以上所述仅为本技术的实施方式,并非因此限制本技术的专利范围,凡是利用本技术说明书及附图内容所作的等效结构或等效流程变换,或直接或间接运用在其他相关的
技术领域,均同理包括在本技术的专利保护范围内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1