小批量误差数据的自动校正与分布拟合方法与流程
1.本发明属于航空生产领域,具体涉及一种基于anderson
–
darling检验和循环估计的小批量误差数据的自动校正与分布拟合方法。
背景技术:
2.作为工业体系的顶端,航空工业对产品质量的把控十分严格,产品外观测量值与理论值的误差数据的分布特征反应了制造过程的质量信息,是实现统计过程控制、优化和生产管理的基本依据。然而,由于测量方式不当和操作人员更换等因素,误差数据的记录值往往会偏移真实值,这尤其给小批量误差数据的统计分布推断带来了更大的挑战。为此,准确地对小批量误差数据进行自动校正,分析误差数据的统计分布特征具有重要意义。
3.目前,大部分文献如:《多变量统计过程控制在反浮选生产过程中的应用》、《融合scada数据的风电机组齿轮箱状态评估》、《平整过程在线监测和统计过程控制的研究与实践》和《基于典型数据集的数据预处理方法对比分析》,这些文件公开的内容主要都是在进行统计过程控制之前,会基于4分位法剔除异常数据,即将超出上下4分位数的数据从样本数据中剔除。这种方法适用于大样本的情况,对于小批量过程而言,样本量的进一步减少对分布的拟合不利,一种更合理的方法是通过数据校正的方法找到数据的真实值,从而准确获取数据的统计分布特征。然而,目前数据的预处理方法只局限于数据的正态化、标准化和归一化,其中正态化方法包括box-cox转换和johnson变换等,可以改善数据的正态性和对称性;标准化和归一化方法旨在通过数学运算将数据无量纲化。这些方法只适用于服从正态分布的情况,而现实的制造误差数据还可能服从截断正态分布、伽马分布或t分布等。
技术实现要素:
4.为了克服上述现有技术存在的问题,本发明提出了一种基于anderson
–
darling检验和循环估计的小批量误差数据的自动校正与分布拟合方法,构建不同连续分布(正态分布、截断正态分布、伽马分布、t分布)下的anderson
–
darling检验统计量,根据不同分布下检验统计量的p值确定误差数据的统计分布类型,基于该分布类型,采用循环估计将数据集随机划分为历史集和观测集,对观测集中的数据选取总体分布拟合p值最高的校正方式,循环选择不同的数据作为观测集,直至每个数据都得到了最优校正或p值达到收敛,完成对数据的自动校正。
5.为了实现上述发明,提供的技术方案如下:
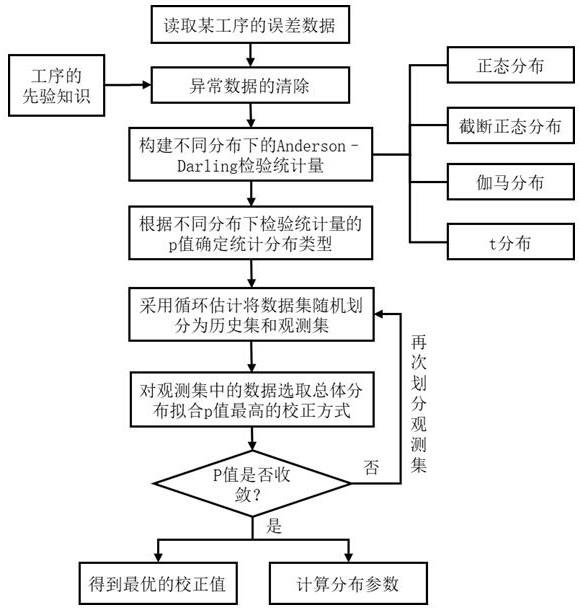
6.小批量误差数据的自动校正与分布拟合方法,
7.具体包括以下步骤:
8.步骤1:从记录表中读取某小批量生产产品同一特征的年度误差数据;
9.步骤2:对误差数据进行异常数据的清除,得到初始数据集d={xi,i=1,
…
,n};
10.步骤3:构建了正态分布、截断正态分布、伽马分布、t分布四个连续分布下的anderson
–
darling检验统计量;
11.步骤4:根据anderson
–
darling检验量a2的极限分布,构建了正态分布、截断正态分布、伽马分布、t分布四个连续分布下的anderson
–
darling检验统计量的p值,通过比较p值大小来确定误差数据的统计分布类型,p值越大表明分布拟合优度越高,即确定的分布类型为j
*
=max
j=1,2,3,4
pj;
12.步骤5:基于得到的分布类型j
*
,采用循环估计对每个数据进行自动校正;预先给定一个补偿值δ,并将数据集d随机打乱,划分为历史集d1和观测集d2;规定数据的校正策略,进行不停迭代,得到最终的校正数据;
13.步骤6:设定不同的补偿值δ重复步骤5,以找到最优的补偿值;在该补偿值下,得到最优校正后的数据集d
′
并采用极大似然估计求解分布j
*
的参数。
14.进一步地,所述步骤3中,为衡量真实数据分布与理论分布的拟合优度,构建了正态分布、截断正态分布、伽马分布、t分布四个连续分布下的anderson
–
darling检验统计量如下:
[0015][0016]
式中:代表第j个假设分布的anderson
–
darling检验统计量,用于衡量假设分布与数据真实分布的差距,越小表明真实数据越贴近假设的分布,n为样本的个数,fd(x)为样本的分布函数;
[0017]
正态分布、截断正态分布、伽马分布、t分布,这四种分布最贴合航空制造领域中误差数据的分布类型,fj(x)为第j个假设分布的理论分布函数:
[0018][0019][0020][0021][0022]
式中:γ代表伽马函数,μ,σ,a,b,α,β,v代表与分布相关的分布系数。
[0023]
进一步地,所述步骤4的具体方法如下:
[0024]
根据anderson
–
darl ing检验量a2的极限分布,通过的极限分布,通过构建四个分布的p值如下:
[0025][0026]
pj代表第j个假设分布的anderson
–
darling检验统计量的p值,p值是介于0到1之间的一个概率值,可以定性且直观的表示真实数据分布与理论分布的拟合优度,p值越大表
明越小,分布拟合优度越高,因此,可以通过比较p值大小来确定误差数据的统计分布类型,即确定的分布类型为j
*
=max
j=1,2,3,4
pj。
[0027]
进一步地,所述步骤5基于得到的分布类型j
*
,采用循环估计对每个数据进行自动校正。
[0028]
再进一步地,所述步骤5具体包括以下步骤:
[0029]
步骤501:预先给定一个补偿值δ,建议该补偿值设置为数据记录精度的整数倍;
[0030]
步骤502:将第r-1次循环校正后的数据集d
r-1
随机打乱,按照8:2的比例将其划分为历史集和观测集
[0031]
步骤503:数据校正策略有三种:减补偿值保持不变和加补偿值对观测集中的每个数据,将该数据与历史集合并为一个新的数据集,计算在分布类型j
*
下三种校正策略的p值,分别记为选取p值最高的校正方式对x进行校正,例如,若则对观测集中的其他所有数据重复该步骤,最终得到校正后的观测集
[0032]
步骤504:记第r次循环校正后的数据集为及其p值为pr;
[0033]
步骤505:比较pr与p
r-1
的大小,若差别忽略不计(p
r-p
r-1
《0.001)则结束校正;否则令r=r+1,重复步骤502-504。
[0034]
与现有技术相比,本发明的优点如下:
[0035]
本方法能够自动搜寻最优的校正值,适用于航空制造领域的各种小批量生产过程,可以快速并有效地弥补因测量方式不当或操作人员更换引起的数据偏差,促使数据集与数据的真实分布更加相近,同时为后续的统计过程控制与控制图的构建提供基础。
附图说明
[0036]
图1为自动校正流程框图。
[0037]
图2为原始数据在四个分布下的拟合情况。
[0038]
图3为不同补偿值下的校正后数据集的伽马分布p值。
[0039]
图4为最优补偿值下(δ=0.006)校正后数据集的伽马分布拟合情况。
[0040]
图5为伽马分布参数的最大似然估计。
具体实施方式
[0041]
为使本发明的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是为了解释本发明而非对本发明的限定。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
[0042]
以下结合附图和实例来说明本发明的具体实施方法,本发明不限于该实施例。
[0043]
实施例1
[0044]
如图1所示,小批量误差数据的自动校正与分布拟合方法,
[0045]
具体包括以下步骤:
[0046]
步骤1:从记录表中读取某小批量生产产品同一特征的年度误差数据;
[0047]
步骤2:利用生产工序的先验信息对误差数据进行异常数据的清除,清除不符合产品特性技术要求的数据(不合格品对应的数据),得到初始数据集d={xi,i=1,
…
,n};
[0048]
步骤3:由统计学基础知识可知,很多随机变量都是服从正态分布,例如测量误差、产品重量、人的身高等。所以生产现场一般默认误差数据服从正态分布,并在正态分布的背景下对数据进行分析。然而,由于测量方式不当和操作人员更换等因素,误差数据的记录值往往会偏移真实值,呈现出的数据不一定服从正态分布。经过现场数据实际验证,误差数据最有可能服从正态分布、截断正态分布、伽马分布、t分布这四种分布之一。为了能够更为准确地确定数据的实际分布,构建了正态分布、截断正态分布、伽马分布、t分布四个连续分布下的anderson
–
darling检验统计量;
[0049]
步骤4:根据anderson
–
darling检验量a2的极限分布,构建了正态分布、截断正态分布、伽马分布、t分布四个连续分布下的anderson
–
darling检验统计量的p值,通过比较p值大小来确定误差数据的统计分布类型,p值越大表明分布拟合优度越高,即确定的分布类型为j
*
=max
j=1,2,3,4
pj;
[0050]
步骤5:基于得到的分布类型j
*
,采用循环估计对每个数据进行自动校正;预先给定一个补偿值δ,并将数据集d随机打乱,划分为历史集d1和观测集d2;规定数据的校正策略,进行不停迭代,得到最终的校正数据;
[0051]
步骤6:设定不同的补偿值δ重复步骤5,以找到最优的补偿值;在该补偿值下,得到最优校正后的数据集d
′
并采用极大似然估计求解分布j
*
的参数。
[0052]
进一步地,所述步骤3中,为衡量真实数据分布与理论分布的拟合优度,构建了正态分布、截断正态分布、伽马分布、t分布四个连续分布下的anderson
–
darling检验统计量如下:
[0053][0054]
式中:代表第j个假设分布的anderson
–
darling检验统计量,用于衡量假设分布与数据真实分布的差距,越小表明真实数据越贴近假设的分布,n为样本的个数,fd(x)为样本的分布函数;
[0055]
正态分布、截断正态分布、伽马分布、t分布,这四种分布最贴合航空制造领域中误差数据的分布类型,fj(x)为第j个假设分布的理论分布函数:
[0056][0057][0058][0059]
[0060]
式中:γ代表伽马函数,μ,σ,a,b,α,β,v代表与分布相关的分布系数。
[0061]
进一步地,所述步骤4的具体方法如下:
[0062]
根据anderson
–
darl ing检验量a2的极限分布,通过的极限分布,通过构建四个分布的p值如下:
[0063][0064]
pj代表第j个假设分布的anderson
–
darling检验统计量的p值,p值是介于0到1之间的一个概率值,可以定性且直观的表示真实数据分布与理论分布的拟合优度,p值越大表明越小,分布拟合优度越高,因此,可以通过比较p值大小来确定误差数据的统计分布类型,即确定的分布类型为j
*
=max
j=1,2,3,4
pj。
[0065]
进一步地,所述步骤5基于得到的分布类型j
*
,采用循环估计对每个数据进行自动校正。该方法可以快速并有效地弥补因测量方式不当或操作人员更换引起的偏差,促使数据集与数据的真实分布更加相近。并且该方法适用于航空制造领域的各种小批量生产过程,能够准确地对小批量误差数据进行自动校正,而现有的方法更多地适用于大样本的情况。
[0066]
再进一步地,所述步骤5具体包括以下步骤:
[0067]
步骤501:预先给定一个补偿值δ,建议该补偿值设置为数据记录精度的整数倍;
[0068]
步骤502:将第r-1次循环校正后的数据集d
r-1
随机打乱,按照8:2的比例将其划分为历史集和观测集
[0069]
步骤503:数据校正策略有三种:减补偿值保持不变和加补偿值对观测集中的每个数据,将该数据与历史集合并为一个新的数据集,计算在分布类型j
*
下三种校正策略的p值,分别记为选取p值最高的校正方式对x进行校正,例如,若则对观测集中的其他所有数据重复该步骤,最终得到校正后的观测集
[0070]
步骤504:记第r次循环校正后的数据集为及其p值为pr;
[0071]
步骤505:比较pr与p
r-1
的大小,若差别忽略不计(p
r-p
r-1
《0.001)则结束校正;否则令r=r+1,重复步骤502-504。
[0072]
实施例2
[0073]
一种基于anderson
–
darling检验和循环估计的小批量误差数据的自动校正与分布拟合方法基于最贴合于航空制造领域的小批量生产过程的误差数据分布类型(正态分布、截断正态分布、伽马分布、t分布),构建了四个分布下的anderson
–
darling检验统计量,通过拟合优度检验,确定数据的分布类型。采用循环估计对每个数据进行自动校正,可以快速并有效地弥补因测量方式不当或操作人员更换引起的数据偏差,促使数据集与数据的真实分布更加相近,同时为后续的统计过程控制与控制图的构建提供基础。
[0074]
构建了最贴合于航空制造领域的小批量生产过程的误差数据分布类型(正态分布、截断正态分布、伽马分布、t分布)下的anderson
–
darling检验统计量。经过现场数据实际验证,误差数据最有可能服从正态分布、截断正态分布、伽马分布、t分布这四种分布之
一,而不是盲目地根据统计学基础知识,默认误差数据服从正态分布并进行分析。其原因在于生产现场可能因为测量方式不当和操作人员更换等因素,造成误差数据的记录值往往会偏移真实值,呈现出的数据不一定服从正态分布。
[0075]
方法适用于航空制造领域的小批量生产过程,通过循环估计的数据校正方法找到数据的真实值,从而准确获取数据的统计分布特征。目前,大部分文献会基于4分位法剔除异常数据,即将超出上下4分位数的数据从样本数据中剔除,这种方法适用于大样本的情况。对于航空制造领域的各种小批量过程而言,样本量的进一步减少对分布的拟合不利,一种更合理的方法是通过数据校正的方法找到数据的真实值,从而准确获取数据的统计分布特征。
[0076]
采用循环估计对每个数据进行自动校正。预先给定一个补偿值δ,并将数据集d随机打乱,划分为历史集d1和观测集d2。规定数据的三种校正策略,进行不停迭代,得到最终的校正数据。该方法可以快速并有效地弥补因测量方式不当或操作人员更换引起的偏差,促使数据集与数据的真实分布更加相近。
[0077]
一种小批量误差数据的自动校正与分布拟合方法,流程框架如图1所示,包括以下步骤:
[0078]
步骤1:从记录表中读取某小批量生产产品同一特征的年度误差数据;
[0079]
步骤2:利用生产工序的先验信息对误差数据进行异常数据的清除,得到初始数据集d={xi,i=1,
…
,n}。例如,为避免零件报废,某些加工工序只会允许尺寸的盈余,即要求误差数据一定为正数,此时可以删除极少数记录为负数的数据;
[0080]
步骤3:构建正态分布、截断正态分布、伽马分布、t分布四个连续分布下的anderson
–
darling检验统计量如下:
[0081][0082]
式中:代表第j个假设分布的anderson
–
darling检验统计量,它衡量假设分布与数据真实分布的差距,n为样本的个数,fd(x)为样本的分布函数,fj(x)为第j个假设分布的理论分布函数如下:
[0083][0084][0085][0086]
[0087]
式中:γ代表伽马函数,μ,σ,,a,b,α,β,v代表与分布相关的分布系数。
[0088]
步骤4:根据anderson
–
darling检验量a2的极限分布,可通过的极限分布,可通过计算四个分布的p值如下:
[0089][0090]
p-值越大表明分布拟合优度越高,通过比较p-值大小可确定误差数据的统计分布类型;
[0091]
步骤5:基于该分布类型,采用循环估计对每个数据进行自动校正。该方法可以快速并有效地弥补因测量方式不当或操作人员更换引起的偏差,促使数据集与数据的真实分布更加相近。
[0092]
所述步骤5包括以下步骤:
[0093]
步骤501:预先给定一个补偿值δ,建议该补偿值设置为数据记录精度的整数倍。
[0094]
步骤502:将第r-1次循环校正后的数据集d
r-1
随机打乱,按照8:2的比例将其划分为历史集和观测集
[0095]
步骤503:数据校正策略有三种:减补偿值保持不变和加补偿值对观测集中的每个数据,将该数据与历史集合并为一个新的数据集,计算在分布类型j
*
下三种校正策略的p值,分别记为选取p值最高的校正方式对x进行校正,例如,若则对观测集中的其他所有数据重复该步骤,最终得到校正后的观测集
[0096]
步骤504:记第r次循环校正后的数据集为及其p值为pr。
[0097]
步骤505:比较pr与p
r-1
的大小,若差别忽略不计(p
r-p
r-1
《0.001)则结束校正;否则令r=r+1,重复步骤502-504。
[0098]
步骤6:设定不同的补偿值δ重复步骤5,以找到最优的补偿值。在该补偿值下,得到最优校正后的数据集d
′
并采用极大似然估计求解分布参数。
[0099]
算例分析:
[0100]
选用四川省成都市某航空企业一年来数控车床加工的质量外圆特征的实测误差数据,该小批量数据集共60个。由于外圆误差不可能为负数,因此首先将两个负数剔除,得到剔除后的数据集d={xi,i=1,
…
,58},如下表1所示。
[0101]
表1原始数据集d
[0102]-0.010-0.0040000000.0010.0010.0010.0010.0010.0020.0020.0020.0020.0020.0020.0020.0020.0030.0030.0030.0030.0040.0040.0040.0040.0040.0050.0050.0050.0050.0050.0050.0060.0070.0070.0090.0100.0100.0100.0100.0100.0100.0110.0120.0120.0130.0150.0150.0150.0150.0160.0200.0200.0200.0200.030
[0103]
采用正态分布、截断正态分布、伽马分布、t分布四个连续分布对d进行分布拟合,
结果如图2所示,分别构建四个分布下的anderson
–
darling检验统计量并计算其p值,如下表2所示,其中伽马分布对应的p3=0.326最大,因此认为该数据集服从伽马分布。
[0104]
表2四个分布下anderson
–
darling检验统计量的p值
[0105][0106]
基于伽马分布,根据误差数据的精度0.0001的倍数设定补偿值δ=0.0001a,a=1,
…
,10。对于每个补偿值,采用循环估计对数据进行自动校正。即将数据集随机划分为历史集和观测集,对观测集中的数据选取总体分布拟合p值最高的校正方式,循环选择不同的数据作为观测集,直至每个数据都得到了最优校正或p值达到收敛,完成对数据的自动校正。计算不同补偿值下的校正后数据集的伽马分布p值,如图3所示,补偿值在0.002~0.006之间时p值较为稳定,δ=0.006时p值最高,因此最优补偿值为0.006。基于该补偿值,得到校正后数据集d
′
如下表3所示,经统计,共4个样本执行加补偿值策略,共20个样本执行保持不变策略,共24个样本执行减补偿值策略。
[0107]
表3δ=0.006时校正后数据集d
′
[0108]
删除删除0000.0010.0010.0010.0020.0020.0020.0020.0030.0030.0030.0040.0040.0040.0040.0050.0050.0050.0050.0050.0050.0060.0060.0060.0060.0070.0070.0070.0070.0070.0080.0090.0090.0100.0100.0100.0100.0100.0100.0100.0110.0120.0130.0150.0150.0150.0150.0150.0150.0170.0170.0200.0200.0250.0250.035
[0109]
对校正后据集d
′
进行伽马分布的拟合,结果如图4所示,其p值从原始的0.326增大到0.9133。最后,采用最大似然估计的方法估计伽马分布参数,结果如图5所示,即d
′
={x
′
|x
′
~gamma(1.257,0.0063)},该统计分布可用于后续的统计过程控制与质量监控等。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1