一种基于控制流图的代码错误自动检出方法
1.本发明属于代码错误自动检出技术领域,涉及一种基于控制流图的代码错误自动检出方法。
背景技术:
2.国外学者在20世纪70年代便出现了关于文本复制检测的相关研究,诸多学者们开始主要针对程序代码克隆复制检测技术进行研究。目前代码克隆技术主要有以下几类:
3.一、现有基于tree的代码查重技术:t.kamiya,s.kusumoto(2002)等人发现基于token的查重方法速度快,所需资源更少。但却无法检测所有类型的代码克隆。而基于树的查重方法可以检测所有类型的代码克隆,但它速度慢且需要大量计算资源。因此提出了一种基于树和基于token的方法相结合的高速,高精度代码查重方法,以提高检测代码克隆的效率和准确性。曾杰,贲可荣(2020)等人提出一种基于程序向量树的代码查重方法,通过实验分析发现,对于moderately type-3和type-4类型的表面相似程度较低的代码克隆而言,利用该方法进行检测具有明显优势,但是该方法目前只针对java程序,以及评测数据集bigclonebench只包含java程序,因此迁移到其他程序语言需要进一步提出针对性的二叉树生成规则。
4.二、基于图的代码查重技术:komondoor r,horwitz s(2001)介绍了使用程序依赖图pdg(program dependence graph)和程序切片来查找表示克隆的同构pdg子图。该方法可以找到不连续的代码克隆,对匹配语句进行了重新排序的克隆以及彼此交织的克隆。汪敏(2018)对传统的基pdg的代码查重技术进行优化,实现了一种基于机器学习的新型pdg的代码查重方法,该方法对于检测时间有明显的提升,但是进行pdg的子图同构判定时是首先将pdg的节点转化为一个类型进行匹配,这使得部分的语句的语义信息会损失,在克隆判定中可能会出现假阳性的结果。
5.三、基于度量的代码查重技术:kontogiannis k a,demori r(1996)等人提出了一种基于源代码度量动态编程算法,用于在两个代码片段之间找到最佳对齐方式,以及一种以抽象语言表示的抽象代码描述与实际源代码之间的统计匹配算法[5]。perumal a,kanmani s(2010)等人提出了一种用于查找相似代码块并量化其相似性的新技术。他们的技术可用于查找用户提供的相似度内的克隆簇,代码块集。它使用类型1,类型2的度量标准检测相似的克隆。
[0006]
综上,近年来代码查重方法引起了广泛国内外学者们的关注与重视,并取得了一定的研究成果。但绝大多数的代码查重技术仍停留在研究层面,并未发展到实际应用中。针对学生作业、竞赛提交代码,不仅仅需要依据代码查重技术对提交代码和正确代码进行比对,还需要判断代码具体出错位置。本专利对学生作业、竞赛的提交代码进行了研究,设计出一种基于控制流图的代码错误自动检出方法。
技术实现要素:
[0007]
本发明的目的就是提供一种基于控制流图的代码错误自动检出方法,能自动检出用户向在线评测系统提交的代码错误,方便用户定位错误位置。
[0008]
本发明具体包括如下步骤:
[0009]
步骤1、生成控制流图:
[0010]
设数据库中的待检测代码有n份,编号为1,2,3,
…
,n。在编译代码时,编号为i的代码生成对应的控制流图g[i],g[i]中会生成m+1个节点的第j(0≤j≤m)个节点为n[i][j],其对应的源代码为c[i][j];
[0011]
并通过编译器去除对代码逻辑不产生影响的节点并对单入单出的多个节点进行合并。
[0012]
步骤2、子图匹配:
[0013]
将待检测代码的控制流图g[i]与正确代码c[k]生成的控制流图g[k]进行子图同构和节点的匹配,若两个程序的控制流图最多相差一个节点并且通过简单的加边加点的操作后两图同构,则认为这两份控制流图是能匹配的。子图同构指的是给定两个图g=(v,e,u,v)和g'=(v',e',u',v'),s是g'的子图,如果存在一个函数f:v
→
v',且f是从g到s的同构,那么,称f是从g到g'的子图同构。经过子图同构算法之后,得到一个结构相似度的集合s,取s中的最大值s[k],表示代码i与k最为相似,即k=argmax(s[k]);
[0014]
步骤3、分支修正:
[0015]
在获得图同构的相关映射之后,直接进行后续的操作,由于在匹配过程中没有将节点的具体的代码内容加入考虑,一个节点的分支对应关系有可能发生颠倒,容易发生误判;
[0016]
因此进行分支修正,对于源控制流图的每一个分支的节点,将其与目标控制流图的分支节点使用基于字符的文本相似度计算进行相应的相似度检测,将相似度最高的两个节点定义为匹配关系,从而尽可能使得分支的顺序正确,降低错误检出的误报率。
[0017]
设正确的代码c[k]生成的控制流图中的分支节点有m+1个,编号为0,1,2,3,
…
,q。对于c[k]中的每一个分支节点n[k][j](0≤j≤q),将其与c[i]生成的控制流图中的分支节点集合n[i]中的所有分支节点进行lcs(最长公共子序列)距离计算。若n[k][j]与n[i]中p节点的相似度大于与n[i]中其他节点的相似度,认为k中的分支节点n[k][j]与i中的分支节点n[i][p]是匹配的。
[0018]
步骤4、以节点为单位进行相似度计算:
[0019]
采用编辑距离进行文本相似度比较,采用lcs(最长公共子序列)距离来定义编辑距离。lcs距离源字符串s的长度为l1,目标字符串t的长度为l2,s与t之间的lcs距离为el,那么可以将s与t之间的文本相似度similarity定义为:similarity=1-el/(l1+l2)。
[0020]
得到两份代码的匹配关系后,要判断两者节点内代码的相似度。将提交代码c[i]与正确代码c[k],即两份代码的源代码的所有节点按照节点匹配关系进行一次基于文本相似度的比较,得到的文本相似度集合t,若其中t[j]的数值小于阈值(根据需求人为设定),则认为代码c[i][j]处有错误。
[0021]
本发明通过发挥控制流图的特点,弥补了一些现有在线测评系统的短板。目前在线测评系统中大多只有代码检测抄袭系统,而没有代码错误自动检出系统,通过本系统能
帮助用快速定位自己程序的错误位置,从而加快编程效率。在教学活动中,减少教师为学生检查代码的时间,从而大大减轻教师的负担,将时间更多的用在教学任务上。
附图说明
[0022]
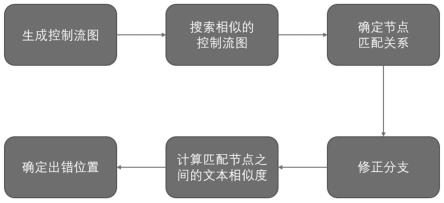
图1为本发明的整体过程流程图。
具体实施方式
[0023]
为了使本发明的目的、技术方案及优点更加清楚明白,以下将结合附图及实施例,对本发明进一步详细说明。
[0024]
如图1所示,一种基于控制流图的代码错误自动检出方法,具体为:根据提交代码生成控制流图;根据提交代码的控制流图与数据库中已有的代码进行比对,找到结构上最相似的代码;通过计算每个节点的代码相似度来判断该节点是否可能出错;通过找到数据库内与源代码逻辑相似的正确代码,从而进一步定位代码的错误位置。
[0025]
本实施例中选取的数据为共298名学生,所提交480道题的c语言代码。经过去重、移除如编译失败等无效代码,数据集共包括85,757份代码。将结果正确简称为ac,结果错误简称为wa。
[0026]
步骤一:如针对编号为299383的提交记录,它生成的控制流图代码如下:
[0027]
[0028]
[0029]
[0030][0031]
gcc(gnu compiler collection,gnu编译器套件)以“;;”开头的行描述了控制流图的结构,且gcc通过相关的优化操作,将部分不必要的点已经除掉了,如在编号为299383的提交记录中无用的节点1和7已被去除,节点6与5已被合并(控制流图(control flow graph,cfg)是描述程序的一种方法,它是编译器中使用的抽象数据结构。程序会去除对代码逻辑不产生影响的节点并对单入单出的多个节点进行合并)。
[0032]
步骤二:将该控制流图的结构和数据库中改题目下已有的正确代码的控制流图结构进行子图匹配,选取最相似的代码,本实施例中匹配到的是编号为52037的代码;
[0033]
步骤三:将各个对应的节点中的代码进行比对,若某节点的相似度低于一定阈值,此处为95%,则输出对应的信息。本实施例中信息如下:
[0034][0035]
步骤四:所有待检测代码同正确代码比较后。生成对应的json文件,提供一个便于解析的接口。
[0036]
步骤五:为了确定本方法确实有效,首先对本实施例中测试采用的数据集共包括85,757份代码进行人工检查。鉴于代码数量繁多,先将数据样本中的所有题目下提交的代码进行匹配,对于每道题目,当有20份代码匹配成功时停止匹配。综合考虑匹配时间与匹配率,取其中10道题目的200份代码进行分析。经过人工检查,发现经本方法检测后共有165份代码正确指出了错误所在的位置,比率为83%。可见本方法在极大多数情况下都是切实可用的。大多数情况下的错误提示都是由输出范围扩大而引起的,而出现这种情况的原因是我们将每一个控制流图的节点去进行比较计算,故错误提示会将范围定位到某个节点,而不是某一行代码,因此虽然提示范围扩大了,但提示的位置依然包含了实际代码错误位置。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1