一种基于规则前缀空间的在线数据包分类方法
1.本发明属于数据包分类领域,具体涉及一种基于规则前缀空间的在线数据包分类方法。
背景技术:
2.数据包分类的目标是根据给定的规则集,判断数据包匹配哪一条规则,这些规则往往由多个字段组成,常见的规则字段包括源ip地址、目的ip地址、源端口、目的端口、协议号等。
3.数据包分类是网络路由、防火墙等服务的关键组成部分,传统的数据包分类技术大多是离线的方法,即给定静态的规则集,建立一个支持高速数据包匹配的静态数据结构。但是随着软件定义网络(sdn)、网络功能虚拟化(nfv)等技术的发展,出现了弹性资源分配、实时迁移等新需求,这要求数据包分类使用在线的方法,即使用一个动态的数据结构,在进行高速数据包分类的同时,能够对规则进行快速更新。
4.现有的数据包分类方法主要可以分为两类:基于决策树的分类方法、基于元组空间的数据包分类方法。基于决策树的分类方法通过对规则中的某些字段进行均匀或非均匀切分,将规则分为多组分配到不同的子节点上。基于决策树的分类方法存在规则复制问题,即进行字段切分时,一条规则可能被划分到多个子节点,这一方面会导致内存空间使用增加,另一方面给规则更新带来困难。基于元组空间的数据包分类方法,根据规则中多个字段的匹配前缀空间将规则集分为多个规则分组,从而避免了规则复制,实现了快速更新;在进行数据包匹配时,基于元组空间的方法需要遍历所有规则分组,虽然有一些规则分组合并、基于优先级提前终止的优化方法,但是由于分组数量较大,数据包分类效率仍然较低。
技术实现要素:
5.本发明技术解决方案:克服现有技术的不足,提供一种基于规则前缀空间的在线数据包分类方法,用以解决当前数据包分类方法无法同时实现高速分类和规则更新的问题,提升了数据包匹配速率。
6.本发明具体技术方案如下:一种基于规则前缀空间的在线数据包分类方法,所述方法包括以下步骤:
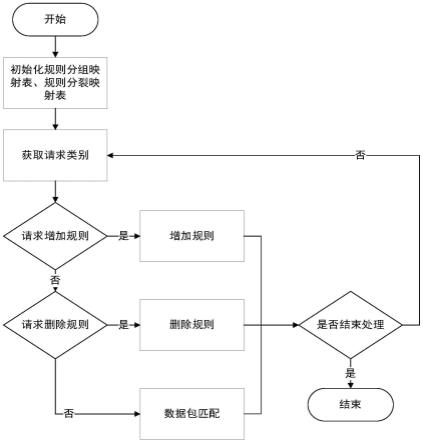
7.步骤1:初始化规则分组映射表和规则分裂映射表;规则分组映射表用于记录某条规则被分配到的规则分组;规则分裂映射表用于记录某条规则是否发生分裂;使用一个先进先出的请求队列,循环接收规则增添请求、规则删除请求、数据包匹配请求;
8.步骤2:对步骤1的规则增添请求进行处理,将规则添加到一个规则分组中,首先从已有的规则分组进行选择,使用规则前缀长度和规则分组的前缀长度,判断规则添加的可行性;当不可行时,对规则进行分裂,并使用规则优先级、规则分组优先级辅助选择规则分组;如果仍然不能添加该条规则时,则新创建一个规则分组,该规则分组的前缀长度的取值,在规则前缀空间的基础上进行放缩得到;
9.步骤3:对步骤1的规则删除请求进行处理,从规则分组中删除一条规则,根据规则分组映射表和规则分裂映射表,获取规则被分配到的规则分组信息、规则是否被分裂的信息;如果规则没有被分裂,则直接从规则分组删除规则,否则需要根据规则分裂信息,将分裂后形成的一组规则从规则分组中删除;
10.步骤4:对步骤1的数据包匹配请求进行处理,按照优先级顺序,对当前存在的规则分组进行遍历,获取该规则分组中与该数据包能够匹配的规则,记录其中最高优先级的规则,如果该最高优先级大于下一个需要访问的规则分组的优先级,则提前终止匹配操作,返回记录的规则。
11.本发明通过放缩规则前缀空间、引入优先级优化规则分组的建立,能够快速对数据包进行分类,获取数据包匹配的最高优先级的规则;同时本发明能够进行在线规则更新,使得规则更新、数据包匹配并发进行,提升了规则更新时的数据包匹配可用性。
12.进一步,所述步骤1中的具体实现如下:
13.(11)规则分组映射表的每个表项由规则的编号与指向规则分组的指针组成,每增加一条规则就在规则分组映射表中加入一条记录;规则分裂映射表的每个表项由规则的编号与该规则的分裂记录组成。两个表用于在规则更新时迅速找到需要处理的规则分组,减少访存和计算;
14.(12)循环接收请求,请求分为三种:向规则分组中添加一条规则、从规则分组中删除一条规则、对一个数据包进行规则匹配,其中前两种请求由用户触发,当网卡接收到一个数据包时,第三种请求被触发。当同时存在多个请求时,使用先来先服务的方式进行处理。
15.进一步,所述步骤2中的具体实现如下:
16.(21)解析规则,获取规则的匹配字段内容、规则前缀长度、规则优先级;遍历当前存在的规则分组,对每个规则分组,获取规则分组使用字段、规则分组前缀长度、规则分组的优先级;
17.(22)比较规则的前缀长度和规则分组的前缀长度,如果对于规则分组使用的每个字段,规则的前缀长度均大于或者等于规则分组的前缀长度,且规则的前缀长度与规则分组的前缀长度的差值之和,小于或者等于设置的阈值,那么计算规则在规则分组前缀下的哈希值,将规则添加到规则分组;
18.(23)如果规则没有被添加到规则分组,那么尝试对规则进行分裂:首先计算规则需要分裂的比特数,即对规则分组使用的每个字段,计算规则分组的前缀长度与规则的前缀长度的差值,取大于0的差值之和作为规则需要分裂的比特数,计算规则分裂的评分f=α(-2k+b)-β(max(p-p,0)),其中α,b,β是预先设定的参数,n取2的指数,用于限制规则分裂;α取1到5之间的整数;β取0到1之间的小数,k为规则需要分裂的比特数,p为规则的优先级,p为规则分组的优先级;
19.(24)如果f》0,则将规则分裂为2k条,在规则分裂映射表中添加记录,依次将所有规则加入到规则分组中,修改规则分组映射表;如果f≤0,则新建立一个规则分组:在规则前缀空间的基础上进行采样,选择与当前已有的规则分组差别最大的一个采样值作为新建立的规则分组的前缀长度,将规则添加到该新建规则分组中;
20.(25)如果规则优先级大于或等于该规则被添加到的规则分组的优先级,则对所有规则分组按照优先级重新排序。
21.所述步骤3中的具体实现如下:
22.(31)在规则分组映射表查询该规则被分配到的规则分组,在规则分裂映射表查询该规则的分裂记录,从两个表删除该规则相关记录;
23.(32)如果该规则没有被分裂,那么从规则分组删除该规则;如果该规则发生了分裂,那么对于分裂记录中的每一条子规则都进行一次规则删除操作。
24.所述步骤4中的具体实现如下:
25.(41)对当前已存在的规则分组按照优先级顺序进行遍历,获取规则分组使用的字段信息,计算数据包在这些字段上的哈希值,通过规则分组维护的哈希表找到对应的规则链表,得到匹配到的最高优先级的规则。
26.(42)记录匹配规则的最高优先级,如果该优先级小于下一个规则分组的优先级,那么继续遍历下一个规则分组;如果该优先级大于下一个规则分组的优先级,则提前终止匹配,返回当前记录的最高优先级规则的编号。
27.本发明与现有技术相比的有益效果如下:
28.(1)通过对规则前缀空间的放缩,减少了规则分组数量;通过引入优先级进行规则分组优化,使得高优先级规则主要集中在靠前的规则分组,从而在匹配数据包时能够提前结束匹配。在保证规则更新性能的同时,提升了数据包匹配速率。
29.(2)本发明能够用于优化软件定义网络系统(ovs、vpp)的数据包分类算法,能够在进行高速数据包匹配的同时进行在线规则更新,提升软件定义网络系统的数据包交换性能。
30.本发明通过放缩规则前缀空间、引入优先级优化规则分组的建立,能够快速对数据包进行分类,获取数据包匹配的最高优先级的规则;同时本发明能够进行在线规则更新,使得规则更新、数据包匹配并发进行,提升了规则更新时的数据包匹配可用性。
附图说明
31.图1是方法总体流程图;
32.图2是规则增加流程图;
33.图3是规则删除流程图;
34.图4是数据包匹配流程图;
35.图5是数据包匹配时间比较;
36.图6是规则更新时间比较。
具体实施方式
37.下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整的描述,显然,所描述的实施例仅为本发明的一部分实施例,而不是全部的实施例,基于本发明中的实施例,本领域的普通技术人员在不付出创造性劳动的前提下所获得的所有其他实施例,都属于本发明的保护范围。
38.表1规则示例表
[0039][0040][0041]
如图1所示,本发明的一种基于规则前缀空间的在线数据包分类方法,包括:
[0042]
步骤1、创建规则分组映射表、规则分裂映射表,循环接收请求;
[0043]
11)创建所述规则分组映射表,该表的每个表项由规则的编号与指向规则分组的指针组成;规则分组映射表初始化为空,每增加一条规则就在规则分组映射表中加入一条记录,从而能够在规则更新时快速找到需要处理的规则分组;
[0044]
12)创建所述规则分裂映射表,该表的每个表项由规则的编号与该规则的分裂记录组成;该规则分裂映射表初始化为空,每增加一条被分裂的规则就在规则分裂映射表中加入一条记录,从而能够在删除被分裂的规则时,减少重复的计算;
[0045]
13)规则分组映射表、规则分裂映射表通过规则编号可以快速索引到一个规则分组,规则分组是用于保存规则的数据结构,每个规则分组在创建时需要指定其使用的规则字段,以及这些字段使用的前缀长度,每个规则分组维护一个哈希表,其中key为规则的指定字段的哈希值,value为规则链表,规则链表初始化为空,用于保存具体的规则信息;
[0046]
14)使用一个先进先出的请求队列,循环接收请求,请求分为三种:向规则分组中添加一条规则、从规则分组中删除一条规则、对一个数据包进行规则匹配。其中前两种请求由用户触发,当网卡接收到一个数据包时,第三种请求被触发。当同时存在多个请求时,使用先来先服务的方式进行处理。当需要处理的请求是向规则分组中添加一条规则时,转到步骤2;当需要处理的请求是从规则分组中删除一条规则时,转到步骤3;当需要处理的请求是对一个数据包进行规则匹配时,转到步骤4。
[0047]
步骤2、向规则分组中添加一条规则,即新创建一个规则分组或者选择一个已有的规则分组,将该规则加入到规则分组对应的规则链表中,并在规则分组映射表、规则分裂映射表进行相应的记录修改。
[0048]
具体包含以下步骤:
[0049]
21)解析规则,获取规则匹配字段的内容s=(s1,s2……
sn),规则的前缀长度l=(l1,l2……
ln)和规则的优先级(p);
[0050]
22)遍历当前已经存在的规则分组,获取规则分组使用的字段信息i=(i1,i2,
……im
),即使用了m(m≤n)个字段,im(im∈{1,2
……
n})为使用的第m个字段在规则匹配字段的索引、规则分组前缀长度l=(l1,l2……
lm),l是规则的前缀长度,由人为设置一条规则时给出;l是规则分组的前缀长度,在创建一个分组时给出,规则分组的优先级p,其值为规则分组中所有规则的最高优先级;
[0051]
23)比较规则的前缀长度l和规则分组的前缀长度l,如果满足下述两个公式,则转到步骤24),否则转到步骤25);
[0052]
li≥li,对于规则分组使用的每个字段,规则的前缀长度均大于或者等于规则分组的前缀长度;
[0053]
∑
i∈i
l
i-li≤thresh,对于规则分组使用的每个字段,计算规则的前缀长度与规则分组的前缀长度的差值,对差值求和,其结果小于或者等于设置的阈值thresh;
[0054]
24)计算规则的哈希值,规则有多个字段,但只有规则分组使用的字段(i=(i1,i2,
……im
))才参与哈希值的计算,且每个字段根据规则分组的前缀长度进行截断(例如对于编号为im的字段,为该字段的内容,lm为规则分组中该字段的前缀长度,对该字段取使用lm截断,得到),最后得到的哈希值为根据该哈希值从规则分组维护的哈希表中找到对应的规则链表,将规则加入到该规则链表中,并将该规则的记录添加到规则分组映射表中,转到步骤28);
[0055]
25)使用下述公式计算是否进行规则分裂,其中α,b,β是预先设定的参数。b取2的指数,用于限制规则分裂;α取一个较小的整数;β取0到1之间的小数,k为规则需要分裂的比特数,p为规则的优先级,p为规则分组的优先级。通过进行规则分裂,能够将高优先级的规则加入到高优先级的规则分组,从而能够提升之后的数据包分类速率;
[0056]
k=∑
i∈i
max(l
i-li,0),对于规则分组使用的每个字段,计算规则分组的前缀长度与规则的前缀长度的差值,取与0相比的较大值,k为这些较大值的和;
[0057]
f=α(-2k+b)-β(max(p-p,0))
[0058]
f表示规则进行分裂的评分,当f》0时,转到步骤26),否则检查所有当前已存在的规则分组的遍历情况:如果遍历结束,则转到步骤27),否则转到步骤22)继续遍历操作;
[0059]
26)将规则分裂为2k条,在规则分裂映射表中添加记录,依次将所有规则加入规则分组中,修改规则分组映射表,转到步骤28);
[0060]
27)新建立一个规则分组,当前规则的前缀长度为l=(l1,l2……
ln),ln表示第n个字段的前缀长度,按下述公式计算规则分组的前缀长度的采样区间[rl1,rl2];
[0061]
rl1=l;rl2=(max(l
1-2,0),max(l
2-2,0),
…
,max(l
n-2,0));
[0062]
在采样区间采样得到待选分组前缀长度r,按照如下公式计算选择的规则分组前缀长度为其中n为已建立的规则分组的数量,li为已建立的第i个规则分组的前缀长度;
[0063][0064]
最后建立新的规则分组,将规则加入到该分组中,并将该规则的记录添加到规则分组映射表中;
[0065]
28)所有规则分组按照优先级重新排序,结束步骤2,转到步骤14),处理下一个请求。
[0066]
步骤3、从规则分组中删除一条规则,即首先找到该条规则所在的规则分组,然后计算哈希值,根据规则分组维护的哈希表找到对应的规则链表,从规则链表中删除该条规则;
[0067]
具体包含以下步骤:
1111-0000 0111 1111 1111),其前6位是固定的,为了能够使用前缀表达,可以将其放缩为(0000 0100 0000 0000-0000 0111 1111 1111),此时前缀长度为6。
[0085]
s=(s1,s2……
s4)=(10.218.234.1,10.4.241.0,4.0,0.0)
[0086]
l=(l1,l2……
l4)=(24,31,6,0)
[0087]
22)遍历当前已经存在的规则分组,假设获取分组使用的字段信息i=(i1,i2)=(1,2)、规则分组的前缀长度l=(l1,l2)=(16,16)、该规则分组的优先级(p,其值为规则分组中所有规则的最高优先级):
[0088]
23)比较规则的前缀长度l和规则分组的前缀长度l,如果对于规则分组使用的每个字段,规则的前缀长度均大于或者等于规则分组的前缀长度,且对于规则分组使用的每个字段,规则的前缀长度与规则分组的前缀长度的差值之和小于16,则转到步骤24),否则转到步骤25)
[0089]
24)计算这里的哈希函数使用cuckoo hash。根据该哈希值从规则分组维护的哈希表中找到对应的规则链表,将规则加入到该规则链表中,并将该规则的记录添加到规则分组映射表中,转到步骤28)
[0090]
25)使用下述公式计算是否可以进行规则分裂,其中α=β=1,n=8是预先设定的参数,k为当前规则需要分裂的比特数,p为规则的优先级,p为规则分组的优先级。当f》0时,转到步骤26),否则检查所有当前已存在的规则分组的遍历情况:如果遍历结束,则转到步骤27),否则转到步骤22)继续遍历操作。
[0091]
k=∑
i∈i
max(l
i-li,0),f=α(-2k+b)-β(max(p-p,0))
[0092]
26)假设当前规则分组前缀长度为l=(l1,l2)=(25,32),那么可以计算k=(25-24)+(32-31)=2,将规则分裂为22=4条,具体如表2所示,在规则分裂映射表中添加记录,依次将所有规则加入到该规则分组中,修改规则分组映射表、规则分裂映射表,转到步骤28)
[0093]
表2规则r5分裂结果表
[0094]
规则源ip地址目的ip地址源端口目的端口优先级r5-110.218.234.1/2510.4.241.0/301039:20470:655355r5-210.218.234.129/2510.4.241.128/301039:20470:655355r5-310.218.234.1/2510.4.241.128/301039:20470:655355r5-410.218.234.129/2510.4.241.0/301039:20470:655355
[0095]
27)新建立一个规则分组,当前处理的规则前缀长度为l=(l1,l2……
ln),按下述公式计算规则分组的前缀长度的采样区间[rl1,rl2]
[0096]
rl1=l;rl2=(max(l
1-2,0),max(l
2-2,0),
…
,max(l
n-2,0))
[0097]
以平均采样为例,待选规则分组的前缀长度r∈{rl1,rl2,(rl1+rl2)/2},按照如下公式计算规则分组前缀长度为其中li为现有的规则分组的前缀长度。最后建立新的规则分组,将规则加入到该分组中,并将该规则的记录添加到规则分组映射表中;
[0098]
[0099]
28)所有规则分组按照优先级重新排序,结束步骤2,转到步骤13),处理下一个请求。
[0100]
3、从规则分组中删除一条规则,如图3所示,具体包含以下步骤:
[0101]
31)获取待删除规则的匹配字段的内容,从规则分组映射表获得该规则映射到的规则分组,从该表中删除记录,获取规则分组使用的字段信息、前缀长度;
[0102]
32)访问规则分裂映射表,如果该规则被分裂,转到步骤33),否则计算规则的哈希值,找到对应的规则链表,从中删除该规则,转到步骤34);
[0103]
33)从规则分裂映射表中读取该规则分裂后形成的一组规则分裂记录,遍历其中的每条规则,计算哈希值,从规则分组中删除规则,并从规则分裂映射表中删除记录,转到步骤34);
[0104]
34)如果被删除的规则是该规则分组中优先级的最高的规则,对所有规则分组按照最高优先级重新排序。结束步骤3,转到步骤13),处理下一个请求。
[0105]
4、对一个数据包进行规则匹配,需要对规则分组按照优先级顺序依次进行访问,最后得到该数据包匹配的最高优先级的规则的编号,流程如图4所示,具体包含以下步骤:
[0106]
41)获取规则分组使用的字段信息,计算数据包在这些字段上的哈希值,通过规则分组维护的哈希表找到对应的规则链表,遍历该规则链表,如果匹配,那么返回匹配到的最高优先级的规则;
[0107]
42)记录所有匹配规则的最高优先级,如果该优先级小于下一个规则分组的优先级,那么转到步骤41);如果该优先级大于下一个规则分组的优先级,则提前终止匹配,返回当前记录的最高优先级规则的编号,结束步骤4,转到步骤13),处理下一个请求。
[0108]
将本发明与其它方法比较,使用开源测试集classbench进行测试,使用了acl1、acl2、fw1、ipc1四个测试集,如图5、图6所示:本发明在仅增加少量规则更新开销的前提下,实现了10%-40%的数据包匹配性能的提升,在保证规则更新性能的同时,提升了数据包匹配速率。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1