面向长文本的稠密信息检索方法与系统
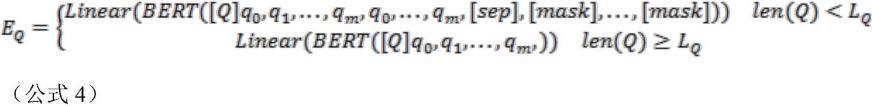
1.本发明涉及信息检索方法技术领域,特别涉及面向长文本的稠密信息检索方法与系统。
背景技术:
2.最近几年,一些大规模的预训练语言模型(如elmo、openai gpt和bert等)的出现不断刷新了自然语言处理中各种任务的评价结果。这些预训练语言模型可以通过微调的方式很好地估计文本之间的相关性。其中,bert是预训练语言模型最具代表性的一种。在bert出现不到一年的时间里,基于bert的许多排序模型已经在各种检索基准上取得了最先进的结果。这受益于它计算两个文本对的深度上下文的语义交互来获取文本之间的语义匹配,弥合文档和查询之间普遍存在的词汇不匹配问题。bert检索器进行交互式语义匹配时的输入是一个问题和每个检索到的文档的连接,即:“[cls]query[sep]document[sep]”。由cls处得到每个段落和查询的相关的概率。由于bert采用基于转换器(transformer)的架构,它的内存和时间消耗会随着输入长度的增加呈平方指数增长,因此bert模型的设计限制了文本的输入长度为最多512个词项。
[0003]
目前对于长文本信息检索的解决方案都一些共同的特点:均采用基于交互式语义匹配的方式对长文本进行检索,对于每个临时的查询,均要计算与每个文档甚至每一段的交互,存在耗时长、代价高的问题。通常,在真实的场景中,用户等待一个查询的时间超过100ms将会影响用户体验。检索文档数量多、信息量大、重复性高的工作,例如大批论文的查重工作中,现有技术耗时长、代价高等问题会更为明显的体现到工期和成本上。
[0004]
中国专利公开了《长文本分类方法、系统、电子设备、计算机可读存储介质》,其专利号为cn202110815723.7,该申请公开了将长文本通过文本规律(段落类型)进行分割后,满足bert输入字节要求的方法。该方法的问题在于,文本的分割方式本身就会引入大量的数据偏见,类似方法产生的数据偏见基本取决于被选择理论的合理程度,而该理论就会直接影响模型的判断方式。因此,类似方法在实用时取得的结果难以获得认可,当然,该方法在标准化文档中的实用性是很高的。
技术实现要素:
[0005]
为了克服现有技术检索耗时长、代价高,以及现有的检索方案语句分割后结果正确性不足的问题,提供了一种面向长文本的稠密信息检索方法与系统,其中面向长文本的稠密信息检索方法为:s1:利用符合bert模型输入要求长度的文本,配合查询相关性训练样本,训练模型。
[0006]
符合bert模型输入要求长度的文本长度小于或等于512字符。
[0007]
查询相关性训练样本采用三元组的形式:《q
′
,passage
+
,passage-》
其中passage
+
表示人工标记为与查询相关的文本,passage-表示排名在前n篇但不是标注为相关的文本。在该模型中,passage
+
为正例,passage-为负例。
[0008]
s2:将被检索文本,通过训练好的模型,得到分段式上下文编码表示将这些长文本进行切割,切割后的文本长度小于512。分别输入步骤1训练好的bert模型,得到文本的分段的编码表示。
[0009]
s3:将查询文本,通过训练好的模型,得到查询的bert编码表示s4:将查询的编码表示与长文档的编码表示进行交互,得到查询结果。
[0010]
作为优选,s2中还包括s2.2在进行向量压缩。
[0011]
将得到bert的最后一层的隐向量压缩后进行拼接后按文档编号依次存入每篇文档的表示。文档d的表示为ed的计算方式如下:其中,ed的第一维大小为k
×
ld,表示k个段落的总长度。ed的第二维为dim,表示每个词向量压缩后的维数(压缩之前为768)。pi代表切分后的第i个段落pi∈d,i∈{1,2,..,k}。tok
i,j
表示文档d的第i个段落的第j个词的向量表示。
[0012]
同样地,当一篇文档的长度len(d)未超过ld时,使用[mask]填充至长度为ld。文档表示的过程为:表示的过程为:其中,toki表示文档中的第i个词的向量表示。
[0013]
对应的,s3中还包括将查询语句通过线性层进行相同压缩的步骤,s3.1,将该查询语句向量通过一个线性层进行压缩,得到查询的编码表示:对于bert的输出,再通过一个线性层进行压缩。得到查询q的表示为eq,其计算方式为:其中,eq的大小为lq×
din。其中dim为每个词向量压缩后的维数(压缩之前为768)。
[0014]
s2与s3中的向量压缩方法,使运算时占用的内存减少。因需要的服务器内存大小是限制产品实际应用的重要因素,该方法能节约成本,降低对服务器的要求,提供经济效益。
[0015]
作为优选,s2还包括对该长文本编码表示进行离线存储。
[0016]
对应的,s4中,查询的编码表示与长文档的编码表示进行交互的过程,还包括从离线存储的数据中调出s2中离线存储的长文本编码表示。
[0017]
离线计算可以减少在查询时对文档编码表示的运行时间,但由于是长文本的表示的每个词嵌入的维数相当大(例如,在bert-base中每个token有768个浮点值),现有技术会
占用大量的内存,难以得到应用。
[0018]
结合s2,s3的向量压缩方法,该方案降低了离线存储的数据大小,降低了硬件需求,使该模型的离线使用硬件成本降低,并且降低了内存的占用率,提高了该模型的工作时间效率,有效利用现有的算力与内存。
[0019]
作为优选,s2中,将这些长文本进行切割时,对于一个文档d,文档长度为len(d)。设切分的大小为ld,如果文档的长度超过ld,将对文档进行切分。对于长度未超过ld的文本,则使用特殊标记[mask]进行填充。假设一篇文档的长度len(d)超过了ld,则将文档以切分为一系列ld的长度的段落,记为d={p1,p2,...,pk}。其中pi代表切分后的第i个段落pi∈d,i∈{1,2,..,k}。tok
i,j
表示文档d的第i个段落的第j个词的向量表示。对于每个段落输入的开始使用[d]标记。
[0020]
长度为ld片段的文本的表示为:长度小于ld片段的文本的表示为:[d],tok1,tok2,...,tok
len(d)
,[sep],[mask],...,[mask]对该文本通过一个标准化过程,将长度不足的文本,通过填充特殊标记[mask],使得到的所有切割后的长文本长度都相同。该方案可以很好的适应transformer网络,得到更准确的结果。
[0021]
填充特殊标记[mask]的标准化过程,使向量压缩后的结果可控,在减少每个向量维度的同时,因每个段落长度相等,词向量的关系相同,所以在压缩后保持了整体段落语义结构。该压缩方法损失的细节基本不影响查询任务,反而使查询需要的信息更加清洁,减少了模型过拟合的风险。
[0022]
作为优选,s3.1中,得到查询语句的bert编码表示具体为首先将查询中的查询词进行分解,并将这些查询词分别记为q1,q2,...,qm。其中输入的开始位置用[q]标记。由于查询的长度通常比文档的长度短的多,因此查询可能缺失某些信息,造成查询和文档之间的匹配困难。然而,查询扩展通过补充查询缺失信息从而更好地找到相关文档
[94]
。本文设计了一种查询扩展策略:设查询的最大长度为lq,对于不足lq的查询,使用一种查询扩展策略,重复1次输入查询的词项,并在结束位置用[sep]表示,剩下不足lq的位置用特殊标记[mask]填充,直至长度达到lq。对于长度超过lq的查询,本文将输入查询的前lq个词项。对于超过lq但是不足bert的输入长度的部分,将使用特殊标记[mask]进行填充。
[0023]
作为优选,s4中查询的编码表示与长文档的编码表示进行交互的过程,包括s4.1:得到每个长文档编码表示片段中与每一个查询词向量余弦相似度最相近的词向量。
[0024]
该细粒度模型得到了片段中与查询值相似度最高的所有词。
[0025]
s4.2:计算片段的表示,并计算查询与单个片段表示的匹配值s4.3:计算文档的总得分。
[0026]
进一步的,s4.2中片段的表示的具体计算方式为:将s4.1种最相近的词向量的平均值作为片段的表示,取查询词项的平均词嵌入的
表示作为查询的表示,查询与单个片段的语义匹配值的计算方式为:其中,是文档的词向量的子集,表示与每个查询的词向量最相近的词向量的集合。eq表示q中查询词q的向量表示,em为文档d中与查询的词向量eq的余弦相似度最大的词项的向量表示。
[0027]
应用此方法从长文档中抽取了最可能相似查询对象的句子,并通过抽取出的编码表示与查询的编码表示计算匹配值。该方法更注重于抽取语义结构相关性,准确度更高,更符合语言结构。
[0028]
配合s2与s3中的向量压缩方法,规避了该压缩方法损失词汇语义细节的弊端,突出抽取语义结构的相关性,使压缩造成的损失对结果的影响更小,数据处理的结果更符合查询要求。
[0029]
进一步的,s4.3中文档总得分的具体计算方式为:计算文档d的最终得分,取查询与文档各个片段得分的最大值作为文档的语义相关性得分,计算方式如下:其中,d={p1,p2,...,pk},d中的片段pi∈d,i∈{1,2,..,k}。
[0030]
模型在短文本数据上训练时使用的损失函数如下:其中,y(q,p)是段落和查询的相关性标签。score(q,p)表示文档d的最终得分。
[0031]
在模型的训练过程中,当效果差的时候学习速度比较快,在效果好的时候学习速度变慢,有利于更快地找到全局最优值。同时,因为该损失函数采用了类间竞争机制,更擅长于学习不同分类间的信息。
[0032]
该方案的有益效果是,免去了一般方法调整模型结构(如按照某些方式予以拆分)以适应长文本的复杂编码操作,更适合现代追求高效率和更精确的语义匹配的检索需求。其数据处理不存在人为拆分存在的偏见,有助于保证最终结果的有效性,并使用正相关与负相关的损失函数,提高微调后模型的辨识能力。通过压缩数据得到更小的存储、内存需求,并提高了处理速度。
[0033]
本发明还提供了一种面向长文本的稠密信息检索系统,该系统包括交互端,服务器,存储介质。
[0034]
该系统部署具体为:通过面向长文本的稠密信息检索方法中s1对bert语义模型进行训练,然后将被检索用的大量长文本,通过面向长文本的稠密信息检索方法中s1,转换后在存储介质中离线存储。
[0035]
该系统的检索过程具体为:通过交互端输入查询语句,并限定被检索的长文本的选取范围,服务器接收到查询后,将查询语句通过面向长文本的稠密信息检索方法中s3进行转换,然后服务器从存储介质中,有顺序的分批调取被选取范围的长文本的表示,通过面
向长文本的稠密信息检索方法中s4得出查询结果。
[0036]
作为优选,该存储介质使用云存储,该系统从不同云服务器中分批调取长文本表示,适合大规模部署。该步骤通过压缩优化,减少了数据大小,压缩后的数据量降低,传输成本低,相对于现有技术更适合网络部署。因线性压缩后的向量表示几乎完全无法辨认出内容,该系统还提高了安全性,避免了在第三方服务器存储文本数据的风险,也降低了黑客通过截取检索数据,解析检索内容的可能性。该方案的有益效果是,提供了一种高效的稠密信息检索系统,并利用高可用性,高可扩展性的存储介质,使该系统可以从需求出发进行各种规模的快速部署。
具体实施方式
[0038]
实施例1本发明实施例包括以下步骤:s1:利用符合bert模型输入要求长度的文本,配合查询相关性训练样本,训练模型。
[0039]
符合bert模型输入要求长度的文本长度小于或等于512字符。
[0040]
本实施例选用的训练用数据集为ms macro中的三元组形式数据。
[0041]
查询相关性训练样本采用三元组的形式:《q
′
,passage
+
,passage-》其中passage
+
表示人工标记为与查询相关的文本,passage-表示排名在前n篇但不是标注为相关的文本。在该模型中,passage
+
为正例,passage-为负例,在本实施例中n的取值在50-500之间,而样本中passage-的数量控制在100以下。
[0042]
该对比学习的方法,给出了负例和正例分别给予模型,提高了模型的辨识能力,使微调后的模型更精确。
[0043]
s2:将被检索文本,通过训练好的模型,得到分段式上下文编码表示,并对该编码表示进行存储,包括:s2.1将这些长文本进行切割,切割后的文本长度小于512。分别输入步骤1训练好的bert模型,得到文本的分段的编码表示。在本实施例中,因为还要一些标识要输入,会占用一些长度,比如[d]、[sep]。因此实际切割后的文本长度约为500。
[0044]
将这些长文本进行切割时,对于一个文档d,文档长度为len(d)。设切分的大小为ld,如果文档的长度超过ld,将对文档进行切分。对于长度未超过ld的文本,则使用特殊标记[mask]进行填充。假设一篇文档的长度len(d)超过了ld,则将文档以切分为一系列ld的长度的段落,记为d={p1,p2,...,pk}。其中pi代表切分后的第i个段落pi∈d,i∈{1,2,..,k}。tok
i,j
表示文档d的第i个段落的第j个词的向量表示。对于每个段落输入的开始使用[d]标记。
[0045]
长度为ld片段的文本的表示为:长度小于ld片段的文本的表示为:[d],tok1,tok2,...,tok
len(d)
,[sep],[mask],...,[mask]对该文本通过一个标准化过程,将长度不足的文本,通过填充特殊标记[mask],使
得到的所有切割后的长文本长度都相同。该方案可以很好的适应transformer网络,得到更准确的结果。
[0046]
s2.2在进行向量压缩后,对该编码表示进行离线存储。
[0047]
将得到bert的最后一层的隐向量压缩后进行拼接后按文档编号依次存入每篇文档的表示。文档d的表示为ed的计算方式如下:其中,ed的第一维大小为k
×
ld,表示k个段落的总长度。ed的第二维为dim,表示每个词向量压缩后的维数(压缩之前为768)。pi代表切分后的第i个段落pi∈d,i∈{1,2,..,k}。tok
i,j
表示文档d的第i个段落的第j个词的向量表示。
[0048]
同样地,当一篇文档的长度len(d)未超过ld时,使用[mask]填充至长度为ld。文档表示的过程为:表示的过程为:其中,toki表示文档中的第i个词的向量表示。
[0049]
s3:将查询文本,通过训练好的模型,得到查询的编码表示s3.1,得到查询语句的bert编码表示,对于查询q:“buy apples on iphone”,首先将查询句子分词为“buy”、“apples”、“on”和“iphone”,并将这些查询词分别记为q1,q2,...,qm。其中输入的开始位置用[q]标记。由于查询的长度通常比文档的长度短的多,因此查询可能缺失某些信息,造成查询和文档之间的匹配困难。然而,查询扩展通过补充查询缺失信息从而更好地找到相关文档
[94]
。本文设计了一种查询扩展策略:设查询的最大长度为lq,对于不足lq的查询,使用一种查询扩展策略,重复1次输入查询的词项,并在结束位置用[sep]表示,剩下不足lq的位置用特殊标记[mask]填充,直至长度达到lq。对于长度超过lq的查询,本文将输入查询的前lq个词项。对于超过lq但是不足bert的输入长度的部分,将使用特殊标记[mask]进行填充。
[0050]
s3.2,将该查询语句向量通过一个线性层进行压缩,得到查询的编码表示:对于bert的输出,再通过一个线性层进行压缩。得到查询q的表示为eq,其计算方式为:其中,eq的大小为lq×
dim。其中dim为每个词向量压缩后的维数(压缩之前为768)。
[0051]
s4:将查询的编码表示与长文档的编码表示进行交互,得到查询结果。
[0052]
每个新查询进入时,则从系统提取出s2得出的降维后的离线存储文本表示,与s3得出的查询文本表示进行交互计算。
[0053]
查询的编码表示与长文档的编码表示进行交互的过程,具体为s4.1:得到每个长文档编码表示片段中与每一个查询词向量余弦相似度最相近的词向量。
[0054]
该细粒度模型得到了片段中与查询值相似度最高的所有词。
[0055]
s4.2:取这些词向量的平均值作为片段的表示,取查询词项的平均词嵌入的表示作为查询的表示,查询与单个片段的语义匹配值的计算方式为:其中,是文档的词向量的子集,表示与每个查询的词向量最相近的词向量的集合。eq表示q中查询词q的向量表示,em为文档d中与查询的词向量eq的余弦相似度最大的词项的向量表示。
[0056]
s4.3:计算文档d的最终得分,取查询与文档各个片段得分的最大值作为文档的语义相关性得分,计算方式如下:其中,d={p1,p2,...,pk},d中的片段pi∈d,i∈{1,2,..,k}。
[0057]
模型在短文本数据上训练时使用的损失函数如下:其中,y(q,p)是段落和查询的相关性标签。score(q,p)表示文档d的最终得分。
[0058]
实施例2本发明还提供了一种面向长文本的稠密信息检索系统,该系统包括交互端,服务器,存储介质。
[0059]
该系统部署具体为:通过面向长文本的稠密信息检索方法中s1对bert语义模型进行训练,然后将被检索用的大量长文本,通过面向长文本的稠密信息检索方法中s1,转换后在存储介质中离线存储。该离线存储的内容放置在云存储中。
[0060]
该系统的检索过程具体为:通过交互端输入查询语句,并限定被检索的长文本的选取范围,服务器接收到查询后,将查询语句通过面向长文本的稠密信息检索方法中s3进行转换,然后服务器从云端分批调取被选取范围的长文本的表示,通过面向长文本的稠密信息检索方法中s4得出查询结果。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1