一种基于二元组的漏洞克隆检测系统及方法
1.本发明涉及一种基于二元组的漏洞克隆检测系统及方法,属于漏洞检测技术领域。
背景技术:
2.开源软件的漏洞克隆检测一直以来都是软件分析领域的热点研究问题之一。随着互联网技术的不断推进发展,网络信息安全成为了人们越来越关注的问题。但与此同时,互联网中暴露出来的漏洞数量也呈现逐年增加的趋势。另外,在计算机领域,许多企业利用开源软件形成了独有的商业模式,据统计,有99%的企业在其it系统中使用了开源软件。开源成为了如今计算机发展的大趋势。开源软件的不断流行壮大的同时,与开源软件相关的漏洞数量也在增长壮大。这主要是因为,在开源代码的克隆复用时,可能会将那些漏洞代码带到正在开发的系统中。这就导致了一个漏洞的隐蔽的广泛传播。从攻击者的角度来看,开源软件安全漏洞很容易从互联网中获得,这导致了攻击者可以根据官方发布的补丁细节进行有针对性的攻击设计。可以看到,尽可能的认识开源软件的漏洞克隆不仅可以提高软件自身的安全性,而且还可以控制漏洞在开源软件代码重用时的传播。所以开发漏洞克隆检测系统快速准确的检测出系统中存在的已知漏洞是应对软件安全风险,减少由漏洞造成的各种损失的有效措施。
3.目前,依据漏洞的分析方法,软件漏洞检测可以分为基于模式匹配的方法和基于代码相似性匹配的方法。开源软件对于源码的获取具有天然的便利性,所以本系统主要是针对源码的漏洞检测。
4.在早期的研究中,一些算法寻求在找出特定类型漏洞的独特模式,在被测代码中找到匹配这个模式的部分,即判定为存在漏洞。但是这种检测方法,首先时漏洞模式的产生,主要依据安全专家的经验,因此主观性强。针对每种类型的抖动,都需要设计不同的检测模式,设计复杂。规则的不完善也会导致检测的不准确。另一种检测算法就是根据与漏洞相似的代码很有可能也含有漏洞这一思想,设计出一种方法能比较出来代码的相似性。
5.针对开源软件的漏洞检测问题,有一些基于代码相似性的方法来处理这个问题。redebug能够迅速发现操作系统规模代码库中未打补丁的漏洞代码。它使用特征散列法编码位向量中的n个标记,使redebug以十分高效的方式执行相似性检测。securesync采用扩展的抽象语法树(xast)来表征漏洞代码段,用于复制源码的再现漏洞检测。cbcd用子图同构匹配来确定缺陷代码的pdg是否是软件系统pdg的子图,并提供了4种pdg查询的优化方法。vuddy将函数作为基本检测粒度,对漏洞函数中的类型名、变量名、函数名进行统一替换来确保对于漏洞代码克隆的检测。song等人采用程序切片的方式,提取与漏洞有关的语句块进行匹配。
6.现有的基于代码相似性的源码漏洞克隆检测中,由于抽象语法树,数据流图,控制流图,程序依赖图对于代码的抽象不够全面,因此找到的漏洞特征不够完整。所以根据以上几种方案设计的检测方法,对漏洞的检测性能不高。而代码属性图结合了以上几种抽象结
构,所以能够获取到足够多的代码结构特征。但是由于获取的抽象信息过多,会有很多的冗余,因此检测的速度包括准确率都不够高。
7.还有就是现有的检测方法,都是以函数为单位进行报告。但是,一个漏洞往往涉及多个函数,仅仅只有部分漏洞函数被匹配上,也不能判定其是一个漏洞。
8.总之,当前漏洞克隆检测方法中,基于文本的方法只需要对代码进行词法分析,文本所包含的代码信息过少。抽象语法树虽然能获得比文本表示更多的代码结构信息,但是抽象语法树的结构复杂,进行大规模软件的漏洞检测成本很高。代码属性图所包含的代码结构信息相较于抽象语法树来说更加的完整,但图相似的计算同样复杂,本发明首次使用二元组将代码属性图中的信息表示出来,将子图匹配问题转化为二元组匹配问题,极大简化了计算过程,提高检测效率,使其能够应用在较大规模软件。
9.另外,当前的漏洞检测是以函数为单位报告检测结果,但是一个漏洞形成原因是复杂的,漏洞的修复往往涉及多个函数。当一个cve涉及到多个函数时,可能在被测项目中只能匹配到该cve包含的一部分漏洞函数。虽然包含了一部分漏洞代码,但是这部分函数的漏洞性已经消失了,也即不存在漏洞。那报告出来的这个函数检测结果也就是没有意义的。因此我们需要对检测结果一个一个检查筛选,确定报告的结果是否一定包含一个漏洞。所以针对于一个漏洞涉及多个函数的情况,本方法在检测过程中,增加一个面向cve的漏洞分析整合过程。
10.[1]jang j,agrawal a,brumley d.redebug:finding un-patched code clones in entire os distributions[c]//2012ieee symposium on security and privacy(s&p).2012:48-62.
[0011]
[2]李赞,边攀,石文昌,等.一种利用补丁的未知漏洞发现方法[j].软件学报,2018,29(5):1199-1212.li z,bian p,shi w c,et al.approach of leveraging patches todiscover unknown vulnerabilities[j].journal of software,2018,29(5):1199-1212.
[0012]
[3]kim s,woo s,lee h,et al.vuddy:a scalable approach for vulnerable code clone discovery[c]//2017ieee symposium on security and privacy(sp).ieee,2017.
[0013]
[4]song x,yu a,yu h,et al.program slice based vulnerable code clone detection[c]//2020ieee 19th international conference on trust,security and privacy in computing and communications(trustcom).ieee,2020.
技术实现要素:
[0014]
本发明技术解决问题:克服现有技术的不足,提供一种基于二元组的漏洞克隆检测系统及方法,减少信息冗余同时降低检测的误报率;同时,进一步准确判断检测结果是否是一个完整的漏洞。
[0015]
本发明技术解决方案:一种基于二元组的漏洞克隆检测系统,包括:漏洞特征库的生成模块,漏洞克隆检测模块和结果过滤生成模块;
[0016]
漏洞特征库的生成模块,首先根据漏洞函数和打补丁后的函数分别生成代码属性图,然后根据代码属性图,获取与漏洞有关的语句,这些语句经过标准化以及抽象表示之
后,得到漏洞特征信息,最终形成漏洞特征库;
[0017]
漏洞克隆检测阶段,将被测项目进行抽象处理,首先获取被测项目中的函数,然后对函数进行处理,生成代码属性图,对代码属性图进一步抽象表示,最后,与漏洞特征库进行匹配,得到检测出的漏洞;
[0018]
结果过滤生成模块,采用过滤器,以cve为单元,对检测出的漏洞进一步判断,如果检测出的漏洞的结果中包含一个cve-id中所涉及的所有的漏洞函数,则判定是一个与所述cve一样的漏洞,如果包含部分漏洞函数,则是一个不确定的结果。
[0019]
所述漏洞特征库的生成模块具体实现如下:
[0020]
(1)首先,获取cve(common vulnerabilities&exposures,通用漏洞披露)给出的漏洞对应的漏洞函数和打补丁函数;在nvd网站上,对于每一个cve,都会公布其相关资源网址,在nvd网站上获取json格式的cve数据集,然后处理数据集,由于本发明只用来检测c/c++代码,因此筛选出来与c/c++相关的cve信息;筛选出来的cve中,包含着cve编号,补丁网址,描述信息;根据补丁网址,去获取对应的补丁,以及漏洞函数;根据补丁以及漏洞函数,将漏洞函数进行修改,最终获取打补丁函数;在获取到漏洞函数和打补丁函数之后,分别对两个函数进行标记;在两个函数标记完之后,处理获得两个函数的代码属性图;
[0021]
(2)对获取到漏洞函数badfunc和打补丁函数goodfunc进行处理,获取两个函数代码属性图,具体为:使用joern对函数进行扫描,然后漏洞函数和打补丁函数经过处理之后均得到两个文件,即节点文件和边文件;节点文件中包括节点关键字,节点信息,节点类型;边文件中包括两个节点之间的边类型,包含flow_to,use八种类型;根据这两个文件,将两个函数分别抽象为两个二元组表示集合,二元组定义如下:[code1_out,code2_in],其中,二元组中的两个语句顺利不能改变,因为其中隐含着其控制流或者数据流关系;
[0022]
(3)在漏洞函数badfunc和打补丁函数goodfunc中获取以标记“+”和标记
“‑”
为核心的语句的所有相关的二元组表示,这一过程被称之为“切片”,整合获取的所有二元组,漏洞函数中获取的二元组表示集合称为漏洞函数切片集合,打补丁函数中获取的二元组表示集合称为补丁函数切片集合。对于这两个集合,再次进行分类,分类规则如下:
[0023]cc
=vuls∩pats[0024]bc
=cc∩vuls[0025]
gc=cc∩pats[0026]
其中,c_c指既出现在漏洞函数切片的集合中,也出现在打补丁函数的切片集合中的二元组,b_c指只出现在漏洞函数的切片集合中的二元组,g_c指只出现在打补丁函数的切片集合中的二元组;
[0027]
(4)对每个集合中的二元组进行标准化处理,将二元组表示为一个32位的哈希值,对于每个漏洞函数来说,漏洞特征有以下五部分组成:
[0028]
{cve_id#funcname,funchash,c_c_hash,b_c_hash,g_c_hash})
[0029]
其中,cve_id#funcname指的是漏洞的函数名,funchash指的是漏洞函数进行hash之后的函数体hash值,c_c_hash指的是c_c进行hash后的二元组hash值,b_c_hash指的是b_c进行hash后的二元组hash值,g_c_hash指的是g_c进行hash后的二元组hash值;
[0030]
(5)最终,针对每个漏洞函数提取的各种特征,采用json数据格式进行存储,以函数为单位,组织漏洞特征,一个函数对应一条记录,存储最终得到的漏洞特征信息,从而形
成漏洞特征库。
[0031]
所述漏洞克隆检测阶段模块具体实现如下:
[0032]
(1)首先是对被测项目进行处理,获取被测项目中的被测函数,具体的提取函数的过程包括:解析提取出文件名,函数名,函数中的变量列表,参数名列表,数据类型列表包括用户自定义的变量类型,函数调用列表和函数体;将上述解析提取的函数内容保存为以函数为单位的文件,文件名命名格式如下:文件路径#~文件名$~函数名$函数在文件中范围;
[0033]
(2)将函数提取保存之后,对函数进行抽象处理,生成代码属性图,之后对代码属性图信息进行压缩,代码属性图是一个有向图,图中的结点包含代码语句,边包含代码之间的控制和依赖关系,将代码属性图按结点先后顺序,同一条有向边连接的两条代码语句为二元组元素,抽象出二元组,再对二元组进行标准化处理,利用hash算法—fnv-1a对二元组进行hash,生成二元组hash,方便后续的检测操作;
[0034]
(3)最后的检测过程是以将被测函数抽象生成的hash与漏洞特征库中的hash进行比较匹配,具体的实现过程是:首先将被测函数的hash与漏洞特征库中的c_c_hash进行比较,通过比较确定被测函数是否与特定漏洞具有有关性,如果与特定漏洞有关,则才需要进一步判断被测函数是否是一个漏洞函数;如果被测函数的hash与漏洞独有特征的二元组集合b_c_hash更符合,而与补丁函数特征的二元组集合g_c_hash符合度不高,则确定该函数是一个漏洞函数。最终该被测函数会被标记为漏洞函数,被测项目中包含该漏洞。该被测函数会放入漏洞列表中。
[0035]
所述结果过滤生成模块中的具体实现如下:
[0036]
(1)对收集到的所有漏洞函数重新进行以cve为单位的组织,生成json文件cve_write.json,文件中的数据组织形式如下:
[0037]
{cve_id:[cve_id#funcname1,cve_id#funcname2,
……
]};
[0038]
cve_id指的是cve官方发布的漏洞编号,cve_id#funcname1指的是该cve所涉及的函数名称,漏洞特征库中的内容再组织是为了方便后续的结果过滤;
[0039]
(2)最后,将漏洞克隆检测阶段得到的检测结果与上述文件比较,将文件内容视为集合,进行集合与集合之间的包含关系的计算,如果检测结果中包括了cve_id下的所有函数,则判定在被测项目中,一定存在此cve_id给出的漏洞,将该漏洞作为一个被测项目中确定存在的漏洞报告给安全人员,安全人员直接按照漏洞官方网站给出的补丁进行修复即可,否则不能直接判定被测项目中存在该漏洞,这些检测出来的函数就会被报告为疑似漏洞。
[0040]
本发明的一种基于二元组的漏洞克隆检测方法,步骤为:
[0041]
(1)首先是漏洞特征库的生成部分,将漏洞函数和打补丁函数分别生成代码属性图,得到漏洞函数代码属性图和打补丁函数代码属性图;以漏洞官方网站给出的漏洞标记语句为中心,根据属性图中的语句关系,分别在两个属性图中得到漏洞语句代码的相关语句的子图,具体实现为:首先根据发布的补丁,找到补丁中打上标记的与漏洞直接相关的语句,然后以这些语句为中心点,找到漏洞函数代码属性图中与这些语句相关的语句所生成的子图;这一步的主要目的就是减少代码中的干扰语句,也就是与漏洞无关的语句。再将找到的这两个漏洞函数代码属性图的子图抽象成二元组,二元组中的内容为向图中的含有顺
序关系的两个语句,这一步是将子图进一步压缩,减少冗余信息,这样匹配的时候复杂度远小于图匹配;将这些二元组利用hash函数进行hash计算得到对应的hash值,将这些二元组hash分为三个集合,分别为删除语句相关的语句切片二元组hash集合、增加语句相关的语句切片二元组hash集合、与删除与增加语句都相关的语句切片二元组hash集合,这一步的主要目的就是方便在检测过程中,先筛选出有漏洞代码的函数,然后筛选出可能是漏洞的函数,再确认是否是一个漏洞函数;
[0042]
(2)然后在检测过程中,首先是对被测项目中的函数进行提取,然后对于被测函数,首先生成代码属性图,然后将代码属性图中的所有语句结点对抽象为二元组,然后将二元组进行hash计算得到对应hash值,对于被测函数生成的所有二元组hash,首先匹配与删除与增加语句都相关的语句切片二元组hash集合,如果达到设定的阈值1,则接着匹配漏洞特征库中的与删除语句相关语句二元组hash集合,如果达到设定的阈值2,则最后匹配增加语句相关的语句切片二元组hash集合,如果满足阈值3则结束检测过程,判定该被测函数是一个漏洞函数。如果三个匹配条件不能都满足,则该被测函数不是一个漏洞函数;最终得到一个与漏洞库中的漏洞特征匹配上的被测函数,这些函数就是检测出来的在被测项目中出现的漏洞。其中三个阈值是需要通过系统实验确定其值。阈值的确定规则如下:首先是对于阈值1,在实验中我们要保证能将实验数据集中的超99%的漏洞相关的函数筛选出来列为候选函数。对于阈值2,在实验中要把保证由阈值1筛选出来的候选函数中99%的疑似漏洞函数筛选出来。对于阈值3,在实验中发现它只要《1-阈值2,能将漏洞函数和打补丁后的函数有一个很好的检测区分。
[0043]
(3)将检测的结果分析过滤,由于一个漏洞往往涉及多个文件或函数,以函数为单位检测完项目得到漏洞函数后,需要重新从漏洞整体角度进行分析筛选,以函数为单位的直接结果报告只能判断出被测项目中存在漏洞函数代码的克隆,但是漏洞代码克隆是否能造成一个漏洞需要进一步手动确认;设计一个结果分析过滤器,该过滤器以cve_id为单位,通过键值对的形式将一个cve涉及到的多个函数名保存下来,用于结果分析;最后,所有的分析结果以cve的形式组织;如果检测结果中包含cve_id涉及的所有函数,则直接判定是一个与cve_id一样的漏洞,报告会给出一个确定结果列表。如果包含部分,则是一个不确定的结果,报告会给出一个疑似结果列表;这样,直接判定为漏洞的确定结果直接参考cve官方网站给出的补丁链接进行漏洞修复,只需要对那些疑似漏洞结果进行分析,确认是否需要修复。
[0044]
本发明与现有技术相比的优点在于:
[0045]
(1)本发明提出了一种新的基于二元组的漏洞特征表示方法,将漏洞函数和打补丁后的函数分别生成代码属性图。考虑生成的这两个抽象图,首先根据官方发布的补丁,找到补丁中打上标记的与漏洞直接相关的语句,然后以这些语句为中心点,找到属性图中与这些语句相关的语句片段。这一步的主要目的就是减少代码中的干扰语句,也就是与漏洞无关的语句。接下来,将找到的这两个代码属性图的子图抽象成二元组。二元组中的内容主要是有向图中的含有顺序关系的两个语句。这一步主要是讲子图进一步压缩,减少冗余信息。这样匹配的时候复杂度远小于图匹配。随后,将这些二元组分为三个集合。分别为删除语句相关语句集合,增加语句相关语句集合,与删除与增加语句都相关的语句集合。这一步的主要目的就是要在检测过程中,先筛选出有漏洞代码的函数,然后筛选出可能是漏洞的
函数,最后确认是否是一个漏洞函数。最后,将检测的结果综合分析,设计一个过滤器,以cve为单位,如果结果中包含所有的漏洞函数。那么就判定是一个与特定cve一样的漏洞,如果包含部分,则是一个不确定的结果,能够将获取到的抽象图信息进一步压缩,减小匹配的复杂性。
[0046]
(2)本发明提出了面向cve的结果过滤方法,可以将检测结果进一步分析总结,减少人工工作量。
附图说明
[0047]
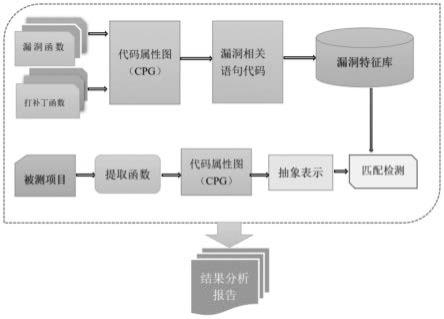
图1为本发明系统的整体框图;
[0048]
图2为本发明的漏洞克隆检测模块实施流程图;
[0049]
图3为被测函数的处理过程。
具体实施方式
[0050]
下面结合附图及实施例对本发明进行详细说明。
[0051]
如图1所示,本发明的系统包含三大模块:漏洞特征库的生成模块,漏洞克隆检测模块和结果过滤生成模块。漏洞特征提取模块,从漏洞函数以及打补丁函数中获取与漏洞有关的语句。这些语句经过标准化以及抽象表示之后,成为特定漏洞的特征;漏洞克隆检测阶段,将被测项目进行抽象处理,与漏洞特征库进行匹配,结果分析报告是指以cve为单元,对检测出来的这些漏洞进一步分析处理。
[0052]
下面将详细介绍系统的漏洞特征库生成模块、漏洞克隆检测模块、结果过滤生成模块的实施步骤。
[0053]
1.漏洞特征库生成模块
[0054]
首先,获取cve对应的漏洞函数和打补丁函数。在nvd网站上,对于每一个cve,都会公布其相关资源网址,首先在nvd网站上获取json格式的cve数据集,然后处理数据集,筛选出来与c/c++相关的cve信息。筛选出来的cve中,包含着cve编号,补丁网址,描述信息等。根据补丁网址,去获取对应的补丁,以及漏洞函数。打补丁函数没有办法直接得到,根据补丁以及漏洞函数,将漏洞函数进行修改,最终获取打补丁函数。在获取到漏洞函数和打补丁函数之后,需要分别将补丁中以
”‑”
标记的语句重新标记到漏洞函数中,以”+”标记的语句重新标记到打补丁函数中。
[0055]
在两个函数标记完之后,还要进行处理获得函数的代码属性图,所以在标记时,不能和补丁函数中标记的方法一样,所以将
”‑”
以”//
‑”
标记到语句末尾,”+”做同样的处理。
[0056]
第二部分就是对获取到漏洞函数(badfunc)和打补丁函数(goodfunc)进行处理,获取其代码属性图。使用joern对函数进行扫描,然后每个函数经过处理之后回得到两个文件,一个节点文件,一个边文件。节点文件中包括节点关键字,节点信息,节点类型等,边文件中包括两个节点之间的边类型,包含flow_to,use等八种类型。根据这两个文件,将函数抽象为一个二元组表示,二元组定义如下:[code1_out,code2_in],其中,二元组中的两个语句顺利不能改变。因为其中隐含着其控制流或者数据流关系。
[0057]
第三部分就是在badfunc或goodfunc中,根据获取的二元组,获取以”//
‑”
标记或者”//+”为核心的语句,其切片规则如下:
[0058]
1)首先对于标记语句,直接进行前向和后向切片。前向切片指的是,在切片时找到标记代码与在二元组code2位置的代码,将code1放入前向切片集合。后向切片指的时,在切片时找到标记代码在code1位置的代码,将code2放入后向切片集合中,并将此二元组放入漏洞特征集。
[0059]
2)对于前向切片集合,执行前向切片,并将二元组放入漏洞特征集。
[0060]
3)对于后向切片集合,执行后向切片,并将二元组放入漏洞特征集。
[0061]
整合其获取的所有二元组,其中主要是”//
‑”
语句及其切片生成的二元组集合。称之为漏洞函数切片集合(vulnerability slices,vul_s),以”//+”语句及其切片生成的二元组集合,称之为补丁函数切片集合(patch slices,pat_s)。
[0062]
对于这两个集合,再次进行分类,定义如下:
[0063]cc
=vuls∩pats[0064]bc
=cc∩vuls[0065]
gc=cc∩pats[0066]
其中,c_c指的是,既出现在漏洞函数切片的集合中,也出现在打补丁函数的切片集合中的二元组。b_c指的是,只出现在漏洞函数的切片集合中的二元组。g_c指的是只出现在打补丁函数的切片集合中的二元组。
[0067]
第四部分,就是对每个集合中的二元组进行标准化处理,将其表示为一个32位的哈希值。
[0068]
最终,对于每个漏洞函数来说,漏洞特征有以下四部分组成:
[0069]
{cve_id#funcname,funchash,c_c_hash,b_c_hash,g_c_hash}
[0070]
2.漏洞克隆检测模块,如图2所示。
[0071]
整个检测模块包括两大部分,分别是对被测项目处理的源码预处理部分和漏洞检测部分。
[0072]
首先是对于被测项目的处理,主要是有两步:
[0073]
1)对文件处理获取函数。要对被测项目中的文件进行处理,得到以函数为单位的数据处理集。处理的过程主要就是遍历所有文件,找出以”.c”,”.cpp”,”.c*”结尾的文件,分别对这些文件中的函数进行提取。
[0074]
2)对函数处理获取抽象表示。对上述提取的函数使用joern进行分析,获取其代码属性图。然后根据代码属性图获取函数中所有语句对,形成函数的二元组集合,对二元组进行抽象和标准化操作,得到能与漏洞特征库匹配的代码表示。具体的被测函数处理过程如图3所示,首先是利用joern对函数进行分析,得到两个文件edges file和nodes file。其中,edges file保存的是代码属性图中的边属性信息,包含结点和结点之间的边,nodes file保存的是结点属性和内容信息,按结点编号给出相应的信息。nodes file和edges file文件中的信息可以通过结点编号连接起来。得到代码属性图文件之后,可以从中提取代码属性图中的边连接的两个语句结点,形成语句二元组(code1,code2)。对这些二元组语句对进行标准化操作,主要就是将变量名、参数名、类型名统一替换为“var”,“para”,“type”。最后将标准化之后的二元组进行hash计算,每一个二元组得到一个hash值。
[0075]
然后是检测模块中的漏洞检测部分,主要流程是:
[0076]
首先,对于被测函数在匹配过程中,要对三个集合分别匹配,设置针对不同集合匹
配时的相似度阈值。首先将目标代码与公共上下文集合进行匹配,达到一定的阈值,确认目标代码时一个漏洞敏感函数。与漏洞特征集合进行匹配,达到一定的阈值,发现其可能存在漏洞。最后与打补丁后的特征集合进行匹配,不超过其阈值,确认目标代码是漏洞函数而非打补丁之后的函数。
[0077]
3.结果过滤生成模块
[0078]
一个漏洞形成原因是复杂的,漏洞的修复往往涉及多个函数。当一个cve涉及到多个函数时,可能会出现能匹配一部分漏洞函数,但是这部分函数的漏洞性已经消失了。所以针对于一个漏洞涉及多个函数的情况,在检测过程中,增加一个面向cve的漏洞分析整合过程。如果一个漏洞涉及多个函数时,如果目标项目中检测到一个漏洞的所有函数时,才能认定其是一个漏洞。如果只检测到部分漏洞函数的话,是无法判断是否是漏洞,所以给出一个疑似漏洞的判定结果。
[0079]
最终,给出两个文件,一个文件是确定的漏洞检测结果,一个是疑似漏洞检测结果。文件中,以cve为单元,显示被测函数,漏洞函数名,漏洞函数,以及对应的补丁文件。
[0080]
以上虽然描述了本发明的具体实施方法,但是本领域的技术人员应当理解,这些仅是举例说明,在不背离本发明原理和实现的前提下,可以对这些实施方案做出多种变更或修改,因此,本发明的保护范围由所附权利要求书限定。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1