对混合证明材料相似比对的方法、系统、电子设备和介质与流程
1.本发明涉及机器学习技术领域,具体涉及一种对混合证明材料相似比对的方法、系统、电子设备和介质。
背景技术:
2.现有技术的对混合证明材料进行真实性验证检测方法可以划分为三类:(1)数据比对校验,分别从提供的各类证明材料中提取比对要素,如,身份证明材料中,从图像中识别出姓名、身份证号码、头像,与相关部门提供的校验渠道进行身份校验;又如,发票证明材料查验时,提取发票号码、开票日期、开具金额(不含税)三个要素在国家税务总局全国增值税发票查验平台进行核验(2)文档真伪识别,分别对提供的某类证明材料文档本身进行真伪判别:如身份证明材料中,对身份证图片的字体、文字位置关系等,作为真伪判别的依据;又如通过图像识别算法对加盖的公章是否经过photoshop等图像处理软件编辑过推断文件是否造假;(3)人工调查,通过人工渠道,使用灵活的人工调查手段,通过诸如网络查询、电话访问、逻辑推断校验等,针对不同材料进行综合判别。
3.前述三种方法的原理需要如下条件:(1)基于庞大而可信的信息库或信息平台,(2)基于特定的专家领域知识来对某方面单一的要素进行判别,(3)发挥人工灵活性,实施全面的审查。
4.但是上述三种方法也具有对应的如下缺陷:(1)维护一个庞大可信的信息平台,需要长久的积累和统一的规范,常见于涉及人群范围较大的公共事务;(2)特定的专家领域知识,仅对特定的场景有效,如果该场景包含的混合多类的证明材料时,可能需要针对性地挖掘多个真伪判别方法,这往往需要投入更多的资源来实现;(3)人工调查的效率、时间成本、经济成本往往高于机器成本,如果规模较大,往往需要投入更多的人员和管理成本。
5.在银行信贷领域涉及的证明材料包括但不限于:身份说明、银行流水证明、工作证明、收入证明、居住证明、住院证明、病历等,信贷业务过程中,客户根据实际情况提供一类或多类的相关证明材料办理业务,银行方根据客户提供的证明材料,进行核验,其中包括材料真实性核验。若单纯的单独采用上述三种方法,可能需要针对性地挖掘多个真伪判别方法,或者如果证明材料较多,往往需要投入更多的人员和管理成本。
技术实现要素:
6.本发明提供一种对混合证明材料相似比对的方法、系统、电子设备和介质,结合了前两个方法各自的优点,通过提供可信平台数据核验渠道,降低对各类证明材料单独研发针对性的真伪识别方案的成本,综合实现效能优化,快速响应业务发展。
7.本发明通过下述技术方案实现:
8.一种对混合证明材料相似比对的方法,包括:
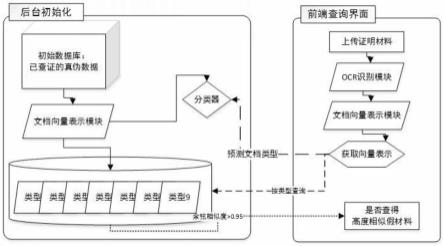
9.s1、收集若干客户的客户数据以形成客户名单并存储在初始数据库中,所述客户数据包括客户id及其对应的证明材料类型、对应的证明材料的文字文本数据以及证明材料
的真伪标识;
10.s2、将所述客户名单中的所有所述证明材料的文字文本数据进行多轮数据清洗、分词,并将每个客户的每一类证明材料的文字文本数据对应构建一组均值单位词向量,且将每组均值单位词向量与对应的客户id绑定;
11.s3、使用每一个所述证明文件的均值单位词向量以及对应的证明文件类型进行训练,从而构建证明材料类型分类器;
12.s4、将需检测的各类待检测证明材料进行文字文本数据的识别,并获取识别的各文字文本数据对应的均值单位词向量,将得到的各均值单位词向量输入至证明材料类型分类器中,判断各所述待检测证明材料的类型,然后将各所述待检测证明材料与其同类型的已收集的客户数据进行向量余弦相似度对比,查找出与各所述待检测证明材料相似的相似文档,判别所述相似文档中是否有虚假资料。
13.作为优化,所述证明材料类型包括工作证明类、交易明细类、收入证明类、病情描述类、健康检查类、案情通告类、身份说明类、居住证明类。
14.作为优化,所述证明材料的文字文本数据可以通过人工或机器ocr识别的方式对原证明材料进行提取。
15.作为优化,所述证明材料的真伪标识可通过调查判定该证明材料的真实性,若调查发现某一类证明材料为虚假,则在该证明材料的对应位置标记虚假标识,否则标记真实标识。
16.作为优化,s2的具体步骤为:
17.s2.1、采用分词工具将每个客户的每一类证明材料的文字文本数据进行分词处理得到若干组与每一类证明材料对应的第一数据组;
18.s2.2、按照预设规则对分词处理后得到的若干所述第一数据组进行数据清洗以得到若干组由关键词或关键字组成的第二数据组;
19.s2.3、通过查询已有的word2vec向量字典,将若干组所述第二数据组中的关键词或关键字分别表示成单个的300维度的第一词向量,并将属于同一组第二数据组中的若干第一词向量进行加权平均、单位向量化,从而得到均值单位词向量;
20.s2.4、将每一类证明材料对应的所述均值单位词向量与对应的客户id进行映射绑定。
21.作为优化,s4的具体步骤为:
22.s4.1通过人工或机器ocr识别的方式对各待检测证明材料的文字文本数据进行提取;
23.s4.2、对各所述待检测证明材料的文字文本数据进行清洗,并获取清洗后的各所述待检测证明材料的文字文本数据对应的均值单位词向量;
24.s4.3、将各所述待检测证明材料的均值单位词向量输入至证明材料类型分类器中,判别出各所述待检测证明材料的类型;
25.s4.4、将各所述待检测证明材料与其同类型的已收集的客户数据进行向量余弦相似度对比,检索出余弦相似度》0.95和/或相似度最高的10个证明材料作为所述待检测证明材料对应的相似文件;
26.s4.5、判断查找出来的相似文件中是否标记有虚假标识,若是,则判定该待检测证
明材料为疑似虚假材料,否则,判定该待检测证明材料为真实材料。
27.作为优化,还包括s5,对判定结果进行提示,具体为:
28.s5.1、若判定所述待检测证明材料为疑似虚假材料,则提示发现疑似虚假材料的字样,同时提示有几个虚假材料与所述待检测证明材料相似;
29.s5.2、若判断所述待检测证明材料为真实材料,则提示未发现虚假材料的字样。
30.本发明还公开了一种对混合证明材料相似比对的系统,包括:
31.后端模块,包括收集模块、文档向量表示模块以及分类器构建模块,其中,
32.收集模块,用于收集若干客户的客户数据以形成客户名单并存储在初始数据库中,所述客户数据包括客户id及其对应的证明材料类型、对应的证明材料的文字文本数据以及证明材料的真伪标识;
33.文档向量表示模块,用于将所述客户名单中的所有所述证明材料的文字文本数据进行多轮数据清洗、分词,并将每个客户的每一类证明材料的文字文本数据对应构建一组均值单位词向量,且将每组均值单位词向量与对应的客户id绑定;
34.分类器构建模块,用于使用每一个所述证明文件的均值单位词向量以及对应的证明文件类型进行训练,从而构建证明材料类型分类器;
35.前端查询模块,用于接收需检测的各类待检测证明材料并对各类所述待检测证明材料进行文字文本数据的识别,通过文档向量表示模块获取识别的各文字文本数据对应的均值单位词向量,将得到的各均值单位词向量输入至证明材料类型分类器中,判断各所述待检测证明材料的类型,然后将各所述待检测证明材料与其同类型的已收集的客户数据进行向量余弦相似度对比,查找出与各所述待检测证明材料相似的相似文档,判别所述相似文档中是否有虚假资料。
36.本发明还公开了一种电子设备,包括至少一个处理器,以及与所述至少一个处理器通信连接的存储器;其中,所述存储器存储有可被所述至少一个处理器执行的指令,所述指令被所述至少一个处理器执行,以使所述至少一个处理器能够执行如上述的一种对混合证明材料相似比对的方法。
37.本发明还公开了一种存储介质,存储有计算机程序,所述计算机程序被处理器执行时实现上述的一种对混合证明材料相似比对的方法。
38.本发明与现有技术相比,具有如下的优点和有益效果:
39.本发明克服了前述的现有技术中存在的对大型可信数据平台的依赖和需要大量不同证明材料的专家知识的实施困难,提供了新的处理流程并利用自然语言处理的方法,加快处理人工难以归类分析的材料。
附图说明
40.为了更清楚地说明本发明示例性实施方式的技术方案,下面将对实施例中所需要使用的附图作简单地介绍,应当理解,以下附图仅示出了本发明的某些实施例,因此不应被看作是对范围的限定,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他相关的附图。在附图中:
41.图1为本发明所述的一种对混合证明材料相似比对的方法的流程图。
63.4)去除长度超过5个字的词语;
64.例:过滤前为“按照中华人民共和国传染病防治法等相关规定你于观察期已满”,过滤后为:“按照等相关规定你于观察期已满”65.5)过滤维护的停用词列表;如:虽然、但是、如果、就是、一般、不过、确实等。
66.例:过滤前为“本人承诺信息真实如果存在虚假描述愿意承担相应责任”,过滤后为:“本人承诺信息真实存在虚假描述愿意承担相应责任”67.s2.3、通过查询已有的word2vec向量字典,将若干组所述第二数据组中的关键词或关键字分别表示成单个的300维度的第一词向量,并将属于同一组第二数据组中的若干第一词向量进行加权平均、单位向量化,从而得到均值单位词向量;该均值单位词向量可以用式下式表示:vector=(v1,v2,
…
,v300)。需要说明的是,word2vec向量字典为现有技术,该字典存储了词语及其向量表示,这里就不再赘述了。
68.s2.4、将每一类证明材料对应的所述均值单位词向量与对应的客户id进行映射绑定,使得每个客户id能够在某证明材料类型下的均值单位词向量进行保存。
69.s3、使用每一个所述证明文件的均值单位词向量以及对应的证明文件类型进行训练,从而构建证明材料类型分类器;
70.分类器采用knn方法,用于区分以下类型:工作证明类、交易明细类、收入证明类、病情描述类、健康检查类、案情通告类、身份说明类、居住证明类等。
71.证明材料类型分类器可以为k近邻的分类模型(knn),而使用每一个所述证明文件的均值单位词向量以及对应的证明文件类型进行训练的过程如下(x可以理解为均值单位词向量, y理解为对应的证明文件类型对应的向量编码,某个位置上出现1,其余为0,表示代表相应的类型,如向量[1,0,0,0,0,0,0,0,0]表示第一个类型“工作证明类”),以python 的scikit-learn包训练为例,最后的estimator为训练好的分类器模型:
[0072]
from sklearn.neighbors import kneighborsclassifier
[0073]
x=[vec1,vec2]
[0074]
y=[[0,1,0,0,0,0,0,0,0],[0,0,0,0,0,0,0,0,1]]
[0075]
estimator=kneighborsclassifier()
[0076]
estimator.fit(x,y)
[0077]
s4、在实际使用时,将需检测的各类待检测证明材料输入至前端网页界面,进行文字文本数据的识别,并获取识别的各文字文本数据对应的均值单位词向量,将得到的各均值单位词向量输入至证明材料类型分类器中,判断各所述待检测证明材料的类型,然后将各所述待检测证明材料与其同类型的已收集的客户数据进行向量余弦相似度对比,查找出与各所述待检测证明材料相似的相似文档,判别所述相似文档中是否有虚假资料。
[0078]
本实施例中,s4的具体步骤为:
[0079]
s4.1通过人工或机器ocr识别的方式对各待检测证明材料的文字文本数据进行提取;
[0080]
本实施例中,采用ocr进行识别;
[0081]
s4.2、对各所述待检测证明材料的文字文本数据进行清洗,并获取清洗后的各所述待检测证明材料的文字文本数据对应的均值单位词向量;
[0082]
s4.3、将各所述待检测证明材料的均值单位词向量输入至证明材料类型分类器
中,判别出各所述待检测证明材料的类型;
[0083]
s4.4、将各所述待检测证明材料与其同类型的已收集的客户数据进行向量余弦相似度对比,检索出余弦相似度》0.95和/或相似度最高的10个证明材料作为所述待检测证明材料对应的相似文件;
[0084]
s4.5、判断查找出来的相似文件中是否标记有虚假标识,若是,则判定该待检测证明材料为疑似虚假材料,否则,判定该待检测证明材料为真实材料。
[0085]
本实施例中,还包括s5,对判定结果进行提示,具体为:
[0086]
s5.1、若判定所述待检测证明材料为疑似虚假材料,则提示发现疑似虚假材料的字样,同时提示有几个虚假材料与所述待检测证明材料相似;发现的虚假材料相似个数越多,材料虚假性越高;
[0087]
s5.2、若判断所述待检测证明材料为真实材料,则提示未发现虚假材料的字样。
[0088]
接下来,以具体的数值作为示例来进行解释。
[0089]
s1中,基础数据准备,建立初始数据库。
[0090]
表1客户名单
[0091][0092]
s2.1、调用分词工具,如python中的jieba分词,去除标点符号、字母、数字,将汉字分成单个的字或词语。如,“兹证明张三于2020年9月入职,薪资为捌仟四百元整,联系电话 028-83456789”,
[0093]
分词得到第一数据组为:兹、证明、张三、于、2020、年、9月、入职、薪资、为、捌仟、四百、元、整、联系、电话、028、-、83456789;
[0094]
s2.2、执行前述涉及到的清洗规则,清洗后保留词语得到第二数据组为:兹、证明、张三、于、年、9月、入职、薪资、为、元、整、联系、电话
[0095]
s2.3、通过查询已有的word2vec向量字典,如自然语言处理领域中公开的中文向量表示字典:基于financial news金融新闻训练的word2wec向量字典“w2v.financial.target.word-word.dim300”,将每个字或词语表示成单个的词向量300维向量,即:兹、证明、张三、于、年、9月、入职、薪资、为、元、整、联系、电话,13个词将对应13个300维的向量,计算向量均值并单位化;
[0096]
s2.4、将输出最终的向量,作为该证明文件的均值单位词向量。
[0097]
s3中,训练一个knn分类器(证明材料类型分类器),用于预测新的待查询文本属于哪类证明材料。这里knn的k=13,即查询到最近的13个文档中,以最多的那类证明材料类型,作为新文本的证明材料类型。
[0098]
s4中,在前端页面上传需要检索的新增客户的所有证明材料,通过中文ocr识别模块(中文ocr识别功能为python包,使用学术公开的ocr识别功能),进行ocr识别,再将识别出的文档,通过执行步骤b1、b2,获取单位向量表示;通过步骤c,判别证明材料类型;并跟数据库中的同一类型文档进行一一对比余弦相似度,判别最相似的10个文档中且相似度》0.95的,有没有包含虚假材料;
[0099]
s5中,查得有客户资料为虚假,则在前端提示;指示后续环节是否还需要深入调查。
[0100]
实施例2
[0101]
本发明还公开了一种对混合证明材料相似比对的系统,包括:
[0102]
后端模块,包括收集模块、文档向量表示模块以及分类器构建模块,其中,
[0103]
收集模块,用于收集若干客户的客户数据以形成客户名单并存储在初始数据库中,所述客户数据包括客户id及其对应的证明材料类型、对应的证明材料的文字文本数据以及证明材料的真伪标识;
[0104]
文档向量表示模块,用于将所述客户名单中的所有所述证明材料的文字文本数据进行多轮数据清洗、分词,并将每个客户的每一类证明材料的文字文本数据对应构建一组均值单位词向量,且将每组均值单位词向量与对应的客户id绑定;
[0105]
分类器构建模块,用于使用每一个所述证明文件的均值单位词向量以及对应的证明文件类型进行训练,从而构建证明材料类型分类器;
[0106]
前端查询模块,用于接收需检测的各类待检测证明材料并对各类所述待检测证明材料进行文字文本数据的识别,通过文档向量表示模块获取识别的各文字文本数据对应的均值单位词向量,将得到的各均值单位词向量输入至证明材料类型分类器中,判断各所述待检测证明材料的类型,然后将各所述待检测证明材料与其同类型的已收集的客户数据进行向量余弦相似度对比,查找出与各所述待检测证明材料相似的相似文档,判别所述相似文档中是否有虚假资料。
[0107]
将需检测的各类待检测证明材料输入至前端查询模块,通过调用中文ocr识别模块对每个待检测证明材料进行文字文本数据提取,通过文档向量表示模块获取各类待检测证明材料对应的均值单位词向量,并通过knn模型对每个均值单位词向量进行分类,判别每个待检测证明材料的类型,将各所述待检测证明材料与其同类型的已收集的客户数据进行向量余弦相似度对比,检索出余弦相似度》0.95和/或相似度最高的10个证明材料作为所述待检测证明材料对应的相似文件,并找出对应的客户id。
[0108]
其中,余弦相似度计算公式为:
[0109][0110]
其中,a、b表示长度为n的均值单位词向量,含有下标的ai表示均值单位词向量a的第 i个值,bi表示均值单位词向量b的第i个值。
[0111]
实施例3
[0112]
本发明还公开了一种电子设备,包括至少一个处理器,以及与所述至少一个处理器通信连接的存储器;其中,所述存储器存储有可被所述至少一个处理器执行的指令,所述指令被所述至少一个处理器执行,以使所述至少一个处理器能够执行如上述的一种对混合证明材料相似比对的方法。
[0113]
实施例4
[0114]
本发明还公开了一种存储介质,存储有计算机程序,所述计算机程序被处理器执行时实现上述的一种对混合证明材料相似比对的方法。以上所述的具体实施方式,对本发明的目的、技术方案和有益效果进行了进一步详细说明,所应理解的是,以上所述仅为本发明的具体实施方式而已,并不用于限定本发明的保护范围,凡在本发明的精神和原则之内,所做的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1