一种稠密子图抽取方法和系统
kecc里,少了一个k-ecc。随机性导致了结果的不确定性。因此称这类算法为近似算法。akiba等在该工作的基础上使用了枚举方式。
10.基于min-cut的方法中,子图裁剪对每一个子图都判断最小割≥k,复杂度非常高。为了解决这一问题,chang等提出了decb-lmsd方法,该算法采用了图分解树方式,在树的根结点都是完整初始图下,每一轮计算分解出新的子图,做为树的子结点,每个图的结点集合进行遍历的过程中采用mas策略将父图分割成两个部分,一个是结点序列l,一个是剩余子图。对于l进行s-t cut判断最后的两个结点是否属于一个k-ecc,对于剩余子图,则是任意选择一个结点重新走上述过程。虽然时间复杂度降低到了o(hl|e|),h为树的深度,l为常整数,l≤|v|。
11.但是,可以设想这么一种情况,在无向图g=(v,e)上的最小min-cut=(v1,v2)且小于k,最小的s-tcutc=(s,t)不小于k。这个时候,可以判定s和t都属于v1或者v2。假设s,t都属于v1,这之后,最大s-t流中有一条路径p1,p1上有一个结点v∈v2,那么该路径中,至少包含了两条属于min-cut的边。在拆分图过程中删除了min-cut的边后,该路径p1被切断,g的子图上最大s-t流也就有可能小于k,这种情况s和t不可能属于一个k-ecc。
12.除了decb-lmsd算法,还有sun等改进的pmsk算法,其与decb-lmsd算法的共同点在于都是使用了mas策略生成结点序列l。但是不同点在于,pmsk会将不符合k-ecc的超级结点放回去父图重新检测。余婷(基于大规模稀疏图的稠密子图挖掘算法研究)设计了类似的结点最大流方法并使用语意感知对结点检测进行排序,该方法有效的避免了decb-lmsd算法的问题,不过,依然可以假想这么一种情况,s和t并不属于一个k-ecc,合并l中最后两个结点s和t之后,剩余结点集与l的联通度仍然可以在l中增加了新的结点q,并发现q在后续的计算中被割离,那么s和t并不能区分是否属于一个k-ecc。
13.在上述的近似算法下,对于mas后获得l集没有细致的探讨,并不能获得一个很好的准确性。
14.精确算法的复杂度在基于min-cut的条件下,无法运用于实际数据集中,现有的近似算法准确性较低,如果获得的k-ecc小于预期,则找不到足够的压缩对象,影响压缩性能。因此高准确率的抽取算法非常重要。
技术实现要素:
15.本发明针对上述问题,提供一种稠密子图抽取方法和系统,通过结合近似算法和准确算法实现高准确率的稠密子图抽取。
16.本发明采用的技术方案如下:
17.一种稠密子图抽取方法,包括以下步骤:
18.对原图采用mas策略进行子图分割,得到节点序列l;
19.对节点序列l进行合并检查,无法通过合并检查的结点重新回到原图做后续的分割;
20.对通过合并检查的子图结点进行合并,构成k边联通子图。
21.进一步地,所述对原图采用mas策略进行子图分割,得到节点序列l,包括:首先从父图中随机选择一个结点加入l,并维护一个l的邻居集合n(l);然后从n(l)中选取与l中结点的连接度最大的结点u加入l尾部,获得u的邻居结点集n(u),并更新n(l),直到n(l)为空;
s、t是mas策略生成的l中的最后两个结点,最后一个结点为t,倒数第二个为s,最后得到的节点序列l为t之前所有顶点。
22.进一步地,以g作为输入的mas策略的第一次运行返回的最小s
1-t1割(s1,t1)有两种情况:s1和t1位于g的全局最小割的不同侧,或者位于同一侧;在前一种情况下(s1,t1)必须是g的全局最小割,在后一种情况下s1和t1收缩为一个超顶点而不影响g的全局最小割。
23.进一步地,当有多个同度结点接入l时,以其邻居加入l的顺序进行排序。
24.进一步地,所述对节点序列l进行合并检查,包括:对l进行最大s-t流检测,如果最大s-t流小于k,则切分子图,并不断重复这一过程,同时使用路径增广与路径交换避免边冲突。
25.进一步地,所述路径增广旨在找到所有可能的s-t路径。
26.进一步地,所述路径交换旨在解决现有路径冲突。
27.一种稠密子图抽取系统,其包括:
28.子图分割模块,用于对原图采用mas策略进行子图分割,得到节点序列l;
29.合并检查模块,用于对节点序列l进行合并检查,无法通过合并检查的结点重新回到原图做后续的分割,对通过合并检查的子图结点进行合并,构成k边联通子图。
30.本发明的关键点包括:1、精确算法的复杂度在基于的条件下,无法运用于实际数据集中,现有的近似算法准确性较低,如果获得的k-ecc小于预期,则找不到足够的压缩对象影响压缩性能。因此高准确率的抽取算法非常重要。2、本发明提出了一种基于mas策略的高准确性的稠密子图抽取方法qkecc,该算法结合了近似算法和准确算法。
31.本发明的有益效果如下:
32.本发明在图分解框架中使用了最大s-t流解决路径数搜索问题,对现有mas策略的不足提出了改进方法,使得本方法在k-ecc抽取工作中提高了现有工作的准确率。在实验部分,本方法通过与现有近似算法在正确性上的比较实验证明了本方法在k-ecc抽取上的改进工作有效性,并在运行效率的对比实验上,表明了本发明算法与现有算法工作的差异。
附图说明
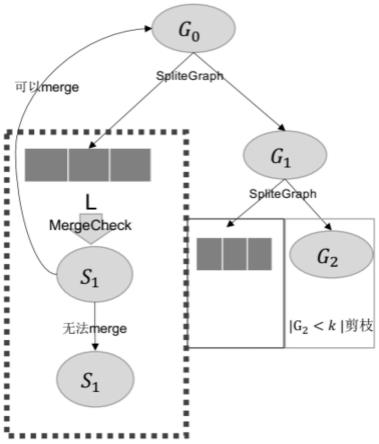
33.图1是qkecc结构图。
34.图2是不同k值下的k-ecc抽取算法时间对比图。
具体实施方式
35.本发明提出了一种基于mas策略的高准确性的稠密子图抽取方法qkecc,该算法结合了近似算法和准确算法,下面将对算法的各部分细节进行详细的描述。
36.如图1所示是qkecc的结构图。首先对原始图g0进行子图分割,然后对l部分进行合并检查,无法通过合并检查的结点重新回到原图g0做后续的分割,对通过检查的子图结点,进行合并构成k-ecc。
37.首先描述一下mas策略,mas策略是一种名为最大连接结点搜索的结点排序策略,可以通过图g构造一个结点序列l。mas算法的过程是,首先从父图中随机选择一个结点加入l,并维护一个l的邻居集合n(l)。然后从n(l)中选取与l中结点的连接度最大的结点u加入l尾部,获得u的邻居结点集n(u),并更新n(l),直到n(l)为空,s、t是mas方法生成的l中的最
后两个结点,最后一个结点为t,倒数第二个为s,最后得到的子图即节点序列l为t之前所有顶点,割集为(l,v\l)。其中v表示图中的结点集合。
38.本发明的子图的分割部分,采用mas策略对于图中随机选定的结点子图进行排序生成序列l的思想。对于图g,如果在序列l生成的过程中,发现l与n(l)中的结点的最大连接度小于k,则对l的父图进行分解,分解为两个部分,一个是l,一个是gi。可以推得,为了找到图的全局最小割,只要mas找到最小s-t割,s和t就会收缩为一个超顶点,并将结果图作为mas的输入以进行另一次运行。让g成为mas第一次运行的输入。在n-1次运行之后,结果图由单个超顶点组成,将识别g的n-1个割,同时通过收缩g的顶点获得的结果图的每个割也是g的一个割。那么,在n-1个识别的割中具有最小值的割是g的全局最小割。考虑以g作为输入的mas的第一次运行返回的最小s
1-t1割(s1,t1),有两种情况:s1和t1位于g的全局最小割的不同侧,或者它们位于同一侧。在前一种情况下,(s1,t1)必须是g的全局最小割,而在后一种情况下,s1和t1可以收缩为一个超顶点而不影响g的全局最小割。
39.对图分解以后,获得的l,并不一定是一个k-ecc,但是一定是k-core(k核),然后,对这个k-core进行k-ecc子图检查。通过子图l的分割,可以确认原始图中获得这个l一定是要比原始图小的,也就完成了子图的检查范围缩小。但是,对于全局的最小割需要对所有结点进行分割,当有多个同度结点接入l的时候,同样需要做出排序,以其邻居加入l的顺序进行排序。因此对于图中子图g3,以v
11
先入l,邻居为v7,v8,v
10
,v
13
,接着假设以结点v
13
先入队列l(通常为v7),那么第三批进入l的结点v
12
,v
13
,v
15
的优先级将更高,因为这些结点与最新入队的v
13
更近,也因此可以更快找出g3。对此,邻居结点集的设计采用二层排序,对新加入l结点的非l结点邻居进行时间权重+1,优先对联通度排序,其次对时间权重排序。
40.下面描述图分解算法splitegraph的完整过程。该算法的输入为一个无向图g={v,e},输出为分解的子图。算法的初始化变量为待分解队列sq,首先将原始图带入到算法中,对所有任意结点抽取出k-core,分割为两个集合s,t(即图1中的l、g1),对这两个集合,直接将t加入下一步分解队列,对于s则进行合并检查,合并检查部分,对符合一个k-ecc的结点合并为一个集,合并检查部分将会在后节详细说明(见后文的子图检查策略、路径增广与路径交换)。mas抽取中,获得了多个k度结点,出于降低复杂度的考虑,只对这些结点进行检查。对于已经合并的集合,存在结点抢占,因此,对每轮合并以后,产生了变化的集合放回到队列中重新合并。当合并检查后的结点符合k-ecc,记录这些结点,完成图分解。
41.现有的方法对于图的分解的最小结点为单个结点或者符合某个要求的结点集如k-ecc集。这一点在构造分解树的时候并不友好,因为迭代的层次会过深入。因此本发明提出剪枝策略,是基于某个结点上的子图并没有出现问题结点,那说明,对于该子图的分解没有必要。
42.这一点是基于这样的一个假设。对于图g,并给出对g做mas以后的序列l,指定初始结点s,当结点依次加入到l中,那么非l中某结点e,与l之间的联通度大小排序应该是不变的,所以l的生成结果,应该是始终不变的。因此,当e是l的下一个目标结点,可以推理出当g删除某条边e
ab
(节点a与节点b之间的边)后,并不会改变n(l)集中加入l的顺序,e仍然是下一个加入l的结点。
43.stoer等证明了mas方法生成的l中的最后两个结点,设最后一个结点为t,倒数第二个为s,那么g上的min s-t cut等于w(l\t,t)。对于图g,在使用mas的时候,如果出现一个
新结点p,p与l中最后一个结点不属于一个k-ecc,那么一定存在一个结点s,使得g上的最小s-t cut《k。
44.基于这种考虑,本发明设计了子图检查策略,对于获取的l,采取一个针对l的子图检查。为了提高检测的效率,只在所有的k联通结点都加入l后,再进行检查。
45.该针对l的子图检查算法是对抽出来的l进行最大s-t流检测。如果最大s-t流小于k,则切分子图。并不断重复这一过程。使用两点,路径增广与路径交换,避免边冲突。
46.路径增广旨在找到所有可能的s-t路径,包括以下步骤:
47.1.构造一个辅助的有向图。对于无向边e
u,v
∈e,都用e
u,v
和e
v,u
代替。迭代搜索所有s-t的有向路径。并记录从s出发的可达结点最短距离(bfs)。有向路通过反向流拓展从t拓展到s。路径p加入新结点t。
48.2.每次加入新的结点v到路径p后,搜索一个结点u满足e
u,v
。
49.3.将u加入p,并回到步骤2,直到到达s流程。
50.路径交换旨在解决现有路径冲突,构建索引<u,v>pn,每当一条有向边e
u,v
加入新路径pm,则在索引中查询其反向边《v,u》。如果没有,则增加该索引。如果有,则去除该pn。并删除桥接路径,构造两个子pn。
51.对于已经构成k条路径的结点,进行结点合并,结点合并指对这些结点的共同邻居的边合并为一条边,权重为边数,这些结点内部不再做改变。
52.与现有的近似算法decb-lmsd、msk以及kcmm一样,本方法在计算的过程中构造了一颗图分解树,这几个算法采用合并分解的策略迭代。本方法将图分解为l与gi,本方法可以保证结点s以及t的正确性范围,因为k-core是更大范围内的k-ecc。对于l中的顶点合并上,本方法采用了多轮合并,每轮对原先集合的影响局限在k-core内结点,而k-core内结点的s-t结点对组合是有上限的,因此一定会收敛,由于结点合并集由先入列的结点决定,先入列的结点将由更多的机会完成集合,当随机结点在多轮k-ecc中,并不能保证算法的稳定结果,这也是本方法仍然为近似算法的原因。
53.复杂度分析中,首先是图检查复杂度,图检查中采用了最大流进行路径增广,对有向边进行补充,通过bfs寻找最短路径,复杂度为o(|e|),但是每次需要对现有的边进行匹配,判断重复,如果重复进行等位结点替换原有路径,因此图检查复杂度为o(l|e|),其中l为最短距离。在图分解部分,多轮合并策略,采用了堆排序堆l进行排序,其复杂度为o(|l|log|l|),每轮mas迭代的遍历复杂度以及图检查合并复杂度为o(l|l|2),每一轮分割都以线性的复杂度进行递增。最终复杂度为o(ch(e)),h为树的分解深度,c为抽取的k-ecc子图数量。
54.下面首先介绍用于k-ecc抽取的数据集,对比算法以及实验环境,并从运行速度和准确性这两个角度评估本章提出的qkecc算法。所有实验运行在intel i7-11800h cpu(主频:4.60ghz 8核16线程),128gb ddr3内存,linux ubuntu 18.04(64位)操作系统。代码以c++实现,用gcc 8.2.1编译并采用o3优化。
55.为了提高随机结点的选取有效性,本实验对超过千万结点的数据集做了一个预处理,处理掉所有的度小于4度结点。该操作并不影响正确率,由于本方法是基于k-core进行,并不影响抽取的正确性,同时对有向边数据集,添加了虚拟反向边,以使得数据集可以适用无向图算法。因此在本章的实验中的数据集,边规模并没有达到十亿级别。
56.数据集选取了构造集和一些社交网络数据集以及github数据,如表1所示,下面分别介绍各数据集。
57.以下是实验中的采用的数据集:
58.1)r-mat是一种构造集,使用了一个简单的递归模型仅用几个参数,可以快速生成逼真的图。利用这个模型可以轻松生成加权图、有向图和二分图;利用r-mat可以生成符合著名的erd
″
os-r
′
e nyi概率的图且可以满足幂律分布。我们利用r-mat生成权重为整数的加权图,以权重模拟边的类型。
59.2)amoazon0601是一种网络图,该网络是通过爬取亚马逊网站收集的。它基于亚马逊网站的购买此商品的客户还购买了功能。如果产品i经常与产品j共同购买,则图包含从i到j的有向边。
60.3)github是一个公开的由ghtorrent构成。从中抽取出任意1/10结点并构成一个数据集。
61.表1 k-ecc抽取实验中使用的数据集
[0062] 结点数边数rmat-1-108,18598,430rmat-10-20065,5341,983,204amazon1,303,3949,443,408github 1/10random11,541,4187,337,648github15,414,182101,831,073
[0063]
对比算法采用以下两种算法:1)decb-lmsd算法(chang等,2013),该算法最早提出k边联通子图图分解算法,也是最早的近似算法。2)pmsk算法(sun等,2016),是精确算法msk算法的近似算法。
[0064]
在两个维度上进行对比实验,一是时间维度选取不同k值时,各数据集运行时长(s),另一维度为准确性,以精确算法msk对数据集搜索得到的子图数量为基准,与主流的近似算法方法进行对比。
[0065]
如表2所示,在各类数据集下,展示了各种算法的准确性结果,子图的k尺寸表示通过图分解算法生成的k边联通子图的k值,本方法与pmsk和decb-lmsd算法相比具有较大的准确性优势,准确性较decb-lmsd方法有80%的提升,本方法在github k=8的子图上出现了错误,而decb-lmsd算法与pmsk在众多数据集上错误分割,这两个算法都是基于min-cut,在结果上也有类似性。通过对比实验,在不同的k值下,pmsk和decb-lmsd算法产生错误重叠,如k=4github随机数据集上,lmsd和pmsk都产生了错误,而本方法没有出错,这可能是由于本方法对mas的排序方式即后入l的结点先分割子图的策略导致。在rmat-10-200的数据集中,本章的qkecc算法准确性上同样优于pmsk与decb-lmsd算法。在较小的数据集rmat-1-10上,三者都没有产生差异,错误情况均无发生,因此本方法在图的分割准确性上对比现有基于min-cut的方法有更好的表现。
[0066]
表2 k-ecc抽取准确性对比结果
[0067][0068]
如图2所示,是不同k值下的k-ecc抽取算法时间对比图,在时间对比上,不同的数据集上有较大差异。当k=4时,本方法较之pmsk算法在amazon的数据集上较差,差距为9.3%这是由于本方法对结点进行了多轮抽取,pmsk在结点不符合的情况中,对l恢复子图,而本方法是对合并的子图接着合并检查当无法通过检查时,采取结点抢占,因此本方法在这样的情况中会出现一个子图的多次验证。本方法较decb-lmsd算法在该数据集上以及github随机数据集具有较好的时间优越性,decb-lmsd在非常稠密的图中,分解树的高度可能很高,该方法没有在这种场景中做出限制。
[0069]
在k为6的场景中amazon数据集上非常稠密现有方法都不能很好的解决这样场景中的问题,用时都已经超过了10000s。而在更大数据上github上,本方法较之现有方法能够在限制的时间内完成。decb-lmsd在github的随机数据集上存在较快情况,可能是该数据集深度不深因此本文的多轮检查的策略较为耗时。k=8以及k=10的对比实验中,当子图规模较小的时候,本方法有着较好的表现。
[0070]
本发明的另一实施例提供一种稠密子图抽取系统,其包括:
[0071]
子图分割模块,用于对原图采用mas策略进行子图分割,得到节点序列l;
[0072]
合并检查模块,用于对节点序列l进行合并检查,无法通过合并检查的结点重新回到原图做后续的分割,对通过合并检查的子图结点进行合并,构成k边联通子图。
[0073]
其中各模块的具体实施过程参见前文对本发明方法的描述。
[0074]
本发明的另一实施例提供一种电子装置(计算机、服务器、智能手机等),其包括存储器和处理器,所述存储器存储计算机程序,所述计算机程序被配置为由所述处理器执行,所述计算机程序包括用于执行本发明方法中各步骤的指令。
[0075]
本发明的另一实施例提供一种计算机可读存储介质(如rom/ram、磁盘、光盘),所述计算机可读存储介质存储计算机程序,所述计算机程序被计算机执行时,实现本发明方法的各个步骤。
[0076]
以上公开的本发明的具体实施例,其目的在于帮助理解本发明的内容并据以实施,本领域的普通技术人员可以理解,在不脱离本发明的精神和范围内,各种替换、变化和修改都是可能的。本发明不应局限于本说明书的实施例所公开的内容,本发明的保护范围以权利要求书界定的范围为准。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1