一种基于轻量级无锚检测模型的可见光森林火灾检测方法
1.本发明属于深度学习图像处理技术领域,具体涉及一种基于轻量级无锚检测模型的可见光森林火灾检测方法。
背景技术:
2.森林火灾是一种突发性强、破坏力大、发生范围广和扑救困难的自然灾害。它不仅烧毁林木,破坏森林环境,还严重影响到了森林生态系统的稳定与平衡,威胁人民群众的生命财产安全。随着成像技术与计算机视觉技术的不断发展,基于图像的火灾检测技术成为一大研究热点。它不仅可以满足远距离火灾探测的要求,还能够给出详细的火情信息,有利于森林火灾的及时发现与扑救。可见光图像中的火灾目标特征非常复杂,采用传统算法难以得到理想的检测效果。近年来,深度学习的方法在目标检测领域展现出了卓越的性能,为森林火灾检测提供了新的思路。常用的深度学习算法中,yolo系列算法由于其不可比拟的快速性与准确性,被广泛应用于目标检测领域。
3.采用基于深度学习的方法进行森林火灾检测虽然会得到较高的检测精度,但由于需要对深度学习的模型进行训练,因此对配置的要求会比较高。然而,森林火灾检测系统常搭载于巡检台或无人机等移动设备上,对设备的配置要求不能过高。针对以上问题,本发明将yolo系列中最新的无锚结构yolox作为基本框架,引入改进的轻量级网络mobilenetv3g,建立一种轻量级的无锚可见光林火检测模型,使得模型可以较好地搭载在移动设备上,并能够得到较精确的检测结果。
技术实现要素:
4.有鉴于此,本发明的主要目的在于提供一种基于轻量级无锚检测模型的可见光森林火灾检测方法。
5.为达到上述目的,本发明的技术方案是这样实现的:
6.一种基于轻量级无锚检测模型的森林火灾检测方法,包括以下步骤:
7.步骤1,获取红外森林火灾图像数据集,标注各图像中火焰的位置和类别信息,得到火焰数据集,对标注后的每幅图像进行预处理,并划分训练集、验证集和测试集;
8.步骤2,构建改进的轻量级无锚检测模型,利用主干特征提取网络mobilenetv3g对输入图像进行火灾特征提取,得到三个有效特征层feature1、feature2与feature3;
9.步骤3,对有效特征层feature3通过空间金字塔池化模块spp进行多尺度最大池化处理;
10.步骤4,将有效特征层feature1、feature2与feature3输入到加强特征提取网络d-panet,对特征层由深至浅进行加强特征融合,然后使用下采样将浅层的位置信息传递到深层特征中,与深层的语义信息相融合,输出特征层level1、level2与level3;
11.步骤5,将特征层level1、level2与level3传入自适应空间特征融合模块asff进行自适应空间特征融合,然后使用1
×
1卷积压缩到原来的通道数,输出特征层asff-1、asff-2
与asff-3;
12.步骤6,将特征层asff-1、asff-2与asff-3输入到预测网络中,进行多尺度预测,使用解耦头解码预测的目标类别信息和位置回归信息,得到预测结果;
13.步骤7,将预测结果进行得分排序和非极大值抑制筛选,筛选出一定区域内得分最高并满足置信度的预测框,由此得到最终的火灾预测结果。
14.与现有技术相比,本发明针对图像背景复杂、森林火灾检测系统搭载的移动设备计算能力有限等问题,可以有效地降低模型复杂度,提高模型检测精度,具有良好的检测效果。
附图说明
15.图1为本发明实例中的mobilenetv3g-daf-yolox模型图。
16.图2为本发明流程示意图。
17.图3为mobilenetv3g基本结构示例图。
18.图4为daf-panet框架结构图。
19.图5为asff模块结构图。
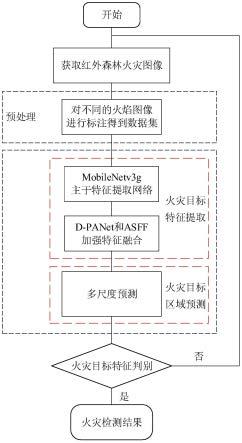
20.图6为火焰目标标记示意图。
21.图7为本发明算法与对比算法的检测结果p-r曲线,其中(a)是与anchor-based算法比较,(b)是与anchor-free算法比较。
22.图8为anchor-based算法的检测结果对比图,其中(a)是森林火灾图像的目标检测真值图,(b)是yolov3算法的火灾检测结果图,(c)是ssd300算法的火灾检测结果图,(d)是faster r-cnn算法的火灾检测结果图,(e)是本发明算法的火灾检测结果示意图。
23.图9为anchor-free算法的检测结果对比图,其中(a)是森林火灾图像的目标检测真值图,(b)是fcos算法的火灾检测结果图,(c)是centernet算法的火灾检测结果图,(d)是本发明算法的火灾检测结果示意图。
具体实施方式
24.为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅用以解释本发明,并不用于限定本发明。
25.本发明实施例提供一种基于轻量级无锚检测模型的可见光森林火灾检测方法,相应的火灾检测模型为mobilenetv3g-daf-yolox,结构如图1所示。首先,采用最新的无锚目标检测框架yolox作为基本架构。其次,考虑到森林火灾监测系统通常搭载在巡检台、无人机等移动设备上,对配置要求不能过高,因此将yolox模型的主干网络替换为改进的轻量级网络mobilenetv3g;然后,使用深度可分离卷积简化panet,降低模型的复杂度;最后,引入asff模块,通过自适应学习各层级特征融合的权重参数,以达到特征提取一致性的目的。
26.具体地,参考图2,本发明基于轻量级无锚检测模型的可见光森林火灾检测方法包括以下步骤:
27.步骤1:获取红外森林火灾图像数据集,标注各图像中火焰的位置和类别信息,得到火焰数据集,对标注后的每幅图像进行预处理,并划分训练集、验证集和测试集。
28.示例地,在本步骤中,所采用的数据集包含森林火灾图像2514张,其中2003张来自北亚利桑那州大学学者提出的flame公开数据集,511张来自比尔肯大学与杜伦大学提供的火灾数据集,共同作为本发明所使用的数据集。同时将森林火灾数据集随机分为训练集、验证集和测试集三部分,比例为7:2:1。然后,采用mosaic、随机仿射变换、随机翻转和对比度变化的数据增强策略对林火数据集中的图像进行处理,并将图像大小调整为统一像素,如640
×
640。最后,使用标注软件labelimg对图像中的火焰进行标注。
29.步骤2:构建改进的轻量级无锚检测模型,利用主干特征提取网络mobilenetv3g对输入图像进行火灾特征提取,得到三个有效特征层feature1、feature2与feature3。
30.示例地,在本步骤中,mobilenetv3g是mobilenetv3的改进版本,其基本结构如图3所示,首先使用一维卷积替换压缩激励网络(senet)注意力机制模块的全连接层,然后在深度可分离卷积前加入一个普通卷积模块,并将两者的输出结果结合起来,从而充分获得语义信息,使得检测结果更加准确。
31.其具体改进方法:以无锚检测模型yolox作为基本框架,首先将yolox的主干网络替换为轻量级网络mobilenetv3,使得该检测模型能够搭载在无人机等移动设备上;然后,结合高效通道注意力网络(ecanet)和ghostnet思想对mobilenetv3网络进行改进,构建mobilenetv3g主干网络,使得在模型轻量化的同时保留多尺度特征信息;最后,使用深度可分离卷积简化路径聚合网络,进一步减少模型的计算量,并引入自适应空间特征融合模块asff,以减轻不同尺度特征图之间的不一致性。
32.本发明的mobilenetv3g包括如下组成部分:
33.(a)ecanet注意力机制:ecanet在全局平均池化后,通过大小为k的一维卷积获取每个通道及其相邻k个通道的局部跨通道交互信息,ecanet通过给定通道数c,自适应地确定卷积核大小k,具体为:
[0034][0035]
式中,式中,表示离最近的奇数,k和c之间存在非线性映射关系φ:c=φ(k)=2
γ*k-b
,其中γ和b为常数系数,本发明中将γ和b分别设置为2和1。
[0036]
(b)改进的深度可分离卷积结构:主要通过借鉴ghostnet的结构对mobilenetv3进行改进,首先使用普通的3
×
3卷积将输入特征图的通道数映射到原始通道数的一半,然后使用深度可分离卷积进一步提取特征,最后将两部分输出的特征图相加。
[0037]
(c)h-swish激活函数:h-swish激活函数是mobilenetv3网络中对swish激活函数的改进。相较于swish函数,h-swish函数计算速度更快、数值稳定性更好。h-swish激活函数的表达式为:
[0038][0039]
式中,relu6(x+3)表示relu6激活函数,即限制relu的最大输出值为6,可表示为relu6(x)=min(6,max(0,x))。
[0040]
本发明的主干特征提取网络mobilenetv3g分为六个阶段,即stage1、stage2、
panet实现路径聚合,d-panet基本结构如图4所示,其使用深度可分离卷积取代路径聚合网络panet中的3
×
3普通卷积,从而降低模型的复杂度,具体过程为:d-panet掺杂在三个有效特征层feature1、feature2与feature3,对特征进行反复提取,对底层特征上采样,与上一层同维度特征层进行堆叠,对高层特征下采样,与下一层同维度特征层进行堆叠,实现特征融合,最终输出三个特征层level1、level2与level3。
[0049]
步骤5:将特征层level1、level2与level3传入asff模块进行自适应空间特征融合,然后使用1
×
1卷积压缩到原来的通道数,输出特征层asff-1、asff-2与asff-3。通过自适应学习特征融合的空间权重,能够提取更有层次性的特征,从而提高检测的准确率。
[0050]
由于asff模块将特征层相加后,输出通道数扩张为输入通道数的两倍,因此需要先使用1
×
1卷积将特征层压缩回原来的通道数,而后才输入到预测网络中。
[0051]
asff模块不同于基于元素求和或级联的传统多层次特征融合方法,是通过自适应学习各尺度特征图的空间融合权重,来缓解不一致性问题,asff模块可分为统一缩放与自适应空间特征融合两部分,其基本结构如图5所示,具体介绍如下:
[0052]
(a)在统一缩放部分,主要使用上采样与下采样操作对特征层进行调整。对于上采样,首先使用1
×
1卷积将通道数压缩到与levell相同,然后使用插值上采样提高分辨率;对于2倍下采样,直接使用大小为3
×
3、步长为2的卷积对特征层尺寸与通道数进行修改;对于4倍下采样,则在卷积层之前再增加一个步长为2的最大池化层。
[0053]
(b)在自适应空间特征融合部分,设xn(n∈{1,2,3})为panet输出的特征层leveln,y
l
(l∈{1,2,3})为x1、x2和x3经过asff模块得到的新特征asff-l。将x1、x2、x3分别乘以权重参数α
l
、β
l
、γ
l
并求和得到融合的特征y
l
,融合的过程可表示为:
[0054][0055]
式中,表示asff输出特征图y
l
在(i,j)处的特征向量,表示leveln缩放到levell的特征图在(i,j)处的特征向量,分别表示三个特征层到levell的空间权重参数,通过softmax函数使且
[0056]
在加强特征提取网络中加入asff模块,通过将每层特征乘以对应的权重参数再相加,能够有效地过滤掉属于其它层的特征,只保留对当前层有用的特征信息,从而使得提取的特征具有层次性,模型的检测效果更好。
[0057]
步骤6:将特征层asff-1、asff-2与asff-3输入到预测网络中,进行多尺度预测,使用解耦头解码预测的目标类别信息和位置回归信息,得到预测结果。
[0058]
示例地,本步骤中,预测网络使用yolox的预测网络,主要包含新的解耦头、anchor-free思想和simota动态正样本匹配方法。具体包括以下几个部分。
[0059]
(9a)新的解耦头:在目标检测中,分类和回归任务之间的冲突是一个众所周知的问题。yolox网络将yolo检测头分成分类和回归两部分,首先使用一个1
×
1卷积层来减小通道尺寸,然后将两个并行分支分别用于分类和回归任务,最后预测时再将其整合在一起。
[0060]
(9b)anchor-free思想:anchor-free机制显著减少了需要启发式调整的设计参数数量,并抛弃了锚聚类、网格敏感等技巧,使得检测器更加简单。具体过程为:将每个位置的预测数目从3减少到1,并使其能够直接预测四个值,分别是到网格左上角的两个偏移量、预测框的高度和宽度。同时,将每个对象的中心位置指定为正样本,并预设一个尺度范围,来
cnn方法,anchor-free方法包括fcos和centernet方法。图7为本发明算法与对比算法的检测结果p-r曲线,图8是anchor-based方法的检测结果对比图,图9是anchor-free方法的检测结果对比图。
[0073]
表2不同算法的检测结果评价指标对比
[0074][0075]
在采用anchor-based方法的对比实验中,将本发明算法与yolov3、ssd300和faster r-cnn算法的检测结果进行比较。表2中显示,二阶段检测方法faster r-cnn具有最高的检测精度,其ap为0.9470,仅比本发明方法低0.0129,但faster r-cnn的flops为61.09g,远大于本发明方法的9.67g。图7(a)中的p-r曲线进一步证明了本发明检测方法的优越性。
[0076]
由图8(b)可以看出,yolov3算法存在漏检问题;由于模型庞大,图8(c)中ssd300算法在训练时存在模型过拟合,因此在测试集中会将部分背景检测为目标;图8(d)中faster r-cnn算法在对小目标进行检测时也存在漏检现象。根据表2和图8(e)可以看出,本发明所研究的方法在精确度和计算复杂度方面都相对表现更好。
[0077]
在采用anchor-free方法的对比实验中,将本发明算法与fcos和centernet算法的检测结果进行比较。由表2可以看出,centernet算法的召回率较高,为0.9039,但比本发明算法低0.0124;fcos的准确率较高,为0.8942,但比本发明算法低0.0409。本发明算法的准确率和ap分别达到0.9351和0.9589,均高于对比算法。同时,本发明所研究算法的flops不到centernet的一半,表明该算法检测效率相对更高。
[0078]
由图9(d)可以看出,本发明算法可以更好地检测复杂背景中的小目标。并且由图7(b)中的p-r曲线可以看出,本发明算法的p-r曲线所包围的面积最大,也就是说,本发明算法的检测精度最高,性能最好。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1