一种基于随机森林算法的人体组织体液识别方法
1.本发明涉及人体组织体液识别技术领域,具体是涉及一种基于随机森林算法的人体组织体液识别方法。
背景技术:
2.犯罪现场遗留的生物痕迹蕴含着对案件侦破极为重要的、有价值的信息。目前短串联重复序列(str)分析被广泛用于生物痕迹的个体识别,但常用的dna分析技术无法进一步鉴别人体组织体液类型。生物痕迹来源鉴别技术对于现场重建、揭示犯罪过程和类型、推断损伤部位及程度等方面尤为重要。目前法医实验室常用的生物痕迹来源鉴别技术仍是传统的生物化学方法、免疫学检测、酶促反应分析等,虽然这些方法简便易行,由于一些组织体液中缺乏特异性酶类或蛋白,导致这些方法不可行或出现错误。因此,人体组织体液的来源鉴别仍是目前法医学实践的难题之一。
技术实现要素:
3.本发明提供一种基于随机森林算法的人体组织体液识别方法,其中所述随机森林算法应用于人体细菌种类和丰度检测,以解决现有技术中所存在的一个或多个技术问题,至少提供一种有益的选择或创造条件。
4.本发明实施例提供一种基于随机森林算法的人体组织体液识别方法,所述方法包括:
5.根据预先设定的模型允许检测的所有人体组织类型,采集若干个检测样本;
6.获取每一个检测样本所对应的特征数据并赋予样本标签,形成原始数据集;
7.按照第一既定数量从所述原始数据集中筛选出重要度更高的特征数据,形成最终数据集;
8.以样本特征数据为输入,以样本所属的人体组织类型为输出,利用所述最终数据集进行多个决策树的训练,再由训练好的多个决策树组成随机森林模型;
9.获取当前待测样本所对应的待测特征数据,将所述待测特征数据输入所述随机森林模型进行预测,得到所述当前待测样本所属的人体组织类型;
10.其中,所述样本特征数据为样本所包含的所有属水平细菌以及每一类属水平细菌所对应的相对丰度。
11.进一步地,所述根据预先设定的模型允许检测的所有人体组织类型,采集若干个检测样本包括:
12.根据预先设定的模型允许检测的所有人体组织类型包括精液类型、皮肤类型、唾液类型、阴道分泌物类型和粪便类型,采集若干个精液样本、若干个皮肤样本、若干个唾液样本、若干个阴道分泌物样本和若干个粪便样本。
13.进一步地,所述样本标签表征检测样本所属的人体组织类型和样本编号。
14.进一步地,所述原始数据集中的每一个特征数据所对应的重要度的求解过程为:
15.利用所述原始数据集进行多个决策树的初步训练,由初步训练好的多个决策树组成初步随机森林模型;
16.通过所述初步随机森林模型获取所述原始数据集中的每一个特征数据所对应的第一袋外数据误差集合;
17.对所述原始数据集中的每一个特征数据加入噪声干扰后,通过所述初步随机森林模型获取每一个特征数据所对应的第二袋外数据误差集合;
18.对每一个特征数据所对应的第一袋外数据误差集合和第二袋外数据误差集合进行求差,再根据所述多个决策树的数量对计算得到的差集中的所有结果进行均值求解,得到每一个特征数据所对应的重要度。
19.进一步地,所述利用所述最终数据集进行多个决策树的训练,再由训练好的多个决策树组成随机森林模型包括:
20.步骤1、从所述最终数据集中随机选取70%的特征数据作为初始训练集,再将剩下30%的特征数据作为测试集;
21.步骤2、从所述初始训练集中以重抽样方式有放回地抽取与其容量相同的特征数据作为训练单个决策树的最终训练集,再从该最终训练集中构建出由第二既定数量的不同特征数据所组合得到的若干个训练子集;
22.步骤3、获取在该决策树的当前层级节点处每一个训练子集所对应的加权平均基尼不纯度,选取加权平均基尼不纯度降低幅度最大所对应的一个训练子集作为节点分割依据,并继续分割出该决策树的下一级节点,直至该决策树的深度达到第一设定值或者节点所包含的样本数量低于第二设定值为止,即该决策树训练完毕;
23.步骤4、根据所述多个决策树的数量,重复执行所述步骤2至所述步骤3以得到训练好的多个决策树,进而组成随机森林模型;
24.步骤5、利用所述测试集对所述随机森林模型进行测试。
25.进一步地,所述获取每一个检测样本所对应的特征数据包括:
26.从每一个检测样本中提取出dna,再利用双末端测序方法构建基因文库进行高通量测序,得到原始测序序列;
27.对所述原始测序序列进行质控和拼接,得到更新后的测序序列;
28.按照既定相似度对所述更新后的测序序列进行otu聚类并剔除嵌合体,得到otu序列;
29.根据silva数据库对所述otu序列进行物种注释,得到该检测样本所包含的所有细菌物种以及每一类细菌物种所对应的相对丰度;
30.将所述所有细菌物种中的所有属水平细菌以及每一类属水平细菌所对应的相对丰度定义为该检测样本所对应的特征数据。
31.进一步地,每一个精液样本的采集方法为:利用无菌塑料杯收集供体的新鲜精液并放置于常温环境下液化30分钟,通过移液枪从中吸取500微升涂抹于无菌棉签,再将该无菌棉签放入15毫升无菌离心管中进行超低温保存;
32.每一个皮肤样本的采集方法为:将吸有无菌生理盐水的无菌棉签通过二步擦拭法对供体的皮肤进行擦拭后放入15毫升无菌离心管中进行超低温保存;
33.每一个唾液样本的采集方法为:当供体在漱口后的一小时内未进食时,利用无菌
离心管收集2毫升供体自然流出的唾液,再将医用无菌棉签蘸取唾液后进行超低温保存;
34.每一个阴道分泌物样本的采集方法为:将无菌棉拭子对供体的宫颈口分泌物或者宫颈后穹窿分泌物进行擦拭后放入无菌拭子管中进行超低温保存;
35.每一个粪便样本的采集方法为:将5ml无菌取样勺对供体排出的处于未接触空气和地面的粪便中段部分进行提取后放入采样管中进行超低温保存。
36.本发明至少具有以下有益效果:通过将高通量测序技术与人工智能学习中的随机森林算法相结合,利用随机森林模型对高通量测序结果进行分析预测,能够实现对法医学常见的五种新鲜人体组织体液进行快速准确鉴识,有利于对司法案件提供有用的定性证据。
附图说明
37.附图用来提供对本发明技术方案的进一步理解,并且构成说明书的一部分,与本发明的实施例一起用于解释本发明的技术方案,并不构成对本发明技术方案的限制。
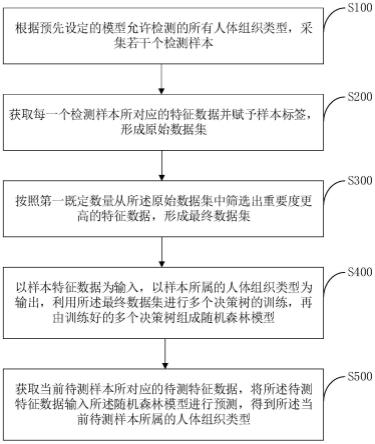
38.图1是本发明实施例中的一种基于随机森林算法的人体组织体液识别方法的流程示意图。
具体实施方式
39.为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅用以解释本发明,并不用于限定本发明。
40.需要说明的是,虽然在系统示意图中进行了功能模块划分,在流程图中示出了逻辑顺序,但是在某些情况下,可以以不同于系统中的模块划分,或流程图中的顺序执行所示出或描述的步骤。说明书和权利要求书及上述附图中的术语“第一”、“第二”等是用于区别类似的对象,而不必用于描述特定的顺序或先后次序。
41.请参考图1,图1是本发明实施例提供的一种基于随机森林算法的人体组织体液识别方法的流程示意图,所述方法包括如下步骤:
42.s100、根据预先设定的模型允许检测的所有人体组织类型,采集若干个检测样本。
43.在本发明实施例中,所述步骤s100的实施过程包括:根据预先设定的模型允许检测的所有人体组织类型包括但不仅限于精液类型、皮肤类型、唾液类型、阴道分泌物类型和粪便类型,采集若干个精液样本、若干个皮肤样本、若干个唾液样本、若干个阴道分泌物样本和若干个粪便样本。
44.其中,针对不同人体组织类型下的检测样本的采集方法分别如下:
45.(1)每一个精液样本的采集方法为:利用无菌塑料杯收集供体的新鲜精液并放置于常温环境(即37℃)下液化30分钟,通过移液枪从中吸取500微升涂抹于无菌棉签,再将该无菌棉签放入15毫升无菌离心管中进行超低温保存;
46.(2)每一个皮肤样本的采集方法为:将吸有无菌生理盐水的无菌棉签通过二步擦拭法对供体的皮肤进行擦拭后放入15毫升无菌离心管中进行超低温保存;
47.(3)每一个唾液样本的采集方法为:当供体在漱口后的一小时内未进食时,利用无菌离心管收集2毫升供体自然流出的唾液,再将医用无菌棉签蘸取唾液后进行超低温保存;
48.(4)每一个阴道分泌物样本的采集方法为:将无菌棉拭子对供体的宫颈口分泌物或者宫颈后穹窿分泌物进行擦拭后放入无菌拭子管中进行超低温保存;
49.(5)每一个粪便样本的采集方法为:将5ml无菌取样勺对供体排出的处于未接触空气和地面的粪便中段部分进行提取后放入采样管中进行超低温保存。
50.需要说明的是,上述五个采集方法中所提及到的超低温保存,优选为在-80℃的环境下进行保存。
51.s200、获取每一个检测样本所对应的特征数据并赋予样本标签,形成原始数据集。
52.在本发明实施例中,针对每一个检测样本所对应的特征数据的具体获取过程包括如下:
53.步骤a1、从每一个检测样本中提取出dna,再利用双末端测序方法构建基因文库进行高通量测序,得到原始测序序列;
54.步骤a2、对所述原始测序序列进行质控和拼接,得到更新后的测序序列;
55.步骤a3、按照既定相似度对所述更新后的测序序列进行otu聚类并剔除嵌合体,得到otu序列;
56.步骤a4、根据silva数据库对所述otu序列进行物种注释,得到该检测样本所包含的所有细菌物种以及每一类细菌物种所对应的相对丰度;
57.步骤a5、将所述所有细菌物种中的所有属水平细菌以及每一类属水平细菌所对应的相对丰度定义为该检测样本所对应的特征数据。
58.在上述步骤a1中,所述从每一个检测样本中提取出dna的具体操作方法为:首先利用soil dna kit试剂盒从该检测样本中提取出dna,接着利用超微量分光光度计(优选的型号为nanodrop 2000c)进行浓度和纯度的检测,最后利用1%琼脂糖凝胶电泳方式对该dna提取的质量进行测定。
59.优选地,上述步骤a1中所提及到的高通量测序任务是在illumina miseq测序平台的辅助作用下执行的。
60.优选地,上述步骤a2中所提及到的质控任务是通过fastp软件执行的,而拼接任务是通过flash软件执行的;其中,flash软件的全称为fast length adjustment of short reads。
61.优选地,上述步骤a3中所提及到的otu聚类任务是通过usearch软件执行的,其设定的相似度为97%;其中,usearch软件的全称为ultra-fast sequence analysis;otu的全称为operational taxonomic unit,译为分类操作单元。
62.在上述步骤a4中,silva数据库的全称为silva ribosomal rna database,是一个核糖体rna基因序列数据库,其提供三个生命域(即细菌、古细菌和真核生物)中的核糖体rna小亚基序列数据集和核糖体rna大亚基序列数据集。
63.此外,上述步骤a4所提及到的所有细菌物种除了包含有属水平细菌之外,还包含有域水平细菌、界水平细菌、门水平细菌、纲水平细菌、目水平细菌、科水平细菌和种水平细菌中的一种或者多种。
64.在本发明实施例中,所述样本标签表征检测样本所属的人体组织类型和样本编号,也就是说,所述样本标签实际上是由两部分组成,第一部分表征检测样本所属的人体组织类型,可用字母形式进行表示,第二部分表示检测样本所对应的样本编号,可用数字形式
进行表示;比如,当用字母x表示精液类型、字母y表示皮肤类型时,样本标签x2指的是所述若干个精液样本中的第二个精液样本,样本标签y2指的是所述若干个皮肤样本中的第二个皮肤样本。
65.s300、按照第一既定数量从所述原始数据集中筛选出重要度更高的特征数据,形成最终数据集。
66.在本发明实施例中,针对所述原始数据集中的每一个特征数据所对应的重要度的具体求解过程包括如下:
67.步骤b1、利用所述原始数据集进行多个决策树的初步训练,由初步训练好的多个决策树组成初步随机森林模型;
68.步骤b2、通过所述初步随机森林模型获取所述原始数据集中的每一个特征数据所对应的第一袋外数据误差集合;
69.步骤b3、对所述原始数据集中的每一个特征数据加入噪声干扰后,通过所述初步随机森林模型获取每一个特征数据所对应的第二袋外数据误差集合;
70.步骤b4、对每一个特征数据所对应的第一袋外数据误差集合和第二袋外数据误差集合进行求差,再根据所述多个决策树的数量对计算得到的差集中的所有结果进行均值求解,得到每一个特征数据所对应的重要度。
71.优选地,所述第一既定数量可为所述若干个检测样本的数量。
72.s400、以样本特征数据为输入,以样本所属的人体组织类型为输出,利用所述最终数据集进行多个决策树的训练,再由训练好的多个决策树组成随机森林模型;其中,所述样本特征数据为样本所包含的所有属水平细菌以及每一类属水平细菌所对应的相对丰度。
73.在本发明实施例中,所述步骤s400的具体实施过程包括如下:
74.步骤c1、从所述最终数据集中随机选取70%的特征数据作为初始训练集,再将剩下30%的特征数据作为测试集;
75.步骤c2、从所述初始训练集中以重抽样方式有放回地抽取与其容量相同的特征数据作为训练单个决策树的最终训练集,再从该最终训练集中构建出由第二既定数量的不同特征数据所组合得到的若干个训练子集;
76.步骤c3、获取在该决策树的当前层级节点处每一个训练子集所对应的加权平均基尼不纯度,选取加权平均基尼不纯度降低幅度最大所对应的一个训练子集作为节点分割依据,并继续分割出该决策树的下一级节点,直至该决策树的深度达到第一设定值或者节点所包含的样本数量低于第二设定值为止,即该决策树训练完毕;
77.步骤c4、根据所述多个决策树的数量,重复执行所述步骤c2至所述步骤c3以得到训练好的多个决策树,进而组成随机森林模型;
78.步骤c5、利用所述测试集对所述随机森林模型进行测试。
79.需要说明的是,在执行上述步骤s400之前,优先由技术人员设置随机森林模型中的决策树数量、每个决策树在节点分裂时所需要考虑的训练子集大小(即上述步骤c2中所提及到的所述第二既定数量)、每个决策树的节点所需要的最少样本数量(即上述步骤c3中所提及到的所述第二设定值)以及每个决策树的最大深度(即上述步骤c3中所提及到的所述第一设定值);但是,上述提及到的各个参数是可以进行调整的,以适应于随机森林模型的优化,比如:通过调节决策树数量可以兼顾到模型的性能和运算速度,通过搜索合适的训
练子集大小可以使得模型的性能达到最优化,通过寻找合适的最少样本数量可以提高模型的判别准确度,等等。
80.在上述步骤c5中,通过将所述测试集输入至所述随机森林模型中,得到预测分类结果后将其与对应的实际分类结果进行比较,利用两者的差异大小来评估所述随机森林模型的性能优劣,此处可以选择采用f1得分进行模型评判,不断通过调整上述提及到的用于模型调优的各个参数,使得所述测试集在最终优化好的随机森林模型中进行预测时所得到的f1得分最高;其中,f1得分的定义为:f1=(2*precision*recall)/(precision+recall),关于precision的求解公式为precision=tp/(tp+fp),关于recall的求解公式为recall=tp/(tp+fn),在上述相关公式中,precision为准确率,recall为召回率,tp代表实际为正的样本数,fp代表实际为负的样本数,fn代表在预测为负的所有样本中实际为正的样本数。
81.s500、获取当前待测样本所对应的待测特征数据,将所述待测特征数据输入所述随机森林模型进行预测,得到所述当前待测样本所属的人体组织类型。
82.在本发明实施例中,所述步骤s500的实施过程为:首先根据上述步骤s200所提出的特征数据获取方式,从所述当前待测样本中获取对应的待测特征数据;接着将所述待测特征数据输入所述随机森林模型中,利用其内部的所有决策树分别对所述待测特征数据进行分类预测,得到所有分类结果;最后对所述所有分类结果进行投票,将投选出来的分类结果众数作为所述当前待测样本的最终分类结果,即输出所述当前待测样本所属的人体组织类型。
83.在本发明实施例中,通过将高通量测序技术与人工智能学习中的随机森林算法相结合,利用随机森林模型对高通量测序结果进行分析预测,能够实现对法医学常见的五种新鲜人体组织体液进行快速准确鉴识,有利于对司法案件提供有用的定性证据。
84.尽管本技术的描述已经相当详尽且特别对几个所述实施例进行了描述,但其并非旨在局限于任何这些细节或实施例或任何特殊实施例,而是应当将其视作是通过参考所附权利要求,考虑到现有技术为这些权利要求提供广义的可能性解释,从而有效地涵盖本技术的预定范围。此外,上文以发明人可预见的实施例对本技术进行描述,其目的是为了提供有用的描述,而那些目前尚未预见的对本技术的非实质性改动仍可代表本技术的等效改动。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1