一种基于双向点乘残差结构的打架视频检测方法与流程
1.本发明涉及视频检测技术领域,特别指一种基于双向点乘残差结构的打架视频检测方法。
背景技术:
2.打架行为破坏社会稳定,威胁人民群众的生命财产安全,带来极其恶劣的社会负面影响。对打架事件进行处理的弊端之一是滞后性,在有人报警之后,警务人员才能出警解决,因此产生了检测摄像头采集的视频,以判断是否存在打架事件,进而提升打架事件处理的及时性的需求。
3.然而,在实际对视频进行检测的过程中,对打架事件识别的准确率不尽如人意,具体有如下原因:1、摄像头拍摄的视频的画质较为模糊;2、许多非打架视频由于存在人物之间的互动,互动的过程和打架的动作类似,会被误判为打架;3、非打架视频的数量远远多于打架视频的数量,导致模型训练的样本比较欠缺,进而导致用于检测打架事件的模型的泛化性能较弱。
4.因此,如何提供一种基于双向点乘残差结构的打架视频检测方法,实现提升打架事件识别的准确率以及泛化性能,成为一个亟待解决的技术问题。
技术实现要素:
5.本发明要解决的技术问题,在于提供一种基于双向点乘残差结构的打架视频检测方法,实现提升打架事件识别的准确率以及泛化性能。
6.本发明是这样实现的:一种基于双向点乘残差结构的打架视频检测方法,包括如下步骤:
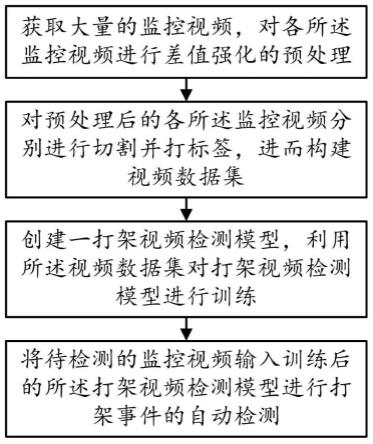
7.步骤s10、获取大量的监控视频,对各所述监控视频进行差值强化的预处理;
8.步骤s20、对预处理后的各所述监控视频分别进行切割并打标签,进而构建视频数据集;
9.步骤s30、创建一打架视频检测模型,利用所述视频数据集对打架视频检测模型进行训练;
10.步骤s40、将待检测的监控视频输入训练后的所述打架视频检测模型进行打架事件的自动检测。
11.进一步地,所述步骤s10具体包括:
12.步骤s11、获取大量的包括打架视频和非打架视频的监控视频;
13.步骤s12、将各所述监控视频分别分解成若干帧的图像帧,分别计算相邻各所述图像帧对应的像素点的rgb差值;
14.步骤s13、构建一信号增强函数,基于所述信号增强函数以及rgb差值对各图像帧进行rgb值的差值强化;
15.步骤s14、对差值强化后的各所述图像帧按原始顺序合并回监控视频,完成所述监
控视频的预处理。
16.进一步地,所述步骤s13中,所述信号增强函数的公式为:
[0017][0018]
其中,x表示rgb差值;α表示无穷大;e表示自然常数。
[0019]
进一步地,所述步骤s20具体包括:
[0020]
步骤s21、将预处理后的各所述监控视频划分为打架视频和非打架视频,并设定切割次数阈值a和b;所述a和b均为正整数,且a>b;
[0021]
步骤s22、分别定位各所述打架视频中,打架事件的时间范围,以所述时间范围为中心,随机对各所述打架视频进行a次的切割,得到a个打架子视频,并分别为各所述打架子视频设定一类型为软标签的打架标签,为所述打架视频设定一类型为硬标签的打架标签;
[0022]
步骤s23、随机对各所述非打架视频进行b次的切割,得到b个非打架子视频,并分别为各所述非打架子视频设定一类型为软标签的非打架标签;
[0023]
步骤s24、基于各所述打架视频、打架子视频以及非打架子视频构建视频数据集。
[0024]
进一步地,所述打架标签以及非打架标签均为数值标签;
[0025]
所述类型为软标签的打架标签的取值范围为(0.8,1);所述类型为硬标签的打架标签的取值为1;所述类型为软标签的非打架标签的取值范围为(0,0.3)。
[0026]
进一步地,所述步骤s30具体为:
[0027]
创建一打架视频检测模型,将所述视频数据集按预设比例划分为训练集和验证集,并设定一收敛条件以及一检测精度阈值;
[0028]
利用所述训练集对打架视频检测模型进行训练,直至满足所述收敛条件;
[0029]
利用所述验证集对训练后的打架视频检测模型进行验证,判断检测精度是否大于所述检测精度阈值,若是,则完成所述打架视频检测模型的训练;若否,则扩充所述视频数据集继续训练。
[0030]
进一步地,所述步骤s30还包括:
[0031]
设定一损失下降阈值,在所述打架视频检测模型训练的过程中,监测所述打架视频检测模型的损失函数的损失值下降程度是否大于损失下降阈值,若是,则进入步骤s20,对相应的所述监控视频进行重新分割;若否,则继续训练。
[0032]
进一步地,所述步骤s30中,所述打架视频检测模型包括一第一卷积模块、一第二卷积模块、一第一sm-gather模块、一第二sm-gather模块以及一第三sm-gather模块;
[0033]
所述第一卷积模块、第一sm-gather模块、一第二sm-gather模块、第二卷积模块以及第三sm-gather模块依次连接;
[0034]
所述第一卷积模块包括3*3的卷积层;所述第二卷积模块包括1*1的卷积层。
[0035]
进一步地,所述第一sm-gather模块、第二sm-gather模块以及第三sm-gather模块均用于执行如下步骤:
[0036]
步骤a、对输入的特征图1进行3*3的卷积得到特征图2,让所述特征图2的形状以及通道数与特征图1保持一致;
[0037]
通过sigmoid函数将所述特征图2的rgb值映射到0~1之间,作为所述特征图1的第一权重;
[0038]
将所述第一权重与特征图1进行点乘得到输出1;
[0039]
步骤b、通过sigmoid函数将所述特征图1的rgb值映射到0~1之间,作为所述特征图2的第二权重;
[0040]
将所述第二权重与特征图2进行点乘得到输出2;
[0041]
步骤c、对所述输出1和输出2进行张量相加得到残差结果值,对所述输出1和输出2进行通道拼接得到拼接值;
[0042]
步骤d、对所述拼接值进行1*1的卷积,以使所述拼接值与残差结果值的通道保持一致;
[0043]
步骤e、通过sigmoid函数将所述残差结果值转换为第三权重,将所述第三权重与卷积后的所述拼接值进行点乘作为最终的输出。
[0044]
进一步地,所述打架视频检测模型的损失函数为:
[0045]
loss
whole
=0.1*loss
soft
+0.8*loss
binary
+0.1*loss
rate
;
[0046][0047][0048][0049]
其中,loss
whole
表示损失函数的总损失值;loss
soft
表示软标签损失;loss
binary
表示交叉熵损失;loss
rate
表示视频切割占比损失;表示软标签;表示软标签的预测值;yi表示真实标签;表示真实标签的预测值;δ表示sigmoid函数,用于将值映射到0~1之间。
[0050]
本发明的优点在于:
[0051]
通过将监控视频分解成图像帧,分别计算相邻各图像帧对应的像素点的rgb差值,利用构建的信号增强函数以及rgb差值对各图像帧进行rgb值的差值强化,再将差值强化后的各图像帧按原始顺序合并回监控视频,即增强监控视频的数据差异性,以克服画质模糊的问题;通过构建包括sm-gather模块的打架视频检测模型,在降低模型深度的同时,也决解决图像帧(特征图)表征能力差的问题,即增强了打架视频检测模型的网络信息捕捉能力,以应对画质模糊的问题;通过对监控视频进行切割以扩大样本量,并构建软标签以弱化正负样本(打架视频和非打架视频)之间的标签强对立信息,即缩小打架视频和非打架视频之间的标签差异,并将软标签加入重构的损失函数,确保打架视频检测模型的模型参数朝泛化能力更强的方向更新,最终极大的提升了打架事件识别的准确率以及泛化性能。
附图说明
[0052]
下面参照附图结合实施例对本发明作进一步的说明。
[0053]
图1是本发明一种基于双向点乘残差结构的打架视频检测方法的流程图。
[0054]
图2是本发明一种基于双向点乘残差结构的打架视频检测方法的流程示意图。
[0055]
图3是本发明打架视频检测模型的架构图。
[0056]
图4是本发明sm-gather模块的架构图。
[0057]
图5是本发明监控视频切割和打标签的流程示意图。
[0058]
图6是本发明打架视频的切割示意图。
[0059]
图7是本发明非打架视频的切割示意图。
具体实施方式
[0060]
本技术实施例中的技术方案,总体思路如下:对监控视频进行差值强化,构建包括sm-gather模块的打架视频检测模型增强网络信息捕捉能力,以应对画质模糊的问题;对监控视频进行切割以扩大样本量,并构建软标签以弱化正负样本之间的标签强对立信息,并将软标签加入重构的损失函数(重构二分类损失函数),确保打架视频检测模型的模型参数朝泛化能力更强的方向更新,以提升打架事件识别的准确率以及泛化性能。
[0061]
请参照图1至图7所示,本发明一种基于双向点乘残差结构的打架视频检测方法的较佳实施例,包括如下步骤:
[0062]
步骤s10、获取大量的监控视频,对各所述监控视频进行差值强化的预处理;
[0063]
步骤s20、对预处理后的各所述监控视频分别进行切割并打标签,进而构建视频数据集;
[0064]
步骤s30、基于神经网络创建一打架视频检测模型,利用所述视频数据集对打架视频检测模型进行训练;所述打架视频检测模型以conv-lstm为框架创建;
[0065]
步骤s40、将待检测的监控视频输入训练后的所述打架视频检测模型进行打架事件的自动检测。
[0066]
所述步骤s10具体包括:
[0067]
步骤s11、获取大量的包括打架视频和非打架视频的监控视频;
[0068]
步骤s12、将各所述监控视频分别分解成若干帧的图像帧,分别计算相邻各所述图像帧对应的像素点的rgb差值;
[0069]
步骤s13、构建一信号增强函数,基于所述信号增强函数以及rgb差值对各图像帧进行rgb值的差值强化;
[0070]
所述图像帧之间通过肉眼查看发现明显存在差异,但所述rgb差值的大小分布较为平缓,无法反应出这种差异,将导致所述打架视频检测模型的识别效果不佳,因此需要对较大的所述rgb差值进行扩大,对较小的所述rgb差值进行抑制;
[0071]
步骤s14、对差值强化后的各所述图像帧按原始顺序合并回监控视频,完成所述监控视频的预处理。
[0072]
所述步骤s13中,所述信号增强函数的公式为:
[0073][0074]
其中,x表示rgb差值;α表示无穷大;e表示自然常数;即所述rgb差值大于0.5,则更新为e
x
;所述rgb差值小于0,则更新为0;否则,维持所述rgb差值;
[0075]
所述步骤s20具体包括:
[0076]
步骤s21、将预处理后的各所述监控视频划分为打架视频和非打架视频,并设定切割次数阈值a和b;所述a和b均为正整数,且a>b;
[0077]
步骤s22、分别定位各所述打架视频中,打架事件的时间范围,以所述时间范围为中心,随机对各所述打架视频进行a次的切割,得到a个打架子视频,并分别为各所述打架子视频设定一类型为软标签的打架标签,为所述打架视频设定一类型为硬标签的打架标签;
[0078]
即每次对所述打架视频进行重新切割,进而保存得到若干个截取区间不同的所述打架子视频;
[0079]
步骤s23、随机对各所述非打架视频进行b次的切割,得到b个非打架子视频,并分别为各所述非打架子视频设定一类型为软标签的非打架标签;
[0080]
步骤s24、基于各所述打架视频、打架子视频以及非打架子视频构建视频数据集。
[0081]
所述打架标签以及非打架标签均为数值标签;
[0082]
所述类型为软标签的打架标签的取值范围为(0.8,1);所述类型为硬标签的打架标签的取值为1;所述类型为软标签的非打架标签的取值范围为(0,0.3)。
[0083]
所述步骤s30具体为:
[0084]
创建一打架视频检测模型,将所述视频数据集按预设比例划分为训练集和验证集,并设定一收敛条件以及一检测精度阈值;
[0085]
利用所述训练集对打架视频检测模型进行训练,直至满足所述收敛条件;
[0086]
利用所述验证集对训练后的打架视频检测模型进行验证,判断检测精度是否大于所述检测精度阈值,若是,则完成所述打架视频检测模型的训练;若否,则扩充所述视频数据集继续训练。
[0087]
所述步骤s30还包括:
[0088]
设定一损失下降阈值,在所述打架视频检测模型训练的过程中,监测所述打架视频检测模型的损失函数的损失值下降程度是否大于损失下降阈值,若是,则进入步骤s20,对相应的所述监控视频进行重新分割;若否,则继续训练。通过此方法能增加负样本的多样性,进而极大的提升了所述打架视频检测模型的泛化性能。
[0089]
所述步骤s30中,所述打架视频检测模型包括一第一卷积模块、一第二卷积模块、一第一sm-gather模块、一第二sm-gather模块以及一第三sm-gather模块;所述第一sm-gather模块、第二sm-gather模块以及第三sm-gather模块均为sigmoid multiplication gather模块;
[0090]
所述第一卷积模块、第一sm-gather模块、一第二sm-gather模块、第二卷积模块以及第三sm-gather模块依次连接;所述第一卷积模块用于打架视频检测模型的输入,所述第三sm-gather模块用于打架视频检测模型的输出;
[0091]
所述第一卷积模块包括3*3的卷积层;所述第二卷积模块包括1*1的卷积层。
[0092]
由于低分辨率的图像在经过深层卷积之后,特征图所包含的信息较少,因此卷积层的个数不能太多,所以采取上述结构的所述打架视频检测模型。
[0093]
resnet的残差结构和densenet的通道拼接结构都是实现上一层和下一层的卷积整合的手段,两者的侧重点不同,前者是将通道信息相加,后者是将通道拼接,而sm-gather模块集成了两者的特点。
[0094]
所述第一sm-gather模块、第二sm-gather模块以及第三sm-gather模块均用于执
行如下步骤:
[0095]
步骤a、对输入的特征图1(feature maps)进行3*3的卷积得到特征图2,让所述特征图2的形状以及通道数与特征图1保持一致;
[0096]
通过sigmoid函数将所述特征图2的rgb值映射到0~1之间,作为所述特征图1的第一权重;
[0097]
将所述第一权重与特征图1进行点乘得到输出1;
[0098]
步骤b、通过sigmoid函数将所述特征图1的rgb值映射到0~1之间,作为所述特征图2的第二权重;
[0099]
将所述第二权重与特征图2进行点乘得到输出2;
[0100]
步骤c、对所述输出1和输出2进行张量相加得到残差结果值,对所述输出1和输出2进行通道拼接得到拼接值;
[0101]
步骤d、对所述拼接值进行1*1的卷积,以使所述拼接值与残差结果值的通道保持一致;
[0102]
步骤e、通过sigmoid函数将所述残差结果值转换为第三权重,将所述第三权重与卷积后的所述拼接值进行点乘作为最终的输出。
[0103]
所述打架视频检测模型的损失函数为:
[0104]
loss
whole
=0.1*loss
soft
+0.8*loss
binary
+0.1*loss
rate
;
[0105][0106][0107][0108]
其中,loss
whole
表示损失函数的总损失值;loss
soft
表示软标签损失,采用绝对误差比值;loss
binary
表示交叉熵损失,即硬标签损失;loss
rate
表示视频切割占比损失,即切割样本与原始样本的差异性损失;表示软标签;表示软标签的预测值;yi表示真实标签;表示真实标签的预测值;δ表示sigmoid函数,用于将值映射到0~1之间。
[0109]
综上所述,本发明的优点在于:
[0110]
通过将监控视频分解成图像帧,分别计算相邻各图像帧对应的像素点的rgb差值,利用构建的信号增强函数以及rgb差值对各图像帧进行rgb值的差值强化,再将差值强化后的各图像帧按原始顺序合并回监控视频,即增强监控视频的数据差异性,以克服画质模糊的问题;通过构建包括sm-gather模块的打架视频检测模型,在降低模型深度的同时,也决解决图像帧(特征图)表征能力差的问题,即增强了打架视频检测模型的网络信息捕捉能力,以应对画质模糊的问题;通过对监控视频进行切割以扩大样本量,并构建软标签以弱化正负样本(打架视频和非打架视频)之间的标签强对立信息,即缩小打架视频和非打架视频之间的标签差异,并将软标签加入重构的损失函数,确保打架视频检测模型的模型参数朝泛化能力更强的方向更新,最终极大的提升了打架事件识别的准确率以及泛化性能。
[0111]
虽然以上描述了本发明的具体实施方式,但是熟悉本技术领域的技术人员应当理解,我们所描述的具体的实施例只是说明性的,而不是用于对本发明的范围的限定,熟悉本
领域的技术人员在依照本发明的精神所作的等效的修饰以及变化,都应当涵盖在本发明的权利要求所保护的范围内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1