一种基于AI引擎提取多语种网络音视频数据的方法与流程
一种基于ai引擎提取多语种网络音视频数据的方法
技术领域
1.本发明属于ai技术领域,具体是一种基于ai引擎提取多语种网络音视频数据的方法。
背景技术:
2.随着ai技术的发展,对于各种语种、各种类型的数据需求,也随之大涨。为了满足ai技术对于各种数据需求,多数ai公司,采用人工标注、人工录音、人工核验等方式进行。通过纯人工的方式存在多语种对标注员素质和专业性要求高、培训人工成本高、制作效率低、数据制作成本高等问题。考虑到网络上有大量的多语种带字幕的音视频、网络电台等,为了解决人工标注各种数据遇到的问题,本发明提供了一种基于ai引擎提取多语种网络音视频数据的方法,能够实现基于带字幕的多语种的音视频、网络电台等大数据自动化提取,降低对标注员素质和专业性要求、降低成本、提高数据制作效率。
技术实现要素:
3.为了解决上述方案存在的问题,本发明提供了一种基于ai引擎提取多语种网络音视频数据的方法。
4.本发明的目的可以通过以下技术方案实现:
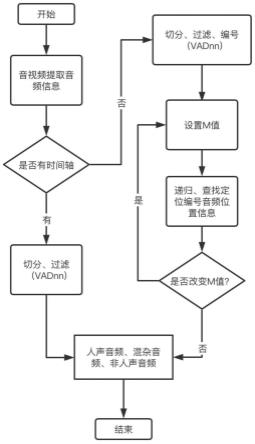
5.一种基于ai引擎提取多语种网络音视频数据的方法,具体步骤包括:
6.步骤一:基于互联网获取目标音视频数据,进行目标音视频数据分类,获得第一数据和第二数据;建立数据库进行储存;
7.步骤二:抽取第一数据的音频数据,使用vadnn算法基于带时间轴的字幕,将各个时间段的音频分类成正常人声音频、人声环境音混杂音频和非人声音频;
8.步骤三:提取第二数据的音频数据,使用vadnn算法将长音频分割成小音频,并从前到后进行编号,编号为001,002,
…
,00t;将切分好的t个音频送入到多语种语音识别引擎进行识别,得到各个编号的音频对应的识别文本,同时结合识别文本和vadnn算法结果,确定切分好的小音频中非人声部分;
9.步骤四:在字幕中查找对应的文本片段,匹配所有切分音频的字幕片段。
10.进一步地,在步骤四中需要进行前提条件和参数设置,具体方法包括:
11.设置最小文本片段,标记为l,识别各个识别文本的长度,将识别文本长度小于l的进行过滤;
12.设置首m长度字符,其中m为动态值,设置初始参数为n。
13.进一步地,通过四种方式在字幕中查找对应的文本片段,分别为:
14.a.识别文本和字幕中一段文本片段完全匹配;
15.b.识别文本的首字符、中字符、尾字符、文本长度特征与字幕中一段文本片段匹配;
16.c.识别文本的首字符、尾字符、文本长度特征与字幕中一段文本片段匹配;
17.d.识别文本的首字符或尾字符、文本长度特征与字幕中一段文本片段匹配;
18.基于上述四种情况,记录当前音频的编号,计算字幕的首、尾位置信息,其中a置信度最高、d置信度最低,结合非人声的音频编号信息,将a、b、c、d条件确定的音频编号信息按照优先级顺序填入t个元素的数组中,高优先级覆盖低优先级;
19.具有两种匹配的情况:
20.a.匹配编号00(i-1)和00(i+1),直接定位到00i编号音频的位置信息;
21.b.匹配编号00(i-2)和00(i+1),其中00(i-1)为非人声,则定位00i编号的音频位置信息;
22.按照上述方式,递归找到所有定位的编号信息,改变m的值,循环确认所有信息,直至找到所有切分音频的字幕片段。
23.进一步地,基于互联网获取目标音视频数据的方法包括:
24.设置目标音视频的限制条件,从互联网中获取具有符合限制条件的目标音视频的网络平台,标记为待选平台,对待选平台进行筛选,获得需要进行对接的待选平台,标记为目标平台;设置数据采集模块,所述数据采集模块包括若干个数据采集单元,将数据采集单元与对应的目标平台进行相关联,所述数据采集单元用于采集对应的相关联的目标平台内的目标音视频数据,并对采集的目标音视频数据进行识别,并打上对应的识别标签。
25.进一步地,对待选平台进行筛选的方法包括:
26.将待选平台标记为j,其中j=1、2、
……
、n,n为正整数;获取待选平台内具有的目标音视频数据量,根据获取的目标音视频数据量匹配对应的数据量级指标,标记为lzj,评估对接对应待选平台的实施成本,标记为cbj,设置质量模型,获取若干个待选平台内的目标音视频数据,并输入到质量模型中进行分析,获得对应质量评分,标记为zpj,根据优先级公式计算对应的优先值,根据计算的优先值进行排序;获取客户的需求量级,根据客户的需求量级和待选平台排序,选择对应的目标平台。
27.进一步地,优先级公式为qj=b1
×
lzj
×
(b2
×
cbj+b3
×
zpj),其中,b1、b2、b3均为比例系数,取值范围为0《b1≤1,0《b2≤1,0《b3≤1。
28.与现有技术相比,本发明的有益效果是:
29.根据客户实际情况建立对应的数据获取渠道,充分利用网络上大量产生的多语种音视频数据,迭代训练多语种ai引擎,极大地减小传统生产数据产生的各种经济和时间成本,实现基于带字幕的多语种的音视频、网络电台等大数据自动化提取,降低对标注员素质和专业性要求、降低成本、提高数据制作效率。
附图说明
30.为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单的介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
31.图1为本发明方法流程图;
32.图2为本发明迭代反哺引擎机制示意图。
具体实施方式
33.下面将结合实施例对本发明的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
34.如图1至图2所示,一种基于ai引擎提取多语种网络音视频数据的方法,具体方法包括:
35.步骤一:基于互联网获取大量的目标音视频数据,进行目标音视频数据分类,获得第一数据和第二数据;建立数据库进行储存;
36.基于互联网获取大量的目标音视频数据的方法包括:
37.设置目标音视频的限制条件,限制条件是个根据ai公司需要进行设置的,从互联网中获取具有符合限制条件的目标音视频的网络平台,标记为待选平台,对待选平台进行筛选,获得需要进行对接的待选平台,标记为目标平台;设置数据采集模块,所述数据采集模块包括若干个数据采集单元,所述数据采集单元的数量与目标平台的数量相同,将数据采集单元与对应的目标平台进行相关联,所述数据采集单元用于采集对应的相关联的目标平台内的目标音视频数据,并对采集的目标音视频数据进行识别,并打上对应的识别标签。
38.数据采集单元是对应目标平台进行设置的,在平台内进行相应的数据采集和识别,识别的其是否带有时间轴的字幕以及其语言种类,因为一般在网络平台内的音视频数据均会有相应的介绍,具有字幕、语言等种类信息,具体的数据采集单元通过现有的技术是可以实现的,且对于部分的网络平台因为运行工作方式相同,是可以使用相同的数据采集单元的,因此不进行详细叙述。
39.对待选平台进行筛选的方法包括:
40.将待选平台标记为j,其中j=1、2、
……
、n,n为正整数;获取待选平台内具有的目标音视频数据量,根据获取的目标音视频数据量匹配对应的数据量级指标,标记为lzj,评估对接对应待选平台的实施成本,标记为cbj,设置质量模型,获取若干个待选平台内的目标音视频数据,并输入到质量模型中进行分析,获得对应质量评分,标记为zpj,根据优先级公式qj=b1
×
lzj
×
(b2
×
cbj+b3
×
zpj)计算对应的优先值,其中,b1、b2、b3均为比例系数,取值范围为0《b1≤1,0《b2≤1,0《b3≤1,根据计算的优先值进行排序;获取客户的需求量级,即根据客户需要目标音视频数据量进行设置的,根据客户的需求量级和待选平台排序,选择对应的目标平台。
41.即根据排序的待选平台对应的数据量级指标进行累加选择。
42.根据获取的目标音视频数据量匹配对应的数据量级指标,由专家组根据可能具有的目标音视频数据量划分不同区间,每个区间设置对应的数据量级指标,进行匹配后即可获得对应的数据量级指标。
43.评估对接对应待选平台的实施成本,根据获取对应目标音视频数的成本、建设成本、运行成本等从对接到获取到的全过程成本,具体的如何确定对应的成本为本领域常识。
44.质量模型是基于cnn网络或dnn网络进行建立的,具体的建立和训练过程为本领域常识。若干个待选平台内的目标音视频数据并不需要进行对接对应的待选平台,因为获取的量少,可以直接从网络中进行获取,而不用耗费实施成本,但是这些方式只能进行评估,
因为通过这种方式的获取效率较低,且数量较少,不符合后续发展需求。
45.在另一个实施例中,可以直接通过现有的方式获取目标音视频数据。
46.进行目标音视频数据种类的方法为以是否带时间轴的字幕方案进行分类;带时间轴的字幕方案的为第一数据,反之为第二数据。
47.步骤二:抽取第一数据的音频数据,使用vadnn算法基于带时间轴的字幕,将各个时间段的音频分类成正常人声音频、人声环境音混杂音频和非人声音频;
48.网络音视频中的音频数据以及对应vadnn算法的工作原理为本领域常识,因此不进行详细叙述。
49.步骤三:提取第二数据的音频数据,使用vadnn算法将长音频分割成小音频,并从前到后进行编号,编号为001,002,
…
,00t;将切分好的t个音频送入到多语种语音识别引擎进行识别,得到各个编号的音频对应的识别文本,同时结合识别文本和vadnn算法结果,确定切分好的小音频中非人声部分;
50.步骤四:在字幕中查找对应的文本片段;
51.进行前提条件和参数设置:
52.过滤掉识别文本长度为l的文本,其中l取值为最小文本片段,避免因为文本片段过小,与字幕中多个片段相匹配,导致定位信息错误的问题;
53.设置首m长度字符,其中m为动态值,如1,2,3,
…
,n;设置初始参数为n;
54.通过四种方式在字幕中查找对应的文本片段:
55.a.识别文本和字幕中某一段文本片段完全匹配;
56.b.识别文本的首字符、中字符、尾字符、文本长度等特征与字幕中某一段文本片段匹配;
57.c.识别文本的首字符、尾字符、文本长度等特征与字幕中某一段文本片段匹配;
58.d.识别文本的首字符或尾字符、文本长度等特征与字幕中某一段文本片段匹配;
59.以上四种情况,记录当前音频的编号,计算字幕的首、尾位置信息,其中a置信度最高、d置信度最低,结合非人声的音频编号信息,将a、b、c、d条件确定的音频编号信息按照优先级顺序填入t个元素的数组中,高优先级覆盖低优先级,具体未公开的部分为本领域常识;出现如下两种匹配的情况:
60.a.匹配编号00(i-1)和00(i+1),可以直接定位到00i编号音频的位置信息;
61.b.匹配编号00(i-2)和00(i+1),其中00(i-1)为非人声,则定位00i编号的音频位置信息;
62.按照以上方式,递归找到所有能够定位的编号信息,改变m的值,循环确认所有信息,直至找到最佳的所有切分音频的字幕片段。
63.上述公式均是去除量纲取其数值计算,公式是由采集大量数据进行软件模拟得到最接近真实情况的一个公式,公式中的预设参数和预设阈值由本领域的技术人员根据实际情况设定或者大量数据模拟获得。
64.以上实施例仅用以说明本发明的技术方法而非限制,尽管参照较佳实施例对本发明进行了详细说明,本领域的普通技术人员应当理解,可以对本发明的技术方法进行修改或等同替换,而不脱离本发明技术方法的精神和范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1