基于WGAN-CNN煤矿井下粉尘浓度预测方法和系统
基于wgan-cnn煤矿井下粉尘浓度预测方法和系统
技术领域
1.本发明涉及煤矿粉尘灾害智能预警技术领域,尤其涉及基于wgan-cnn煤矿井下粉尘浓度预测方法和系统。
背景技术:
2.粉尘灾害是煤矿开采所面临的主要灾害之一。随着机械化水平的提高,煤矿井下粉尘灾害防治工作难度明显增大。与此同时,由于煤矿工作环境恶劣和缺乏职业防护,中国煤工尘肺新增病例仍在以每年1万余例的速度增长。研究表明,呼吸性粉尘是导致尘肺病的罪魁祸首。呼吸性粉尘指所采集的粉尘空气动力学直径均在7.07μm以下,空气动力学直径5μm粉尘的采集效率为50%,并且能进入人体肺泡区的颗粒物,长时间积累会对肺部细胞造成不可逆性破坏,从而危害生命。《“健康中国2030”规划纲要》中明确指出要“建立完善重点职业病监测与职业病危害因素监测、报告和管理网络,遏制尘肺病和职业中毒高发势头”,这对煤矿井下作业现场呼吸性粉尘监测预警技术提出了更高的要求。
3.目前,煤矿现场大多采用呼吸性粉尘采样器进行人工采样、称重或者数值模拟实验等方式实现对矿井呼吸性粉尘危害程度的评估。该方法存在检测周期长、成本高、精度低的问题。同时,由于称重采样时大多是固定点采样而实际作业人员工作点位置在不断变化,导致很难实现煤矿井下作业场所呼吸性粉尘浓度的动态准确预测和反映现场作业人员所在位置的呼吸性粉尘暴露水平,不能对粉尘灾害起到有效监测预警作用。近年来,人工智能技术的快速发展,为煤矿粉尘灾害智能预警技术注入了新的活力。cn114117924a公开了一种生产性粉尘多参量分布式监测与智能预测方法,该方法采用分布式粉尘监测网络,并综合利用多元回归分析方法、主成因分析方法和长短期记忆网络方法实现了对生产性粉尘的时空分布的智能预测,但是该方法存在数据监测节点布置随机性较大和预测精度不明晰的问题,难以保证其现场长时间应用的可靠性。cn113009074a公开了一种基于卷积神经网络算法的隧道空气质量监测方法,该方法利用卷积神经网络模型(cnn)实现了对隧道内包括粉尘浓度在内的多种空气质量环境参数的准确预测,具有方法步骤简单、实现方便的特点,但是由于煤矿粉尘监测数据存在数据量失真、可靠性差等问题,无法提供cnn网络训练需要的大量有效数据,阻碍了该类预测方法在煤矿粉尘预测领域的推广应用。因此,从现有对煤矿呼吸性粉尘的采集方法来看,仍存在效率低、准确度差、实时性不强的问题;从运用人工智能新方法预测呼吸性粉尘浓度方面来看,缺少大量可靠数据是制约这类方法提高其预测精度和推广应用的关键因素。这些问题导致煤矿现场难以有效掌握井下作业场所的呼吸性粉尘危害程度和作业人员的呼吸性粉尘暴露水平,进而阻碍了煤矿粉尘灾害防治和职业危害防护工作的有效开展。
技术实现要素:
4.本方案针对上文提出的问题和需求,提出一种基于wgan-cnn煤矿井下粉尘浓度预测方法和系统,由于采取了如下技术特征而能够实现上述技术目的,并带来其他多项技术
效果。
5.本发明的一个目的在于提出一种基于wgan-cnn煤矿井下粉尘浓度预测方法,包括如下步骤:
6.s10:采集煤矿井下呼吸性粉尘及其特征参量监测数据,按照类别标签将相关监测数据分割成不同的数据子集,并对其进行筛分和标准化处理,形成原始数据集并记为“real”;
7.s20:构建wgan网络模型,所述wgan网络包括判别器d和生成器g,将原始数据集输入判别器d预览,使判别器d具备从随机噪声中区分原始数据的能力,再将随机噪声输入生成器g并使生成器g输出正确的数据格式,然后按照需求确定需要生成的新的数据总量;
8.s30:对wgan网络模型中的生成器g和判别器d进行多次交叉迭代训练,使得不断训练迭代训练之后的判别器d和生成器g的损失函数值降低,直至达到纳什平衡并产生分布与原始数据集相同的数据集,记为“fake”;
9.s40:将wgan网络模型的生成数据集“fake”与原始数据集“real”混合,新的混合数据排列为与原始数据集具有相同的二维数组的形式,记为“mixture”,将其一部分用作为cnn回归预测网络的训练数据集,记为“train”,另一部分用作为cnn回归预测网络的测试数据集,记为“test”;
10.s50:将训练数据集“train”输入cnn回归预测网络中进行多次迭代训练,每次迭代过程cnn回归网络通过前向训练和反向传播运算提取数据分布特征并更新权值,多次迭代之后,cnn网络得到最优模型并保存其相关参数;
11.s60:将测试数据集输入基于wgan网络模型和cnn回归预测网络模型得到的煤矿井下呼吸性粉尘浓度预测模型预测呼吸性粉尘浓度,然后计算预测数值和测试集数据的相关性差异并确定该模型的可靠性;
12.s70:获取煤矿井下呼吸性粉尘及其特征参量的实时数据,先将实时数据输入步骤s10中处理,然后输入上述经过可靠性验证的煤矿井下呼吸性粉尘浓度预测模型,实现对煤矿井下呼吸性粉尘浓度的动态精准预测。
13.另外,根据本发明的基于wgan-cnn煤矿井下粉尘浓度预测方法,还可以具有如下技术特征:
14.在本发明的一个示例中,在所述步骤s10中,所述呼吸性粉尘的特征参量包括:呼吸性粉尘粒径分布、风速、湿度、煤层硬度、切割速度、巷道截面积和操作者位置。
15.在本发明的一个示例中,在步骤s10中,对所述数据子集进行筛分和标准化处理包括:
16.依据拉依达准则剔除测量结果误差绝对值大于3倍标准差的测量数据,采用最大-最小标准化方法对筛分后数据进行归一化处理,然后将呼吸性粉尘浓度的数据子集作为标签y,其余数据子集作为特征参量x1~xn。
17.在本发明的一个示例中,在所述步骤s20中,
18.所述判别器d包括:3个全连接层和2个激活函数层,其中,所述全连接层和所述激活函数层依次交替串接,配置为提取特征信息并使其具有非线性关系。
19.在本发明的一个示例中,在所述步骤s20中,
20.所述生成器g包括:3个全连接层、3个激活函数层和2个bn层,其中,所述全连接层
和所述激活函数层依次交替串接,其中一个bn层串接在第二个激活函数层和第三个全连接层之间,其中另一个bn层与第三个激活函数层串接。
21.在本发明的一个示例中,在所述步骤s30中,
22.多次交叉迭代训练中每次迭代首先用原始数据集训练判别器d之后,再用生成器g生成的数据训练判别器d并计算判别器d的误差梯度,然后根据误差梯度传回的损失训练生成器g并产生新数据集。
23.在本发明的一个示例中,在步骤s50中,所述cnn回归预测网络模型包括:
24.依次串接的3个卷积层和2个全连接层,配置为对输入数据进行卷积运算,从中提取数据分布特征并将其输入到全连接层中完成前向训练过程,然后通过反向传播更新卷积层的权值和偏置获得预测误差。
25.本发明的另一个目的在于提出一种基于wgan-cnn煤矿井下粉尘浓度预测系统,其特征在于,包括:
26.数据采集与处理模块,用于采集煤矿井下呼吸性粉尘及其特征参量监测数据,按照类别标签将相关监测数据分割成不同的数据子集,并对其进行筛分和标准化处理,形成原始数据集并记为“real”;
27.建立模型模块,用于构建wgan网络模型,所述wgan网络包括判别器d和生成器g,将原始数据集输入判别器d预览,使判别器d具备从随机噪声中区分原始数据的能力,再将随机噪声输入生成器g并使生成器g输出正确的数据格式,然后按照需求确定需要生成的新的数据总量;
28.训练模型模块,用于对wgan网络模型中的生成器g和判别器d进行多次交叉迭代训练,使得不断训练迭代训练之后的判别器d和生成器g的损失函数值降低,直至达到纳什平衡并产生分布与原始数据集相同的数据集,记为“fake”;
29.数据更新与划分模块,用于将wgan网络模型的生成数据集“fake”与原始数据集“real”混合,新的混合数据排列为与原始数据集具有相同的二维数组的形式,记为“mixture”,将其一部分用作为cnn回归预测网络的训练数据集,记为“train”,另一部分用作为cnn回归预测网络的测试数据集,记为“test”;
30.cnn回归预测模型训练模块,用于将训练数据集“train”输入cnn回归预测网络中进行多次迭代训练,每次迭代过程cnn回归网络通过前向训练和反向传播运算提取数据分布特征并更新权值,多次迭代之后,cnn网络得到最优模型并保存其相关参数;
31.预测模型建立模块,用于将测试数据集输入基于wgan网络模型和cnn回归预测网络模型得到的煤矿井下呼吸性粉尘浓度预测模型预测呼吸性粉尘浓度,然后计算预测数值和测试集数据的相关性差异并确定该模型的可靠性;
32.粉尘浓度预测模块,用于获取煤矿井下呼吸性粉尘及其特征参量的实时数据,先将实时数据输入数据采集与处理模块中处理,然后输入预测模型建立模块中经过可靠性验证的煤矿井下呼吸性粉尘浓度预测模型,实现对煤矿井下呼吸性粉尘浓度的动态精准预测。
33.在本发明的一个示例中,所述预测模型建立模块还包括:
34.可靠性检验单元,用于将测试数据集输入煤矿井下粉尘浓度预测模型中获得预测数据集,计算预测数据集和测试集数据的相关性差异并确定该模型的可靠性。
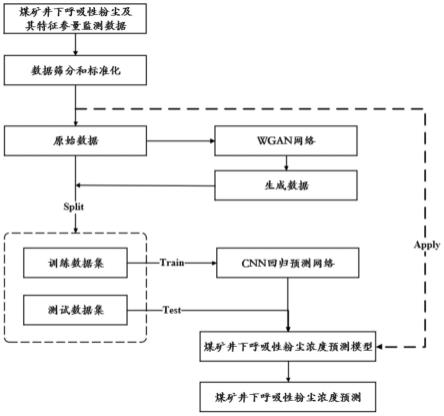
35.在本发明的一个示例中,所述判别器d包括:3个全连接层和2个激活函数层,其中,所述全连接层和所述激活函数层依次交替串接,配置为提取特征信息并使其具有非线性关系。
36.与现有技术相比,本发明具有以下优点:
37.1、充分利用wgan生成对抗网络强大的数据增广能力,能够对煤矿井下呼吸性粉尘及其特征参量进行数据增广得到大量分布特征与原始数据相同的数据,解决了由煤矿粉尘监测数据可靠性差和人工采样效率低下导致的煤矿现场难以获取大量可靠呼吸性粉尘浓度数据的问题,为应用cnn卷积神经网络预测煤矿井下作业场所呼吸性粉尘浓度提供了数据支撑。
38.2、在wgan的基础上融合cnn卷积神经网络,实现了数据增广,并将扩展后的数据集应用于cnn卷积神经网络。随着数据量的增大,预测模型能更充分的学习数据的分布特征,使得预测模型的精度得以提高,然后应用基于本发明的煤矿井下呼吸性粉尘浓度预测模型可以实现煤矿呼吸性粉尘的动态精确预测,解决现有手段难以准确预测煤矿井下作业场所呼吸性粉尘浓度的问题,对于帮助掌握煤矿作业场所的呼吸性粉尘危害程度和反映作业人员呼吸性粉尘暴露水平具有较好的推广和应用价值。
39.下文中将结合附图对实施本发明的最优实施例进行更加详尽的描述,以便能容易理解本发明的特征和优点。
附图说明
40.为了更清楚地说明本发明实施例的技术方案,下文中将对本发明实施例的附图进行简单介绍。其中,附图仅仅用于展示本发明的一些实施例,而非将本发明的全部实施例限制于此。
41.图1为根据本发明实施例的基于wgan-cnn的煤矿井下粉尘浓度预测方法的流程图;
42.图2为根据本发明实施例的基于wgan-cnn的煤矿井下粉尘浓度预测方法的模型结构图;
43.图3为根据本发明实施例的wgan网络的生成器和判别器结构图;
44.图4为据本发明实施例的cnn回归预测网络模型结构图;
45.图5为根据本发明实施例的基于本发明的石壕煤矿综采面呼吸性粉尘预测结果测试图。
具体实施方式
46.为了使得本发明的技术方案的目的、技术方案和优点更加清楚,下文中将结合本发明具体实施例的附图,对本发明实施例的技术方案进行清楚、完整地描述。附图中相同的附图标记代表相同部件。需要说明的是,所描述的实施例是本发明的一部分实施例,而不是全部的实施例。基于所描述的本发明的实施例,本领域普通技术人员在无需创造性劳动的前提下所获得的所有其他实施例,都属于本发明保护的范围。
47.根据本发明第一方面的一种基于wgan-cnn煤矿井下粉尘浓度预测方法,如图1和图2所示,包括如下步骤:
48.s10:采集煤矿井下呼吸性粉尘及其特征参量监测数据,按照类别标签将相关监测数据分割成不同的数据子集,并对其进行筛分和标准化处理,形成原始数据集并记为“real”;
49.在本发明的一个示例中,在所述步骤s10中,所述呼吸性粉尘的特征参量包括:呼吸性粉尘粒径分布、风速、湿度、煤层硬度、切割速度、巷道截面积和操作者位置;需要说明的是特征参量包括但不限于上述参数,井下参数获取要根据实际技术条件而定。
50.在本发明的一个示例中,在步骤s10中,对所述数据子集进行筛分和标准化处理包括:
51.依据拉依达准则剔除测量结果误差绝对值大于3倍标准差的测量数据,采用最大-最小标准化方法对筛分后数据进行归一化处理,然后将呼吸性粉尘浓度的数据子集作为标签y,其余数据子集作为特征参量x1~xn。
52.采集煤矿井下呼吸性粉尘及其特征参量监测数据,特征参量可以根据井下现有与呼吸性粉尘浓度相关监测数据进行选取,包括呼吸性粉尘粒径分布、风速、湿度、煤层硬度、切割速度、巷道截面积和操作者位置等。本实施例通过相关文献调研,获取重庆市石壕煤矿采煤工作面的呼吸性粉尘浓度、煤层硬度、切割速度、巷道截面积、湿度、风速、呼吸性粉尘粒径分布和操作者位置作为原始数据集,记为“real”。该数据集已完成数据子集划分,并通过拉依达准则(pauta criterion)剔除测量结果误差绝对值大于3倍标准差的测量数据,然后采用最大-最小标准化方法(min-max normalization)对筛分后数据进行归一化处理。本实施例将呼吸性粉尘浓度数据子集作为标签y,煤层硬度数据子集作为特征参量x1,切割速度作为特征参量x2,巷道截面积数据子集作为特征参量x3,湿度数据子集作为特征参量x4,风速数据子集作为特征参量x5,呼吸性粉尘粒径分布数据子集作为特征参量x6,操作者位置数据子集作为特征参量x7;
53.s20:构建wgan网络模型,所述wgan网络包括判别器d和生成器g,将原始数据集输入判别器d预览,使判别器d具备从随机噪声中区分原始数据的能力,再将随机噪声输入生成器g并使生成器g输出正确的数据格式,然后按照需求确定需要生成的新的数据总量;
54.例如,在本发明的一个示例中,在所述步骤s20中,如图3所示,
55.所述判别器d包括:3个全连接层和2个激活函数层,其中,所述全连接层和所述激活函数层依次交替串接,配置为提取特征信息并使其具有非线性关系。
56.例如,在本发明的一个示例中,在所述步骤s20中,如图3所示,
57.所述生成器g包括:3个全连接层、3个激活函数层和2个bn层(batchnorm1d),其中,所述全连接层和所述激活函数层依次交替串接,其中一个bn层串接在第二个激活函数层和第三个全连接层之间,其中另一个bn层与第三个激活函数层串接。
58.采用wasserstein距离作为损失函数,并选择leakyrelu激活函数和rmsprop优化算法。wasserstein距离也称作em距离,相较于基于js散度的gan网络,em距离可以产生一个连续可用的梯度,这有利于达到原始数据分布和生成数据分布重合的目的,其表达式如下所示:
[0059][0060]
其中pr和pg分别是原始数据分布和生成数据分布,π(pr,pg)是原始数据和生成
数据的联合概率分布。
[0061]
leakyrelu激活函数作为判别器d线性层之间的非线性激活函数,计算效率高,允许网络快速收敛,并且解决了relu函数的神经元死亡问题,其表达式如下所示:
[0062][0063]
其中α是一个很小的常数,表示一个很小的梯度。
[0064]
rmsprop优化算法是一种自适应学习率方法,采用指数加权平均的方式消除梯度下降中的摆动,可有效避免不稳定和陷入局部最优的问题出现,其表达式如下所示:
[0065][0066][0067]
其中
⊙
表示矩阵逐元素相乘,表示权重梯度矩阵,η表示学习率,的加权平均和。
[0068]
在判别器d构建完成过后,将步骤s10中整合好的原始数据集real输入判别器d预览,使判别器d具备从随机噪声中区分原始数据的能力。再将随机噪声输入构建好的生成器g中并使生成器g输出正确的数据格式,本实施例中生成器g包括3个全连接层,选择leakyrelu激活函数和rmsprop优化算法,并采用batchnormld算法加速收敛速度和提高网络训练稳定性。在训练好判别器d和生成器g之后,按照实际需求,本实施例确定需要的数据总量为3000。
[0069]
s30:对wgan网络模型中的生成器g和判别器d进行多次交叉迭代训练,使得不断训练迭代训练之后的判别器d和生成器g的损失函数值降低,直至达到纳什平衡并产生分布与原始数据集相同的数据集,记为“fake”;
[0070]
在本发明的一个示例中,在所述步骤s30中,
[0071]
多次交叉迭代训练中每次迭代首先用原始数据集训练判别器d之后,再用生成器g生成的数据训练判别器d并计算判别器d的误差梯度,然后根据误差梯度传回的损失训练生成器g并产生新数据集。
[0072]
具体地,对wgan模型中的生成器g与判别器d进行多次交叉迭代训练,具体训练次数可根据实际情况调整,每次迭代首先用原始数据训练判别器d之后,再用生成器g生成的数据训练判别器d并计算判别器d的误差梯度,然后根据误差梯度传回的损失训练生成器g并产生新数据集,不断迭代之后判别器d和生成器g的损失函数值降低,直到达到纳什平衡并产生分布与原始数据集相同的数据集,记为“fake”,通过计算得到生成数据和原始数据的r2复相关系数为0.9737,这说明通过所述步骤s30构建的wgan网络已经具备强大的数据增广能力,生成数据的分布特征与原始数据基本一致。
[0073]
s40:将wgan网络模型的生成数据集“fake”与原始数据集“real”混合,新的混合数据排列为与原始数据集具有相同的二维数组的形式,记为“mixture”,将其一部分用作为cnn回归预测网络的训练数据集,记为“train”,另一部分用作为cnn回归预测网络的测试数据集,记为“test”;
[0074]
例如,按照7:3的比例,将其70%用作为cnn回归预测网络的训练数据集,记为“train”,其30%用作为cnn回归预测网络的测试数据集,记为“test”。
[0075]
s50:将训练数据集“train”输入cnn回归预测网络中进行多次迭代训练,每次迭代过程cnn回归网络通过前向训练和反向传播运算提取数据分布特征并更新权值,多次迭代之后,cnn网络得到最优模型并保存其相关参数;
[0076]
在本发明的一个示例中,在步骤s50中,所述cnn回归预测网络模型包括:
[0077]
依次串接的3个卷积层和2个全连接层,配置为对输入数据进行卷积运算,从中提取数据分布特征并将其输入到全连接层中完成前向训练过程,然后通过反向传播更新卷积层的权值和偏置获得预测误差。可以理解的是,本发明中的全连接层用的函数都是一个,但是里面参数不一样。
[0078]
如图4所示,首先构建cnn卷积神经网络模型,本实施例中cnn网络包括3个一维卷积层和2个全连接层,采用adam优化算法,并选择leakyrelu激活函数和mseloss损失函数。mseloss损失函数又称均方误差损失函数,是回归损失函数中最常用的误差。mseloss损失是预测值f(x)与目标值y之间差值平方和的均值,其公式如下所示:
[0079][0080]
cnn回归预测网络构建完毕后,将步骤s40中生成的训练数据集train,输入cnn回归预测网络中进行多次迭代训练,具体训练次数可根据实际情况调整,本实施例中迭代次数设置为2000,学习率设置为0.001。cnn回归预测网络首先对输入数据进行卷积运算,再通过激活函数从中提取数据分布特征并将其输入到全连接层中完成前向训练过程,然后通过反向传播更新卷积层的权值和偏置实现预测误差为0.0332,这表明该模型在训练数据集train上表现优异,可以作为最优模型保存其相关参数并输出。
[0081]
s60:将测试数据集输入基于wgan网络模型和cnn回归预测网络模型得到的煤矿井下呼吸性粉尘浓度预测模型预测呼吸性粉尘浓度,然后计算预测数值和测试集数据的相关性差异并确定该模型的可靠性;
[0082]
具体地,步骤s40所述的测试数据集test在进行本步骤之前不能参与其他训练过程并不被改动。将测试数据集test中的数据输入基于wgan网络和cnn回归预测网络训练得到的呼吸性粉尘浓度预测模型,然后在测试集条件下预测石壕煤矿采煤工作面的呼吸性粉尘浓度并计算其r2复相关系数。如图5所示,基于本发明的石壕煤矿采煤工作面呼吸性粉尘浓度预测值和测试数据集中的分布特征基本一致,两者r2复相关系数为0.9126,准确度优于行业标准,这表明基于本发明得到的煤矿井下呼吸性粉尘浓度预测模型可靠性较高,能够反映煤矿井下呼吸性粉尘浓度发展态势。
[0083]
s70:获取煤矿井下呼吸性粉尘及其特征参量的实时数据,先将实时数据输入步骤s10中处理,然后输入上述经过可靠性验证的煤矿井下呼吸性粉尘浓度预测模型,实现对煤矿井下呼吸性粉尘浓度的动态精准预测。
[0084]
本发明充分利用wgan生成对抗网络强大的数据增广能力,能够对煤矿井下呼吸性粉尘及其特征参量进行数据增广得到大量分布特征与原始数据相同的数据,解决了由煤矿粉尘监测数据可靠性差和人工采样效率低下导致的煤矿现场难以获取大量可靠呼吸性粉尘浓度数据的问题,为应用cnn卷积神经网络预测煤矿井下作业场所呼吸性粉尘浓度提供了数据支撑;在wgan的基础上融合cnn卷积神经网络,实现了数据增广,并将扩展后的数据
集应用于cnn卷积神经网络。随着数据量的增大,预测模型能更充分的学习数据的分布特征,使得预测模型的精度得以提高,然后应用基于本发明的煤矿井下呼吸性粉尘浓度预测模型可以实现煤矿呼吸性粉尘的动态精确预测,解决现有手段难以准确预测煤矿井下作业场所呼吸性粉尘浓度的问题,对于帮助掌握煤矿作业场所的呼吸性粉尘危害程度和反映作业人员呼吸性粉尘暴露水平具有较好的推广和应用价值。
[0085]
根据本发明第二方面的一种基于wgan-cnn煤矿井下粉尘浓度预测系统,包括:
[0086]
数据采集与处理模块,用于采集煤矿井下呼吸性粉尘及其特征参量监测数据,按照类别标签将相关监测数据分割成不同的数据子集,并对其进行筛分和标准化处理,形成原始数据集并记为“real”;
[0087]
建立模型模块,用于构建wgan网络模型,所述wgan网络包括判别器d和生成器g,将原始数据集输入判别器d预览,使判别器d具备从随机噪声中区分原始数据的能力,再将随机噪声输入生成器g并使生成器g输出正确的数据格式,然后按照需求确定需要生成的新的数据总量;
[0088]
训练模型模块,用于对wgan网络模型中的生成器g和判别器d进行多次交叉迭代训练,使得不断训练迭代训练之后的判别器d和生成器g的损失函数值降低,直至达到纳什平衡并产生分布与原始数据集相同的数据集,记为“fake”;
[0089]
数据更新与划分模块,用于将wgan网络模型的生成数据集“fake”与原始数据集“real”混合,新的混合数据排列为与原始数据集具有相同的二维数组的形式,记为“mixture”,将其一部分用作为cnn回归预测网络的训练数据集,记为“train”,另一部分用作为cnn回归预测网络的测试数据集,记为“test”;
[0090]
cnn回归预测模型训练模块,用于将训练数据集“train”输入cnn回归预测网络中进行多次迭代训练,每次迭代过程cnn回归网络通过前向训练和反向传播运算提取数据分布特征并更新权值,多次迭代之后,cnn网络得到最优模型并保存其相关参数;
[0091]
预测模型建立模块,用于将测试数据集输入基于wgan网络模型和cnn回归预测网络模型得到的煤矿井下呼吸性粉尘浓度预测模型预测呼吸性粉尘浓度,然后计算预测数值和测试集数据的相关性差异并确定该模型的可靠性;
[0092]
粉尘浓度预测模块,用于获取煤矿井下呼吸性粉尘及其特征参量的实时数据,先将实时数据输入数据采集与处理模块中处理,然后输入预测模型建立模块中经过可靠性验证的煤矿井下呼吸性粉尘浓度预测模型,实现对煤矿井下呼吸性粉尘浓度的动态精准预测。
[0093]
在本发明的一个示例中,所述预测模型建立模块还包括:
[0094]
可靠性检验单元,用于将测试数据集输入煤矿井下粉尘浓度预测模型中获得预测数据集,计算预测数据集和测试集数据的相关性差异并确定该模型的可靠性。
[0095]
在本发明的一个示例中,所述判别器d包括:3个全连接层和2个激活函数层,其中,所述全连接层和所述激活函数层依次交替串接,配置为提取特征信息并使其具有非线性关系。
[0096]
以上结果表明,通过本发明公开的一种基于wgan-cnn的煤矿井下呼吸性粉尘的预测系统,能够对煤矿井下呼吸性粉尘及其特征参量进行数据增广得到大量分布特征与原始数据相同的数据,解决了由煤矿粉尘监测数据可靠性差和人工采样效率低下导致的煤矿难
以获取大量可靠呼吸性粉尘浓度数据的问题。同时,通过应用cnn卷积神经网络得到的煤矿井下呼吸性粉尘浓度预测模型,实现了对煤矿井下作业环境中呼吸性粉尘浓度的动态精准预测,解决了现有手段难以准确预测煤矿井下作业场所呼吸性粉尘浓度的问题,对于帮助掌握煤矿作业场所的呼吸性粉尘危害程度和反映作业人员呼吸性粉尘暴露水平具有较好的推广和应用价值。
[0097]
上文中参照优选的实施例详细描述了本发明所提出的基于wgan-cnn煤矿井下粉尘浓度预测方法和系统的示范性实施方式,然而本领域技术人员可理解的是,在不背离本发明理念的前提下,可以对上述具体实施例做出多种变型和改型,且可以对本发明提出的各种技术特征、结构进行多种组合,而不超出本发明的保护范围,本发明的保护范围由所附的权利要求确定。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1