一种基于深度学习的轻量级车辆检测方法
1.本发明属于图像处理及目标检测技术领域,具体涉及一种基于深度学习的轻量级车辆检测方法。
背景技术:
2.车辆检测属于通用目标检测领域的一个分支,它通过对车载摄像头的视频数据进行特征提取和分类,从而检测出轿车,卡车,货车等车辆目标,为ids提供周边车辆位置,类别,大小等信息供其进行智能决策。
3.深度学习的出现极大地推动了目标检测领域的发展,凭借着深度神经网络(deep neural networks,dnn)强大的特征提取能力,基于深度学习的目标检测算法迅速成为研究主流。尽管这类算法虽然准确率较高,但常见的算法的网络结构复杂、参数量大、计算量大,而汽车搭载的处理器性能有限,在运行这类复杂的算法时,无法满足实时性需求。而目前常见的轻量级检测算法如yolov4-tiny,nanodet等,对车辆目标检测的准确率较低。
技术实现要素:
4.为了克服上述现有技术存在的缺陷,本发明的目的在于提出一种基于深度学习的轻量级车辆检测方法,一方面能够减小算法模型的参数量和计算量,另一方面提升了检测模型的准确率,具有实时性好、计算量小、准确率高的优点,能够很好地在车载设备上进行实时车辆检测任务。
5.为了实现上述目的,本发明采用的技术方案是:
6.一种基于深度学习的轻量级车辆检测方法,具体包括以下步骤:
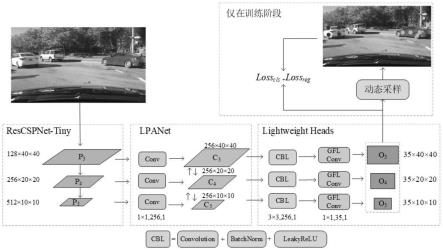
7.步骤1.输入待检测的车载视频图像数据;
8.步骤2.将步骤1输入的图像通过包括随机的翻转,亮度增强,对比度增强,饱和度增强,标准化,尺度缩放,拉伸方法进行预处理;
9.步骤3.将步骤2预处理过的图像输入到轻量级骨干网络rescspnet
‑ꢀ
tiny进行多次下采样特征提取,并输出经过下采样特征提取后的多尺度特征pi;
10.步骤4.通过轻量级的路径聚合网络lpanet对步骤3得到的多尺度特征pi进行融合,并输出融合之后的多尺度特征ci;
11.步骤5.通过多尺度的预测子网络对步骤4得到的多尺度特征ci进一步处理,得到最终的多尺度预测值oi;
12.步骤6.对步骤5得到的多尺度预测值oi进行解码,得到预测的目标类别得分score与位置信息pre
box
;
13.步骤7.进行正负样本标签划分,计算获得正负样本的标签;然后通过gfl和giou进行损失计算,采用反向传播算法迭代更新模型参数,最终完成算法模型的训练;
14.步骤8.在算法模型的实际使用阶段,直接将步骤6得到的目标类别得分score与位置信息pre
box
通过nms处理过后输出车辆检测的结果。
15.所述步骤3具体为:通过对轻量级骨干网络rescspnet-tiny的特征提取单元,进行多次下采样特征提取,输出多尺度特征pi:
16.第一特征提取单元,用于将输入图像依次经过切片操作、标准卷积层,得到特征图p1;
17.第二特征提取单元,用于将第一特征提取单元输出的特征图p1经过浅层残差模块和下采样模块,得到特征图p2;
18.第三特征提取单元,用于将第二特征提取单元输出的特征图p2经过浅层残差模块和下采样模块,得到特征图p3;
19.第四特征提取单元,用于将第三特征提取单元输出的特征图p3经过跨层级局部模块和下采样模块,得到特征图p4;
20.第五特征提取单元,用于将第四特征提取单元输出的特征图p4经过跨层级局部模块和下采样模块,得到特征图p5。
21.所述步骤4具体为:
22.将步骤3中得到的多尺度特征图p3,p4,p5分别通过卷积层,变换通道维度;
23.构建自上而下的特征融合路径,通过双线性插值的操作来完成对多尺度特征图p4,p5的上采样,通过相加操作来完成不同尺度特征间的融合,得到多尺度特征图h3,h4,h5;
24.构建自下而上的特征融合路径,通过双线性插值的操作来完成对多尺度特征图h3,h4的下采样,通过相加操作来完成不同尺度特征间的融合,得到多尺度特征图c3,c4,c5。
25.所述步骤5具体为:
26.对多尺度特征图c3,c4,c5依次通过卷积层、批量归一化层、激活函数层和卷积层后,得到最终的多尺度预测值o3,o4,o5。
27.所述步骤7具体为:
28.1).自定义设置深度学习网络训练超参数样本集;
29.2).将步骤7第1)步训练样本集中batch张图像输入到构建的网络中进行前向传播,得到预测的多尺度特征oi;
30.3).解码步骤7第2)步得到的多尺度特征oi中的不同尺度特征的预测信息:
31.3.1)对多尺度特征oi在通道维度进行划分,得到维度为n的质量预测值pre
cls
和维度为4*regmax边框回归预测值pre
box
;
32.3.2)对于一个s
×
s尺寸的多尺度特征oi,将这s2个特征点映射回原图中,得到预设锚点a的坐标;
33.3.3)对于质量预测pre
cls
,在通道维度通过sigmoid函数激活之后,得到每一个锚点位置对应类别的分类预测得分score;
34.3.4)对于边框回归预测pre
box
,其值代表当前锚点a
xy
距离预测框4条边的距离(t,r,b,l),采用一个长度为regmax的一维向量v来表示;将每条边的距离向量v进行softmax函数之后,每个位置的值就代表其处在当前位置的概率,最终实际的距离distance,采用期望的方式来计算;
35.4)进行正负样本标签划分:
36.4.1)初始化质量预测的目标标签label
cls
,边框回归的目标标签label
reg
;
37.4.2)通过步骤7第3.1)步得到的回归预测值pre
box
得到距离向量 (t,r,b,l),然后将其与p
xy
进行解码,得到算法预测的目标框anchor;
38.4.3)选出所有中心点p落入gt
box
内的p及其对应的anchor,记为p
candidate
, anchor
candidate
,将p
candidate
的label
cls
置为对应gt
box
的gt
label
;
39.4.4)计算所有anchor
candidate
与gt
box
的iou,记为score
iou
;计算iou的代价cost
iou
=-log(score
iou
);
40.4.5)对于p
candidate
的label值与score
iou
相乘,得到label
soft
,并令label
cls
=label
soft
;
41.4.6)对于anchor
candidate
,计算其质量score与label
soft
的交叉熵损失,记为cost
cls
;
42.4.7)计算anchor
candidate
的代价矩阵m=cost
cls
+cost
iou
;
43.4.8)根据设置的k值,对每个gt
box
选取score
iou
中前k个anchor
candidate
,记为anchork,计算anchork的score
iou
之和,并且向下取整,得到了每个gt
box
应该分配锚框数n;
44.4.9)根据每个gt
box
需要分配的数量n,对每个gt
box
选取m中前n小的 anchor
candidate
作为正样本,其余视为负样本,根据正负样本选择对label
reg
进行填充;
45.4.10)如果存在一个anchor
candidate
被多个gt
box
选择的情况,选择m中最小值对应的gt
box
作为其目标,其他gt
box
舍去;
46.4.11)返回划分的样本标签label
cls
,label
reg
;
47.5)定义广义焦点损失函数gfl,计算预测框与对应样本的损失值:
48.5.1)对于多尺度预测值oi中的分类预测值,采用qfl进行分类质
49.量预测的损失计算,其计算方式如公式(1.1)所示;
50.loss
cls
=loss
qfl
51.loss
qfl
(σ)=-|y-σ|
β
((1-y)log(1-σ)+ylog(σ))
ꢀꢀꢀꢀ
(1.1)
[0052][0053]
其中,y为真实的质量标签,其值是[0,1]之间的连续值,对于正样本其值是预测框与真实目标框的iou值,对于负样本其值是0;σ为当前网络的分类预测得分,即分类预测值通过函数激活之后的数值,β为权重系数;
[0054]
5.2)对于多尺度特征oi中的边框回归预测值,仅针对正样本进行回归损失计算,边框回归分支的损失构成如公式(1.2)所示;
[0055]
loss
reg
=loss
dfl
+loss
giou
ꢀꢀꢀ
(1.2)
[0056]
5.2.1)采用dfl对于边框回归预测值的概率分布进行损失计算,对于边框概率的分布进行学习,优化最接近目标位置两侧的概率值,从而让模型能够快速地聚焦到目标位置的邻近区域的分布中去,dfl的计算方式如公式(1.3)所示:
[0057]
loss
dfl
(si,s
i+1
)=-((y
i+1-y)log(si)+(y-yi)log(s
i+1
))
ꢀꢀꢀꢀ
(1.3)
[0058][0059]
其中,y表示目标位置的下标,yi表示目标位置左侧位置下标,y
i+1
表示右侧位置下标,为yi位置的概率,为y
i+1
位置的概率;
[0060]
5.2.2)对边框回归预测值,进行解码后得到目标框的位置信息,通过giou损失函
数对预测出的目标框信息与真实的目标框信息直接进行损失计算,其计算过程如公式(1.4)所示:
[0061][0062]
其中a,b分别为预测框和真实框,c为包含a,b的最小外接矩形框;
[0063]
5.3)最终,将qfl,dfl,giou损失计算结果进行相加,就得到了最终的损失函数,其具体的构成如公式(1.5)所示:
[0064]
loss=w1loss
qfl
+w2loss
dfl
+w3loss
giou
ꢀꢀ
(1.5)
[0065]
其中,w1,w2,w3分别表示不同损失的权重。
[0066]
所述步骤8具体为:
[0067]
1)将实际使用场景中的图像即测试样本集按自定义的大小调整后,依次输入到训练好的深度学习网络进行前向传播,得到每张图像的预测类别和预测框坐标;
[0068]
2)采用非极大值抑制法,筛选掉重叠的预测框,使用最终的预测框在图像上标记出目标的位置和类别:
[0069]
2.1)设置筛选阈值n;
[0070]
2.2)用所有预测框构成初始预测框集合b;
[0071]
2.3)创建最终预测框集合d,并将其初始化为空集;
[0072]
2.4)将预测框与真实框的iou值和预测类别概率相乘作为置信度,并按照置信度对集合b中的预测框按照降序排序;
[0073]
2.5)选取第一个预测框,添加到集合d中,再将其从集合b中删除;
[0074]
2.6)遍历集合b中的所有预测框,计算它们与d集合中的最终预测框的iou值,若iou值大于阈值n,则将其从集合b中删除;
[0075]
2.7)重复步骤2.5)~2.6)直到集合b为空;
[0076]
2.8)输出集合d中的元素作为最终的预测框,并使用最终的预测框在该图像中标记出目标的位置和类别,完成目标检测。
[0077]
本发明的有益效果是:
[0078]
第一,本发明使用rescspnet-tiny网络作为主干网络,在大幅度降低了深度学习网络的参数量,保证了骨干网络的特征提取能力,使得本发明可以在资源受限的设备上部署应用,在具有较高的检测速度的同时,拥有较高的检测精度。
[0079]
第二,本发明使用lpanet网络作为特征融合网络,在大幅度降低了特征融合层计算复杂度的同时,保证了算法模型对尺度变化物体的检测能力。
[0080]
第三,本发明建立的轻量级车辆检测算法,在保证算法模型轻量化的同时,大幅度提升了算法对复杂驾驶场景下车辆目标的检测能力。
附图说明
[0081]
图1是本发明的实现流程图。
[0082]
图2是本发明构建的rescspnet-tiny网络结构图。
[0083]
图3是本发明构建的浅层残差单元与resnet中残差单元的对比图。
[0084]
图4是本发明构建的浅层跨层级局部结构框架图。
[0085]
图5是本发明中轻量级特征融合lpanet网络结构图。
[0086]
图6是本发明中轻量级多尺度预测子网络结构图。
[0087]
图7是本发明与现有技术检测效果对比图,其中,(a)为本发明算法法检测效果,(b)为采用yolov4-tiny-416算法检测效果,(c) 为采用nanodet-m算法检测效果。
具体实施方式
[0088]
下面结合附图对本发明进一步详细描述。
[0089]
参见图1,一种基于深度学习的轻量级车辆检测方法,包括以下
[0090]
具体步骤:
[0091]
(1)获取车辆数据集
[0092]
从网络上下载bdd数据集,其包含了道路目标检测,可实行区域划分,车道线标记,实例分割4种图像注释;包含了下雪、雾天、晴天、多云、阴天、下雨6种天气,主要以晴天为主;包含了住宅区、加油站、隧道、公路、城市、停车场6种场景,主要以城市街道为主;包含了黎明(黄昏)、白天、夜晚3种时间阶段,主要以白天、夜晚居多;一共包含了bus、light、sign、person、bike、truck、motor、 car、train、rider共10种类别的物体。
[0093]
本发明针对车辆检测的特定任务,从道路目标检测标签中提取了含有car,truck,bus三种车辆类别的标注图像。并且由于测试集官方并未提供标注文件,所以本发明将验证集作为测试集使用。
[0094]
经过提取过后,本发明所使用的训练集包含了69133张含有车辆的图像,测试集包含了9902张含有车辆的图像。
[0095]
(2)构建轻量级骨干网络rescspnet-tiny
[0096]
该骨干网络一共由5个特征提取单元组成,如图2所示。
[0097]
第一特征提取单元,用于将输入图像依次经过切片操作,再通过 1组3*3的标准卷积层,得到高160,宽160,通道数为32的特征图 p1;
[0098]
第二特征提取单元,用于将第一特征提取单元输出的特征图经过浅层残差模块和下采样模块,得到高80,宽80,通道数为64的特征图p2;
[0099]
第三特征提取单元,用于将第二特征提取单元输出的特征图经过浅层残差模块和下采样模块,得到高40,宽40,通道数为128的特征图p3;
[0100]
第四特征提取单元,用于将第三特征提取单元输出的特征图依次经过跨层级局部模块和下采样模型,得到高20,宽20,通道数为256 的特征图p4;
[0101]
第五特征提取单元,用于将第三特征提取单元输出的特征图依次经过跨层级局部模块和下采样模型,得到高10,宽10,通道数为512 的特征图p5;
[0102]
第二,第三浅层残差模块的如图3所示,对应的n,c分别为160, 32和80,64。第四,第五残特征提取单元的如图4所示,对应的n,c 分别为40,128和20,256.
[0103]
第三、第四、第五个特征提取单元的输出一组多尺度特征图p3、 p4、p5。该组特征图的通道数为128、256、512,且相对于图像的下采样比例为8、16、32。
[0104]
(3)构建轻量级多尺度特征融合网络
[0105]
将输入的多尺度特征图p3,p4,p5分别通过一个1*1,步长为1的卷积层,将通道维度变换为256;
[0106]
构建自上而下的特征融合路径,通过双线性插值的操作来完成对多尺度特征图p4,p5的上采样,通过相加操作来完成不同尺度特征间的融合,得到多尺度特征图h3,h4,h5;
[0107]
构建自下而上的特征融合路径,通过双线性插值的操作来完成对多尺度特征图h3,h4的下采样,通过相加操作来完成不同尺度特征间的融合,得到多尺度特征图c3,c4,c5;
[0108]
特征融合的过程如图5所示。
[0109]
(4)构建轻量级的多尺度预测头
[0110]
对多尺度特征图c3,c4,c5先分别通过一个3*3,步长为1的卷积层,以及一个批量归一化层和leakyrelu激活函数层后,再通过一个1*1,步长为1的卷积层,最终预测的多尺度特征o3,o4,o5。其中第一个卷积层的输出通道数为256,第二个卷积层的输出通道数为35。
[0111]
轻量级多尺度预测子网络如图6所示。
[0112]
(5)训练车辆检测模型
[0113]
5.1)预处理训练样本集:调整图像尺寸大小为320
×
320,并采用如下表所示的数据增强方法。
[0114][0115][0116]
5.2)设置深度学习网络训练超参数:设置损失函数的系数分别为: w1=1,w2=0.25,w3=2;使用adamw优化器,初始学习率设置为0.001,权重衰减系数设置为0.05,批处理大小设置为160;训练的总周期设置为300,其中前500次迭代采用线性预热策略;使用余弦退火的学习率衰减策略,其中最小的学习率设置为0.00005。
[0117]
5.3)将训练样本集中batch张图像输入到构建的网络中进行前向传播,得到预测的多尺度特征oi。
[0118]
5.4)采用自适应训练样本分配策略,为每个预测框分配正负样本。
[0119]
5.4.1)解码不同尺度特征的预测信息:
[0120]
5.4.1.1)对多尺度特征oi在通道维度进行划分,得到维度为n的质量预测值pre
cls
和维度为4*regmax边框回归预测值pre
box
。本发明中取n=3,regmax=8。
[0121]
5.4.1.2)对于一个s
×
s尺寸的多尺度特征oi,将这s2个特征点映射回原图中,得到预设锚点p的坐标.
[0122]
5.4.1.3)对于质量预测pre
cls
,在通道维度通过sigmoid函数激活之后,得到每一个锚点位置对应类别的分类预测得分score。
[0123]
5.4.1.4)对于边框回归预测pre
box
,其值代表当前锚点p
xy
距离预测框 4条边的距离(t,r,b,l),采用一个长度为regmax的一维向量v来表示。将每条边的距离向量v进行softmax函数之后,每个位置的值就代表其处在当前位置的概率,最终实际的距离distance,采用期望的方式来计算。
[0124]
5.4.2)进行正负样本标签划分
[0125]
5.4.2.1)初始化质量预测的目标标签label
cls
,边框回归的目标标签label
reg
;
[0126]
5.4.2.2)对(t,r,b,l)与p
xy
进行解码,得到算法预测目标框anchor;
[0127]
5.4.2.3)选出所有中心点p落入gt
box
内的p及其对应的anchor,记为 p
candidate
,anchor
candidate
,将p
candidate
的label
cls
置为对应gt
box
的gt
label
;
[0128]
5.4.2.4)计算所有anchor
candidate
与gt
box
的iou,记为score
iou
;计算iou的代价cost
iou
=-log(score
iou
);
[0129]
5.4.2.5)对于p
candidate
的label值与score
iou
相乘,得到label
soft
,并令 label
cls
=label
soft
;
[0130]
5.4.2.6)对于anchor
candidate
,计算其质量score与label
soft
的交叉熵损失,记为cost
cls
;
[0131]
5.4.2.7)计算anchor
candidate
的代价矩阵m=cost
cls
+cost
iou
;
[0132]
5.4.2.8)根据设置的k值,对每个gt
box
选取score
iou
中前k个anchor
candidate (本发明中k取13),记为anchork,计算anchork的score
iou
之和,并且向下取整,得到了每个gt
box
应该分配锚框数n;
[0133]
5.4.2.9)然后根据每个gt
box
需要分配的数量n,对每个gt
box
选取m中前n小的anchor
candidate
作为正样本,其余视为负样本,根据正负样本选择对label
reg
进行填充;
[0134]
5.4.2.10)如果存在一个anchor
candidate
被多个gt
box
选择的情况,选择m中最小值对应的gt
box
作为其目标,其他gt
box
舍去;
[0135]
5.4.2.11)返回划分的样本标签label
cls
,label
reg
。
[0136]
6)定义广义焦点损失函数gfl,计算预测框与对应样本的损失值.
[0137]
6.1)对于分类预测,采用qfl进行分类质量预测的损失计算,其计算方式如下公式所示。
[0138]
loss
cls
=loss
qfl
[0139]
loss
qfl
(σ)=-|y-σ|
β
((1-y)log(1-σ)+ylog(σ))
[0140]
其中,y为真实的质量标签,其值是[0,1]之间的连续值,对于正样本其值是预测框与真实目标框的iou值,对于负样本其值是0;σ为当前网络的分类预测得分,即分类预测值通过sigmoid函数激活之后的数值。β为权重系数,本发明中取2。
[0141]
6.2)对于边框回归预测,仅针对正样本进行回归损失计算,本发明采用dfl和giou
分别进行损失计算。边框回归分支的损失构成如下所示。
[0142]
loss
reg
=loss
dfl
+loss
giou
[0143]
6.2.1)首先,采用dfl对于边框回归输出的概率分布进行损失计算,对于边框概率的分布进行学习,优化最接近目标位置两侧的概率值,从而让模型能够快速地聚焦到目标位置的邻近区域的分布中去。 dfl的计算方式如下所示:
[0144]
loss
dfl
(si,s
i+1
)=-((y
i+1-y)log(si)+(y-yi)log(s
i+1
))
[0145]
其中,y表示目标位置的下标,yi表示目标位置左侧位置下标,y
i+1
表示右侧位置下标,为yi位置的概率,为y
i+1
位置的概率。
[0146]
6.2.2)对边框回归预测的输出,进行解码后得到目标框的位置信息,将预测的目标框与真实的目标框通过giou损失函数进行损失计算,其计算过程如下示:
[0147][0148][0149]
loss
giou
=1-giou
[0150]
其中,a,b分别为预测框和真实框,c为包含a,b的最小外接矩形框。
[0151]
6.3)最终,将qfl,dfl,giou三个损失计算结果进行相加,就得到了最终的函数,其具体的构成如下所示:
[0152]
loss=w1loss
qfl
+w2loss
dfl
+w3loss
giou
[0153]
其中w1,w2,w3分别表示不同损失的权重
[0154]
7)进行车辆检测
[0155]
7.1)将测试样本集中的图像调整为320
×
320,依次输入到训练好的深度学习网络进行前向传播,得到每张图像的预测类别和预测框坐标。
[0156]
7.2)采用非极大值抑制法,筛选掉重叠的预测框,使用最终的预测框在图像上标记出目标的位置和类别:
[0157]
7.2.1)设置筛选阈值n。
[0158]
7.2.2)用所有预测框构成初始预测框集合b。
[0159]
7.2.3)创建最终预测框集合d,并将其初始化为空集。
[0160]
7.2.4)将预测框与真实框的iou值和预测类别概率相乘作为置信度,并按照置信度对集合b中的预测框按照降序排序。
[0161]
7.2.5)选取第一个预测框,添加到集合d中,再将其从集合b中删除。
[0162]
7.2.6)遍历集合b中的所有预测框,计算它们与d集合中的最终预测框的iou值,若iou值大于阈值n,则将其从集合b中删除。
[0163]
7.2.7)重复步骤7.2.5)~7.2.6)直到集合b为空。
[0164]
7.2.8)输出集合d中的元素作为最终的预测框,并使用最终的预测框在该图像中标记出目标的位置和类别,完成目标检测。
[0165]
实施例1
[0166]
本发明的检测效果可以通过以下实验进一步说明:
[0167]
实验的硬件环境为:
[0168]
tu102[geforce rtx 2080ti]
[0169]
32 intel(r)xeon(r)silver 4110cpu@2.10ghz
[0170]
软件环境配置如下:
[0171]
ubuntu 20.04,cuda 11.4,opencv 4.5.3,python 3.8.12,pytorch 1.10.1。
[0172]
bdd车辆数据集上与其他轻量级检测算法的性能对比:
[0173]
从下表可以看到,当输入图像尺寸为320
×
320时,在速度方面,本发明的算法能够达到每秒448帧的推理速度,比yolov4-tiny的推理速度快了5%左右,比nanodet-m的推理速度快1.5倍左右;在精度方面,本发明的算法的map达到了37.1%,比yolov4-tiny高出6.8%,比nanodet-m高出12%;在模型参数量方面,sfvd有4.06m 参数量,是nanodet-m的4倍多,但是相比于yolov4-tiny,其参数量降低了近30%,总参数量也保持在可接受的范围之内。对于输入图像尺寸为416
×
416的yolov4-tiny,本发明的算法依旧在各项指标上都保持领先。
[0174][0175]
为了更直观的对比检测结果,本发明将各类算法的检测结果进行了可视化,如附图7,其中从上到下依次对应本发明的算法,yolov4
‑ꢀ
tiny-416,nanodet-m的检测结果,从图中可以看到,本发明的算法对车辆目标检测结果更加精准。本发明设计的车辆检测算法速度快,精度高,拥有比已有轻量级算法更好的性能,更加适合处理驾驶场景下的车辆检测任务,参见图7。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1