一种基于毫米波雷达的人体姿态追踪方法
1.本发明属于无线感知与计算机视觉交叉领域,具体涉及一种基于毫米波雷达的人体姿态追踪方法。
背景技术:
2.基于视觉的人体姿态追踪是估计多人姿态(human pose estimation,hpe)并为帧中的每个对象分配唯一实例id的任务。系统通常包括图像采集设备和后台处理设备,通常使用一个或多个摄像头采集人体日常活动的视频,通过网络通信传送到后台处理系统,系统从视频帧中分离出前景,提取目标人体的特征信息包括静态特征和动态特征,根据这些特征值的变化,结合深度学习的方法进行姿态估计并追踪。
3.目前基于视觉的hpe性能上已经取得了一定的进步,但是在应用领域上仍然存在着局限性。在场景光线昏暗的情况下,摄像头将会面临光线昏暗的问题,再加上人体之间相互遮挡,会大幅度的降低检测的准确率和轨迹跟踪的性能。并且摄像头是入侵性的,在某些方面,存在隐私侵犯问题。比如,某些场景下,对于基于姿态的方法做跌倒检测,以及在敏感环境中的行为识别,视觉的方法会涉及到严重的隐私问题。
技术实现要素:
4.本发明主要解决的技术问题是提出一种基于毫米波雷达的人体姿态追踪实现。能够在环境光线昏暗,电磁波,摄像头视距等限制因素都被革除的同时保证数据隐私性,并实现高效的人体姿态追踪。
5.在姿态估计工作上,为了表示从输入数据中提取的关键点和特征,本发明选择采用的人体动力学模型(骨骼模型),能够有效的展现人体在二维像素平面中的姿态数据和运动行为,并且计算成本开模型构建成本较低。本发明提出使用跨监督学习方法,使用视觉信息辅助雷达学习射频信息中的人体信息,并使用自下而上的方法实现人体姿态估计。在训练完成以后,后期雷达射频网络能够仅仅以射频信息作为输入,估计人体姿态。本发明使用卡尔曼滤波器进行运动预测和补偿,能够有效地在人体在被遮挡的情况下,预测被遮挡对象的关键点数据。在卡尔曼滤波器的预测信息以及网络输出的姿态信息与新到达的度量信息之间的关联问题解决方案上,本发明建立一个分配问题,使用匈牙利算法计算。
6.一种基于跨监督学习的毫米波雷达的人员人体姿态追踪方法,包含以下步骤:
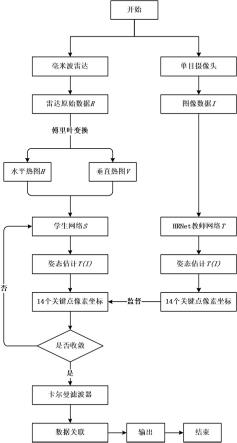
7.步骤1,获取数据。本发明使用单目摄像头和三发射四接收天线的rwx6843毫米波雷达同步采集图像数据i和雷达原始射频数据r。图像采集帧率和雷达数据采集帧率设置为20。
8.步骤2,选取教师网络。本发明使用hrnet作为教师网络,hrnet从高分辨率子网作为第一阶段始,逐步增加高分辨率到低分辨率的子网,形成更多的阶段,并将多分辨率子网并行连接,所以能在网络中随时保持高分辨率表示。网络最终从图像数据i中提取14个人体骨骼关键点,得到每个关键点的像素坐标,实现人体姿态估计,教师网络的数据输出是一个
形式为(n,c,f,v,m)的五维张量信息。n表示网络输入图片的数量,c表示通道,代表像素坐标系下的横纵坐标以及置信分数;f表示帧数,v表示关键点个数,m表示人数。
9.步骤3,雷达数据处理。采集到的雷达数据的形式为(s,l,x,f),s为采样点samples,l表示每秒发射chirp的数量,x表示通道数channel,对应雷达的发射和接收天线,f表示射频数据获取的帧数。对采集到的数据做维度变换以及傅里叶变换,得到水平h和垂直热图v。
10.步骤4,训练学生网络s。将水平垂直热图(h,v)输入学生网络的两个分支编码网络(ev,eh)。(ev,eh)射频编码网络的构建,编码网络为共计10层的9
×5×
5的卷积网络,随后对结果做批处理归一化,并在每一层的最后使用relu激活函数。图像数据i输入教师监督网络t完成实现基于视觉的人体姿态估计,得到14个人体关键点的像素坐标,并将结果t(i)作为标签训练学生网络s。学生网络的学习目的是最小化和教师网络预测关键点像素坐标之间的差异。最终输出人体的姿态信息,每一帧都包含不同人员对应的姿态数据,数据输出形式同教师网络的输出。
11.步骤5,人员追踪。本发明使用卡尔曼滤波器实现运动预测,对于上一步骤产生的姿态数据,预测下一帧中目标可能出现的位置。本发明创建并维护每一帧对象检测的轨迹(tracks),既为每一个对象创建一个轨迹集。当帧中的对象出现在第一帧中时,或者出现不能与现有对象匹配的对象时,会被建立新的轨迹(tracks)。
12.步骤6,姿态匹配。本发明使用匈牙利算法实现预测对象和检测对象之间的关联问题。将当前帧预测的下一帧对象可能存在的位置和下一帧学生网络s检测出的人体位置进行匹配关联。
13.然而在配对过程中可能会发生失败的现象,具体分为以下几种情况,并阐述应对方法:
14.(1)新目标出现。出现新目标以后,新检测到的目标(detections)不能和原有轨迹集(tracks)中目标关联,因为卡尔曼滤波器并没有该新对象的历史信息,不能做出预测。既出现匹配失败的情况。这时建立新的轨迹集,并将出现的新目标添加进轨迹集中。
15.(2)已存在目标消失。场景中存在的目标,在离开场景以后,其对应的轨迹集会被标记为不激活状态,在连续多帧内仍然不被添加对象以后,删除轨迹集。
16.(3)噪声。可能因为场景中存在的噪声或者是检测算法的误检测,导致检测结果不能和卡尔曼滤波器的预测结果对应。该情况可以在连续多帧内将检测和轨迹集匹配过滤。
17.本发明的有益效果:
18.(1)相比传统的基于视觉的人体姿态追踪算法在场景光线昏暗的情况下,摄像头采集的数据就会面临很大的问题,模糊的人体再加上遮挡情况,会大幅度的降低检测的准确率和轨迹跟踪的性能。在某些方面,摄像头存在隐私侵犯问题。比如,在检测老年人浴室是否摔倒的问题上,摄像头就存在严重的隐私侵犯问题。本发明基于毫米波雷达不受视距,光线强度不利因素的影响,并且雷达数据不能被直接读取出有效的信息,能够保护用户的隐私性。
19.(2)本发明采用的方法使用射频数据作为输入,由于射频信息无法直接打标签,使用跨监督模式学习,解决射频信息无法被标注人体姿态的问题。
20.(3)本发明使用卡尔曼滤波器有效的解决人体之间相互遮挡,检测模型不能正常
预测的情况,并使用匈牙利算法有效的实现姿态数据之间的关联。
附图说明
21.图1是本发明实施例中的教师学生网络神经网络图。
22.图2是本发明实施例中的卡尔曼滤波器工作流程图。
23.图3是本发明实施例中的教师学生网络工作流程图。
具体实施方式
24.下面结合说明书附图对本发明的技术方案做进一步的详细说明。
25.本发明是一种基于跨监督学习的毫米波雷达人体姿态追踪方法。首先获取rgb图像数据i,毫米波雷达同步的获取雷达回波信息r。使用人体姿态估计算法对图像数据进行处理,完成人体姿态估计,提取人体关键点坐标,辅助学生网络学习以射频信息作为输入,输出人体姿态关键点数据,得到射频人体姿态估计模型。追踪过程的实现使用卡尔曼滤波器完成运动预测和更新。具体过程如下:
26.对于跨监督学生网络的设计,如图1所示。
27.学生网络以射频信息实现人体姿态估计的流程如下所述:
28.步骤1,数据采集。使用单目摄像头和三发射四接收天线的rwx6843毫米波雷达配合同步采集图像数据i和雷达原始射频数据r。图像采集帧率和雷达数据采集帧率设置为20fps。
29.步骤2,教师网络选取。教师网络选择使用hrnet网络,hrnet从高分辨率子网作为第一阶段始,逐步增加高分辨率到低分辨率的子网,形成更多的阶段,并将多分辨率子网并行连接,所以能在网络中随时保持高分辨率表示。本发明将图像i输入教师网络hrnet网络得到的人体姿态估计结果ti,ti为一个形式为(n,c,f,v,m)的五维张量信息。n表示网络输入的batch-size,c表示通道,代表像素坐标系下的横纵坐标以及置信分数,f表示帧数,v表示关键点个数,m表示人数。将ti作为标签信息,监督学生射频网络学习得到结果s(r)。
30.步骤3,雷达数据处理。采集到的雷达数据的形式为(s,l,x,f),s为采样点sample,l表示每秒发射chirp的数量,x表示雷达数据的通道数channel,对应着雷达的发射和接收天线,f表示射频数据获取的帧数。对采集到的数据进行维度变换以及傅里叶变换,得到水平热图h和垂直热图v。
31.步骤4,学生网络训练。将水平垂直热图并行输入射频编码网络,分别做编码处理,经过编码以后再将二者信息按通道维度拼接,将聚合后的信息再次输入编码网络d。如图1所示,射频编码e的构建,编码网络e为共计10层的9
×5×
5的卷积网络,随后对结果做批处理归一化,并在每一层的最后使用relu激活函数。解码网络d的构建,使用4层3
×6×
6的卷积神经网络,同样在每一层之后使用relu激活函数。对于垂直和水平编码网络,每次输入500帧的热图信息(25秒)。
32.本发明采用的姿态估计方法是自下而上的解析,在关键点的关联问题上。比如,对于人员k的肢体c,与其相关联的两类关键点是j1,j2(比如肢体c为大臂,则j1、j2分别为肩部关键点和肘部关键点。肢体c为小臂,则j1、j2分别为肘部关键点和腕部关键点)。对于关节点j1和j2,设置对应的标签为
33.对于人员k,如果预测的关键点在肢体上,则为两个关键点连线方向单位向量(模长为1),否则为零向量。计算公式为:
[0034][0035]
v=(x
j2,k-x
j1,k
)/||x
j2,k-x
j1,k
||2[0036]
从数学上描述一个点p在肢体limbc,k上,有两点约束:点p与起始关键点在肢体方向(即两个关联关键点的连线方向)的距离不能超过终止关键点,在垂直肢体方向的距离不能超过肢体的宽度。
[0037]
0≤v
·
(p-x
j1,k
)≤l
c,k
and|v
⊥
·
(p-x
j1k
)|≤σ
l
[0038][0039]v⊥
是法向量,σ
l
是肢体的宽度。
[0040]
训练的目标是最小化教师网络标签数据和学生网络预测结果的差值,本发明将损失定义为每个关键点的二元交叉损失熵之和,计算公式如下:
[0041][0042][0043]
s(r)表示以射频信息r为输入的学生网络s的预测结果,t(i)表示以视觉信息i为输入的教师网络t的输出。和表示(i,j)的像素坐标位置。迭代循环完成以上步骤就能得到仅仅以射频信号作为输入,实现人体姿态估计的网络模型。
[0044]
步骤5,姿态追踪。由于人体在运动的过程可能会存在相互遮挡的情况发生,所以会发生跟踪对象丢失的情况的发生,本发明使用卡尔曼滤波器实现运动的预测和更新。对于姿态估计的输出(n,c,f,v,m),卡尔曼滤波器设置帧数阈值q。当姿态信息的帧数f累计达到卡尔曼滤波器的阈值时,卡尔曼滤波器根据累计姿态像素坐标信息,预测下一帧中人员可能出现的位置,对于每一个出现的对象,卡尔曼滤波器都会创建一个新的轨迹集,并将该对象的信息添加进轨迹集,并计算出预测的像素坐标信息。
[0045]
步骤6,数据关联。数据关联问题上使用匈牙利算法,目标是在每个人员检测和保持跟踪的目标之间创建一个关联,从而使组合的距离损失最小化。对于每一个轨迹k,设置一个帧计数器counter,计算自上一次关联成功以来的帧数。帧数计数器counter在卡尔曼滤波器预测期间值在递增,并在轨迹关联成功的时候重置为0。超过最大帧数a
max
设置的轨迹被认为是离开场景,并将对应的该轨迹从轨迹集中删除。对于无法与现有的轨迹关联的每个检测,都会启动新的轨迹假设。
[0046]
在配对过程中可能会发生失败的现象及应对方法如下:
[0047]
(1)新目标出现。出现新目标以后,新检测到的目标(detections)不能和原有轨迹集(tracks)中目标关联,因为卡尔曼滤波器并没有该新对象的历史信息,不能做出预测。既出现匹配失败的情况。这时候需要建立新的轨迹集,并将出现的新目标添加进轨迹集中。
[0048]
(2)已存在目标消失。场景中存在的目标,在退出场景以后,其对应的轨迹集会被
标记为不激活状态,在连续多帧内仍然不被添加对象以后,删除轨迹集。
[0049]
(3)噪声。可能因为场景中存在的噪声或者是检测算法的误检测,导致检测结果不能和卡尔曼滤波器的预测结果对应。该情况可以在连续多帧内将检测和轨迹集匹配过滤。
[0050]
通过以上说明可见与现有的技术相比,本发明提出的基于毫米波雷达的姿态追踪方法,能够在场景光线昏暗,视距受限,烟雾干扰的情况下实现人体姿态追踪,并能够有效的保护用户隐私。并且本发明使用跨监督方法有效的克服了雷达射频数据无法被标注骨骼信息标签的问题。使用卡尔曼滤波器有效的解决人体之间相互遮挡,检测模型不能正常预测的情况,并使用匈牙利算法有效的实现姿态数据之间的关联。
[0051]
以上所述仅为本发明的较佳实施方式,本发明的保护范围并不以上述实施方式为限,但凡本领域普通技术人员根据本发明所揭示内容所作的等效修饰或变化,皆应纳入权利要求书中记载的保护范围内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1