一种基于场景先验的视觉车道线检测系统及方法与流程
1.本技术属于车道线检测技术领域,通过引入场景已知的先验知识来提升车道线检测的精度,具体涉及一种基于场景先验的视觉车道线检测系统及方法。
背景技术:
2.车道线检测是无人驾驶中的基础技术模块之一,对于车辆的横向定位和路径规划都具有重要意义。
3.受到图像检测和分割技术的启发,目前的车道线技术主要通过改良主流的分割、检测算法来建模车道线的细长结构,来提升检测精度。相关的研究表明全transformer架构的视觉模型比基于cnn的模型具有更高的模型精度上限,更加适用于无人驾驶算法基于海量数据闭环的训练范式,而现有技术中缺少采用全transformer架构实现车道线检测的技术。
技术实现要素:
4.为了解决现有技术中存在的上述技术问题,本发明提供了一种基于场景先验的视觉车道线检测系统和方法,包括:数据处理模块、视觉主干网络模块、先验知识对齐模块、融合网络模块、检测网络模块;所述数据处理模块的输入为待检测的图像数据、场景先验数据、定位数据,输出为归一化之后的图像、用栅格图维护的局部场景先验信息;所述视觉主干网络模块的输入为归一化之后的图像,输出为图像特征;所述先验知识对齐模块,输入为用栅格图维护的局部场景先验信息,输出为对齐后的局部场景先验信息;所述融合网络模块,输入为图像特征和对齐后的局部场景先验信息,输出为融合后的图像特征和局部场景先验信息;所述检测网络模块,输入为融合后的图像特征,输出为用掩码表示的车道线检测结果。
5.进一步的,所述栅格图,通过定位信息索引全局场景先验信息获取;场景先验信息是任何可以预先获取的环境信息,包括当前栅格的高度、当前栅格是否为道路、当前栅格的静态障碍物类型等,栅格的尺寸和每个栅格代表的物理空间大小,由预先定义。
6.进一步的,所述视觉主干网络模块由l个自注意力层构成,每层输出一个特征图, l由预先设定,对于输入每个自注意力层的特征图,其尺寸为c
l *h
l
*w
l
,用大小为k*k的滑动窗口切成特征块,移动步长为s,每个特征块大小为c
l *k*k, 然后用全连接层将每个特征块映射为1*v
l
的特征向量, 共可得到(h
l
/s)*(w
l
/s)个向量,对这些向量执行自注意力操作,得到优化后的向量,整理成v
l
*(h
l
/s)*(w
l
/s)的特征图x
l
,输入到下个自注意力层, 以上参数取值由预先设定且每层取值可以相同或者相异。
7.进一步的,所述先验知识对齐模块模块通过构建卷积层来计算栅格图的嵌入表示map_embd,其中卷积层的输入通道为cm,输出通道为d
embd
,卷积核大小为km*km,步长为sm,其取值均由预先设定,其中d
embd
的取值往往与v
l
保持一致,卷积层输出尺寸为d
embd
*(hm/sm)*(wm/sm)的栅格图嵌入表示,以上参数的取值由预先定义;将map_embd输入到由多层卷积组
成的投影网络,得到由2*3矩阵表示的仿射变换参数affine_param;通过使用affine_param对map_embd进行空间变换,得到变换后的特征张量,将该特征张量沿宽、高两个维度展平,得到d
embd
*lm的矩阵map_prompt,其中l
m=
(hm/sm)*(wm/sm) ,以上参数的取值由预先定义。
8.进一步的,融合网络,包含知识编码器层和融合编码器层两种网络层,选取视觉主干网络模块中的某一层特征图x
l
,将其沿着宽、高两个维度展平,得到v
l
*l
l
的矩阵img_feat
l
,其中l
l
=(h
l
/s)*(w
l
/s);将map_prompt和img_feat
l
一起输入到融合网络,融合网络首先对map_prompt进行l1次自注意力操作,得到优化后的特征map_refined,再将img_feat
l
和map_refined拼接,得到v
l
*(l
l
+lm)的查询特征query_feat;进一步对query_feat进行l2次自注意力操作,得到优化后的特征query。
9.进一步的,输入为查询特征query, 首先从query中切分出图像相关的特征,对于每个输入到融合模块的特征图x
l
,找出其在query中的对应位置的特征,重新整理成跟x
l 尺寸一致的特征图nx
l ;按通道拼接每一个特征图x
l ,
在拼接之前对特征图进行上采样,使之通道数目不变,而宽高跟视觉主干网络中最大的特征图保持一致,如果某个特征图x
l
存在对应的融合特征图nx
l
,那么用nx
l
代替x
l
进行上采样和拼接,得到拼接特征feat_all;将拼接特征feat_all输入到一个全连接模块,得到cls*h
seg
*w
seg
的分割结果,其中cls表示分割的种类,为预先设定,h
seg
和w
seg
为视觉主干网络中最大特征图的高和宽,对该分割结果进行上采样使之大小于原图一致,得到cls*h*w的车道线检测结果。
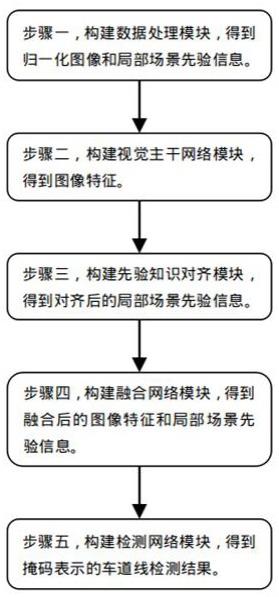
10.本发明还提供了一种基于场景先验的视觉车道线检测方法,包括如下步骤:步骤1.构建数据处理模块,得到归一化图像和局部场景先验信息;步骤2.构建视觉主干网络模块,得到图像特征;步骤3.构建先验知识对齐模块,得到对齐后的局部场景先验信息;步骤4.构建融合网络模块,得到融合后的图像和局部场景先验信息;步骤5.构建检测网络模块,得到掩码表示的车道线检测结果。
11.本发明通过引入全transformer的架构来提升视觉车道线检测的性能,同时该架构支持输入场景先验知识来提升检测精度和稳定性,并且对于先验知识本身的精度要求很低。
附图说明
12.图1 是本发明的基于场景先验的视觉车道线检测方法流程图;图2是本发明的基于场景先验的视觉车道线检测系统的网络架构图。
具体实施方式
13.下面结合附图对本发明作进一步说明。
14.如图1所示,本发明的基于场景先验的视觉车道线检测方法,包括如下步骤:步骤1.构建数据预处理模块构data_propress,输入当前待检测图像,裁剪保留感兴趣区域,尺寸为3*360*640,分别表示通道数,高度,宽度;将待检测图像做减均值除方差的归一化操作,得到归一化后的图像img。
15.输入场景先验知识,如果以开源地图数据作为常见的常见信息,通过当前定位,索引周围环境的osm地图数据m。提取m中的道路信息,在俯视视角下的栅格图中(栅格图的物
理范围和分辨率由事先给定),画出道路结构(用1表示道路,用0表示非道路), 生成二值地图binary_map。同理,其他场景先验知识也可以用相同思路存储在binary_map中,不同的先验知识用不同的通道表示。
16.步骤2.构建视觉主干网络vision_transformer,此处采用mit-b5模型作为主干网络,其由四个自注意力层构成,每层对于输入的特征图用滑动窗口切成特征块,然后将特征块用全连接层映射为特征向量,进一步计算向量之间的注意力。
17.具体地第一个注意力层,输入3*360*640的img,滑动窗口大小为7,步长为4,将每个3*7*7的特征块用全连接层映射为1*64的向量,得到64*90*160的特征图,将该特征图输入自注意力模块,输出64*90*160的特征图x1。
18.第二个注意力层,输入x1,滑动窗口为3,步长为2,将每个64*3*3的特征块用全连接层映射为1*128的向量,得到128*45*80的特征图,将该特征图输入自注意力模块,输出128*45*80的特征图x2。
19.第三个注意力层,输入x2,滑动窗口为3,步长为2,将每个128*3*3的特征块用全连接层映射为1*320的向量,得到320*24*40的特征图,将该特征图输入自注意力模块,输出320*24*40的特征图x3。
20.第四个注意力层,输入x3,滑动窗口为3,步长为2,将每个320*3*3的特征块用全连接层映射为1*512的向量,得到512*12*20的特征图,将该特征图输入自注意力模块,输出512*12*20的特征图x4。
21.步骤3.输入binary_map,尺寸为3*200*200,经过一层卷积层构建地图嵌入表示,卷积层的输入通道为3,输出通道为512,卷积核大小为10*10,步长为10,得到512*20*20的地图嵌入表示map_embd。
22.构建先验知识对齐模块kea,将map_embd输入kea,得到由一个2*3矩阵表示的仿射变换参数affine_param。将map_embd通过affine_param投影为新的特征张量,并且将该张量按宽、高两个维度展平,得到512*100的矩阵map_prompt。
23.步骤4.构建融合网络(fusion_transformer),其包含知识编码器层(knowledge encoder layer)和融合编码器层(fusion encoder layer)两种网络层,将步骤2中的特征图x4沿着宽、高两个维度展平,得到512*240的矩阵img_feat。
24.将map_prompt和img_feat一起输入到fusion_transformerr,其首先对map_prompt进行4次自注意力操作(即构建4层knowledge encoder layer),得到优化后的特征map_refined,再将img_feat和map_refined拼接,得到512*(240+100)的查询特征query_feat。进一步对query_feat进行4次自注意力操作(即构建4层fusion encoder layer),得到优化后的特征query。
25.步骤5.构建检测网络seg_net,首先从query中切分出图像相关的特征,其大小为512*240,参考特征图x4的尺寸,将其折叠为512*12*20的新特征图mx4。
26.对特征图x2、x3、mx4进行上采样操作,上采样后宽高跟x1一致,分别得到128*90*160、320*90*160、512*90*160的新特征图nx2、nx3、nmx4。
27.将x1、nx2、nx3、nmx4按照通道进行拼接,得到(64+128+320+520)*90*160的特征图,输入到一个全连接模块,得到4*90*160的分割结果,对该分割结果进行上采样使之大小于原图一致,得到4*360*640的车道线检测结果,4表示分割的种类。
28.如图2所示,本发明的基于场景先验的视觉车道线检测系统,包括:数据处理模块、视觉主干网络模块、先验知识对齐模块、融合网络模块、检测网络模块;所述数据处理模块的输入为待检测的图像数据、场景先验数据、定位数据,输出为归一化之后的图像、用栅格图维护的局部场景先验信息;所述视觉主干网络模块的输入为归一化之后的图像,输出为图像特征;所述先验知识对齐模块,输入为用栅格图维护的局部场景先验信息,输出为对齐后的局部场景先验信息;所述融合网络模块,输入为图像特征和对齐后的局部场景先验信息,输出为融合后的图像特征和局部场景先验信息;所述检测网络模块,输入为融合后的图像特征,输出为用掩码表示的车道线检测结果;所述数据处理模块,输入为当前待检测图像、场景先验数据、定位数据,输出为归一化的图像img和维护当前局部场景先验信息的栅格图binary_map;其中输入图像尺寸为c*h*w,分别表示通道数,高度,宽度,将待检测图像做减均值除方差的归一化操作,得到归一化后的图像img;维护当前局部场景先验信息的栅格图,通过定位信息索引全局场景先验信息获取;场景先验信息可以是任何可以预先获取的环境信息,如当前栅格的高度、当前栅格是否为道路、当前栅格的静态障碍物类型等,栅格的尺寸和每个栅格代表的物理空间大小,由预先定义。
29.所述视觉主干网络模块,输入为归一化后的图像img,输出为l个不同分辨率的图像特征图,l由预先设定;该视觉主干网络模块由l个自注意力层构成,每层输出一个特征图, l由预先设定,对于输入每个自注意力层的特征图,其尺寸为c
l *h
l
*w
l
,用大小为k*k的滑动窗口切成特征块,移动步长为s,每个特征块大小为c
l *k*k, 然后用全连接层将每个特征块映射为1*v
l
的特征向量, 共可得到(h
l
/s)*(w
l
/s)个向量,对这些向量执行自注意力操作(self-attention),得到优化后的向量,将之整理成v
l
*(h
l
/s)*(w
l
/s)的特征图x
l
,输入到下个自注意力层, 以上参数取值由预先设定且每层取值可以相同或者相异;所述先验知识对齐模块,输入为维护当前局部场景先验信息的栅格图binary_map,尺寸为cm*hm*wm,分别表示栅格图的通道数、长度和宽度。该先验知识对齐模块通过构建一个卷积层来计算栅格图的嵌入表示(embedding)map_embd,其中卷积层的输入通道为cm,输出通道为d
embd
,卷积核大小为km*km,步长为sm,其取值均由预先设定,其中d
embd
的取值往往与v
l
保持一致,卷积层输出尺寸为d
embd
*(hm/sm)*(wm/sm)的栅格图嵌入表示,以上参数的取值由预先定义;将map_embd输入到由多层卷积组成的投影网络(投影网络的层数和每层的参数设计由预先设定,只要满足输出尺寸要求即可),得到由2*3矩阵表示的仿射变换参数affine_param(也可以用其他预先定义尺寸的矩阵来表示其他空间变换)。通过使用affine_param对map_embd进行空间变换,得到变换后的特征张量,将该特征张量沿宽、高两个维度展平,得到d
embd
*lm的矩阵map_prompt,其中l
m=
(hm/sm)*(wm/sm) ,以上参数的取值由预先定义;所述融合网络模块,输入为对齐后的局部场景先验信息map_prompt和图像特征。融合网络fusion_transformer,其包含知识编码器层(knowledge encoder layer)和融合编码器层(fusion encoder layer)两种网络层,选取视觉主干网络模块中的某一层特征图x
l
,将其沿着宽、高两个维度展平,得到v
l
*l
l
的矩阵img_feat
l
,其中l
l
=(h
l
/s)*(w
l
/s)。将map_prompt和img_feat
l
一起输入到融合网络,融合网络首先对map_prompt进行l1次自注意力操作(即构建l1层knowledge encoder laye,l1由预先定义),得到优化后的特征map_
refined,再将img_feat
l
和map_refined拼接,得到v
l
*(l
l
+lm)的查询特征query_feat。进一步对query_feat进行l2次自注意力操作(即构建l2层fusion encoder layer, l2由预先定义),得到优化后的特征query。对于5.2中视觉主干网络模块特征图的选择,可以选择其中的任意一层,也可以选择多层参考5.2中相同的方式拼接融合到特征query中。
30.所述检测网络模块,输入为查询特征query, 首先从query中切分出图像相关的特征,对于每个输入到融合模块的特征图x
l
,找出其在query中的对应位置的特征,重新整理成跟x
l 尺寸一致的特征图nx
l 。按通道拼接每一个特征图x
l ,
在拼接之前对特征图进行上采样,使之通道数目不变,而宽高跟视觉主干网络中最大的特征图保持一致,如果某个特征图x
l
存在对应的融合特征图nx
l
,那么用nx
l
代替x
l
进行上采样和拼接,得到拼接特征feat_all。将feat_all输入到一个全连接模块,得到cls*h
seg
*w
seg
的分割结果,其中cls表示分割的种类,为预先设定,h
seg
和w
seg
为视觉主干网络中最大特征图的高和宽,对该分割结果进行上采样使之大小于原图一致,得到cls*h*w的车道线检测结果。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1