基于专家统计特征的增量计算更新方法、电子设备、介质与流程
1.本发明涉及人工智能特征工程、统计变量计算与数据存储技术领域,尤其涉及一种基于专家统计特征的增量计算更新方法、电子设备、介质。
背景技术:
2.对于人工智能技术而言,数据和特征决定了机器学习的上限,而模型和算法只是逼近这个上限。因此,特征工程在机器学习中占有相当重要的地位。在实际应用当中,特征工程阶段产生的数据和特征是机器学习成功的关键。现有的自动特征生成技术通过对低阶特征进行简单的转化和聚合生成数量庞大的新特征,然后对其中重要性高的特征予以保留,利用新特征进行模型再训练,是目前通用的做法,这一切均依赖于非常强大的计算资源。多数用户的计算资源并不充足,难以承载如此强大的计算量。因此,在传统模式中以其有限的计算资源为基础构造适当的样本特征为特征工程任务提出了新的挑战,而构造这类特征常常需要专家经验的介入。已有的专家经验特征通常可以分为静态特征和动态特征,即通过对简单的多个低阶特征进行组合和计算得到的特征,以及通过对简单的低阶特征在时空维度执行统计操作得到的特征。
3.常规特征统计计算过程中,静态特征通常采用直接的多个低阶特征执行计算逻辑即可以得到,而动态特征则需要针对部分历史数据或者全部历史数据进行统计计算获得。为了得到这些特征需要强大的计算资源或者需要较长的时间周期,这无形中增大了生成专家特征的计算量和巨大计算成本。
4.因此,亟需提出一种基于专家统计特征的增量计算更新方法,在针对低服务器资源的情况,仍然能够高效的输出统计特征。
技术实现要素:
5.针对现有技术不足,本发明提出了一种基于专家统计特征的增量计算更新方法。
6.为实现上述技术目的,本发明的技术方案为:本发明实施例的第一方面提供了一种基于专家统计特征的增量计算更新方法,所述方法具体包括以下步骤:
7.(1)构建专家统计特征配置文件,所述专家统计特征配置文件中包括若干字段,其中第一字段的列名为统计型专家特征的名称,其余字段的列名包括统计型专家特征对应的统计计算类别、分组属性名、筛选条件关联属性名、筛选条件、执行统计操作的属性名、统计操作类型;
8.(2)读取步骤(1)构建的专家统计特征配置文件,将第一字段名作为主键,按统计型专家统计对应的统计计算类别对其余字段进行验证,再将通过验证的其余字段拼接成链表作为值组成哈希映射;
9.(3)离线生成历史数据的关联统计信息:根据步骤(2)得到的哈希映射抽取待生成的专家统计特征,依据步骤(2)中得到的值获取对应的专家统计特征的计算类别,根据统计型专家特征的计算类别分别保存统计型专家特征对应的历史数据的关联统计信息;
10.(4)持久化步骤(3)保存的历史数据的关联统计信息;
11.(5)在线生成新增数据的关联统计信息,根据步骤(2)得到的哈希映射抽取待生成的专家统计特征,依据步骤(2)中得到的值获取对应的专家统计特征的计算类别,根据统计型专家特征对应的统计计算类别分别保存统计型专家特征对应的新增数据的统计关联信息;
12.(6)更新历史关联统计信息,根据步骤(4)保存的历史数据的关联统计信息以及步骤(5)生成的新增数据的统计关联信息,更新对应的历史关联统计信息,以当前新增数据时间为新的历史数据时间节点,获得更新后的历史关联统计信息,并持久化作为新的历史数据统计关联信息;
13.(7)利用步骤(6)更新后的历史数据统计关联信息,推断出统计型专家特征的数值。
14.本发明实施例的第二方面提供了一种电子设备,包括存储器和处理器,所述存储器与所述处理器耦接;其中,所述存储器用于存储程序数据,所述处理器用于执行所述程序数据以实现上述的基于专家统计特征的增量计算更新方法。
15.本发明实施例的第三方面提供了一种计算机可读存储介质,其上存储有计算机程序,所述程序被处理器执行时实现上述的基于专家统计特征的增量计算更新方法。
16.本发明是基于上述技术背景和业务场景,提供一种通用高效、兼容性强、实用性强的计算金融风控专家统计特征的方法。
17.本发明的有益效果为:本发明方法提供了一种基于专家统计特征的增量计算更新方法,通过离线计算和在线计算两个部分分别得到历史数据的关联统计信息、新增数据的关联统计信息,并进行持久化历史数据的统计关联信息。基于历史和新增数据抽取得到的统计关联信息生成更新后的离线数据统计关联信息并执行持久化操作;最后,基于更新后的离线数据的统计关联信息生成对应的统计特征。与现有的全量数据统计特征更新方法相比,本发明提供的基于专家统计特征的增量计算更新方法在测试数据集上能够达到10倍以上的速度提升;此外,针对低服务器资源的情况,本发明方法仍然能够高效的输出统计特征,能够应用于金融风控业务场景中ai模型的实时数据推断。
附图说明
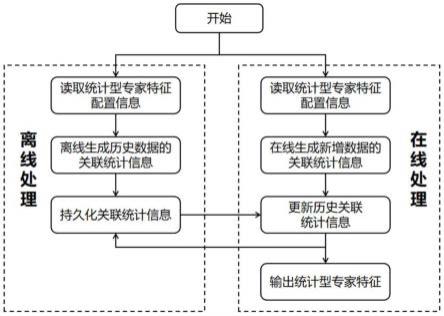
18.图1为本发明基于增量计算的金融风控专家统计特征的更新方法的流程图;
19.图2为本发明实施例示出的一种电子设备的示意图。
具体实施方式
20.这里将详细地对示例性实施例进行说明,其示例表示在附图中。下面的描述涉及附图时,除非另有表示,不同附图中的相同数字表示相同或相似的要素。以下示例性实施例中所描述的实施方式并不代表与本发明相一致的所有实施方式。相反,它们仅是与如所附权利要求书中所详述的、本发明的一些方面相一致的装置和方法的例子。
21.下面结合附图,对本发明进行详细说明。在不冲突的情况下,下述的实施例及实施方式中的特征可以相互组合。
22.本发明提供了一种基于专家统计特征的增量计算更新方法,如图1所示,具体包括
以下步骤:
23.(1)构建专家统计特征配置文件,包括:
24.配置第一字段的列名,该第一字段由原始数据表单中参与统计计算,将统计型专家特征作为第一字段的列名。
25.配置第二字段的列名,该第二字段由第一字段中统计型专家特征对应的类别组成;本发明实施例中,所述专家统计特征的类别包括:基于某一特征的历史数据统计值,在特定有效时间内基于某一特征的历史数据统计值,在特定有效时间内发生次数的统计值,基于某一特征近几期的数值统计值。
26.配置第三字段的列名,该第三字段由生成第一字段的专家统计特征的原始数据表进行分组统计操作形成的分组统计特征对应的列名组成,且该第三字段需为执行统计操作的原始表格中的列名。
27.配置第四字段的列名,该第四字段由生成第一字段的专家统计特征的原始数据表进行条件筛选操作时筛选条件作用的列名组成,且该字段需为执行统计操作的原始表格中的列名。
28.配置第五字段的列名,该第五字段由筛选条件设定的条件范围数值组成,具体可以细分为:纯数值类型、数值与其对应计量单位的联合表示类型,当参数为多个时,参数间以“#”隔开。
29.配置第六字段的列名,该第六字段由生成的第一字段的专家统计特征输出统计结果数值所属的列名组成,且该字段需为执行统计操作的原始表格中的列名。
30.配置第七字段的列名,该第七字段由基于第六字段列名关联的原始表格数值生成第一字段标识的专家统计特征需要执行的统计操作类型组成。
31.作为一优选方案,配置的字段列表中,字段间以逗号隔开。
32.(2)读取专家统计特征配置信息,将对应的第一字段名作为主键(key),后续字段名拼接成链表作为值(value)组成哈希映射(hashmap)。
33.作为一优选方案,步骤(2)中利用数组拼接hashmap,具体如下:
34.读取步骤(1)构建的专家统计特征配置文件中的每一条记录,将第一字段数值作为key,并对第二至第七字段的数值进行验证,将验证通过的第二至第七字段的数值构建链表,该链表作为value;
35.其中,对第二至第七字段的配置合法性进行验证判断,具体判断以下条件:
36.条件1:专家统计特征配置文件中的第二字段配置的类别是否在已配置的类别范围内(已配置的类别范围即基于某一特征的历史数据统计值,在特定有效时间内基于某一特征的历史数据统计值,在特定有效时间内发生次数的统计值,基于某一特征近几期的数值统计值);
37.条件2:依据已配置的类别判断第三至第七字段数值的非空值要求是否满足;
38.示例性地,依据第二字段配置的类别为基于某一特征的历史数据执行数值统计,则判断第三字段、第四字段、第六字段、第七字段是否为空。
39.示例性地,依据第二字段配置的类别为在特定有效时间内基于某一特征的历史数据的执行数值统计,则判断第三字段、第四字段、第五字段、第六字段、第七字段是否为空。
40.如任一条件不满足,则该专家统计特征配置文件存在问题,不满足类别要求的字
段为空值。
41.(3)离线生成历史数据的关联统计信息:根据步骤(2)得到的哈希映射(hashmap)抽取待生成的专家统计特征,依据value获取对应的专家统计特征的计算类别,根据专家统计特征的计算类别分别保存专家统计特征的统计关联信息,保证生成的历史数据统计关联信息可以推导获得相应的专家统计特征。
42.示例性地,步骤(3)中每一个专家特征的数值生成,根据步骤(2)中哈希映射(hashmap)抽取统计型专家特征,依据value获取对应的专家特征的统计计算类别(即由步骤(1)中第二字段决定),根据基于某一特征的历史数据统计值(sta_type_history_value)、在特定有效时间内基于某一特征的历史数据统计值(sta_type_recent_date_value)、在特定有效时间内发生次数的统计值(sta_type_recent_date)、基于某一特征近几期的数值统计值(sta_type_recent_periods_value)分别执行不同的统计关联信息的保存。
43.并且不同的统计关联信息的保存的过程中,保存的关联信息由以下内容决定:
44.内容1:根据步骤(2)得到的value值链表的第三个值,即步骤(1)所述第四个字段(即统计的筛选条件关联属性名),确定执行的过滤条件属性。
45.内容2:根据步骤(2)得到的value值链表的第五个值,即步骤(1)所述第六个字段(即统计结果依赖的属性名),确定执行的统计操作的关联属性。
46.其中,关联信息按照内容1和内容2需要分别采用独立的链表结构进行存储。
47.示例性地,依据基于某一特征的历史数据统计值(sta_type_history_value)这一统计计算类别执行统计关联信息的保存过程中,由上述内容1决定筛选条件,进行过滤,得到存储关联信息[value1,value2,value3...]。
[0048]
示例性地,依据基于某一特征在有效时间内的执行数值统计的属性列(sta_type_recent_date_value)这一统计计算类别执行统计关联信息的保存过程中,由上述内容1和内容2决定保存的关联信息,得到存储关联信息[date1,date2,date3...]和[value1,value2,value3...]。
[0049]
示例性地,依据基于有效时间内的发生次数的统计值(sta_type_recent_date)这一统计计算类别执行统计关联信息的保存过程中,由上述内容2决定保存的关联信息,得到存储关联信息[date1,date2,date3...]。
[0050]
(4)存储离线模式下生成的历史数据关联信息,持久化历史数据关联的统计信息,确保关联统计信息的持久化。
[0051]
示例性地,步骤(4)中可以选择采用mysql、oracle等数据库形式,或者,采用csv、xls、pkl等文件形式存储数据。
[0052]
(5)在线生成新增数据的关联统计信息,根据步骤(2)得到的哈希映射(hashmap)抽取待生成的专家统计特征,依据value获取对应的专家统计特征的计算类别,根据专家统计特征的计算类别分别保存专家统计特征对应的新增数据的统计关联信息,保证生成的新增数据统计关联信息可以推导获得相应的专家统计特征。
[0053]
示例性地,步骤(5)中:
[0054]
(5.1)每一个专家特征的数值生成,根据步骤(2)中哈希映射(hashmap)抽取待生成的专家统计特征,依据value获取对应的专家特征的统计计算类别,即步骤(1)所述第二
字段决定,分别执行不同的统计关联信息的保存;
[0055]
具体地,保存的关联信息由以下内容决定:
[0056]
内容1:根据步骤(2)得到的value值链表的第三个值,即步骤(1)所述第四个字段,确定执行的过滤条件属性;
[0057]
内容2:根据步骤(2)得到的value值链表的第五个值,即步骤(1)所述第六个字段,确定执行的统计操作的关联属性;
[0058]
其中,需要保存满足统计条件的新增数据关联信息,其中关联信息,按照内容1和内容2分别采用独立的链表结构进行存储。
[0059]
(6)更新历史关联统计信息,根据步骤(4)保存的历史统计关联信息以及步骤(5)在线生成的新增数据的关联统计信息,更新对应的历史关联统计信息,以当前新增数据时间为新的历史数据时间节点,获得更新后的历史关联统计信息,并持久化作为新的历史关联统计信息。
[0060]
示例性地,步骤(6)中:
[0061]
(6.1)将历史数据的关联统计信息并入新增数据的统计关联信息中,以新增数据的统计关联信息更新历史数据的关联统计信息,形成更新版的历史数据关联统计信息,并执行持久化操作,等待下一次的新增数据,执行下一轮历史数据的关联统计信息的迭代。
[0062]
(6.1)将历史数据的关联统计信息并入新增数据的统计关联信息中,具体包括如下两种方式:
[0063]
方式1:依据新增数据的统计关联信息,从历史数据的统计关联信息中找到新增数据需要合并的历史统计关联信息。
[0064]
方式2:依据统计数值的过滤条件(即第四字段筛选条件关联属性名和第五字段统计筛选的条件),查找历史数据的统计关联信息中需要更新的数据,对该部分数据执行更新操作并将更新后的信息并入新增数据的统计关联信息。
[0065]
(6.2)新增数据更新历史数据的方式包括以下两种:
[0066]
方式1:与历史数据信息重叠的部分,采用以新增数据统计关联信息替代历史数据的统计关联信息方式处理。
[0067]
方式2:与历史数据信息不重叠的部分,采用以新增数据统计关联信息直接并入的方式处理。
[0068]
(7)输出专家统计特征,根据步骤(6)生成的新的历史数据关联统计信息,为下一个推断周期的数据输出专家统计特征。
[0069]
示例性地,步骤(7)中:利用步骤(6)更新后的历史数据统计关联信息,针对存储的关联统计信息的链表信息分别执行求和(sum)、求最大值(max)、求最小值(min)、求平均值(avg)、计数(count)、提取唯一值(unique)等统计操作,即可快速计算出推断数据的专家统计特征的数值。
[0070]
实施例1
[0071]
(1)构建专家统计特征配置文件:
[0072]
表1为实施例专家统计特征配置文件的表结构,本实例的业务场景是在金融风控领域提供专家统计特征的相关统计信息。
[0073]
表1:专家统计特征配置文件的表结构
[0074][0075]
配置第一字段的列名,将原始数据表单中生成的统计型专家特征名称(new_generated_col_name)作为第一字段的列名。
[0076]
配置第二字段的列名为统计型专家统计特征抽象的统计计算类别(statistic_type),依照从金融(覆盖银行及保险领域)风控体系的专家统计特征抽象的统计计算类别,其中,统计计算类别共计四类,分别为:基于某一特征的历史情况统计值(sta_type_history_value),基于某一特征在有效时间内的执行数值统计的属性列(sta_type_recent_date_value),基于有效时间内的发生次数的统计值(sta_type_recent_date),基于某一特征近几期的数值统计值(sta_type_recent_periods_value)。
[0077]
配置第三字段的列名为统计的分组属性名(col_groupby_name),配置第四字段的列名为统计的筛选条件关联属性名(col_filter),配置第五字段的列名为统计筛选的条件(filter_condition),配置第六字段的列名为统计结果依赖的属性名(col_value),配置第七字段的列名为统计操作类型(calc_func)。
[0078]
(2)读取步骤(1)构建的专家统计特征配置文件中的每一条信息:
[0079]
将对应的第一字段名作为key,后续字段名拼接成list作为value组成哈希映射(hashmap),同时需要专家统计特征的配置合法性进行判断,不合法的特征配置,取消特征生成。合法性判断的步骤具体如下:
[0080]
(2.1)统计计算类别是否属于合法配置项;
[0081]
(2.2)统计计算类别不可缺省的参数项是否合理正确配置;
[0082]
(2.3)若专家统计特征未正确配置,则该特征不放入hashmap中。
[0083]
图2中非空的参数配置项,即为对应统计计算类别不可缺省的参数项,在选定统计计算类别后,对应的参数项必须填写,否则对应专家特征无法生成。
[0084]
(3)离线生成历史数据的关联统计信息:
[0085]
依据步骤(2)中生成的哈希映射(hashmap),获取value链表中统计计算类别参数,依据计算类别参数分别执行不同的离线历史数据的关联信息统计,关联信息存储的目的是为了有效的执行后续的新增数据的迭代,保证专家统计特征正确快速地生成,因此针对不同的统计计算类别数据,需要存储的关联信息如下表2所示。
[0086]
表2:统计计算类别与存储关联信息表
[0087][0088]
为了优化后续利用新增数据执行历史数据的关联统计信息的更新性能,在存储关联信息包含date链表的情况,会同时记录链表中值最小的date数值。
[0089]
(4)持久化关联统计信息:
[0090]
需要保存离线生成的历史数据的关联统计信息,本实例中采用csv格式的文件进行存储,实施例离线生成的历史数据的关联统计信息表如下表3所示。
[0091]
表3:离线生成的历史数据的关联统计信息表
[0092][0093][0094]
(5)在线生成新增数据的关联统计信息:
[0095]
该步骤与步骤3)的生成过程类似,因为在线更新的数据量要远小于离线数据量,因此在线生成新增数据的关联统计信息计算量小,可以很快得到结果。表4为实施例在线生成的新增数据的关联统计信息表图(为了方便对比结果,本实例中进行了存储,实际在线计算无需持久化)。
[0096]
表4:在线生成的新增数据的关联统计信息表
[0097][0098]
(6)更新历史关联统计信息:
[0099]
针对更新数据的统计关联信息以及历史数据的统计关联信息,采用两步走的方式完成,首先筛选历史数据的统计关联信息中涉及更新操作(带时间窗口统计计算类别,即sta_type_recent_date_value、sta_type_recent_date),需要依据统计关联信息的有效时间链表最小有效时间属性列(参见表4,即offline_date_count_within_12_month_date_min属性列)数值做筛选,关联信息的有效时间链表最小有效时间不满足时间窗要求的历史数据统计关联信息需要依据时间窗做筛选并将此部分的历史数据信息并入更新数据的统计关联信息。接着,针对历史数据统计关联信息和更新数据的统计关联信息,对存在分组数值(参见表4,即id属性列)一样的情况,以更新数据的统计关联信息为准;对仅在历史数据统计关联信息存在的分组数值(参见表4,即id属性列),以历史数据的统计关联信息为准;对仅在更新数据统计关联信息存在的分组数值(参见表4,即id属性列),以更新数据的统计关联信息为准。形成更新版的历史数据关联统计信息,并执行持久化操作,等待下一次的新增数据,执行下一轮历史数据的关联统计信息的迭代。实施例更新历史关联统计信息操作后的信息表如表5所示。
[0100]
表5:更新的历史数据关联统计信息表
[0101][0102]
(7)输出专家统计特征:
[0103]
依据步骤(6)更新历史关联统计信息,以及,依据步骤(2)中生成的hashmap的value链表中执行统计操作的类别,针对存储的关联统计信息的链表信息分别执行求和(sum)、求最大值(max)、求最小值(min)、求平均值(avg)、计数(count)、提取唯一值(unique)等统计操作,可以快速得到对应的专家统计特征数值。
[0104]
本技术还提供一种电子设备,包括:一个或多个处理器;存储器,用于存储一个或多个程序;当所述一个或多个程序被所述一个或多个处理器执行,使得所述一个或多个处理器实现如上述的基于专家统计特征的增量计算更新方法。如图2所示,为本发明实施例提供的一种基于专家统计特征的增量计算更新方法所在任意具备数据处理能力的设备的一种硬件结构图,除了图2所示的处理器、内存、dma控制器、磁盘、以及非易失内存之外,实施例中装置所在的任意具备数据处理能力的设备通常根据该任意具备数据处理能力的设备的实际功能,还可以包括其他硬件,对此不再赘述。
[0105]
相应地,本技术还提供一种计算机可读存储介质,其上存储有计算机指令,该指令被处理器执行时实现如上述的基于专家统计特征的增量计算更新方法。所述计算机可读存储介质可以是前述任一实施例所述的任意具备数据处理能力的设备的内部存储单元,例如硬盘或内存。所述计算机可读存储介质也可以是风力发电机的外部存储设备,例如所述设备上配备的插接式硬盘、智能存储卡(smart media card,smc)、sd卡、闪存卡(flash card)等。进一步的,所述计算机可读存储介还可以既包括任意具备数据处理能力的设备的内部存储单元也包括外部存储设备。所述计算机可读存储介质用于存储所述计算机程序以及所述任意具备数据处理能力的设备所需的其他程序和数据,还可以用于暂时地存储已经输出或者将要输出的数据。上述实例是示例性的,不能理解为对本发明的限制,本发明的专利保
护范围包括但不限于上述具体示例实施方式。任何符合本发明的一种基于金融风控专家统计特征的增量计算更新方法的权利要求说明的且任何本领域的技术人员在本发明范围内根据业务场景不同,示例数据,对专家统计特征配置文件、数据库表、持久化存储方式的变化、替换和变型,皆应落入本发明的专利保护范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1