一种日志数据自定义解析方法与流程
1.本发明涉及数据处理领域,尤其涉及一种日志数据自定义解析方法。
背景技术:
2.目前,大数据量日志处理方面的技术竞争越发复杂和激烈,越来越多的安全监控设备和技术的出现为网络安全提供安全保障,来自各种设备的网络日志数据采用不同格式和属性来记录网络行为各个方面。也因此程序处理的日志数据也逐渐增大,对程序的处理性能要求也越来越高,而匹配地址作为网络日志分析的一环,因为需要跟地址库数据做匹配,通常是日志中的ip地址跟百万级的数据做碰撞来获取国家地址、编码、经度纬度等信息,现有的日志解析系统通常会把地址库数据保存在pg mysql等传统数据库中,在通过查询匹配地址数据,但这样的方法再小量级的日志数据环境下才能考虑,在处理日志数据量大时会消耗过长的时间来处理数据,同时对数据库资源产生较大的压力。这种时候优化地址匹配代码的速度就能大幅提升日志分析系统的性能。
技术实现要素:
3.有鉴于此,针对现有的匹配ip地址的算法,应用在大数据领域的spark任务的大数据量级ip地址匹配逻辑还不算完善,对内存和cpu要求较高的技术问题,本发明提出一种日志数据自定义解析方法。
4.一种日志数据自定义解析方法,其包括以下步骤:
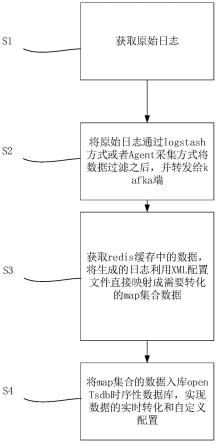
5.s1、获取原始日志;
6.s2、将原始日志通过logstash方式或者agent采集方式将数据过滤之后,并转发给kafka端;
7.s3、获取redis缓存中的数据,将生成的日志利用xml配置文件直接映射成需要转化的map集合数据;
8.s4、将map集合的数据入库opentsdb时序性数据库,实现数据的实时转化和自定义配置。
9.本发明提供的有益效果是:在接入大批量的原始日志,可以通过分析日志的生成数据,自定义解析规则,通过上传解析规则,可以及时的获取情报数据,从而降低开发成本以及时间的消耗。
附图说明
10.图1是本发明一种日志数据自定义解析方法的流程图。
具体实施方式
11.为使本发明的目的、技术方案和优点更加清楚,下面将结合附图对本发明实施方式作进一步地描述。
12.请参考图1,一种日志数据自定义解析方法,包括以下:
13.s1、获取原始日志;
14.需要说明的是,日志是一种半结构化数据,由特定的代码生成。
15.比如日志消息:
16.2015-10-18 18:05:29,570info dfs.datanode$packetresponder:received block blk_-562725280853087685of size 67108864from/10.251.91.84,由代码log.info("received block"+block+"of size"+block.getnumbytes()+"from"+inaddr)生成。
17.以上日志消息中,包括了下列信息:
18.时间戳timestamp:2015-10-18 18:05:29,570;
19.日志级别level:info;
20.组成部分component:datanode$packetresponder;
21.事件模板event template:received block blk562725280853087685 of size67108864from/10.251.91.84;
22.事件模板中的参数parameters:[“blk_-562725280853087685”、“67108864”、“10.251.91.84”];
[0023]
日志模式解析的目的就是将日志解析成如上所示的结构化数据的形式,即从日志中提取出时间戳、等级、组件、日志模板和参数信息。
[0024]
s2、将原始日志通过logstash方式或者agent采集方式将数据过滤之后,并转发给kafka端;
[0025]
需要说明的是,管道(logstash pipeline)是logstash中独立的运行单元,每个管道都包含两个必须的元素输入(input)和输出(output),和一个可选的元素过滤器(filter),事件处理管道负责协调它们的执行。输入和输出支持编解码器,可以在数据进入或退出管道时对其进行编码或解码,而不必使用单独的过滤器。如:json、multiline等,因此在本技术将原始日志进行一些根据实际需求的过滤。
[0026]
s3、获取redis缓存中的数据,将生成的日志利用xml配置文件直接映射成需要转化的map集合数据;
[0027]
需要说明的是,redis是一个key-value存储系统。和memcached类似,它支持存储的value类型相对更多,包括string(字符串)、list(链表)、set(集合)、zset(sorted set
‑‑
有序集合)和hash(哈希类型);
[0028]
原始日志经过过滤后,通过redis获取日志中对应的缓存数据;
[0029]
接下来,利用xml配置文件进行自定义规则处理。
[0030]
其中,xml配置文件包括解析规则单元、解析对象单元和属性规则转换单元;
[0031]
其中,解析规则单元,具体指:根据grok表达式,读取parse标签,通过配合对象实现映射,将数据直接映射成实体类对象。
[0032]
需要说明的是,grok表达式用来快速解析日志,可以将数据按照自定义的名称进行输出。举例如下:
[0033]
%{ip:source_ip}表示使用名为ip的正则表达式提取出内容,并命名为source_ip;
[0034]
在本技术实施例中,需要设计到grok表达式,grok表达式的使用方法这里不再详
细进行介绍,可参考下表;
[0035]
通过表达式标识可以将数据直接映射成对应的数据;
[0036]
表1grok表达式的使用说明
[0037][0038][0039]
解析过程具体操作如下所示:
[0040]
grok表达式格式如下:
[0041]
<%{word}>%{greedydata}%{ip:deviceaddress}\s+%{greedydata:devicename}:发送时间:%{greedydata:occurtimestr}\s+数据名称:%{greedydata}内容:%{greedydata:eventname}事件等级:%{greedydata:level}源ip地址:%{ip:sourceadress}源端口:%{int:sourceport}目标ip地址:%{ip:destinationaddress}目标端口:%{int:detinationport}"
[0042]
日志源输入:
[0043]
《14》sat apr 11 00:11:46 2020 192.168.184.107科来网络全流量安全分析系统-服务器(测试机)发送时间:2022-08-12 15:40:41数据名称:研发测试内容:可疑域名警报事件等级:1源ip地址:209.222.97.22源端口:8080目标ip地址:192.168.182.209目的端口:9091
[0044]
grok解析输出:
[0045]
"deviceaddress":"192.168.184.107",
[0046]
"devicename":"科来网络全流量安全分析系统-服务器(测试机)",
[0047]
"occurtimestr":"2022-08-12 15:40:41",
[0048]
"eventname":"可疑域名警报",
[0049]
"level":"1",
[0050]
"sourceadress":"209.222.97.22",
[0051]
"sourceport":"8080",
[0052]
"destinationaddress":"192.168.182.209",
[0053]
"detinationport":"9091";
[0054]
所述属性规则转换单元具体指:将实体类对象的属性进行相互转换,实现数据增强。属性转化就是对数据的一个特殊处理。
[0055]
例如上述中的level值为1,数据通过属性规则转换单元下面的格式要求,转化为high,最后现实的数据为high。
[0056]
originlevel字段的值用数字1表示,这样能够将原始数据和处理后的数据都保留下来。
[0057]
occurtime发生时间根据原始数据进行格式化得到2022-08-12 15:40:41。
[0058]
devicetype表示的是默认字段,表示所有的原始日志,都默认的设备类型为测试设备。从而实现实体类对象的属性数据增强日志。
[0059]
在本技术实施例中,简单列举出level的属性转换部分的源码实现:
[0060]
《field name=”level”》
[0061]
《transfer key=”1”value=”high”/》
[0062]
而对于occutime部分的属性转化如下:
[0063]
《field name=”occurtime”type=”dateformatter”》
[0064]
《transfer key=”dateformatter”value=”yyyy-mm-dd hh:mm:ss”/》
[0065]
#{level}代表此时的属性值默认为解析匹配的level原始值。
[0066]
transfer代表将字段显示值转化为对应的标签值;
[0067]
formate表示时间解析格式为yyyy-mm-dd;
[0068]
最后,通过解析对象单元将实体类对象进行map存储;
[0069]
map存储,也称为键值对,有一个key,一个value,将解析的对象及数据进行存储。
[0070]
s4、将map集合的数据入库opentsdb时序性数据库,实现数据的实时转化和自定义配置。
[0071]
本发明中,技术上运用到了:kafka、logstash、grok插件等内容,相关插件的使用可参考现有技术文档,这里不再赘述。
[0072]
数据库:支持所有数据库、非关系型数据库:es\opentsdb\mongodb。
[0073]
本发明的操作实施方式:通过调用本服务中的上传xml接口实现规则和对象属性上传,通过调用发送数据接口和指定kafka的topic实现数据的解析,最后生成的map集合数据可供用户自由发挥存入需要的数据库。
[0074]
本发明的有益效果是:采用大数据组件并结合缓存实现数据切分,并采用二分查找等算法进行数据检索的方式能大大提升日志分析领域的效能,解决地址数据大规模匹配的瓶颈。
[0075]
以上所述仅为本发明的较佳实施例,并不用以限制本发明,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1