一种融合实体类型表征与关系表征的关系抽取方法
1.本发明涉及关系抽取领域,具体涉及一种融合实体类型表征与关系表征的关系抽取方法。
背景技术:
2.在当今信息爆炸的背景下,信息抽取技术从海量的非结构化文本中抽取出重要的信息,并重构为下游任务(如:知识图谱构建、搜索引擎知识库构建、问答系统知识库构建)易用的结构化信息。关系抽取是信息抽取的一个重要领域,旨在从非结构化文本中提取结构化的关系三元组信息,即(主体,关系,客体),以帮助刻画实体之间的关联关系。
3.现有的关系抽取方法大多使用基于命名实体识别的联合或管道方法来实现对关系的抽取。在建模时,首先对命名实体主体和客体进行识别,基于识别的结果,在特征信息中强化主体和客体的语义信息去对关系进行抽取,而忽略了语句全局的上下文信息,导致模型一定程度上退化为基于实体对的关系匹配模型,影响了关系抽取的合理性和鲁棒性。为此,本专利提出了一种融合实体类型表征与关系表征的关系抽取方法,增加了模型对于未见实体或语句的性能鲁棒性。
技术实现要素:
4.为解决现有技术中存在的问题,本发明提供了一种融合实体类型表征与关系表征的关系抽取方法,从语义表征、实体类型表征、关系表征出发,利用文本-主客体弱相关语义表征机制和关系特征融合机制,提出了一种新颖的关系抽取模型,可有效地语句的全局上下文信息,实现非结构化文本中实体对和关系的抽取,解决了上述背景技术中提到的问题。
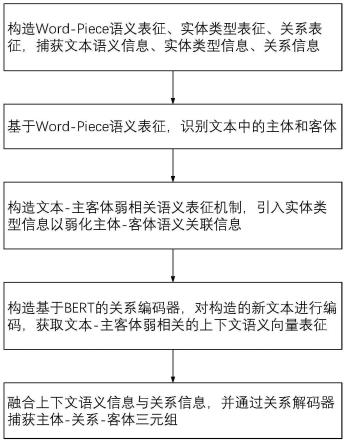
5.为实现上述目的,本发明提供如下技术方案:一种融合实体类型表征与关系表征的关系抽取方法,所述关系抽取方法具体步骤如下:
6.步骤s10:对于输入系统的自然语言文本,基于word-piece分词方法编码文本的语义信息、实体类型信息及关系信息,输出word-piece语义表征、实体类型表征、关系表征;
7.步骤s20:基于输出的word-piece语义表征,进一步利用bert和二元标注法抽取文本中的主体和客体;
8.步骤s30:通过输出的实体类型表征替换抽取出的主体和客体的词义表征,以弱化主体-客体语义关联信息,构造文本中主体与客体的弱相关语义表征机制,生成主体客体之间的弱语义关联新文本;
9.步骤s40:构造基于bert表示模型的关系编码器,对弱语义关联新文本进行编码,提取文本中的高层抽象语义信息,并结合双向上下文信息输出文本-主客体弱相关的上下文语义向量表征;
10.步骤s50:构造文本-主客体弱相关的上下文语义信息与关系信息的融合机制,融合后的表征向量将被用于捕获主体-关系-客体三元组。
11.优选的,所述步骤s10的具体步骤如下:
12.步骤s101,输入系统的自然语言文本为单词序列,s={w1,...,w
l
},其中wi,i∈{1,2,...,l},表示语句中的第i个单词,l为待抽取语句所含单词数量;构造基于bpe双字节编码方式的word-piece表征模型来表示向量空间中的单词,将输入句子中的每个单词都分割为细粒度的子词,输出子词表征序列其中ti,i∈{1,2,...,l},表示语句中的第i个子词,l为待抽取语句经过word-piece划分后的子词长度;
13.步骤s102,将实体类型和关系类型预先输入系统进行向量表征,ε为实体类型的集合,r为关系类型的集合,对于输入系统的任意实体类型e∈ε和任意关系类型r∈r,分别构造基于多层感知机的实体类型和关系表征模型,将离散的实体类型符号和关系类型符号转化为连续的高维表征向量化为连续的高维表征向量以输出实体类型和关系类型的细粒度语义信息。
14.优选的,所述步骤s20的具体步骤如下:
15.步骤s201,构造基于bert神经网络表示模型的命名实体编码器,将子词序列作为系统编码器的输入,顺序通过n个transformer编码器块,通过微调参数对每个词元的双向上下文信息进行深层次编码,输出深度的双向语言表征向量序列
16.其中,trans表示transformer编码器块,h
α-1
表示上一个transformer编码器块的编码结果;
17.步骤s202,建立基于全连接神经网络的命名实体主体解码器和客体解码器,以抽取子词序列中的候选主体和候选客体,以编码器最后一个块的输出为解码器的输入,对子词序列中的每个词元i,计算该词元为主体跨度起点、主体跨度终点、客体跨度起点、客体跨度终点的概率,公式分别如下:
[0018][0019][0020][0021][0022]
其中,用代表全连接神经网络中可学习的权重参数和偏差参数,σ是sigmoid激活函数;
[0023]
对比计算出的概率值type∈start_s,end_s,start_o,end_o是否超过预设定的阈值0.5(该阈值是结合先验知识和超参数实验人为设置的超参数。控制系统根据输出的概率值是否超过阈值,判定该词元是否为对应type的标签),若是,则相应的判定标签type∈start_s,end_s,start_o,end_o被分配为1,否则标签被分配为0;
[0024]
根据上述判定标签的结果输出对应的主体跨度起点、主体跨度终点、客体跨
度起点、客体跨度终点的序列表示,度起点、客体跨度终点的序列表示,度起点、客体跨度终点的序列表示,
[0025]
步骤s203,对主体起点判定序列d
start_s
中的一个1标签,在主体终点判定序列d
end_s
中向右寻找最近的一个1标签,以组成一个潜在主体跨度subi;对于客体判定序列进行相同的操作,输出一个潜在客体跨度obji;
[0026]
对所有主体和客体起点判定序列中的1标签进行上述操作,分别输出潜在主体跨度序列h
sub
=(sub1,...,subm)和潜在客体跨度序列h
obj
=(obj1,...,objn),两两组合,形成潜在主体-客体跨度对序列,h=(sub1,obj1),...,(subm×n,objm×n);
[0027]
其中,m,n分别为子词序列抽取出的潜在主体数目和潜在客体数目。
[0028]
优选的,所述步骤s30的具体步骤如下:
[0029]
步骤s301,构造文本-主客体弱相关语义表征机制,输入实体类型信息以弱化主体-客体语义关联信息,对于给定主体-客体跨度对(subi,objj),i≠j,使用对应的实体类型表征向量对子词序列中对应跨度的表征向量进行替换,以弱化主体-客体语义关联信息,输出新文本表征序列,l2为替换后的子词序列长度,同时输出类型表征向量e(subi),e(objj)在新序列t中的位置,(s1,...,sm)表示主体替换位置序列,m为主体替换长度,(o1,...,on)表示客体替换位置序列,n为客体替换长度。
[0030]
优选的,所述步骤s40的具体步骤如下:
[0031]
步骤s401,对于主体-客体对(subi,objj),i≠j,构造基于bert神经网络表示模型的关系编码器,将新文本表征序列作为系统编码器的输入,顺序通过n个transformer编码器块,通过微调参数对每个词元的双向上下文信息进行深层次编码,输出深度的双向语言表示向量序列其中trans表示transformer编码器块,h
α-1
表示上一个transformer编码器块的编码结果;关系编码器的输出为最后一个transformer编码器块的编码结果,也即文本-主客体弱相关的上下文语义表征其中,hi,i∈{1,2,...,l2},为子词序列的词元ti的上下文编码结果。
[0032]
优选的,所述步骤s50的具体步骤如下:
[0033]
步骤s501,构造基于全连接线性神经网络的关系解码器,计算主体-客体对(subi,objj),i≠j在系统输入的自然语言文本语句为s={w1,...,w
l
}时,输出关系的概率,公式如下:
[0034]
h=h
sub
+h
obj
[0035][0036][0037]
p
i,j,k
=σ(w(h;e(rk))+b)
[0038]
其中,为关系的表征向量,和分别为编码器输出的语义表征在位置(s1,...,si),(o1,...,oj)的值,maxpooling表示最大池化层运算,输出主体表征h
sub
和客体表征h
obj
,两者相加形成总体实体表征h,w,b分别为全连接线性神经网络中可学习的权重参数和偏差参数,σ为sigmoid激活函数;
[0039]
若计算出的概率值p
i,j,k
超过预设阈值0.6(该阈值是结合先验知识和超参数实验人为设置的超参数。控制系统根据输出的概率值是否超过阈值,判定该三元组是否具有某关系),则认为主体-客体对(subi,objj),i≠j在自然语言文本语句为s={w1,...,w
l
}时,存在关系对h=(sub1,obj1),...,(subm×n,objm×n)中的任意实体对和任意计算其发生概率,最终输出结果为所有概率超过预设阈值的三元组形成抽取结果,即自然语言文本语句s={w1,...,w
l
}的关系抽取结果reuslt=((sub1,r1,obj1),...,(subn,rn,objn)),n为抽取出的三元组数量。
[0040]
本发明的有益效果是:
[0041]
1)本发明以自然语言文本为研究对象,提供了一种融合实体类型表征与关系表征的关系抽取方法,从语义表征、实体类型表征、关系表征出发,利用文本-主客体弱相关语义表征机制和关系特征融合机制,提出了一种新颖的关系抽取模型,可有效地语句的全局上下文信息,实现非结构化文本中实体对和关系的抽取。
[0042]
2)本发明除输出语义表征外,还输出了实体类型表征、关系表征,使用基于bert的神经网络模型,同时对主体和客体进行抽取并对抽取出的主体和客体进行配对;根据配对的结果,使用主体和客体的类型信息对主体和客体的编码信息进行替换,获取新的语义信息;使用基于bert的神经网络模型对获取的新语义信息进行再编码,并使用最大池化及多层感知机对是否存在关系进行预测。本发明设计文本-主客体弱相关语义表征机制,通过引入实体类型信息替换实体词意信息,进而降低抽取模型对主体-客体语义关联的依赖。
附图说明
[0043]
图1为本发明方法步骤流程示意图。
具体实施方式
[0044]
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
[0045]
请参阅图1,本发明提供一种技术方案:一种融合弱相关语义表征与关系表征的关系抽取方法,所述关系抽取方法具体步骤如下:
[0046]
步骤1:对于输入系统的自然语言文本,基于word-piece分词方法编码文本的语义信息、实体类型信息及关系信息,输出word-piece语义表征、实体类型表征、关系表征;步骤1-1,输入系统的自然语言文本为单词序列,s={w1,...,w
l
},其中wi,i∈{1,2,...,l},表示语句中的第i个单词,l为待抽取语句所含单词数量。系统构造基于bpe双字节编码方式的
word-piece表征模型来表示向量空间中的单词,将输入句子中的每个单词都分割为细粒度的子词,输出子词表征序列其中ti,i∈{1,2,...,l},表示语句中的第i个子词,l为待抽取语句经过word-piece划分后的子词长度;
[0047]
步骤1-2,将实体类型和关系类型预先输入系统进行向量表征,ε为实体类型的集合,r为关系类型的集合,对于输入系统的任意实体类型e∈ε和任意关系类型r∈r,分别构造基于多层感知机的实体类型和关系表征模型,将离散的实体类型符号和关系类型符号转化为连续的高维表征向量化为连续的高维表征向量以输出实体类型和关系类型的细粒度语义信息。
[0048]
步骤2:基于输出的word-piece语义表征,进一步利用bert和二元标注法抽取文本中的主体和客体;
[0049]
步骤2-1,构造基于bert神经网络表示模型的命名实体编码器。将子词序列作为系统编码器的输入,顺序通过n个transformer编码器块,通过微调参数对每个词元的双向上下文信息进行深层次编码,输出深度的双向语言表征向量序列其中trans表示transformer编码器块,h
α-1
表示上一个transformer编码器块的编码结果;
[0050]
步骤2-2,建立基于全连接神经网络的命名实体主体解码器和客体解码器,以抽取子词序列中的候选主体和候选客体。以编码器最后一个块的输出为解码器的输入,对子词序列中的每个词元i,计算该词元为主体跨度起点、主体跨度终点、客体跨度起点、客体跨度终点的概率,公式分别如下:
[0051][0052][0053][0054][0055]
其中,用代表全连接神经网络中可学习的权重参数和偏差参数,σ是sigmoid激活函数。
[0056]
对比计算出的概率值type∈start_s,end_s,start_o,end_o是否超过预设定的阈值0.5(该阈值是结合先验知识和超参数实验人为设置的超参数。控制系统根据输出的概率值是否超过阈值,判定该词元是否为对应type的标签),若是,则相应的判定标签type∈start_s,end_s,start_o,end_o被分配为1,否则标签被分配为0;
[0057]
系统根据上述判定标签的结果输出对应的主体跨度起点、主体跨度终点、客体跨度起点、客体跨度终点的序列表示,体跨度起点、客体跨度终点的序列表示,体跨度起点、客体跨度终点的序列表示,
[0058]
步骤2-3,系统对主体起点判定序列d
start_s
中的一个1标签,在主体终点判定序列d
end_s
中向右寻找最近的一个1标签,以组成一个潜在主体跨度subi;对于客体判定序列进行相同的操作,输出一个潜在客体跨度obji。对所有主体\客体起点判定序列中的1标签进行上述操作,分别输出潜在主体跨度序列h
sub
=(sub1,...,subm)和潜在客体跨度序列h
obj
=(obj1,...,objn)。两两组合,形成潜在主体-客体跨度对序列,h=(sub1,obj1),...,(subm×n,objm×n),m,n分别为子词序列抽取出的潜在主体数目和潜在客体数目;
[0059]
步骤3:通过输出的实体类型表征替换抽取出的主体和客体的词义表征,以弱化主体-客体语义关联信息,构造文本中主体与客体的弱相关语义表征机制,生成主体客体之间的弱语义关联新文本;
[0060]
步骤3-1,构造文本-主客体弱相关语义表征机制,输入额外的实体类型信息以弱化主体-客体语义关联信息。对于给定主体-客体跨度对(subi,objj),i≠j,系统使用对应的实体类型表征向量对子词序列中对应跨度的表征向量进行替换,以弱化主体-客体语义关联信息,输出新的文本表征序列,l2为替换后的子词序列长度。同时输出类型表征向量e(subi),e(objj)在新序列t中的位置,(s1,...,sm)表示主体替换位置序列,m为主体替换长度,(o1,...,on)表示客体替换位置序列,n为客体替换长度;
[0061]
步骤4:构造基于bert表示模型的关系编码器,对弱语义关联新文本进行编码,提取文本中的高层抽象语义信息,并结合双向上下文信息输出文本-主客体弱相关的上下文语义向量表征;
[0062]
步骤4-1,对于主体-客体对(subi,objj),i≠j,构造基于bert神经网络表示模型的关系编码器。将新的文本表征序列作为系统编码器的输入,顺序通过n个transformer编码器块,通过微调参数对每个词元的双向上下文信息进行深层次编码,输出深度的双向语言表示向量序列其中trans表示transformer编码器块,h
α-1
表示上一个transformer编码器块的编码结果。关系编码器的输出为最后一个transformer编码器块的编码结果,也即文本-主客体弱相关的上下文语义表征其中,hi,i∈{1,2,...,l2},为子词序列的词元ti的上下文编码结果;
[0063]
步骤5:构造文本-主客体弱相关的上下文语义信息与关系信息的融合机制,融合后的表征向量将被用于捕获主体-关系-客体三元组;
[0064]
步骤5-1,构造基于全连接线性神经网络的关系解码器,计算主体-客体对(subi,objj),i≠j在系统输入的自然语言文本语句为s={w1,...,w
l
}时,输出关系的概率,公式如下:
[0065]
h=h
sub
+h
obj
[0066][0067]
[0068]
p
i,j,k
=σ(w(h;e(rk))+b)
[0069]
其中,为关系的表征向量,和分别为编码器输出的语义表征在位置(s1,...,si),(o1,...,oj)的值,maxpooling表示最大池化层运算,输出主体表征h
sub
和客体表征h
obj
,两者相加形成总体实体表征h,w,b分别为全连接线性神经网络中可学习的权重参数和偏差参数,σ为sigmoid激活函数;
[0070]
若计算出的概率值p
i,j,k
超过预设阈值0.6(该阈值是结合先验知识和超参数实验人为设置的超参数。控制系统根据输出的概率值是否超过阈值,判定该三元组是否具有某关系),则认为主体-客体对(subi,objj),i≠j在自然语言文本语句为s={w1,...,w
l
}时,存在关系对h=(sub1,obj1),...,(subm×n,objm×n)中的任意实体对和任意r∈r,计算其发生概率,系统的最终输出结果为所有概率超过预设阈值0.6的三元组形成抽取结果,即自然语言文本语句s={w1,...,w
l
}的关系抽取结果,reuslt=((sub1,r1,obj1),...,(subn,rn,objn)),n为抽取出的三元组数量。
[0071]
本发明方法以自然语言文本为研究对象,设计了一种融合实体类型表征与关系表征的关系抽取方法,从语义表征、实体类型表征、关系表征出发,利用文本-主客体弱相关语义表征机制和关系特征融合机制,提出了一种新颖的关系抽取模型,可有效地语句的全局上下文信息,实现非结构化文本中实体对和关系的抽取。
[0072]
尽管参照前述实施例对本发明进行了详细的说明,对于本领域的技术人员来说,其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1