翻译推荐方法、译后编辑模型的训练方法和相关装置与流程
本技术涉及机器翻译领域,特别是涉及一种翻译推荐方法、译后编辑模型的训练方法和相关装置。
背景技术:
1、随着国际交流的日益深入,人们对语言翻译的需求与日俱增。然而,世界上存在的语言种类繁多,各有特征,形式灵活,使得语言的自动处理,包括语言之间的机器翻译,成为至关重要的技术。
2、机器翻译又称为自动翻译,是利用计算机把一种语言(源语言)转变为另一种语言(目标语言)的过程,一般指自然语言之间句子和全文的翻译。相应的,机器翻译的翻译文本指利用计算机对一种语言文本进行翻译,得到的另一种语言文本。而译后编辑(post-editing,ps)指对机器翻译生成的译文进行完善的过程,使得译文更加符合人类语言风格,得到更好的翻译效果。
3、在译后编辑过程中,需要将译文中不恰当译文进行校正,然而目前的译后编辑方式准确性较低,效果较差。
技术实现思路
1、为了解决上述技术问题,本技术提供了一种翻译推荐方法和相关装置,可以显示的区分源语言片段和目标语言片段,进而针对不同的分段进行区分建模,从而在输出翻译推荐结果时考虑到跨语言信息,提高译后编辑模型的推荐性能,提高翻译推荐结果的准确性,进而提高译后编辑的准确性和译后编辑效果。
2、本技术实施例公开了如下技术方案:
3、一方面,本技术实施例提供一种翻译推荐方法,所述方法包括:
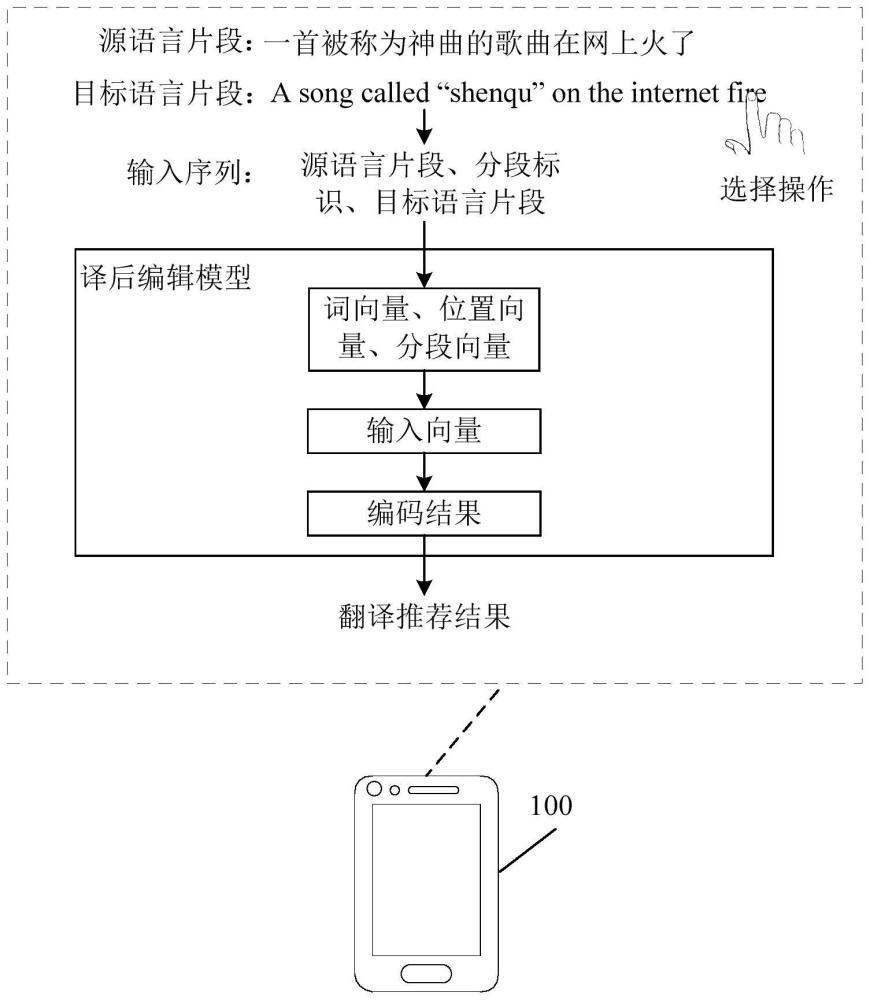
4、获取包括多个分段和分段标识的输入序列,所述多个分段包括源语言片段和带有掩膜标签的目标语言片段,所述分段标识用于将所述源语言片段和所述目标语言片段进行分割,所述目标语言片段是所述源语言片段的第一原始译文,所述掩膜标签位于所述目标语言片段的待推荐位置;
5、通过译后编辑模型对所述输入序列进行嵌入处理得到所述输入序列对应的词向量、位置向量,以及基于所述分段标识进行嵌入处理得到分段向量;
6、基于所述输入序列对应的词向量、位置向量和分段向量,通过所述译后编辑模型进行向量融合得到所述输入序列的输入向量;
7、基于所述输入向量,通过所述译后编辑模型进行编码输出编码结果;
8、基于所述编码结果,通过所述译后编辑模型进行解码输出所述待推荐位置对应的翻译推荐结果。
9、一方面,本技术实施例提供一种译后编辑模型的训练方法,所述方法包括:
10、获取输入样本序列,所述输入样本序列中包括多个样本分段和样本分段标识,所述多个样本分段包括源语言样本片段和带有掩膜标签的目标语言样本片段,所述样本分段标识用于将所述源语言样本片段和所述目标语言样本片段进行分割,所述目标语言样本片段是所述源语言样本片段的第一原始样本译文,所述掩膜标签位于所述目标语言样本片段的样本推荐位置;
11、通过初始网络模型对所述输入样本序列进行嵌入处理得到所述输入样本序列对应的词向量、位置向量,以及基于所述样本分段标识进行嵌入处理得到分段向量;
12、基于所述输入样本序列对应的词向量、位置向量和分段向量,通过所述初始网络模型进行向量融合得到所述输入样本序列的输入样本向量;
13、基于所述输入样本向量,通过所述初始网络模型进行编码输出样本编码结果;
14、基于所述样本编码结果,通过所述初始网络模型进行解码输出所述样本推荐位置对应的预测翻译推荐结果;
15、基于所述预测翻译推荐结果和所述样本推荐位置对应的标准译文对所述初始网络模型进行训练,得到所述译后编辑模型。
16、一方面,本技术实施例提供一种翻译推荐装置,所述装置包括获取单元、处理单元、确定单元、编码单元和解码单元:
17、所述获取单元,用于获取包括多个分段和分段标识的输入序列,所述多个分段包括源语言片段和带有掩膜标签的目标语言片段,所述分段标识用于将所述源语言片段和所述目标语言片段进行分割,所述目标语言片段是所述源语言片段的第一原始译文,所述掩膜标签位于所述目标语言片段的待推荐位置;
18、所述处理单元,用于通过译后编辑模型对所述输入序列进行嵌入处理得到所述输入序列对应的词向量、位置向量,以及基于所述分段标识进行嵌入处理得到分段向量;
19、所述确定单元,用于基于所述输入序列对应的词向量、位置向量和分段向量,通过所述译后编辑模型进行向量融合得到所述输入序列的输入向量;
20、所述编码单元,用于基于所述输入向量,通过所述译后编辑模型进行编码输出编码结果;
21、所述解码单元,用于基于所述编码结果,通过所述译后编辑模型进行解码输出所述待推荐位置对应的翻译推荐结果。
22、一方面,本技术实施例提供一种译后编辑模型的训练装置,所述装置包括获取单元、处理单元、确定单元、编码单元、解码单元和训练单元:
23、所述获取单元,用于获取输入样本序列,所述输入样本序列中包括多个样本分段和样本分段标识,所述多个样本分段包括源语言样本片段和带有掩膜标签的目标语言样本片段,所述样本分段标识用于将所述源语言样本片段和所述目标语言样本片段进行分割,所述目标语言样本片段是所述源语言样本片段的第一原始样本译文,所述掩膜标签位于所述目标语言样本片段的样本推荐位置;
24、所述处理单元,用于通过初始网络模型对所述输入样本序列进行嵌入处理得到所述输入样本序列对应的词向量、位置向量,以及基于所述样本分段标识进行嵌入处理得到分段向量;
25、所述确定单元,用于基于所述输入样本序列对应的词向量、位置向量和分段向量,通过所述初始网络模型进行向量融合得到所述输入样本序列的输入样本向量;
26、所述编码单元,用于基于所述输入样本向量,通过所述初始网络模型进行编码输出样本编码结果;
27、所述解码单元,用于基于所述样本编码结果,通过所述初始网络模型进行解码输出所述样本推荐位置对应的预测翻译推荐结果;
28、所述训练单元,用于基于所述预测翻译推荐结果和所述样本推荐位置对应的标准译文对所述初始网络模型进行训练,得到所述译后编辑模型。
29、一方面,本技术实施例提供一种计算机设备,所述计算机设备包括处理器以及存储器:
30、所述存储器用于存储程序代码,并将所述程序代码传输给所述处理器;
31、所述处理器用于根据所述程序代码中的指令执行前述任一方面所述的方法。
32、一方面,本技术实施例提供一种计算机可读存储介质,所述计算机可读存储介质用于存储程序代码,所述程序代码当被处理器执行时使所述处理器执行前述任一方面所述的方法。
33、一方面,本技术实施例提供一种计算机程序产品,包括计算机程序,该计算机程序被处理器执行时实现前述任一方面所述的方法。
34、由上述技术方案可以看出,本技术在进行翻译推荐时可以获取包括多个分段和分段标识的输入序列,多个分段包括源语言片段和带有掩膜标签的目标语言片段,分段标识用于将源语言片段和目标语言片段进行分割,从而可以显示的区分源语言片段和目标语言片段,目标语言片段是源语言片段的第一原始译文,掩膜标签位于目标语言片段的待推荐位置。将输入序列输入至译后编辑模型,通过译后编辑模型对输入序列进行嵌入处理得到输入序列对应的词向量、位置向量,以及基于分段标识进行嵌入处理得到分段向量,进而基于输入序列对应的词向量、位置向量和分段向量,通过译后编辑模型进行向量融合得到输入序列的输入向量。由于输入向量是基于输入序列对应的词向量、位置向量和分段向量得到的,分段向量是基于分段标识确定的,故输入向量可以显示的区分源语言片段和目标语言片段。这样,根据输入向量,通过译后编辑模型进行编码输出编码结果时,能够针对不同的分段进行区分建模,得到体现不同分段的编码结果,从而考虑到跨语言信息,避免在基于编码结果,通过译后编辑模型进行解码输出待推荐位置对应的翻译推荐结果时,将源语言片段和目标语言片段混淆,导致输出的翻译推荐结果不准。可见,本方案可以通过译后编辑模型进行自动翻译推荐供用户选择,从而实现译后编辑。在进行翻译推荐时,可以显示的区分源语言片段和目标语言片段,进而针对不同的分段进行区分建模,从而在输出翻译推荐结果时考虑到跨语言信息,提高译后编辑模型的推荐性能,提高翻译推荐结果的准确性,进而提高译后编辑的准确性和译后编辑效果。
- 还没有人留言评论。精彩留言会获得点赞!