一种面向边缘计算的配电网自适应集成负荷预测方法与流程
network,rnn),既保留了rnn处理时间序列的优势,同时不需要采用反向传播算法进行权重迭代,只需采用最小二乘估计输出权重矩阵,大大提高了训练效率。同时esn超参数少,主要超参数仅有泄漏率、储备池大小和正则化参数,超参数寻优计算量小。
10.由于esn的初始参数的随机初始化和一次性的训练机制,单一的esn预测模型对未知数据的预测往往会出现不稳定的情况。而集成学习作为为一种元算法,并不是一个单独的机器学习算法,而是通过构建并结合多个机器学习器(基学习器)来完成学习任务,因而当负荷变化频繁时,集成预测模型往往能获得比单一预测模型更高的预测精度和泛化性,但是集成学习算法需要集成众多基学习器,实际应用时的计算资源消耗和存储资源也是巨大的(取决于集成规模),因此,为适应边缘计算装置的硬件资源约束,有必要对众多基学习器进行稀疏化。同时,受到外部环境的影响,负荷数据以及影响因素的分布情况随时间的推移发生改变,而迁移学习作为一种辅助框架为解决数据漂移问题提供了重要的突破口。在保持预测模型的自适应性问题上,卡尔曼滤波算法作为一种数据同化方法,能在原有预测模型基础上融入新的量测数据,实现对负荷的动态预测。且卡尔曼滤波利用线性系统状态方程,通过系统输入输出观测数据,对系统状态进行最优估计,与esn的结构完全契合。
技术实现要素:
11.本发明所要解决的技术问题是,为了克服现的技术的不足,提供一种能够实现最终集成规模降低的面向边缘计算的配电网自适应集成负荷预测方法。
12.本发明所采用的技术方案是:一种面向边缘计算的配电网自适应集成负荷预测方法,包括如下步骤:
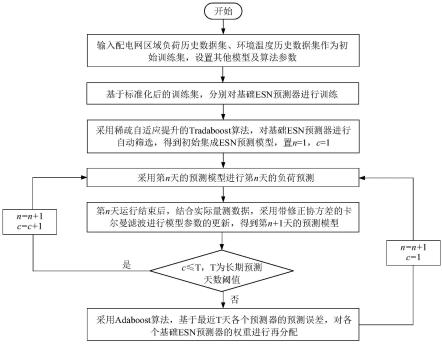
13.1)输入配电网边缘计算装置所辖区域负荷历史数据集e、环境温度历史数据集t,作为初始训练集ω;设置回声状态网络的初始化训练样本个数n0、训练样本个数γ,泄漏率候选集储备池参数候选集正则化参数候选集集成规模n0=n1×
n2×
n3、回声状态变量低维维度d
l
,源域天数md、目标域天数nd,初始后验估计误差的协方差矩阵集合{p}、初始过程噪声协方差矩阵集合{q}、初始量测噪声协方差向量rm、修正因子训练样本计算数k、长期预测天数阈值t
l
;
14.其中,n1、n2、n3分别为泄漏率、储备池参数和正则化参数所在候选集的总个数;为泄漏率候选集中的第n1个泄漏率,为储备池参数候选集中的第n2个储备池参数,为正则化参数候选集中的第n3个正则化参数,集成规模n0即为基础回声状态网络的总个数;
15.2)对初始训练集ω中的负荷历史数据集e、环境温度历史数据集t,分别进行min-max标准化处理,并进行训练样本划分,得到训练集ω
′
;
16.3)基于边缘计算装置计算能力的限制,选取轻量化神经网络中的回声状态网络作为核心预测算法,并引入稀疏编码对储备池回声状态变量进行降维,基于训练集ω
′
,分别对n0个基础回声状态网络{g
l
(x),l=1,2,
…
,n0}进行训练;其中,g
l
(x)为第l个基础回声状态网络;
17.4)置当前预测日天数n=1,长期预测天数标识c=1,为降低边缘计算装置存储资源的需求和集成规模,对训练得到的n0个基础回声状态网络{g
l
(x),l=1,2,
…
,n0},采用稀疏自适应提升的tradaboost算法自动删除非关键基础回声状态网络,将自动筛选后剩余的
基础回声状态网络{g
1,z
(x),z=1,2,
…
,n
sp
}及对应的模型权重系数{αz,z=1,2,
…
,n
sp
},集成得到第1天的集成回声状态网络预测模型g1(x);
18.其中,g
1,z
(x)为第1天的集成回声状态网络预测模型g1(x)的第z个基础回声状态网络,n
sp
为自动筛选后剩余的基础回声状态网络的个数;
19.5)在当前预测日开始前,即第n天开始前,采用第n天的集成回声状态网络预测模型gn(x)进行日前预测,输入预测日前1天的负荷实际值、预测日前7天的负荷实际值和预测日天气预报的环境温度数据,得到第n天负荷预测结果
20.6)在第n天结束后,记录第n天的实际负荷数据为避免频繁重新训练模型以进一步提升预测速度,采用带修正协方差的卡尔曼滤波算法,对第n天的集成回声状态网络预测模型gn(x)进行参数更新,得到第n+1天的集成回声状态网络预测模型g
n+1
(x);
21.7)若c≤t
l
,则令n=n+1,c=c+1,返回步骤5);否则进行步骤8);
22.8)基于gn(x)的各个基础回声状态网络{g
n,z
(x),z=1,2,
…
,n
sp
}在第n-t
l
+1天至第n天的预测误差,采用adaboost算法,对gn(x)的各个基础回声状态网络{g
n,z
(x),z=1,2,
…
,n
sp
}的模型权重系数{αz}进行重新计算,得到新的模型权重系数{α
′z},令n=n+1,c=1,返回步骤5);其中,g
n,z
(x)表示第n天的集成回声状态网络预测模型gn(x)中的第z个基础回声状态网络。
23.本发明的一种面向边缘计算的配电网自适应集成负荷预测方法,立足于解决边缘侧就地负荷预测中的负荷随机性强、季节性明显、预测模型的自适应性等问题,同时尽可能降低预测模型的复杂度和存储资源占用。在模型初始训练阶段,以tradaboost算法为主体集成框架,以esn作为基础预测器;在集成过程中,通过删除预测性能低的esn预测器,并相应地提高预测性能高的esn预测器,实现最终集成规模的降低,降低了后续预测的计算开销和存储资源。在日前的滚动预测阶段,结合每天的实际负荷数据,采用带修正协方差的卡尔曼滤波算法对各个基础esn预测器进行参数更新;当达到长期预测的阈值后,结合前一段时间各个基础预测器的预测性能,采用adaboost算法对各个基础esn预测器的权重进行再分配,解决边缘侧负荷预测模型的自适应问题,为配电网生成分布式电源的控制策略、确定有载调压变的变比等精细化控制优化提供依据。本发明的主要优点如下:
24.(1)在模型初始训练阶段,以esn作为基础预测器,以tradaboost算法为主体集成框架;在集成过程中,通过删除预测性能低的esn预测器,并相应地提高预测性能高的esn预测器,实现最终集成规模的降低,降低了后续预测的计算开销和存储资源。既发挥了集成学习模型的泛化性的优势,又避免的集成学习模型的冗余计算;
25.(2)在日前的滚动预测阶段,为充分发挥新采集的流式数据价值,结合每天的实际负荷数据,采用带修正协方差的卡尔曼滤波算法对各个基础esn预测器进行参数更新;通过自动编码器对隐含层变量进行降维,进一步降低在线更新时的计算和存储资源;
26.(3)当达到长期预测的阈值后,结合前一段时间各个基础预测器的预测性能,采用adaboost算法对各个基础esn预测器的权重进行再分配,解决边缘侧负荷预测模型的自适应问题,覆盖整个预测周期来最大限度地降低模型复杂度;
27.(4)硬件实现方面,预测程序可以部署在一个内存仅为1gb,cpu仅为800mhz的实际的边缘计算装置上,而许多深度学习的模型复杂度较高,难以部署在实际边缘计算装置上。
附图说明
28.图1是本发明的一种面向边缘计算的配电网自适应集成负荷预测方法的流程图;
29.图2是算例1区域1不同方法预测结果对比图;
30.图3是算例2区域20不同方法预测结果对比图。
具体实施方式
31.下面结合实施例和附图对本发明的一种面向边缘计算的配电网自适应集成负荷预测方法做出详细说明。
32.如附图1所示,本发明的一种面向边缘计算的配电网自适应集成负荷预测方法,包括如下步骤:
33.1)输入配电网边缘计算装置所辖区域负荷历史数据集e、环境温度历史数据集t,作为初始训练集ω;设置回声状态网络(echo state network,esn)的初始化训练样本个数n0、训练样本个数γ,泄漏率候选集储备池参数候选集正则化参数候选集集成规模n0=n1×
n2×
n3、回声状态变量低维维度d
l
,源域天数md、目标域天数nd,初始后验估计误差的协方差矩阵集合{p}、初始过程噪声协方差矩阵集合{q}、初始量测噪声协方差向量rm、修正因子训练样本计算数k、长期预测天数阈值t
l
;
34.其中,n1、n2、n3分别为泄漏率、储备池参数和正则化参数所在候选集的总个数;为泄漏率候选集中的第n1个泄漏率,为储备池参数候选集中的第n2个储备池参数,为正则化参数候选集中的第n3个正则化参数,集成规模n0即为基础回声状态网络的总个数;
35.2)对初始训练集ω中的负荷历史数据集e、环境温度历史数据集t,分别进行min-max标准化处理,并进行训练样本划分,得到训练集ω
′
;
36.所述的进行训练样本划分,得到训练集ω
′
,具体为:基于标准化后的初始训练集ω进行训练样本划分,第i个训练样本的输入数据为:第i个预测日前1天的负荷实际值、前7天的负荷实际值和第i个预测日的天气预报的环境温度数据,并将所述的输入数据合并成列向量u(i),维度记为m
×
1;第i个训练样本的标签为训练集ω
′
中第i个预测日的负荷实际值y(i),训练样本的标签维度记为n
×
1;其中,n为日前预测的总时段数。
37.min-max标准化计算公式如下:
[0038][0039]
式中,数据类型u∈{e,t},u表示与数据类型u对应的负荷历史数据集e、环境温度历史数据集t,ui表示u中第i个数据,表示标准化后的值,[a,b]表示标准化后的数值区间,这里取[0,1];
[0040]
3)基于边缘计算装置计算能力的限制,选取轻量化神经网络中的回声状态网络作为核心预测算法,并引入稀疏编码对储备池回声状态变量进行降维,基于训练集ω
′
,分别对n0个基础回声状态网络{g
l
(x),l=1,2,
…
,n0}进行训练;其中,g
l
(x)为第l个基础回声状态网络;
[0041]
所述的基于训练集ω
′
,分别对n0个基础回声状态网络{g
l
(x),l=1,2,
…
,n0}进行训练,具体如下:
[0042]
(3.1)将泄漏率候选集储备池参数候选集正则化参数候选集进行排列组合,并作为n0个基础回声状态网络的超参数;
[0043]
(3.2)设定第l个基础回声状态网络g
l
(x)的超参数组为{r
l
,l
l
,c
l
},初始化储备池回声状态变量x
l
(0)=0,随机生成输入权值矩阵储备池内部连接矩阵稀疏编码随机权值矩阵a
l
、随机偏置矩阵b
l
;其中r
l
、l
l
、c
l
分别表示g
l
(x)的泄漏率、储备池参数和正则化参数,x
l
维度为l
l
×
1,维度为l
l
×
m,维度为l
l
×
l
l
,a
l
维度为d
l
×
(m+l
l
),b
l
维度为d
l
×
γ,m为单个训练样本输入列向量u的维度,γ为训练样本个数;
[0044]
其中,输入权值矩阵随机稀疏矩阵稀疏编码随机权重矩阵a
l
、随机偏置矩阵b
l
的每个元素由均匀分布在[-1,1]上的随机数生成;随机稀疏矩阵与储备池内部连接矩阵具有相同的维度,的获得方式如下:
[0045][0046]
式中,为缩放因子,越接近1,esn的回声特性越强,这里|λ|
max
表示所有特征值的模的最大值;
[0047]
(3.3)基于训练集ω
′
中前n0个初始训练样本,递推计算第l个基础回声状态网络g
l
(x)的储备池回声状态变量,递推公式如下:
[0048][0049]
式中,u(i)为训练集ω
′
中第i个训练样本的输入向量,x
l
(i-1)、x
l
(i)分别为训练集ω
′
中第i-1个、第i个训练样本的储备池回声状态变量,tanh为双曲正切函数;
[0050]
(3.4)形成:
[0051]
(m+l
l
)
×
1维列向量s
l
(i)=[u(i);x
l
(i)],
[0052]
(m+l
l
)
×
γ维矩阵s
l
=[s
l
(n0+1),s
l
(n0+2),
…
,s
l
(n0+γ)],
[0053]n×
γ维矩阵y
l
=[y(n0+1),y(n0+2),
…
,y(n0+γ)],其中,y(n0+1)为训练集ω
′
中第n0+1个训练样本的实际负荷值;
[0054]
计算低维特征矩阵h
l
、稀疏编码降维矩阵输出权值矩阵完成第l个基础回声状态网络g
l
(x)的训练:
[0055]hl
=a
lsl
+b
l
ꢀꢀꢀꢀ
(4)
[0056][0057][0058]
式中,i为单位矩阵,h
l
维度为d
l
×
γ,维度为d
l
×
(m+l
l
),维度为n
×dl
;
[0059]
(3.5)重复第(3.2)步~第(3.4)步,直至完成n0个基础回声状态网络的训练。
[0060]
4)置当前预测日天数n=1,长期预测天数标识c=1,为降低边缘计算装置存储资源的需求和集成规模,对训练得到的n0个基础回声状态网络{g
l
(x),l=1,2,
…
,n0},采用稀疏自适应提升的tradaboost算法自动删除非关键基础回声状态网络,将自动筛选后剩余的
基础回声状态网络{g
1,z
(x),z=1,2,
…
,n
sp
}及对应的模型权重系数{αz,z=1,2,
…
,n
sp
},集成得到第1天的集成回声状态网络预测模型g1(x);
[0061]
其中,g
1,z
(x)为第1天的集成回声状态网络预测模型g1(x)的第z个基础回声状态网络,n
sp
为自动筛选后剩余的基础回声状态网络的个数;
[0062]
所述的采用稀疏自适应提升的tradaboost算法自动删除非关键基础回声状态网络,将自动筛选后剩余的基础回声状态网络{g
1,z
(x),z=1,2,
…
,n
sp
}及对应的模型权重系数{αz,z=1,2,
…
,nsp,集成得到第1天的集成回声状态网络预测模型g1x,具体包括:
[0063]
(4.1)将用于训练的γ个训练样本按时间先后顺序划分为由前md个训练样本构成的源域数据集和由剩余的nd个训练样本构成的目标域数据集;令源域权重参数当前迭代次数l=1,计算训练集ω
′
各训练样本的初始权重
[0064][0065]
(4.2)对于具有样本权重分布d
l-1
的训练集ω
′
,计算第l个基础回声状态网络g
l
(x)在训练集ω
′
上的训练样本最大回归误差e
l
:
[0066]el
=max (∑|y(i)-g
l
(u(i))|),i=1,2,
…
,md+ndꢀꢀꢀ
(8)
[0067]
式中,g
l
(u(i))表示第l个基础回声状态网络g
l
(x)对训练集ω
′
中第i个训练样本的预测值,y(i)为对训练集ω
′
中第i个训练样本的实际值,g
l
(u(i))和y(i)维度均为n
×
1,∑|y(i)-gl(ui)表示对向量yi-gl(ui)的所有元素的绝对值求和;
[0068]
(4.3)计算第l个基础回声状态网络g
l
(x)在训练集ω
′
上的每个训练样本的相对回归误差e
l,i
:
[0069][0070]
(4.4)计算第l个基础回声状态网络g
l
(x)在训练集ω
′
上的总体回归误差e
l
和目标域权重参数β
l
:
[0071][0072][0073]
式中,表示取和0.5的间相对小的值,表示第l次迭代训练集ω
′
中第i个训练样本的权重;
[0074]
(4.5)计算第l个基础回声状态网络g
l
(x)的模型权重系数α
l
及累积模型权重系数r:
[0075][0076][0077]
式中,αv表示第v次迭代时所选的第v个基础回声状态网络gv(x)的模型权重系数;
[0078]
(4.6)若l=1,则令l=l+1,返回步骤(4.2);否则,按下式寻找两个需要进行模型
权重系数调整的第h1和h2次迭代的基础回声状态网络,记为和然后进入第(4.7)步:
[0079][0080][0081]
式中,u(i)表示训练集ω
′
中第i个训练样本的输入向量,gh(u(i))表示第h次迭代所选的第h个基础回声状态网络gh(x)对训练集ω
′
中第i个训练样本u(i)的预测值,gv(u(i))表示第v次迭代所选的第v个基础回声状态网络gv(x)对训练集ω
′
中第i个训练样本u(i)的预测值,表示哈达玛积,即矩阵对应元素相乘;
[0082]
(4.7)计算最优模型权重系数转移步长p
*
并进行相应基础回声状态网络模型权重系数的调整:
[0083][0084][0085]
式中,表示对训练集ω
′
中第i个训练样本的预测值,表示对训练集ω
′
中第i个训练样本的预测值,表示的模型权重系数,表示的模型权重系数;
[0086]
(4.8)若则利用下式(16)调整累积模型权重系数r,并将模型权重系数小于0的基础回声状态网络模型权重系数置为0,删除该基础回声状态网络:
[0087][0088]
(4.9)更新源域、目标域的训练样本权重:
[0089][0090]
(4.10)若l《n0,则令l=l+1,返回步骤(4.2);否则计算得到第1天的集成回声状态网络预测模型g1(x):
[0091][0092]
5)在当前预测日开始前,即第n天开始前,采用第n天的集成回声状态网络预测模型gn(x)进行日前预测,输入预测日前1天的负荷实际值、预测日前7天的负荷实际值和预测日天气预报的环境温度数据,得到第n天负荷预测结果包括:
[0093]
(5.1)设定第n天的集成回声状态网络预测模型gn(x)由n
sp
个基础回声状态网络{g
n,z
(x),z=1,2,
…
,n
sp
}和相应的模型权重系数{αz,z=1,2,
…
,n
sp
}集成得到,gn(x)的第z个基础回声状态网络g
n,z
(x)的输入权值矩阵为输出权值矩阵为稀疏编码降维矩
阵为相应的超参数组为{rz,lz,cz};其中,g
n,z
(x)表示第n天的集成回声状态网络预测模型gn(x)的第z个基础回声状态网络;rz、lz、cz分别表示g
n,z
(x)的泄漏率、储备池参数和正则化参数;令z=1;
[0094]
(5.2)对g
n,z
(x)的储备池回声状态变量进行更新:
[0095][0096]
式中,u(n)为第n天的输入向量,xz(n-1)、xz(n)分别为gn(x)的第z个基础回声状态网络g
n,z
(x)在第n-1天、第n天的储备池回声状态变量,tanh为双曲正切函数;
[0097]
(5.3)对g
n,z
(x)的储备池回声状态变量进行降维,得到降维后的储备池回声状态变量hz(n):
[0098][0099]
(5.4)输出g
n,z
(x)的预测结果yz(n):
[0100][0101]
(5.5)若z《n
sp
,则令z=z+1,返回第(5.2)步;否则计算得到第n天负荷预测结果
[0102][0103]
式中,α
p
为第n天的集成回声状态网络预测模型gn(x)的第p个基础回声状态网络的模型权重系数。
[0104]
6)在第n天结束后,记录第n天的实际负荷数据为避免频繁重新训练模型以进一步提升预测速度,采用带修正协方差的卡尔曼滤波算法,对第n天的集成回声状态网络预测模型gn(x)进行参数更新,得到第n+1天的集成回声状态网络预测模型g
n+1
(x);包括:
[0105]
(6.1)设定第n天的集成回声状态网络预测模型gn(x)由n
sp
个基础回声状态网络{g
n,z
(x),z=1,2,
…
,n
sp
}和相应的模型权重系数{αz,z=1,2,
…
,n
sp
}集成得到,gn(x)的第z个基础回声状态网络g
n,z
(x)的输入权值矩阵为输出权值矩阵为稀疏编码降维矩阵为相应的超参数组为{rz,lz,cz};其中,g
n,z
(x)表示第n天的集成回声状态网络预测模型gn(x)的第z个基础回声状态网络;rz、lz、cz分别表示g
n,z
(x)的泄漏率、储备池参数和正则化参数;令z=1;
[0106]
(6.2)计算g
n,z
(x)的第m个时段的权值分量对g
n,z
(x)的第m个时段的权值分量先验估计误差的协方差矩阵进行更新:
[0107][0108][0109]
式中,表示第m行,表示第m行的转置,p
n-1,z
(m)、q
n-1,z
(m)分别表示第n-1天集成回声状态网络预测模型g
n-1
(x)的第z个基础回声状态网络g
n-1,z
(x)的第m个时段的权值分量后验估计误差的协方差矩阵和过程噪声协方差矩阵;
[0110]
(6.3)计算g
n,z
(x)的第m个时段的卡尔曼增益k
n,z
(m):
[0111][0112]
式中,hz(n)表示g
n,z
(x)降维后的储备池回声状态变量;
[0113]
(6.4)更新g
n,z
(x)的第m个时段的后验估计误差协方差矩阵p
n,z
(m):
[0114][0115][0116]
式中,fe(m)为p
n,z
(m)的修正因子,c(m)为在第n-k天至第n天的第m个时段的预测误差的方差,计算如下:
[0117][0118]
式中,表示第n-j天的第m个时段的实际负荷值,表示第n-j天集成回声状态网络预测模型g
n-j
(x)的第z个基础回声状态网络g
n-j,z
(x)的第m个时段的负荷预测值;
[0119]
(6.5)更新g
n,z
(x)的第m个时段的权值分量得到第n+1天集成回声状态网络预测模型g
n+1
(x)的第z个基础回声状态网络g
n+1,z
(x)的输出权值矩阵
[0120][0121][0122]
式中,表示第n天的第m个时段的实际负荷值,为g
n+1,z
(x)的第m个时段的权值分量;
[0123]
(6.6)若z《n
sp
,令z=z+1,返回第(6.2)步;否则,得到第n+1天的集成回声状态网络预测模型g
n+1
(x)。
[0124]
7)若c≤t
l
,则令n=n+1,c=c+1,返回步骤5);否则进行步骤8);
[0125]
8)基于gn(x)的各个基础回声状态网络{g
n,z
(x),z=1,2,
…
,n
sp
}在第n-t
l
+1天至第n天的预测误差,采用adaboost算法,对gn(x)的各个基础回声状态网络{g
n,z
(x),z=1,2,
…
,n
sp
}的模型权重系数{αz}进行重新计算,得到新的模型权重系数{α
′z},令n=n+1,c=1,返回步骤5);其中,g
n,z
(x)表示第n天的集成回声状态网络预测模型gn(x)中的第z个基础回声状态网络。
[0126]
本发明的一种面向边缘计算的配电网自适应集成负荷预测方法,采用轻量级神经网络esn作为基础预测器,以tradaboost算法为主体集成框架,通过删除预测性能低的esn预测器,并相应地提高预测性能高的esn预测器,实现集成规模的降低,降低了后续预测的计算开销和存储资源。在日前的滚动预测阶段,结合每天的实际负荷数据,采用带修正协方差的卡尔曼滤波算法对各个基础预测器进行更新;在长期预测中,定期采用adaboost算法对各个基础esn预测器的权重进行再分配,解决边缘侧负荷预测模型的自适应问题。
[0127]
下面给出具体实例:
[0128]
为证明本发明模型(model-4)的有效性,在全球能源预测竞赛(gefcom2012)负荷数据集上进行了仿真实验,并重点将结果与如下模型进行了对比:
[0129]
常规集成esn模型(model-1):采用esn作为基础预测器,采用tradaboost作为集成
学习框架,后续预测不对模型参数进行调整;
[0130]
稀疏集成esn模型(model-2):在model-1的基础上,对基础预测器进行自动筛选,降低最终集成规模,后续预测不对模型参数进行调整;
[0131]
稀疏集成esn-kf模型(model-3):初始模型与model-2相同,每天采用带修正协方差的卡尔曼滤波算法进行模型的更新。
[0132]
此外,还与传统机器学习模型、传统集成学习模型进行了对比,传统机器学习模型采用了梯度提升树(gradient boosting decision tree,gbdt)模型,传统集成学习模型采用了使用较为广泛的adaboost集成算法。
[0133]
评价指标采用常见的平均绝对百分比误差(mape),计算如下:计算方式如下:
[0134][0135]
式中,n为日前预测的总的时段数,xi为第i个小时的实际负荷值,第i个小时的预测负荷值。
[0136]
本发明所提方法可以部署在一个内存仅为1gb,cpu仅为800mhz的实际的边缘计算装置上,为了方便比较不同模型的预测性能和计算速度,所有模型构建及训练在matlab2018上进行,硬件平台采用intel core i7 cpu,主频2.9ghz,内存16gb。
[0137]
算例1选取全球能源预测竞赛负荷数据集中的区域1、11、12、15和20作为研究对象,训练集采用2007.1.1-2007.3.31之间的数据,测试集采用2007.4.1-2007.4.7之间的数据。输入相关参数:用于初始化网络的样本数为n0=20、用于训练的样本数为γ=70、回声状态网络esn泄漏率候选集{0.92,0.94,0.96,0.98}、储备池参数候选集{700,800,900,1000,1100,1200}、正则化参数候选集{10,102,103,104}、集成规模n0=80、目标低维维度d
l
=100、源域天数md=50、目标域天数nd=20、修正因子样本计算数k=30、长期预测天数阈值t
l
=30,初始后验估计误差的协方差矩阵集合{p}的主对角线元素取10-2
,其余为0;初始过程噪声协方差矩阵集合{q}的主对角线元素取10-4
,其余为0;初始量测噪声协方差向量rm各个元素均取10-4
。
[0138]
所有集成类预测模型均进行10次独立实验,取平均值作为最终结果。各个区域不同模型的预测结果对比如附表1所示,区域1不同方法预测结果如附图2所示,由于测试集天数只有7天,未进行基础预测器权重的调整,因此model-4与model-3结果一致,故model-4结果未列出。由附表1和附图2可知,gbdt的预测结果最差,adaboost.r2的结果其次,在区域1、11、15上,model-4的预测性能最佳,但在区域12和20上并未取得最佳的预测性能。这是由于测试集时间过短,过程噪声矩阵和量测噪声取值非理想值的原因所致。
[0139]
不同模型的计算时间对比如附表2所示,gbdt的平均训练时间和平均预测时间都是最短的,这是由于其他模型都采用了集成学习,训练众多基础预测器时间开销大,但相应地,gbdt的预测性能最差;由于model-1采用的是tradaboost框架,相比于adaboost训练时间略长,model-2和model-4加入了自动筛选机制,在平均训练时间上最长,但增加的时间开销相对很低。在平均预测时间上,mdel-4由于采用了卡尔曼滤波,而其他模型不需要进行参数更新,故model-4平均预测时间最长,但在后续预测时,model-4不需要重新训练,且平均预测时间比平均训练时间少很多,总体来看仍具有优势。
[0140]
为了验证model-3和model-4的自适应性,针对算例1中短期未取得最佳预测结果
的区域12和20进行了算例2的实验。算例2其他条件与算例1一致,不同之处在于将测试时间延长了,测试集时间为2007.4.1-2008.1.31。model1-4相对于gbdt预测性能差距较为明显,为了比较的直观清晰,只给出了model1-4在区域20在2007.4.1-2007.5.31的日移动平均mape曲线,如附图3所示,具体的统计误差如附表3所示。由附图3和附表3可知,model-3和model-4由于每天都更新模型参数,即使在近一年的预测中,不需重新训练,也能保证预测结果的准确性。在一个月后,model-3和model-4的预测性能便稳定优于model-1和model-2。model-4由于每个月还会对基础预测器进行权重的再分配,因此相较于于model-3仍有小幅提高。
[0141]
综上,本发明提出的一种面向边缘计算的配电网自适应集成负荷预测方法能有效对边缘侧负荷进行日前预测,且计算开销、存储资源占用较少,具有部署在边缘装置上的可行性。
[0142]
表1算例1不同方法预测结果对比(mape,%)
[0143]
区域编号gbdtadaboost.r2model-1model-2model-4125.0924.8613.3113.3012.851125.1523.5410.3810.3810.311225.0924.348.048.059.321522.1222.0214.8814.8814.762019.4320.0811.0211.0212.05
[0144]
表2算例1不同方法计算时间对比
[0145][0146]
表3算例2不同方法预测结果对比(mape,%)
[0147]
区域编号model-1model-2model-3model-4128.428.426.516.43209.549.566.256.19
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1