一种基于深度自编码器的HTTP流量异常检测方法与流程
一种基于深度自编码器的http流量异常检测方法
技术领域
1.本发明涉及网络通信安全技术领域,更具体地说,本发明涉及一种基于深度自编码器的http流量异常检测方法。
背景技术:
2.互联网技术的飞速发展,使人们越来越依赖互联网服务,随之产生了海量的流量数据。从海量数据中识别异常流量,变得更加重要。随着机器学习的发展和应用,异常流量识别方法也从传统的waf工具转向了基于机器学习的方法。
3.基于机器学习的异常流量检测方法,大致可分为两类:有监督的分类方法和无监督的异常检测方法。常用的分类方法有knn,svm,决策树等。不同分类方法的分类目标不同,比如svm的目标是寻找一个能将正负样本最大程度分开的最优超平面,决策树则是寻找对特征属性进行划分的一系列决策规则集合。
4.这类方法的缺点是,对数据要求较高,需要足够的带有标签的样本数据。但在实际业务中,异常数据较少,数据标注成本高,很难获取带有标签的数据。并且,分类方法只能识别已知的异常,对未知的异常无法识别。常用的异常检测方法有孤立森林,one-class svm,lof等,这类方法无需样本标签,通常需要人工构造特征,在正常数据上进行训练。因为没有标签数据,模型无法根据标签学习,所以效果的优劣非常依赖特征的设计,对人工专业领域的知识和经验要求较高。
技术实现要素:
5.为了克服现有技术的上述缺陷,本发明的实施例提供一种基于深度自编码器的http流量异常检测方法,本发明所要解决的技术问题是:现有的异常流量检测方法异常数据较少,数据标注成本高,很难获取带有标签的数据。
6.为实现上述目的,本发明提供如下技术方案:一种基于深度自编码器的http流量异常检测方法,包括具体检测步骤如下:
7.s1、数据采集:接入流量采集或解析设备,解析流量获得http流量事件;对最终得到的http流量事件进行下一步处理;
8.s2、数据处理:http流量事件包括请求(request)部分和响应(response)部分;抽取request部分和response部分中http协议所涵盖的各类文本内容,进行文本组合,得到语义不变文本,该文本用于表达对应的http流量事件;然后对http流量事件的语义不变文本进行随机形态字符串检测替换、字符泛化和多自然语言词汇拆分的相关文本变换操作后,得到标准化文本;
9.s3、向量化表示:对经过上述步骤s1-s2过程处理后的得到的标准化文本,统计所有单词的出现次数,将出现次数较多的词作为特征,使用词袋模型,对每条文本数据进行向量化表示,每条数据表示成一维向量;特征值计算方法参考自然语言处理技术领域的经验或根据需求自定义;
10.s4、异常样本剔除:将向量化表示的数据输入聚类模型进行训练;用训练好的聚类模型对数据进行聚类,通过从类簇中抽样的方式,对聚类结果进行验证;剔除包含异常数据的簇,将剩余数据作为训练数据;
11.s5、训练异常流量识别模型:将训练数据输入深度自编码器模型进行训练;深度自编码器基于正常数据,通过自监督的方式对输入变量进行重构;正常数据之间较为相似,重构误差较小,而异常数据跟正常数据差异较大,重构后的误差通常较大;预测时,通过计算重构变量和输入变量的误差是否超过阈值,实现异常流量识别;其中,阈值的设定可结合训练数据的异常分数,采取多种方式制定;
12.s6、异常流量检测:用训练好的异常流量识别模型对新流量进行检测,识别异常流量。
13.在一个优选的实施方式中,所述步骤s1数据采集中根据自定义策略对http流量事件进行采样、过滤、剔除以降低整个模型构建过程的内存占用或时间消耗;
14.采样策略围绕以保证http流量事件内容多样性为目标进行设计。
15.在一个优选的实施方式中,所述步骤s2中具体流程如下:
16.s2.1:对每条http流量事件,从request部分中抽取path,query和body位置的文本内容,从response部分中抽取body位置的文本内容;将抽取的各文本内容按照统一的顺序组合成一条文本,得到语义不变文本;经过多类通用实验数据场景验证;
17.s2.2、字符泛化:对每条http流量事件对应的语义不变文本中的特殊字符进行泛化,消除特殊字符的对文本语义的影响;其中特殊字符包含数字、中文或特殊符号的类型字符;
18.s2.3、随机形态字符串检测替换:在准备好的数据集上训练马尔可夫模型,用训练好的马尔可夫模型进行随机字符串识别,对识别到的随机形态字符串进行标准字符串替换;
19.s2.4、自然语言词汇拆分:对经过上述步骤s2.1-s2.3的过程处理后得到的文本,进行字符串语义识别、拆分和转换;
20.s2.5、其他文本处理操作:对经过上述过程处理后得到的文本,选择进行其他文本处理操作以满足性能和效果目标。
21.在一个优选的实施方式中,所述步骤s3的具体流程如下:
22.s3.1:从数据集中统计不同单词出现的次数,将出现次数较高的单词作为特征词典;
23.s3.2:将每条数据表示成词典长度的向量。
24.在一个优选的实施方式中,所述步骤s4中聚类算法从kmeans或dbscan的成熟算法中选择。
25.在一个优选的实施方式中,所述步骤s5中深度自编码器有多层神经网络结构,由编码器和解码器组成;编码器将输入变量编码x为包含重要信息的低维中间变量z,解码器将中间变量z还原为重构变量公式如下:
[0026][0027]
本发明的技术效果和优点:
[0028]
本发明将http流量事件视为包含语义信息的文本,经过自然语言处理相关技术的预处理操作后,使用词袋模型进行向量化表示,并在使用聚类算法剔除异常样本后,输入深度自编码器模型进行训练,得到异常流量识别模型,用于http流量异常检测,借助自然语言处理领域算法进行分析和处理,提出应用深度自编码器模型对http流量事件进行分析和处理,并实现了深度自编码器模型在http流量事件数据集上的训练技术方法及异常检测技术方法。
附图说明
[0029]
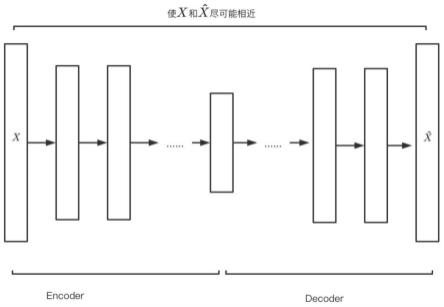
图1为本发明的深度自编码器原理示意图。
[0030]
图2为本发明的异常流量识别模型训练流程图。
[0031]
图3为本发明的异常流量检测流程图。
具体实施方式
[0032]
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
[0033]
本发明提供了一种基于深度自编码器的http流量异常检测方法,具体检测步骤如下:
[0034]
s1、数据采集:接入流量采集或解析设备,解析流量获得http流量事件;出于性能优化的目的,可选择根据自定义策略对http流量事件进行采样、过滤、剔除以降低整个模型构建过程的内存占用或时间消耗;出于模型构建效果优化的目的,采样策略可围绕以保证http流量事件内容多样性为目标进行设计,例如采样策略可定义为保留响应码为2xx等事件、不保留响应内容包含错误信息的事件等等;对最终得到的http流量事件进行下一步处理;
[0035]
s2、数据处理:http流量事件包括请求(request)部分和响应(response)部分;抽取请求(request)部分和响应(response)部分中http协议所涵盖的各类文本内容,进行文本组合,得到语义不变文本,该文本用于表达对应的http流量事件;每个http流量事件都可通过该方式得到其对应的语义不变文本形式;然后对http流量事件的语义不变文本进行随机形态字符串检测替换、字符泛化和多自然语言词汇拆分的相关文本变换操作后,得到标准化文本,其形式类似于自然语言中的一行或一段语句,构成语句的词汇通过空格进行分隔;
[0036]
具体流程如下:
[0037]
s2.1:对每条http流量事件,从请求(request)部分中抽取path,query和body位置的文本内容,从响应(response)部分中抽取body位置的文本内容;可选的,可视具体情况根据自定义策略从request部分和response部分中抽取全部或部分请求头和响应头文本内容;将抽取的各文本内容按照统一的顺序组合成一条文本,得到语义不变文本;经过多类通用实验数据场景验证,具体的组合顺序对最终整体模型效果的影响可忽略不计;如果某些特定场景下的组合顺序对整体模型效果影响较大,应当使用最终表现最好的组合顺序;
[0038]
s2.2、字符泛化:对每条http流量事件对应的语义不变文本中的特殊字符进行泛化,消除特殊字符的对文本语义的影响;其中特殊字符包含数字、中文或特殊符号的类型字符;出于效果优化目的,可根据实际情况扩大字符泛化范围,例如不同国家语言字符集环境中的拼音符号等;
[0039]
s2.3、随机形态字符串检测替换:在准备好的数据集上训练马尔可夫模型,用训练好的马尔可夫模型进行随机字符串识别,对识别到的随机形态字符串进行标准字符串替换,该过程用于消除随机形态字符串对文本语义的影响;例如,对于随机形态字符串“xge34fyrbf38fh”进行检测替换后,其文本内容变成“string”;出于效果优化的目的,可扩大随机形态字符串定义范围,例如将uuid形态字符串、哈希形态字符串等都作为随机形态字符串进行检测替换;替换所用的字符串形式可自定义,但需要保证其形式全局保持统一,例如全部使用“string”字符串形式进行替换,或全部使用“randomvalue”字符串形式进行替换;
[0040]
s2.4、自然语言词汇拆分:对经过上述步骤s2.1-s2.3的过程处理后得到的文本,进行字符串语义识别、拆分和转换;该过程目标在于桥接非自然语言词汇和自然语言词汇,实现非自然语言词汇到自然语言词汇的转化映射;作为可选操作策略之一,可将多个单词连在一起的字符串拆分成多个单词,例如,对“getuserinfo”拆分后变成“get”、“user”、“info”三个单词;作为可选操作策略之一,可将单词缩写还原为其自然语言形式,例如:“info”可还原为“information”单词;
[0041]
s2.5、其他文本处理操作:对经过上述过程处理后得到的文本,选择进行其他文本处理操作以满足性能和效果目标;例如,可选的,可剔除语义无关词汇,包括自然语言中的语气词、停用词等对语义正确性影响较少的词汇,降低无关词汇干扰,提升处理性能
[0042]
s3、向量化表示:对经过上述步骤s1-s2过程处理后的得到的标准化文本,统计所有单词的出现次数,将出现次数较多的词作为特征,使用词袋模型,对每条文本数据进行向量化表示,每条数据表示成一维向量,例如:[2,1,0,0,1,0,0,0,3,0,0,......];特征值计算方法参考自然语言处理技术领域的经验或根据需求自定义,例如使用tf(termfrequency)方法;
[0043]
具体流程如下:
[0044]
s3.1:从数据集中统计不同单词出现的次数,将出现次数较高的单词作为特征词典;
[0045]
s3.2:将每条数据表示成词典长度的向量,例如,如果使用tf(termfrequency)方法,可将对应位置的值用该单词在该条数据中的出现次数表示
[0046]
s4、异常样本剔除:将向量化表示的数据输入聚类模型进行训练;用训练好的聚类模型对数据进行聚类,通过从类簇中抽样的方式,对聚类结果进行验证;剔除包含异常数据的簇,将剩余数据作为训练数据;聚类算法从kmeans或dbscan的成熟算法中选择;
[0047]
s5、训练异常流量识别模型:将训练数据输入深度自编码器模型进行训练深度自编码器有多层神经网络结构,由编码器和解码器组成;编码器将输入变量编码x为包含重要信息的低维中间变量z,解码器将中间变量z还原为重构变量训练目标是最小化重构误差,公式如下:
[0048][0049]
深度自编码器基于正常数据,通过自监督的方式对输入变量进行重构;正常数据之间较为相似,重构误差较小,而异常数据跟正常数据差异较大,重构后的误差通常较大;预测时,通过计算重构变量和输入变量的误差是否超过阈值,实现异常流量识别;其中,阈值的设定可结合训练数据的异常分数,采取多种方式制定;
[0050]
s6、异常流量检测:用训练好的异常流量识别模型对新流量进行检测,识别异常流量;异常流量检测过程如图3所示。
[0051]
如图1-3所示的,实施方式具体为:
[0052]
首先,获取http流量数据,对http流量事件的文本内容进行预处理,提取http流量事件的请求path、请求query、请求头、响应头、请求body、响应body等各部分文本内容进行组合,获得语义不变文本;对组合后的语义不变文本进行随机形态字符串检测替换、字符泛化、多自然语言词汇拆分等相关文本处理操作后,将每个http流量事件转换成对应的标准化文本;
[0053]
然后,从处理后的标准化文本中提取出现次数较多的单词,作为特征词典,使用词袋模型对数据进行向量化表示,将http流量事件转换为向量形式;最后,借助聚类算法剔除异常样本或事件向量,将剩余的样本或事件向量作为训练数据,输入深度自编码器模型并进行训练,得到异常流量识别模型(异常流量识别模型训练过程如图2所示),可用于http异常流量检测。这种方法的优点是,无需人工构造特征,避免了对人工知识的过度依赖;借助文本表示相关技术将文本词汇自身作为特征构建深度自编码器模型,对未知的异常流量也能实现有效检测。
[0054]
深度自编码器(深度自编码器结构如图1所示)是一种无监督的神经网络模型,它的思想是对输入向量进行重构,通过计算输入向量的重构误差来判断输入是否异常。深度自编码器由编码器和解码器组成,编码器将输入向量x编码成低维的隐向量,解码器将隐向量还原成跟输入向量相近的输出向量训练目标是使输出向量和输入向量x尽可能相近。深度自编码器基于正常样本数据训练模型,计算重构误差与阈值进行比较,实现异常流量检测。
[0055]
最后应说明的几点是:首先,在本技术的描述中,需要说明的是,除非另有规定和限定,术语“安装”、“相连”、“连接”应做广义理解,可以是机械连接或电连接,也可以是两个元件内部的连通,可以是直接相连,“上”、“下”、“左”、“右”等仅用于表示相对位置关系,当被描述对象的绝对位置改变,则相对位置关系可能发生改变;
[0056]
其次:本发明公开实施例附图中,只涉及到与本公开实施例涉及到的结构,其他结构可参考通常设计,在不冲突情况下,本发明同一实施例及不同实施例可以相互组合;
[0057]
最后:以上所述仅为本发明的优选实施例而已,并不用于限制本发明,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1