一种序列推荐方法及设备与流程
1.本发明属于通信技术技术领域,特别是涉及一种序列推荐方法及设备。
背景技术:
2.随着互联网应用逐渐广泛,序列推荐技术显得越来越重要,比如购物、听音乐、看视频等等序列推荐场景出现的越来越频繁。目前存在着多种序列推荐技术,对序列推荐产生了重要的影响,但仍存在改进空间。
3.顺序推荐(sr)由于其成功性和可扩展性,引起了学术界和业界的广泛关注。sr方法通过按时间顺序对交互进行排序,将每个用户的历史交互格式化为一个序列。sr的目标是描述用户不断变化的兴趣,并预测下一个首选项。sr通过在序列中建模项目-项目转换关系来编码用户的动态兴趣。
4.目前已知的几种顺序推荐的方案:(1)马尔可夫链markov chain:通过历史数据构建项目之间的转移矩阵,之后只需要通过建立好的转移矩阵就可以预测下一个可能的项目是什么了。(2)循环深度网络rnn:给定一个历史用户-项目交互序列,基于循环神经网络(rnn)的序列推荐通过对给定交互的顺序依赖关系建模来预测下一个可能的交互。其中,比较经典的模型是gru4rec。(3)注意力机制transformer:transformer技术引入了自我注意机制来揭示位置-项目-项目关系。比较典型的模型有sasrec和bert4rec。sasrec是根据transformer技术的改进的,允许捕捉长期语义,拥有注意机制,预测较少的动作。它从动作历史记录中确定哪些项目是“相关的”,并用于预测下一个项目。bert4rec同样改进了transformer技术,采用顺序双向建模。
5.基于transformer的方法将项目嵌入为向量,使用点积自我注意力的方法来衡量项目之间的关系,表现出优越的能力。但是基于点积自我注意的方法未能考虑动态不确定性和协作传递性的问题。现有的sr方法假设动态用户兴趣是确定性的。因此,推断出的用户嵌入是潜在空间中的固定向量,不足以表示各种用户兴趣,尤其是在真实的动态环境中。项目转换反映了用户顺序行为的演变过程,有时很难理解,一个项目转换中的两个项目甚至可能不在同一产品类别中。因此,如果用户有很大一部分意外的项目转换,那么使用确定性流程对该用户进行建模可以获得次优的建议。bpr衡量用户对积极项目和随机抽样的消极项目的偏好得分之间的差异。然而,不能保证正项在潜在空间中离负项更远。
技术实现要素:
6.为了解决上述问题,本发明提出了一种序列推荐方法及设备,能够有效提升序列推荐准确性和效率,使得推荐技术更加合理有效。
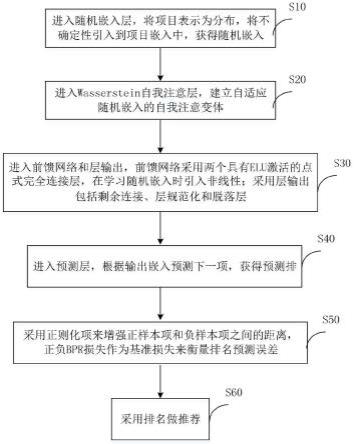
7.为达到上述目的,本发明采用的技术方案是:一种序列推荐方法,包括步骤
8.s10,进入随机嵌入层,将项目表示为分布,将不确定性引入到项目嵌入中,获得随机嵌入;
9.s20,进入wasserstein自我注意层,建立自适应随机嵌入的自我注意变体;
10.s30,进入前馈网络和层输出,前馈网络采用两个具有elu激活的点式完全连接层,在学习随机嵌入时引入非线性;采用层输出包括剩余连接、层规范化和脱落层;
11.s40,进入预测层,根据输出嵌入预测下一项,获得预测排名;
12.s50,采用正则化项来增强正样本项和负样本项之间的距离,正负bpr损失作为基准损失来衡量排名预测误差;
13.s60,采用排名做推荐。
14.进一步的是,使用多维椭圆高斯分布来表示项,椭圆高斯分布由平均向量和协方差向量控制,其中协方差引入项目的潜在不确定性;
15.对于所有项目,定义一个平均嵌入表m
μ
和协方差嵌入表m
σ
;
16.由于均值和协方差识别不同的信号,为均值和协方差引入单独的位置嵌入p
μ
和p
σ
,获得用户的均值和协方差序列嵌入,计算公式为:
[0017][0018]
随机嵌入表示为d-维椭圆高斯分布其中并且并且
[0019]
进一步的是,在wasserstein自我注意层建立自适应随机嵌入的自我注意变体时:
[0020]
表示作为自我关注的价值观,分别获取项目sk和项目s
t
的随机嵌入;
[0021]
采用wasserstein距离来测量两个项目的随机嵌入之间的距离,计算a
kt
表示项目sk和项目s
t
之间的注意值,k≤t,包括:
[0022]
对于两个项目sk和s
t
,相应的随机嵌入是和
[0023]
其中:
[0024][0025]
其中,分别表示对应的项目的不同距离值,σ表示协方差距离,μ表示平均值距离,k表示项目sk中第k个项目,t表示项目s
t
中第t个项目;
[0026]
将注意力权重定义为2-wasserstein距离w2(
·
,
·
),获得自我关注的注意值:
[0027][0028]
进一步的是,建立自我项目在序列每个位置的输出嵌入是之前步骤中嵌入的加权和,其中权重是归一化的注意值获得自我关注的注意值为:
[0029][0030]
其中,a
jt
表示从第j个项目到第t个项目的注意力值。
[0031]
进一步的是,由于每个项都表示为具有均值和协方差的随机嵌入,因此均值和协方差的聚合,采用高斯分布的线性组合特性,计算公式为:
[0032][0033]
其中并且k≤t;
[0034]
输出结果和共同形成新生成序列的随机嵌入,将历史序列信号与不确定性意识聚合在一起。
[0035]
进一步的是,两个具有elu激活的点式完全连接层,在学习随机嵌入时引入非线性:
[0036][0037][0038]
其中以及表示学习参数;
[0039]
采用剩余连接、层规范化和脱落层,层输出为:
[0040][0041][0042]
如果堆叠更多层,z
μ
和z
σ
作为下一个wasserstein自我注意层的输入。
[0043]
进一步的是,根据输出嵌入预测下一项,包括步骤:
[0044]
在序列的第t个位置的项目s
t
,计算第t+1位置上的下一个项目j的预测分数,表示为两个项目和的2-wasserstein距离:
[0045][0046]
其中和是给定序列(s1,s2,
…
,s
t
)的表示,1≤t≤n;)的表示,1≤t≤n;和是输入随机嵌入表m
μ
和m
σ
的的嵌入索引;
[0047]
按升序排列分数来生成排名前n的推荐列表。
[0048]
进一步的是,正则化项来增强此类距离,计算方法为:
[0049][0050]
其中[x]
+
=max(x,0)是标准损失,j
+
代表下一个损失,j-是从用户从不与之交互的项目中随机抽取的负面项目,l
pun
(t,j
+
,j-)代表的是是正项和负项之间的距离;表示预测距离左右的值,表示从st到j+的距离;
[0051]
大于预测距离否则,如果则违反直觉,则违反直觉,揭示了阳性项目j
+
与负项j-接近;
[0052]
将此校正损失作为正则化项与bpr损失合并到最终损失中:
[0053][0054]
其中,表示距离集合,σ表示标准差,β表示权重,λ表示权重;
[0055]
使用adam优化器最小化l并优化所有可学习的参数θ;在理想情况下,第二项λl(s
t
,j
+
,j-)变为0,也就是说s
t
与j
+
接近,但是s
t
与j
+
远离j-。
[0056]
采用本技术方案的有益效果:
[0057]
本发明提出了一种新的随机自我注意序列模型,用于建模动态不确定性和捕获协作传递性。还引入了一种新的bpr损失正则化方法,保证了正负采样项之间的较大距离。数据集的大量结果和定性分析证明了模型的有效性,也很好地支持了模型在缓解冷启动项目推荐问题方面的优势。
[0058]
本发明中分布表示有助于扩展项目的潜在交互空间,以更好地理解不确定性和灵活性。
[0059]
本发明对协作传递性的考虑有助于发现和归纳项目传递中固有的协作信号。
[0060]
本发明新引入的损失带来了一个额外的约束,它将积极项目和消极项目之间的距离限制为不大于积极项目之间的距离。wasserstein自我注意的优越性,为顺序推荐建模不确定性信息和协作传递性的必要性提供了保证。
[0061]
本发明不确定性信息在用户建模和冷启动项目问题缓解中有效。序列长度最短的组拥有最多的用户,并且随着序列长度的变长,用户的大小会减小。与短序列相比,模型在最大序列长度间隔内实现了最显著的用户改进。
附图说明
[0062]
图1为本发明的一种序列推荐方法流程示意图.
具体实施方式
[0063]
为了使本发明的目的、技术方案和优点更加清楚,下面结合附图对本发明作进一步阐述。
[0064]
在本实施例中,参见图1所示,本发明提出了一种序列推荐方法,包括步骤
[0065]
s10,进入随机嵌入层,将项目表示为分布,将不确定性引入到项目嵌入中,获得随机嵌入;
[0066]
s20,进入wasserstein自我注意层,建立自适应随机嵌入的自我注意变体;
[0067]
s30,进入前馈网络和层输出,前馈网络采用两个具有elu激活的点式完全连接层,在学习随机嵌入时引入非线性;采用层输出包括剩余连接、层规范化和脱落层;
[0068]
s40,进入预测层,根据输出嵌入预测下一项,获得预测排名;
[0069]
s50,采用正则化项来增强正样本项和负样本项之间的距离,正负bpr损失作为基准损失来衡量排名预测误差;
[0070]
s60,采用排名做推荐。
[0071]
作为上述实施例的优化方案,在步骤s10中,进入随机嵌入层,将项目表示为分布,将不确定性引入到项目嵌入中,获得随机嵌入;具体的:
[0072]
使用多维椭圆高斯分布来表示项目,椭圆高斯分布由平均向量和协方差向量控制,其中协方差引入项目的潜在不确定性;
[0073]
对于所有项目,定义一个平均嵌入表m
μ
和协方差嵌入表m
σ
;
[0074]
由于均值和协方差识别不同的信号,为均值和协方差引入单独的位置嵌入p
μ
和p
σ
,获得用户的均值和协方差序列嵌入,计算公式为:
[0075][0076]
随机嵌入表示为d-维椭圆高斯分布其中并且并且
[0077]
作为上述实施例的优化方案,用随机嵌入建模序列动力学仍然存在挑战。首先,在仍然满足三角形不等式的情况下,用分布对项目转移的动力学建模仍然存在问题。其次,这些序列信号的聚合以获得序列的表示仍然没有得到解决。为了应对这两个挑战,引入了wasserstein距离作为注意权重来衡量序列中项目之间的成对关系,并且我们还采用高斯分布的线性组合特性来聚合历史项目并获得序列表示。
[0078]
在步骤s20中,进入wasserstein自我注意层,建立自适应随机嵌入的自我注意变体;具体的:
[0079]
在wasserstein自我注意层建立自适应随机嵌入的自我注意变体时:
[0080]
表示作为自我关注的价值观,分别获取项目sk和项目s
t
的随机嵌入;
[0081]
采用wasserstein距离来测量两个项目的随机嵌入之间的距离,计算a
kt
表示项目sk和项目s
t
之间的注意值,k≤t,包括:
[0082]
对于两个项目sk和s
t
,相应的随机嵌入是和
[0083]
其中:
[0084][0085]
其中,分别表示对应的项目的不同距离值,σ表示协方差距离,μ表示平均值距离,k表示项目sk中第k个项目,t表示项目s
t
中第t个项目;
[0086]
将注意力权重定义为2-wasserstein距离w2(
·
,
·
),获得自我关注的注意值:
[0087][0088]
使用wasserstein距离有几个优点。首先,wasserstein距离测量分布之间的距离,能够测量具有不确定性信息的项目的相异性。其次,wasserstein距离满足三角形不等式,可以归纳地捕捉序列建模中的协同传递性。最后,wasserstein距离还具有更稳定的训练过程的优势,因为当两个分布不重叠时,它提供了更平滑的测量值,这在sr中意味着两个项目彼此远离。然而,kl发散将产生无穷远的距离,导致数值不稳定。与传统的自我关注相比,公
式可以通过批量矩阵乘法计算,而不会牺牲计算和空间效率。建立自我项目在序列每个位置的输出嵌入是之前步骤中嵌入的加权和,其中权重是归一化的注意值获得自我关注的注意值为:
[0089][0090]
其中,a
jt
表示:从第j个项目到第t个项目的注意力值。
[0091]
由于每个项都表示为具有均值和协方差的随机嵌入,因此均值和协方差的聚合,采用高斯分布的线性组合特性,计算公式为:
[0092][0093]
其中并且k≤t;
[0094]
输出结果和共同形成新生成序列的随机嵌入,将历史序列信号与不确定性意识聚合在一起。
[0095]
作为上述实施例的优化方案,在步骤s30中,进入前馈网络和层输出,前馈网络采用两个具有elu激活的点式完全连接层,在学习随机嵌入时引入非线性;采用层输出包括剩余连接、层规范化和脱落层;具体的:
[0096]
两个具有elu激活的点式完全连接层,在学习随机嵌入时引入非线性:
[0097][0098][0099]
其中以及表示学习参数;
[0100]
采用剩余连接、层规范化和脱落层,层输出为:
[0101][0102][0103]
为了保证协方差的正定性,在协方差嵌入中采用了elu激活和加1。
[0104]
如果堆叠更多层,z
μ
和z
σ
作为下一个wasserstein自我注意层的输入。
[0105]
作为上述实施例的优化方案,在步骤s40中,进入预测层,根据输出嵌入预测下一项,包括步骤:
[0106]
在序列的第t个位置的项目s
t
,计算第t+1位置上的下一个项目j的预测分数,表示为两个项目和的2-wasserstein距离:
[0107][0108]
其中和是给定序列(s1,s2,
…
,s
t
)的表示,1≤t≤n;)的表示,1≤t≤n;和是输入随机嵌入表m
μ
和m
σ
的的嵌入索引;
[0109]
对于评估,与点积法不同,距离分数越小,表示下一个项目的概率越高。因此,通过按升序排列分数来生成排名前n的推荐列表。
[0110]
作为上述实施例的优化方案,在步骤s50中,正则化项来增强此类距离,计算方法为:
[0111][0112]
其中[x]
+
=max(x,0)是标准损失,j
+
代表下一个损失,j-是从用户从不与之交互的项目中随机抽取的负面项目,l
pun
(t,j
+
,j-)代表的是是正项和负项之间的距离;表示预测距离左右的值,表示从st到j+的距离;
[0113]
大于预测距离否则,如果则违反直觉,则违反直觉,揭示了阳性项目j
+
与负项j-接近;
[0114]
将此校正损失作为正则化项与bpr损失合并到最终损失中:
[0115][0116]
其中,表示距离集合,σ表示标准差,β表示权重,λ表示权重;
[0117]
使用adam优化器最小化l并优化所有可学习的参数θ;在理想情况下,第二项λl(s
t
,j
+
,j-)变为0,也就是说s
t
与j
+
接近,但是s
t
与j
+
远离j-。
[0118]
以上显示和描述了本发明的基本原理和主要特征和本发明的优点。本行业的技术人员应该了解,本发明不受上述实施例的限制,上述实施例和说明书中描述的只是说明本发明的原理,在不脱离本发明精神和范围的前提下,本发明还会有各种变化和改进,这些变化和改进都落入要求保护的本发明范围内。本发明要求保护范围由所附的权利要求书及其等效物界定。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1