一种基于视频的微表情识别方法、装置及存储介质与流程
本发明涉及信息处理,并且更具体地,涉及一种基于视频的微表情识别方法、装置及存储介质。
背景技术:
1、随着互联网技术的不断发展,金融产品也开始提供线上销售的渠道,以便于人们进行购买。在销售过程中,可以对录制的销售过程视频使用微表情识别技术,分析客户在视频中企图抑制的真实情绪,实现对客户的情绪识别以规避销售过程中的风险。
2、现有的微表情识别算法需要完成特征提取和表情识别两个任务。其中,“特征提取”是指在一段经过合适的预处理方法的视频图像序列中,通过各种特征提取方式检测并提取其中的微表情,例如,基于光流的特征提取或者基于lbp-top算子(即时空局部纹理算子)的特征提取。而“表情识别”实际上是一个分类任务。亦即,将提取获得的微表情分到预先设定的类别中,从而最终确定每个微表情具体对应的含义。例如,高兴、悲伤、惊讶、生气、厌恶、害怕等等。
3、现有的表情识别方法是通过cnn(卷积神经网络)来实现的。其首先利用训练数据集对构建好的cnn模型进行训练。然后通过训练好的cnn模型进行分类和识别。但是,现有使用cnn进行识别和分类时,cnn无法利用视频图像序列在时域上的相关信息(cnn的特征输入层中,每个特征之间的相互关系没有体现,输入层的神经元是等效的)。亦即,cnn只能对视频图像信息中的单个图像帧进行识别而无法学习到相邻图像帧之间的变化或者关联。而微表情是客户在一段较短时间内,面部局部区域呈现的运动。时域上的相关信息也是识别和区分微表情非常重要的部分。因此,忽略时域上的相关信息会导致cnn对微表情识别性能的下降。
4、现有公开号为:cn111738160a的专利申请,使用预训练好的权重层,独立提取每帧图片的特征,然后根据相似性分出集合,然后在集合内归一化相似度,根据得到结合权重值的图像特征向量,再输入到卷积神经网络或者直接输入到softmax进行表情分类。这种方法虽然考虑到了时域上的相关信息,但是实际处理时,提取特征的时候都是单帧独立提取的,在特征提取时没有充分的考虑到时域的影响,精度不高。
5、因此,需要一种基于视频的微表情识别的方法。
技术实现思路
1、本发明要解决的问题包括如何高效准确地基于视频帧数据进行微表情的识别。
2、为了解决上述诸如如何高效准确地基于视频帧数据进行微表情的识别的技术问题,提出了本发明。本发明的实施例提供了一种基于视频的微表情识别方法、装置及存储介质。
3、根据本发明实施例的另一个方面,提供了一种基于视频的微表情识别方法,所述方法包括:
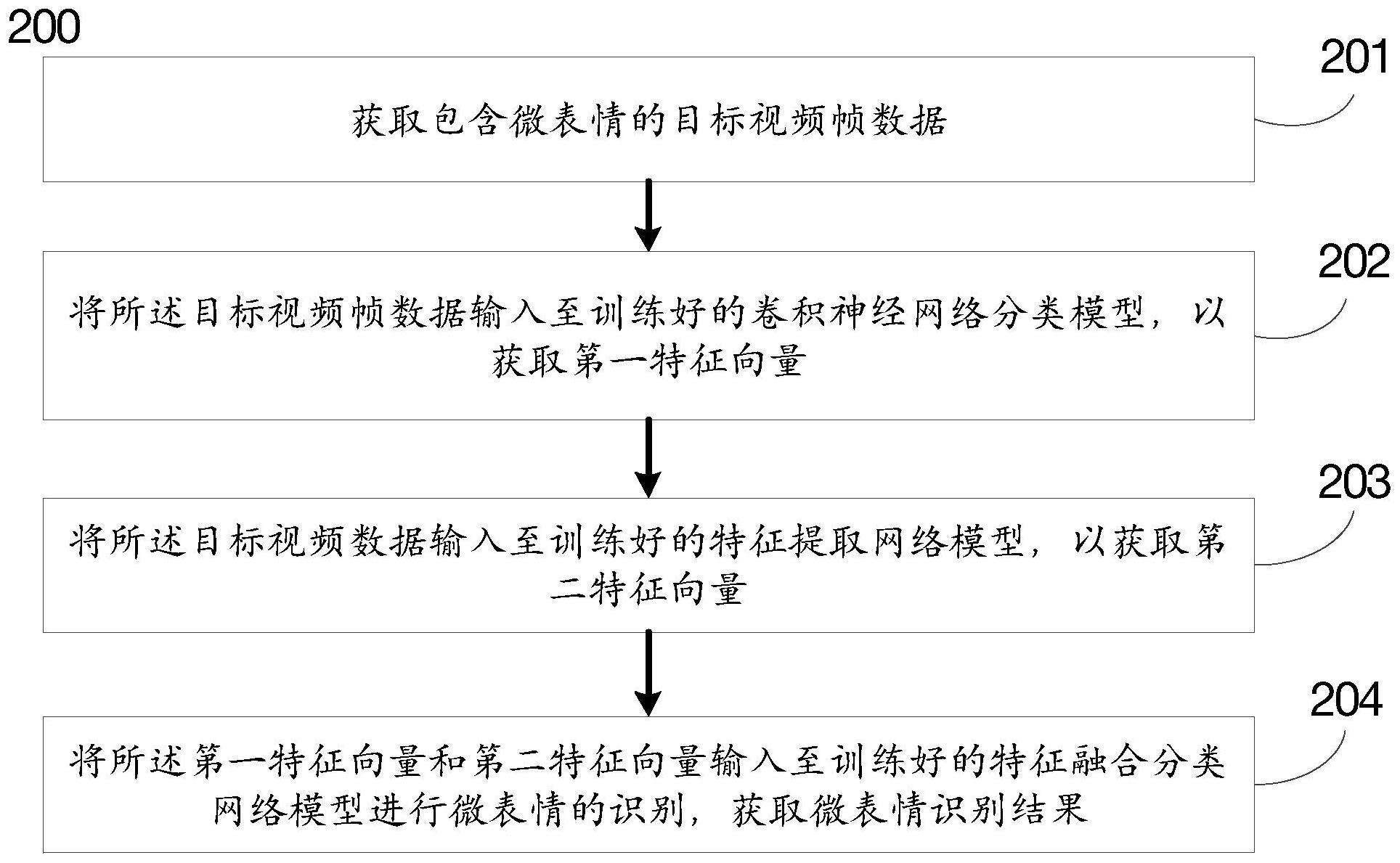
4、获取包含微表情的目标视频帧数据;
5、将所述目标视频帧数据输入至训练好的卷积神经网络分类模型,以获取第一特征向量;
6、将所述目标视频数据输入至训练好的特征提取网络模型,以获取第二特征向量;
7、将所述第一特征向量和第二特征向量输入至训练好的特征融合分类网络模型进行微表情的识别,获取微表情识别结果。
8、可选地,其中所述方法还包括:
9、对所述目标视频帧数据按照预设步长进行采样,并将采样后的视频帧数据输入至训练好的卷积神经网络分类模型。
10、可选地,其中所述预设步长n的取值范围为[1,8]。
11、可选地,其中所述方法还包括:
12、获取标注好表情类别的微表情视频帧样本数据和标注好表情类别的宏表情视频帧样本数据;
13、按照预设步长对所述微表情视频帧样本数据和宏表情视频帧样本数据进行采样,以获取第一样本数据集;
14、基于所述第一样本数据集对初始的卷积神经网络分类模型进行训练,并使用表情类别作为标签,使用交叉熵损失函数优化模型,以获取训练好的卷积神经网络分类模型;
15、其中,所述卷积神经网络分类模型包括:依次连接的输入层、卷积神经网络层、展平层、全连接层和softmax分类层;卷积神经网络层的输出为特征向量;所述卷积神经网络层包括多个3d卷积层。
16、可选地,其中所述方法还包括:
17、获取标注好表情类别的微表情视频帧样本数据和标注好表情类别的宏表情视频帧样本数据;
18、对所述微表情视频帧样本数据和宏表情视频帧样本数据进行面部编码系统facs标注,以获取第二样本数据集;
19、基于所述第二样本数据集对初始的特征提取网络模型进行训练,以获取训练好的特征提取网络模型;
20、其中,特征提取网络模型包括:输入层、编码层和transformer解码层。
21、可选地,其中所述将所述第一特征向量和第二特征向量输入至训练好的特征融合分类网络模型进行微表情的识别,获取微表情识别结果,包括:
22、对第二特征向量进行展平和全连接操作,将第二特征向量的特征维度降维至和第一特征向量的特征维度相同,以获取降维后的第二特征向量;
23、将所述第一特征向量和降维后的第二特征向量进行特征拼接,获取拼接特征;
24、将所述拼接特征输入至全连接层,再基于softmax分类层进行微表情的分类识别,获取微表情识别结果。
25、可选地,其中所述方法还包括:
26、确定卷积神经网络分类模型和特征提取网络模型所占的权重;
27、将微表情视频帧样本数据输入至训练好的卷积神经网络分类模型,以获取第三特征向量;
28、将微表情视频帧样本数据输入至的特征提取网络模型,以获取第四特征向量;
29、基于所述第三特征和第四特征对初始的特征融合分类网络模型进行训练,以获取训练好的特征融合分类网络模型;
30、其中,所述特征融合分类网络模型,包括:依次连接的第一输入层、第一特征输出层、特征拼接层、第一全连接层和softmax分类层,以及依次连接的第二输入层、第二特征输出层、展平层和第二全连接层,所述第二全连接层与所述特征拼接层相连接;所述第一特征输出层包括:卷积神经网络分类模型中的卷积神经网络层、展平层和全连接层。
31、根据本发明实施例的另一个方面,还提供了一种存储介质,存储介质包括存储的程序,其中,在程序运行时由处理器执行以上所述的方法。
32、根据本发明实施例的又一个方面,提供了一种基于视频的微表情识别装置,所述装置包括:
33、数据获取模块,用于获取包含微表情的目标视频帧数据;
34、第一特征向量获取模块,用于将所述目标视频帧数据输入至训练好的卷积神经网络分类模型,以获取第一特征向量;
35、第二特征向量获取模块,用于将所述目标视频数据输入至训练好的特征提取网络模型,以获取第二特征向量;
36、识别模块,用于将所述第一特征向量和第二特征向量输入至训练好的特征融合分类网络模型进行微表情的识别,获取微表情识别结果。
37、根据本发明实施例的又一个方面,提供了一种基于视频的微表情识别装置,所述装置包括:
38、处理器;以及
39、存储器,与所述处理器连接,用于为所述处理器提供处理以下处理步骤的指令:
40、获取包含微表情的目标视频帧数据;
41、将所述目标视频帧数据输入至训练好的卷积神经网络分类模型,以获取第一特征向量;
42、将所述目标视频数据输入至训练好的特征提取网络模型,以获取第二特征向量;
43、将所述第一特征向量和第二特征向量输入至训练好的特征融合分类网络模型进行微表情的识别,获取微表情识别结果。本发明实施例提供了一种基于视频的微表情识别方法、装置及存储介质,可以获取包含微表情的目标视频帧数据;将所述目标视频帧数据输入至训练好的卷积神经网络分类模型,以获取第一特征向量;将所述目标视频数据输入至训练好的特征提取网络模型,以获取第二特征向量;将所述第一特征向量和第二特征向量输入至训练好的特征融合分类网络模型进行微表情的识别,获取微表情识别结果。本发明采用cnn与transformer模型结合的方式,兼顾了空间语义和时域语义信息,为了兼顾效率,对偏向提取空间语义信息能力的cnn模型采用高分辨,低帧率的数据输入,对于transformer模型采用低分辨率,高帧率的数据输入,基于本发明可以高效准确地进行微表情识别,且能够应用于不同的应用场景。
44、下面通过附图和实施例,对本发明的技术方案做进一步的详细描述。
- 还没有人留言评论。精彩留言会获得点赞!