不需要硬件复位的执行软件在处理组件之间的灵活迁移的制作方法
本文的技术涉及集成电路设计,并且更具体地,涉及解决与包括但不限于图形处理单元(gpu)的复杂芯片中的制造缺陷有关的问题。所述技术进一步涉及定义虚拟gpu处理集群,所述虚拟gpu处理集群是逻辑或物理电路的抽象,用于提供不同结构化的芯片之间的兼容性;gpu处理集群及其处理组件之间的灵活迁移;考虑跨集成电路基板的底层清除(floorswept)/禁用/非功能与全功能硬件的平衡;以及允许硬件在不需要时被选择性地关闭的动态处理资源禁用。
背景技术:
1、总体gpu集成电路或芯片设计目标是提供最大性能和最大芯片制造产量。较大芯片具有较多电路,从而实现较高性能。但是由于制造缺陷的较高可能性,所以较大的芯片往往具有较低的产量,因为芯片上制造缺陷的数量大致与芯片面积成比例。
2、由于在制造复杂芯片(诸如gpu芯片)中所需的高容差,特定制造芯片的一些电路或操作有缺陷并不罕见。有时,缺陷对于芯片的运行是如此的重要,使得芯片需要被报废。然而,由于现代gpu芯片被设计为大规模并行,因此在许多情况下,缺陷仅影响并行功能块中的一者或一些,使得其他并行功能块完全可操作。
3、一种用于增加半导体制造产量的技术被称为“底层清除(floorsweeping)”。为了克服较大芯片上降低的产量,可以关闭、禁用或制作不可访问的有缺陷的电路,制作全功能芯片,但与无缺陷的芯片相比,具有较少的总功能电路。因此,“底层清除”是一种工艺或技术,通过该工艺或技术,存在于集成电路中的制造缺陷或其他错误可以被禁用和/或绕过或以其他方式变得不可访问(例如,诸如通过熔断保险丝来打开内部布线),从而使得集成电路维持其所设计的功能中的一些或全部。每个芯片还可以包括片上可编程底层清除电路,该片上可编程底层清除电路能够响应于由芯片测试/编程设备外部施加的命令而在该芯片上实现底层清除。这种底层清除可以使得诸如gpu或cpu之类的集成电路能够维持一致的操作,尽管存在一个或更多个制造缺陷。参见例如us20150149713a1。偶尔地,为了跨多个芯片的一致性,还使用底层清除来永久地禁用超能力芯片的不需要的全功能部分,例如以降低功耗和发热。这在现有技术中有时完成,使得给定库存单位(“sku”)产品标志符中的所有芯片具有相同数量的可访问/操作的tpc。
4、图1示出了在半导体晶圆或基板上制造的示例gpu芯片管芯。芯片管芯包括真正地数十亿的电路,这些电路一起工作以传递高性能计算和3d图形。从图1中可以得到芯片设计复杂程度如何的想法。例如,所示出的此特定芯片包括8个图形处理集群(gpc),每gpc具有8个tpc(tpc=纹理处理集群)、每个tpc具有2个sm(sm=流式多处理器)、每个gpc具有16个sm、每个全gpu具有128个sm、每个sm具有64个fp32 cuda核心、每个全gpu具有8192个fp32cuda核心、每个sm具有4个张量核心、每个全gpu具有512个张量核心、6个hbm2堆栈、以及在628.4mm2的管芯大小上包括超过280亿个晶体管的十二个512位存储器控制器。在此特定芯片中,两个sm一起包括纹理处理器集群或tpc。这些tpc中的八个(并且因此这些sm中的十六个)包括被称为gpu处理集群(“gpc”)的较高级别块,并且这些gpc中的八个组成全gpu。还存在八个多实例gpu或mig切片,其可独立地用作用于桌面基础设施的虚拟推理引擎和虚拟gpu。例如,参见:
5、https://docs.nvidia.com/pdf/ampere_tuning_guide.pdf;
6、https://developer.nvidia.com/blog/nvidia-ampere-architecture-in-depth/;
7、nvidia a100张量核心gpu架构v1.0(nvidia 2020);以及图29。
8、制造缺陷统计上可能发生在这种复杂性的管芯上。如果所发现的具有任何缺陷的任何芯片都被丢弃,则大多数芯片将被丢弃并且产量将非常低。例如,具有称为纹理处理集群或“tpc”的72个物理并行处理块的gpu设计将具有非常低的产量,如果该部分(part)的运输产品sku要求所有72个tpc是有功能的话。然而,就像“十三个(baker’s dozen)”多于12个,只是在一些烘焙物品重量不足的情况下,假设芯片的产品sku假定4个tpc是有缺陷的。然后,具有68个或更多个工作tpc的芯片可被包括在产品sku中。这意味着具有72、71、70、69或68个良好tpc的芯片可作为68-tpc gpu在产品sku下销售。
9、一些芯片制造商常规地具有来自一个芯片设计的多个产品sku,其中,产品sku具有不同数量的功能电路块。例如,在很多情况下,每个gpu芯片家族具有多个物理上不同的芯片设计,主要通过gpc和tpc的数量区分。对于每个芯片设计,制造商可以在产量(更多的底层清除意味着更高的产量)和性能(更多的底层清除意味着更低的性能)之间进行权衡。通常,尤其对于大型芯片,制造商对于给定的芯片设计可以具有多个sku,其中,它们具有基本上不同的底层清除,从而使得性能差异不是细微的。由此,存在以特定产品sku指定的所有芯片被要求具有一致的能力配置文件的重要场景。
10、特别地,如上所述,图1中示出的芯片被组织为具有某数量的gpc,每个gpc具有某数量的tpc,每个tpc具有某数量的sm处理器核心布置。例如,假设图1的物理芯片布局被设计成具有8个gpc,其中每个gpc具有9个tpc。然后,在4个tpc例如由于有缺陷而被关闭的情况下,产品sku可具有每个具有8个tpc的4个gpc和每个具有9个tpc的4个gpc。这种“配置”的示例命名是8/8/8/8/9/9/9/9。在这种命名法中,gpc从最少的tpc排序(sort)到最多的tpc。在排序之后,gpc被从0至7编号为逻辑gpc。特别地,tpc可以具有物理tpc id(例如,如布局在gpc基底上的物理tpc的连续编号)以及逻辑tpc id(例如,在确定上述配置之后在gpc内分配给tpc的连续编号)。逻辑tpc id编号可以遵循统一模式,例如,对于每个gpc中的第一操作tpc,它可以从0开始。
11、对于要包括在产品sku中的芯片,哪些gpc具有8个tpc并不重要,因为在示例gpu设计中启动时间逻辑gpc编号过程可以通过指派逻辑gpc id来将物理gpc从最少到最多tpc排序。由此,即使不同的物理tpc在不同的芯片中可能已经失效,这些差异也可以通过以下方式使用逻辑tpc id和/或逻辑gpc id来隐藏以提供跨产品sku的一致性:(a)将sku标准化成使用少于最大数目的物理tpc,(b)对这些部分(parts)进行测试和装仓(binning),使得具有太多失效的tpc的各部分将不被包括在sku中,以及(c)在上电/重启时动态地分配逻辑gpc id。这样的一致性例如当gpu在高性能计算(hpc)和云计算中的使用需要将上下文从一个gpu迁移到另一gpu时是有用的,因为迁移通常需要在同一产品sku中的gpu之间匹配配置文件。
12、图2a、图2b、图2c以图形方式示出了被设计和制造为具有8个逻辑gpc(标记为0-7)的gpu的三种不同配置,每个gpc具有9个tpc。在该图中,每个配置中的每个单元表示tpc。x轴用如以上所讨论的“逻辑”gpc id标记,并且在每个逻辑gpc id上方的竖直列中的块反映了每个gpc中的tpc的数目。该图还示出了那些tpc中的一些不佳。具体地,以暗交叉线示出的这些块是“死的”并且不能用于处理。
13、作为示例,图2a、图2b、图2c中所示的三个gpu配置中的每一个具有68个全功能tpc,其中4个失效的(failed)tpc以交叉线示出。可能存在这样的规则,即,具有多于4个失效的tpc的任何芯片不能被包括在特定产品sku中。然后,所示出的三个示例配置之间的差异是如何跨芯片的gpc分布失效的tpc。在左手的配置中,gpc 0、1、2和3各自具有一个单个失效的tpc(8/8/8/8/9/9/9/9)-即,失效的tpc是分布式的,因此没有gpc具有多于一个失效的tpc。然而,由于制造缺陷基本上随机地发生,所以许多其他分布是可能的。例如,在右手的配置中,gpc0具有三个失效的tpc并且gpc1具有单个失效的tpc(6/8/9/9/9/9/9/9)。在中间的配置中,gpc0具有两个失效的tpc,并且gpc1和gpc2各自具有一个失效的tpc(7/8/8/9/9/9/9/9)。还有可能在两个gpc的每一个中都具有两个失效的tpc,并且在同一gpc中具有四个失效的tpc。注意,因为这些图反映逻辑gpc id,所以对它们进行预先排序,所以失效的tpc全部出现在图的左侧,但是如果我们看物理gpc id,失效的tpc可以在芯片上的任何地方。
14、目标是使这三个不同的芯片在软件和人类程序员而言看起来是“相同的”,即使它们在内部是相当不同的。这种布置的一个标准是看每个gpc内失效的tpc的数目。可以制定对于特定产品sku是可接受的规则,gpc可以具有不超过一个失效的tpc。在这种配置文件匹配策略下,具有7/8/8/9/9/9/9/9(图2b)的配置的芯片不能被包括在具有8/8/8/8/9/9/9/9/9(图2a)的产品sku中,即使功能tpc的总数匹配,因为每gpc配置文件的tpc不匹配。也就是说,逻辑gpc在它们的tpc计数中不是一对一匹配的。具体地,具有8/8/8/8/9/9/9/9的产品sku将需要每个gpc具有至少8个功能tpc,所以具有7/8/8/9/9/9/9/9的配置的芯片将不符合该要求。
15、但不允许7/8/8/9/9/9/9/9芯片被包括在产品sku中可以大大降低可用产量。丢弃具有68个全功能tpc的7/8/8/9/9/9/9/9芯片,仅仅是因为恰好不同地分布的四个非功能tpc潜在地是相当浪费的。随着更多硬件单元有缺陷,该问题变得更加严重——例如,图2c示出了再次具有68个全功能tpc的cpu芯片的6/8/9/9/9/9/9/9配置,但是这次其gpc之一仅具有6个全功能tpc。或考虑诸如5/9/9/9/9/9/9/9/9之类的示例,一旦其再次具有68个全功能tpc,但是其中所有四个失效的tpc都在同一gpc中。
16、当然,可以创建若干不同的产品sku,并且取决于每gpc有多少tpc失效,将芯片“装仓”到那些不同的sku中。这就像从农民市场上从“秒(seconds)”仓购买苹果或西红柿——消费者可能为能力较低的芯片支付较少的费用。但是,产品sku的激增常常不是该问题的解决方案,因为它引起消费者混淆和后勤复杂化,并且还因为针对现代gpu编写的应用程序在要求各种上下文中的某一最小程度的并行性和性能方面比以往要求更高。具体来说,虽然能力较低的gpu芯片的市场可能有限,但许多应用程序现在需要将执行软件从数据中心中的一个芯片迁移到另一芯片的能力。因此需要更好的解决方案。
17、示例硬件背景
18、通过进一步的信息,图3和图4示出了现代gpu可以提供各种不同的硬件分区和层级。在这些示例中,gpu内的sm本身可分组成较大的功能单元。例如,gpu的图形处理集群(gpc)可包括多个纹理处理集群(tpc)(其中每一者可包括一个或更多个sm)和sm的附加阵列(例如,为了计算能力)以及其他支持硬件,例如用于实时光线追踪加速的光线追踪单元。
19、图3示出了被分区成多个gpu处理集群(“gpc”)的gpu硬件,每个gpu处理集群包括多个纹理处理集群(“tpc”),每个纹理处理集群包括一个或更多个(例如,两个)流式多处理器(sm),每个流式多处理器进而可以包括多个处理核心。gpc还可以包括未指派给tpc的另外的sm群。图4为示出gpc 208的阵列230如何由i/o单元205、主机接口206、前端212、可包括计算工作分配器(cwd)的任务/工作单元207、交叉开关210以及存储器接口分区单元215和关联的片上存储器220支持的框图。图4还示出了整个系统可以包括任意数量的这种多gpc处理单元202和经由内存桥105耦接到主机cpu的关联的存储器204。
20、每个sm又可被分区成多个独立的处理块,每个处理块具有一个或若干不同种类的核心(例如,fp32、int32、张量等)、线程束调度器、分派单元和本地寄存器文件,如图5中所反映的。图5的现代sm的示例架构图包括高级计算硬件能力,该高级计算硬件能力包括许多并行数学核心,诸如除了纹理处理单元之外还包括多个张量核心。例如,截至目前,2017nvidia volta gv100 sm被分区成四个处理块,每个具有16个fp32核心、8个fp64核心、16个int32核心、用于深度学习矩阵算术的两个混合精度张量核心、l0指令高速缓存、一个线程束调度器、一个分派单元和64kb寄存器文件——并且将来的gpu设计可能继续该趋势。这种增加的计算并行性使得能够显著减少计算处理时间。如上所讨论的,每个tpc可包括一个或更多个sm。例如,在一个实施例中,每个tpc包括一对sm,但其他实施例可具有不同的布置。
21、图5a和图5b示出了一些gpu实现方式(例如,nvidia ampere)可以如何启用作为“微gpu”(诸如μgpu0和μgpu1)操作的多个分区,其中,每个微gpu包括整个gpu的处理资源的一部分。当gpu被分区为两个或更多个单独的更小的μgpu以供不同客户端访问时,资源(包括物理存储器设备165,诸如本地l2高速缓存存储器)通常也被分区。例如,在一种设计中,耦合到μgpu0的第一半物理存储器设备165可以对应于第一组存储器分区位置,并且耦合到μgpu1的第二半物理存储器设备165可以对应于第二组存储器分区位置。gpu内的性能资源还根据该两个或更多个单独的较小处理器分区来分区。资源可包括二级高速缓存(l2)资源170和处理资源160。
22、此外,存在多实例gpu(“mig”)特征(其与“微gpu”不同),该特征允许将gpu安全地分区成用于cudatm(“计算统一设备架构”)应用的许多单独的gpu实例,从而为多个用户提供单独的gpu资源以加速其相应的应用。例如,mig在gpc边界上将gpu分成n个分区,典型地每分区8、4、2或1个gpc。对于具有多租户用例的云服务提供商(csp),除了为客户提供增强的隔离之外,mig确保一个客户端不能影响其他客户端的工作或调度。使用mig,每个实例的处理器具有穿过整个存储器系统的独立且隔离的路径——片上交叉开关端口、l2高速缓存库、存储器控制器和dram地址总线全部被唯一地指派给个体实例。这确保个体用户的工作负载能够以可预测的吞吐量和延迟、以相同的l2高速缓存分配和dram带宽来运行,即使其他任务正在颠簸(thrash)其自己的高速缓存或使其dram接口饱和。mig可以对可用的gpu计算资源(包括流式多处理器或sm,以及诸如复制引擎或解码器之类的gpu引擎)进行分区,以便为诸如vm、容器或进程之类的不同客户端提供具有故障隔离的定义的服务质量(qos)。mig因此使得多个gpu实例能够在单个物理gpu上并行运行。参见例如https://youtu.be/lw_ywppmpsq;
23、https://www.nvidia.com/en-us/technologies/multi-instance-gpu/;以及
24、https://docs.nvidia.com/datacenter/tesla/mig-user-guide/;以及图29。
25、图5c示出了多线程软件被组织为能够在不同硬件分区上并发运行的协作线程组或cta。例如,每个cta可以在不同的sm上运行,其中cta的所有线程并发地在同一sm上运行。然而,在现有设计中,程序员希望同时启动的不同cta可在不同时间在不同sm上结束运行。类似地,上述mig特征使得相同或不同用户的不同程序能够在非干扰的基础上在相同的gpu硬件上同时运行。
26、关于此类现有gpu硬件架构和布置的更多信息,参见例如usp8,112,614;usp7,506,134;usp7,836,118;usp7,788,468;us10909033;us20140122809;林霍尔姆等人,“nvidia tesla:统一图形和计算架构(nvidia tesla:a unified graphics andcomputing architecture)”,ieee micro(2008);
27、https://docs.nvidia.com/cuda/parallel-thread-execution/index.html(2021检索的);肖凯特等人,“volta:性能和可编程性(volta:performance andprogrammability)”,ieee micro(38卷,第2期,2018年3/4月),doi:10.1109/mm.2018.022071134。
28、迁移挑战
29、企业越来越多地转向基于云的解决方案。例如,基于云的解决方案提供支持来自任何地方的新工作正常的企业所需的灵活性和简化的管理。随着nvidia gpu和软件的云采用,可能性是无限的。现代工作负载(包括人工智能(ai)、高性能计算(hpc)、数据科学和图形工作站)可以利用物理系统的性能从云得到支持。
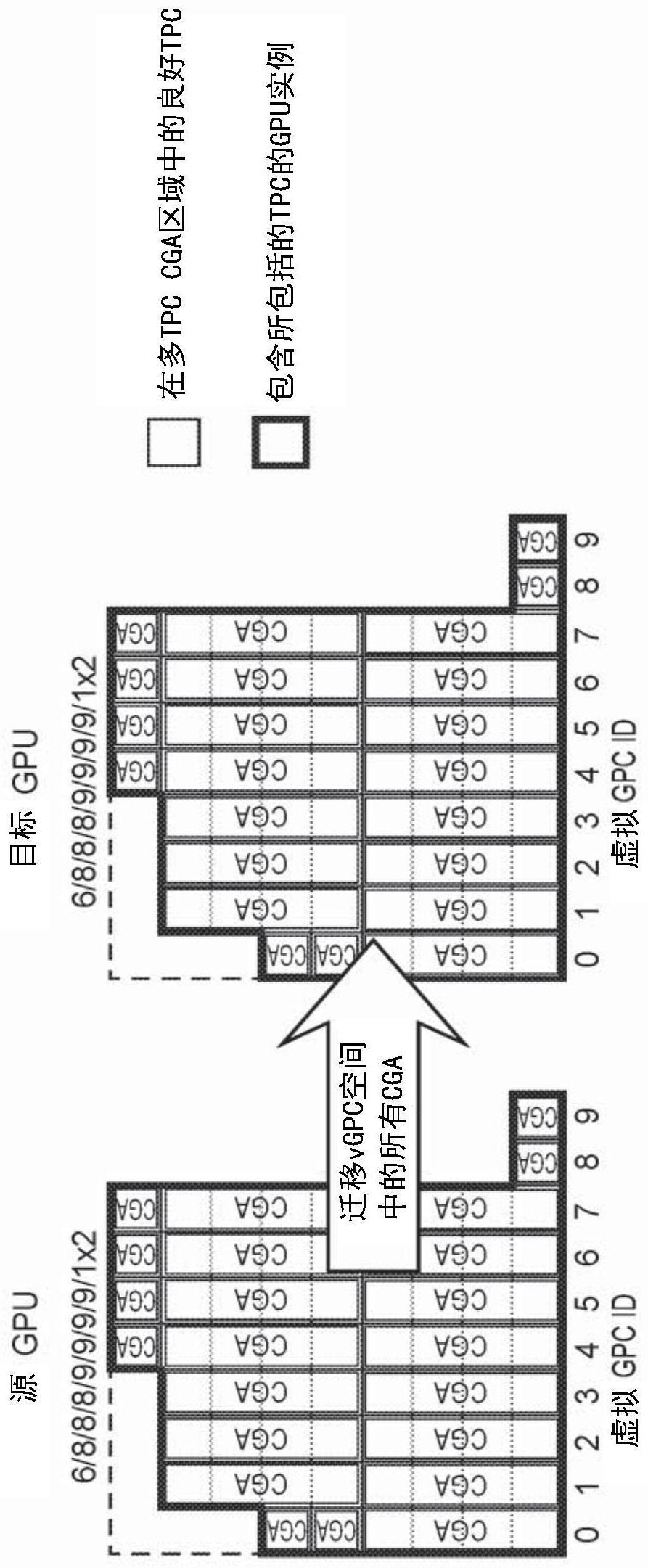
30、高性能计算(hpc)云安装经常利用计算资源的虚拟化。在由nvidia虚拟gpu供电的虚拟化环境中,nvidia虚拟gpu(vgpu)软件与管理程序(hypervisor)一起被安装在虚拟化层处。该软件创建使得每个虚拟机(vm)共享安装在服务器上的物理gpu的虚拟gpu。对于要求更高的工作流,单个vm可利用多个物理gpu的功率。例如,安装可以包括许多节点,其中每个节点可以包括若干cpu和若干gpu。每个节点可支持多个虚拟机(vm),其中每个vm运行其自己的操作系统(os)的实例。这种gpu共享依赖于vdi软件来提供抽象层,该抽象层使客户端应用程序表现得好像它拥有它自己的物理、专用gpu,而服务器的gpu(和驱动程序)可以认为它正在响应一个主要主机。在服务器上运行的vdi管理程序拦截api调用并转换命令、绘制上下文和进程特定的地址空间,然后沿着传递到图形驱动器。软件可包括用于每个vm的图形或计算驱动器。由于在现有的基于云的解决方案中通常由cpu完成的工作现在被卸载到gpu,所以用户具有更好的体验。参见例如,埃雷拉,“nvidia网格:具有工作站的视觉性能的图形加速的vdi(nvidia grid:graphics accelerated vdi with the visualperformance of a workstation)(nvidia 2014年5月);us20150067672;us20150009222;以及李石等人,“vcuda:gpu加速的虚拟机高性能计算(vcuda:gpu-accelerated high-performance computing in virtual machines),”计算机上的ieee事务,第61卷,第6号,第804-816页,2012年6月,doi:10.1109/tc.2011.112。
31、hpc安装应当能够将vm从安装的一部分迁移到另一部分。例如,当节点被取下用于维护时,该节点上的所有vm被迁移到不同的节点。作为另一示例,整个机架可被断电,但仅在所有活动的vm已被迁移到不同机架之后。在迁移时,在迁移vm上运行的程序被抢先从一个或更多个cpu和一个或更多个gpu、存储器映像和上下文保存缓冲区移动到hpc安装中的不同位置,在此处vm可以再次开始运行。
32、在更基本的层面上,一些形式的迁移涉及取得在一个gpu芯片上运行的所有工作并且将其移动到另一个gpu芯片。这种类型的迁移通常需要跨源gpu芯片和目标gpu芯片的每gpc的tpc的统一配置文件。但是在云中,可能有几百甚至几千个gpu芯片,其可构成目标gpu芯片。这就是为什么在一些实施例中,在整个gpu产品sku上希望每gpc配置文件的tpc的统一性。以此方式,统一性将跨具有相同sku的任何gpu芯片而存在。
33、之前,为了允许vm在gpu之间迁移,要求每gpc的tpc的配置文件在产品sku中的所有芯片上是一致的。例如,如果芯片布局具有8个gpc,其中每个gpc具有9个tpc,其中4个tpc由于有缺陷而关闭,则产品sku可以具有每个具有8个tpc的4个gpc和每个具有9个tpc的4个gpc。我们的这种“配置”的命名法是8/8/8/8/9/9/9/9。注意,在该命名法中,gpc被从最少的tpc排序到最多的tpc。在排序之后,gpc被从0至7编号为逻辑gpc。对于要包括在产品sku中的芯片,哪些gpc具有8个tpc无关紧要,因为启动时间逻辑gpc编号过程可以通过指派逻辑gpc id来将物理gpc从最少到最多tpc排序。然而,在之前的设计中,具有7/8/8/9/9/9/9的配置的芯片不能被包括在具有8/8/8/8/9/9/9/9的产品sku中,即使tpc的总数匹配,因为每gpc配置文件的tpc不匹配。也就是说,逻辑gpc在它们的tpc计数中不是一对一匹配的。每gpc配置文件的相同tpc使得迁移成为可能,因为在迁移源处的gpc上的被抢占的程序具有与迁移目的地处的gpc的一对一的tpc对应关系。因此,在过去,要求同一产品sku中的gpu具有相同的每gpc配置文件的tpc。在过去,为了包括7/8/8/9/9/9/9/9和8/8/8/8/9/9/9/9芯片两者(两者均具有68个总tpc),有必要将两个芯片降级至每gpc配置文件的“最差”公共tpc,即7/8/8/8/9/9/9/9(具有67个总tpc)。随着更多的硬件单元由于有缺陷而被关闭,该问题变得更加恶化。
34、使用以上引用的mig特征,gpu实例被要求允许迁移,正如全gpu具有对迁移的要求一样。例如,具有配置7/9的2-gpc gpu实例需要迁移到具有配置8/8的2-gpc gpu实例或从具有配置8/8的2-gpc gpu实例迁移。这是迁移的另一示例,除了它应用于gpu实例而不是全gpu之外。
35、对于mig,在将gpu划分为gpu实例时出现附加的复杂性。例如,当6/7/8/9/9/9/9/9gpu(总共66个tpc)被分成各自具有16个tpc的四个2-gpc gpu实例时,正在使用的tpc的数目从66个tpc减少到64个tpc。在现有设计中,改变正在使用的tpc的数目意味着进行完全复位。如果gpu当时没有运行任何东西(例如,在gpu实例上不存在vm),则完全复位是可能的,但是当节点中存在多个gpu时,则整个节点很可能需要被复位。这潜在地是必须解决的大问题。此外,如果gpu已经被划分成两个4-gpc gpu实例,并且这两个gpu实例中的第二个不再使用,那么第二个gpu实例可以被进一步分成两个2-gpc gpu实例。然而,如果正在使用的tpc的总数需要改变,则存在问题,因为完全复位将破坏在两个4-gpc gpu实例中的第一个上运行的工作。
36、对于mig存在附加问题:有时需要重新打包gpu实例。实质上,这是在一个gpu内的迁移。例如,如果gpu被划分为四个2-gpc gpu实例,则编号为0(使用gpc 0和1)、1(使用gpc2和3)、2(使用gpc 4和5)和3(使用gpc 6和7),以供四个vm使用。然后,关闭使用gpu实例1和3的vm,使0和2仍然运行。然后,系统管理员想要创建4-gpc gpu实例,这应该是可能的,因为4个gpc未被使用。因此,需要进一步的改进。
技术实现思路
- 还没有人留言评论。精彩留言会获得点赞!