一种检测合约升级的兼容性的方法和装置与流程
1.本说明书实施例属于区块链技术领域,尤其涉及一种检测合约升级的兼容性的方法和装置。
背景技术:
2.区块链(blockchain)是分布式数据存储、点对点传输、共识机制、加密算法等计算机技术的新型应用模式。区块链系统中按照时间顺序将数据区块以顺序相连的方式组合成链式数据结构,并以密码学方式保证的不可篡改和不可伪造的分布式账本。由于区块链具有去中心化、信息不可篡改、自治性等特性,区块链也受到人们越来越多的重视和应用。
技术实现要素:
3.本发明的目的在于提供一种检测合约升级的兼容性的方法和装置,包括:
4.一种检测合约升级的兼容性的方法,包括:
5.生成升级前后合约的抽象语法树;
6.解析生成的抽象语法树,顺序提取每个抽象语法树的节点信息中的基础信息;
7.比较升级前后的抽象语法树的节点信息中的基础信息,得到兼容性结论。
8.一种合约升级的兼容性的检测装置,包括:
9.抽象语法树生成单元,用于生成升级前后合约的抽象语法树;
10.提取单元,用于解析生成的抽象语法树,并顺序提取每个抽象语法树的节点信息中的基础信息;
11.比较单元,用于比较升级前后的抽象语法树的节点信息中的基础信息,得到兼容性结论。
12.一种客户端,包括:
13.处理器,
14.存储器,存储有程序,其中在所述处理器执行所述程序时,执行上述方法。
15.升级的合约写法需要满足一定的规范才能使得升级前后兼容,即升级后的新合约中的状态,需要保持能够读取旧合约中相同状态的值的能力。用户在编写升级的合约时,往往忽略这些规范,从而导致升级后的合约出现数据丢失、错乱等严重问题。通过上述例子,可以实现基于抽象语法树的solidity等类型的合约升级存储数据兼容性检测方案。
附图说明
16.为了更清楚地说明本说明书实施例的技术方案,下面将对实施例描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本说明书中记载的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动性的前提下,还可以根据这些附图获得其他的附图。
17.图1是一实施例中部署智能合约的示意图;
18.图2是一实施例中调用智能合约的示意图;
19.图3是一实施例中区块存储结构的示意图;
20.图4是一实施例中区块存储结构的示意图;
21.图5是一实施例中mpt树的示意图;
22.图6是一实施例中交易处理过程中涉及的模块及cpu、内存和磁盘关系的示意图;
23.图7是一实施例中交易处理过程中涉及的evm虚拟机模块的示意图;
24.图8是一实施例中slot结构的示意图;
25.图9是一实施例中slot结构的示意图;
26.图10是一实施例中检测合约升级的兼容性的方法的流程图;
27.图11是一实施例中slot结构的示意图;
28.图12是一实施例中slot结构的示意图。
具体实施方式
29.为了使本技术领域的人员更好地理解本说明书中的技术方案,下面将结合本说明书实施例中的附图,对本说明书实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本说明书一部分实施例,而不是全部的实施例。基于本说明书中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都应当属于本说明书保护的范围。
30.区块链一般被划分为三种类型:公有链(public blockchain),私有链(private blockchain)和联盟链(consortium blockchain)。此外,还有多种类型的结合,比如私有链+联盟链、联盟链+公有链等不同组合形式。其中去中心化程度最高的是公有链。加入公有链的参与者可以读取链上的数据记录、参与交易以及竞争新区块的记账权等。而且,各参与者(体现为参与者在区块链上的节点)可自由加入以及退出网络,并进行相关操作。私有链则相反,该网络的写入权限由某个组织或者机构控制,数据读取权限受组织规定。简单来说,私有链可以为一个弱中心化系统,参与节点具有严格限制且少。这种类型的区块链更适合于特定机构内部使用。联盟链则是介于公有链以及私有链之间的区块链,可实现“部分去中心化”。联盟链中各个节点通常有与之相对应的实体机构或者组织;参与者通过授权加入网络并组成利益相关联盟,共同维护区块链运行。
31.不论是公有链、私有链还是联盟链,除了可以支持账户间转移区块链上的原生资产,还可以提供智能合约的功能。区块链上的智能合约是在区块链系统上可以被交易触发执行的合约。智能合约可以通过代码的形式定义。
32.智能合约支持用户在区块链网络中创建并调用一些复杂的逻辑,这是可编程的区块链区别于原有区块链技术的最大挑战。作为一个可编程区块链的核心是虚拟机(evm),每个区块链节点都可以运行evm。evm是一个图灵完备的虚拟机,这意味着可以通过它实现各种复杂的逻辑。用户在区块链中发布和调用智能合约就是在evm上运行的。实际上,虚拟机直接运行的是虚拟机代码(虚拟机字节码,下简称“字节码”)。部署在区块链上的智能合约可以是字节码的形式。
33.例如图1所示,bob将一个包含创建智能合约信息的交易发送到区块链网络后,节点1的evm可以执行这个交易并生成对应的合约实例。图1中的“0x6f8ae93
…”
代表了这个合
约的地址,交易的data字段保存的可以是字节码,交易的to字段为一个空的账户。节点间通过共识机制达成一致后,这个合约成功创建,后续用户可以调用这个合约。
34.合约创建后,区块链上出现一个与该智能合约对应的合约账户,并拥有一个特定的地址,合约代码和账户存储将保存在该合约账户中。智能合约的行为由合约代码控制,而智能合约的账户存储则保存了合约的状态。换句话说,智能合约使得区块链上产生包含合约代码和账户存储(storage)的虚拟账户。
35.前述提到,包含创建智能合约的交易的data字段保存的可以是该智能合约的字节码。字节码由一连串的字节组成,每一字节可以标识一个操作。基于开发效率、可读性等多方面考虑,开发者可以不直接书写字节码,而是选择一门高级语言编写智能合约代码。高级语言编写的智能合约代码,经过编译器编译,生成字节码,进而该字节码可以部署到区块链上。区块链支持的高级语言很多,如solidity、serpent、lll语言等。
36.以solidity语言为例,用其编写的合约与面向对象编程语言中的类(class)很相似,在一个合约中可以声明多种成员,包括状态变量、函数、函数修改器、事件等。状态变量是存储在智能合约的账户存储中的值,用于保存合约的状态。
37.如下是以solidity语言编写的一个简单的智能合约的代码示例1:
[0038][0039][0040]
代码示例1.simplestorage代码
[0041]
上述代码示例1中,第2行声明了字符型(string)的状态变量storeddata,第3行声明了事件(event),该事件存储的内容是调用该合约的发起者地址和字符串s。第4-7行定义了set函数,入参是字符串s。该set函数执行的操作包括将入参设置到状态变量storeddata,产生一个事件,该事件的内容包括调用该合约的发起者地址和字符串s。
[0042]
如前所述,状态变量最终将存储在数据库中。生成的事件,一般是如下形式:
[0043]
[topic1][topic2]...[topicn][data]
[0044]
这里,第一个topic,即topic1一般是默认值,例如是回执的标识,可以是对事件名称、事件参数类型等顺序拼接后取的hash值。topic2~topicn,每一个topic是否存在,取决于定义参数时是否加入了indexed修饰,有则这个参数的值将是回执中的一个topic,而不加indexed修饰的一般会放入data中。上面代码示例1中的例子,第3行声明event时,两个参
数address from和s,都没有indexed修饰,一般会放入data中。第6行的代码,通过stored()事件设定了事件中的data内容[msg.sender,s]。这样,对于第6行操作的事件,整体上形式为:
[0045]
[topic1:事件标识][data:msg.sender,s]
[0046]
第8-10行定义了get函数。该函数的操作包括返回查询的storeddata的值。returns(string)表示返回值的类型,constant修饰符标识该函数不能对合约中的状态变量的值进行修改。
[0047]
此外,如图2所示,bob将一个包含调用智能合约信息的交易发送到区块链网络后,节点1的evm可以执行这个交易并生成对应的合约实例。图2中交易的from字段是发起调用智能合约的账户的地址,to字段中的“0x6f8ae93
…”
代表了被调用的智能合约的地址,交易的data字段保存的调用智能合约的方法和参数。此外,还可以包括value字段,用以表示该交易中以太币的值。调用智能合约后,storeddata的值可能改变。后续,某个客户端可以通过某一区块链节点(例如图2中的节点6)查看storeddata的当前值。
[0048]
智能合约可以以规定的方式在区块链网络中每个节点独立的执行,所有执行记录和数据都保存在区块链上,所以当这样的交易完成后,区块链上就保存了无法篡改、不会丢失的交易凭证。
[0049]
如前所述,上述示例中的storeddata即是状态变量,其存储在智能合约的账户存储中。引入智能合约的各种区块链网络中,通常账户可以包括两种类型:
[0050]
合约账户(contract account):存储执行的智能合约代码以及智能合约代码中状态的值,通常只能通过外部账户调用激活;
[0051]
外部账户(externally owned account):用户的账户,例如以太币拥有者账户。
[0052]
外部账户和合约账户的设计,实际上是账户地址到账户状态的映射。账户的状态通常包括nonce、balance、storage root、codehash等字段。nonce、balance在外部账户和合约账户中都存在。codehash和storage root属性一般仅在合约账户上有效。
[0053]
nonce:计数器。对于外部账户,这个数字可以代表从账户地址发送的交易数量;对于合约账户,可以是账户创建的合约数量。
[0054]
balance:这个地址拥有的以太币的数量。
[0055]
storage root:一个mpt树根节点的哈希,这个mpt树对合约账户的状态变量的存储进行组织。
[0056]
codehash:智能合约代码的哈希值。对于合约账户,这是智能合约的哈希值;对于外部账户,由于不包括智能合约,因此codehash字段一般可以是空字符串/全0字符串。
[0057]
mpt全称为merkle patricia tree,是结合了merkle tree(默克尔树)和patricia tree(压缩前缀树,一种更节省空间的trie树,字典树)的一种树形结构。merkle tree,默克尔树算法对每个交易都计算一个hash值,然后两两连接再次计算hash,一直到最顶层的merkle根。一些区块链网络中采用改进的mpt树,例如是16叉树的结构,通常也简称为mpt树。
[0058]
mpt树的数据结构包括状态树(state trie)。状态树中包含区块链网络中每个账户所对应的存储内容的键值对(key and value pair,也写作key-value,简称k-v或kv)。状态树中的“键”(key)可以是一个的160bits的标识符(例如区块链账户的地址或地址的hash
值的一部分,下面统称为账户地址),这个账户地址分布于从状态树的根节点开始到叶子节点的存储中。状态树中的“值”是通过对区块链账户的信息进行编码(使用递归长度字典编码(recursive-length prefix encoding,rlp)方法)生成的。如前所述,对于外部账户来说,值包括nonce和balance;对于合约账户来说,值包括nonce、balance、codehash和storageroot。
[0059]
合约账户用于存储智能合约相关的状态。智能合约在区块链上完成部署后,会产生一个对应的合约账户。这个合约账户一般会具有一些状态,这些状态由智能合约中状态变量所定义并在智能合约执行时产生新的值。所述的智能合约通常是指在区块链环境中以代码形式定义的能够自动执行条款的合约。一旦某个事件触发合约中的条款(满足执行条件),代码即可以自动执行。在区块链中,合约的相关状态保存在storage trie中,storage trie根节点的hash值即存储于上述storageroot中,从而将该合约的所有状态通过hash锁定到该合约账户下。storage trie也是一个mpt树形结构,存储了状态地址到状态值的key-value映射。从storage trie树的根节点到叶子节点中的部分信息顺序排布后用以存储一个状态的地址,该叶子节点中存储状态的值。
[0060]
如图3所示的一些区块链数据存储中,每一区块的区块头包括若干字段,例如上一区块哈希previous_hash(图中的prev hash),随机数nonce(在一些区块链系统中这个nonce不是随机数,或者在一些区块链系统中不启用区块头中的nonce),时间戳timestamp,区块号block num,状态根哈希state_root,交易根哈希transaction_root,收据根哈希receipt_root等。其中,下一区块(如区块n+1)的区块头中的prev hash指向上一区块(如区块n),即为上一区块的hash值。通过这种方式,区块链上通过区块头实现了下一区块对上一区块的锁定。其中,state_root、transaction_root和receipt_root分别锁定了状态集合、交易集合和收据集合。状态集合、交易集合和收据集合分别以树的形式组织了状态、交易和收据。一般的,可以是相同的树形结构,也可以是不同的树形结构。例如在上述采用mpt结构的区块链网络中,采用了相同的mpt结构。在一些包括智能合约的状态集合的树形结构中,包括两级的mpt结构:上一级的mpt结构的叶子节点包括外部账户和合约账户两种类型;其中的每个合约账户包括下一级的mpt结构,下一级的叶子节点中包括合约账户中的状态的值。
[0061]
图4是一个区块链数据存储的结构示意图。可以结合图3所示,state_root是当前区块中所有账户的状态组成的mpt树的根的哈希值,即指向state_root的为一颗mpt形式的状态树state trie。这个mpt树的根节点一般为一个扩展节点(extension node)或一个分支节点(branch node),state_root中存储的一般为这个根节点的hash值。根节点可以与下面一层或多层的extension node/branch node相连,这些多层的树节点可以统称为中间节点(internal node)。从这个mpt的根节点到叶子节点中每个节点中的一部分值按照顺序串联起来可以构成账户地址并作为key,叶子节点中存储的账户信息为这个账户地址对应的value,这样,构成了key-value键值对。这个key也可以是sha3(address)后取一部分,即账户地址的hash值(hash算法例如采用sha3算法)的一部分,其存储的值value可以为rlp(account),即账户信息的rlp编码。其中账户信息是[nonce,balance,storageroot,codehash]构成的四元组。如前所述,对于外部账户来说,一般只有nonce和balance两项,而storageroot、codehash字段默认存储空字符串/全0字符串。也就是说,外部账户不存储合
约,也不存储合约执行后的产生的状态变量。合约账户一般包括nonce,balance,storage root,codehash。其中nonce是该合约账户的交易计数器;balance是账户余额;storage root对应另外一个mpt,通过storage root能链接到合约相关的状态的信息;codehash是合约代码的hash值。不论是外部账户还是合约账户,其账户信息一般都位于一个单独的叶子节点(leaf node)中。从根节点的extension node/branch node到每个账户的leaf node,可能中间会经过若干个分支节点以及扩展节点。
[0062]
state trie可以是mpt形式的树,一般是16叉树,即每一层最多可以有16个孩子节点。对于extension node,用于存储共同前缀,其一般有1个孩子节点,这个孩子节点可以是branch node。对于branch node,其最多可以有16个孩子节点,其中可能包括extension node和/或leaf node。
[0063]
其中,对于state trie中的一个合约账户来说,其storage_root指向另一颗同为mpt形式的树,其中存储了合约执行涉及的状态变量(state variable)的数据。这个storage_root指向的mpt形式的树为storage trie,即storage trie的根节点的hash值。一般的,这个storage trie树存储的也是key-value键值对。key表明状态变量的地址,其取值可以是合约中的状态变量声明的位置(从0开始计数的值)经过一定规则处理后得到的结果,例如是sha3(状态变量声明的位置),或者是sha3(合约名称+状态变量声明的位置)。value用于存储状态变量的取值(例如是经rlp编码的值)。从根节点经中间节点到叶子节点的路径上存储的一部分数据连起来构成key,叶子节点中存储value。前面提到,这个storage trie也可以是mpt形式的树,一般也是16叉树,即对于branch node,其最多可以有16个孩子节点,这些孩子节点可能包括extension node和/或leaf node。而对于extension node,其一般可以有1个孩子节点,这个孩子节点可以是branch node或leaf node。
[0064]
例如图4中的state trie的leaf node account p,该账户是一个合约账户,其storage root锁定了该合约存储中的所有状态。这些状态组织为mpt树,树形结构如该storage root链接的storage trie。这个链接的storage trie中,以leaf node state variable n为例,例如为前述合约代码示例的storeddata的值,则其key为sha3(storeddata的声明位置,后面将详述),其value值为s(为了简洁,这里省略了对value的编码格式,例如是rlp,后续类似,不再赘述)。其中,key的值顺序的分布于storage trie的根节点到叶子节点(即leaf node variable n)中。
[0065]
再例如,图4中的state trie中的leaf node account c,该账户是一个外部账户,其key为sha3(address c),即账号c的地址的hash值(hash算法例如采用sha3算法),其存储的值value可以为(account),其中账户信息account是[nonce,balance]构成的二元组。如前所述,由于account c为外部账户,因此其账户信息是nonce和balance两项(这里省略了codehash和storage root,以下类似)。例如一个外部账户,其nonce为20,balance为4550,则leaf node state variable c这个叶子节点中即存储nonce=20,balance=4550。而account c的地址为key,其值顺序的分布于state trie的根节点到叶子节点(即leaf node variable c)中。
[0066]
这些状态,包括外部账户的k-v和合约账户的k-v,最终存储于数据库中。数据库中的存储,并不是直接存储这些账户的状态,即不是直接存储这些账户的k-v,而是存储每个树节点本身的k-v值。
[0067]
如图5的示例中所示,上一级的mpt结构中,对于叶子节点a1,通过根节点a8(extension node)中shared nibble的a7—中间节点a7(branch node)的槽位1—叶子节点a1中key-end的1335,顺序组合起来构成该叶子节点的key,即为a711335,在该叶子节点中存储balance=45.0eth,nonce=n1。对于叶子节点a2,通过根节点a8(extension node)中shared nibble的a7—中间节点a7(branch node)的槽位7—节点a6(extension node)中shared nibbles的d3—中间节点a5(branch node)中的槽位3-叶子节点a2中key-end的7,顺序组合起来构成该叶子节点的key,即为a77d337,在该叶子节点中存储balance=1.00wei,nonce=n2。对于叶子节点a3,通过根节点a8(extension node)中shared nibble的a7—中间节点a7(branch node)的槽位f—叶子节点a3中key-end的9365,顺序组合起来构成该叶子节点的key,即为a7f9365,在该叶子节点中存储balance=1.1eth,nonce=n3。对于叶子节点a4,通过根节点a8(extension node)中shared nibble的a7—中间节点a7(branch node)的槽位7—节点a6(extension node)中shared nibbles的d3—中间节点a5(branch node)中的槽位9-叶子节点a4中key-end的7,顺序组合起来构成该叶子节点的key,即为a77d397,在该叶子节点中存储balance=0.12eth,nonce=n4,codehash=c1,storage root=s1。s1可以为h(a10),即下一层树的根节点a10的hash至。其中,a1、a2和a3的叶子节点中存储的是外部账户的信息,a4的叶子节点中存储的是合约账户的信息。对于合约账户,其包含下一级mpt,构成storage trie,用于存储该合约账户中的状态变量。
[0068]
如图5的示例中所示,下一级的mpt结构中,对于叶子节点a11,通过根节点a10(branch node)中的槽位3—叶子节点a11中key-end的35b2e4,顺序组合起来构成该叶子节点的key,即为335b2e4,在该叶子节点中存储“张三_a=20”,例如表示在合约中定义的a类型数字资产归属于张三的份额为20,即张三的a类资产的余额为20。对于叶子节点a12,通过根节点a10(branch node)中的槽位7—叶子节点a12中key-end的c25988,顺序组合起来构成该叶子节点的key,即为7c25988,在该叶子节点中存储“李四_b=20”,例如表示在合约中定义的b类型数字资产归属于李四的份额为50,即李四的b类资产的余额为50。对于叶子节点a15,通过根节点a10(branch node)中的槽位f—中间节点a13(extension node)中shared nibble的a—中间节点a14(branch node)的槽位6—叶子节点a15中key-end的be33,顺序组合起来构成该叶子节点的key,即为fa6be33,在该叶子节点中存储“storeddata=s”。对于叶子节点a16,通过根节点a10(branch node)中的槽位f—中间节点a13(extension node)中shared nibble的a—中间节点a14(branch node)的槽位9—叶子节点a16中key-end的9365,顺序组合起来构成该叶子节点的key,即为fa99365,在该叶子节点中存储“王五_a=35”,例如表示在合约中定义的a类型数字资产归属于王五的份额为35,即王五的a类资产的余额为35。
[0069]
上述mpt树的节点构成中,用前缀prefix表示树节点类型,例如0表示包含偶数个shared nibbles(共享的半字节)的extension node,用1表示包含奇数个shared nibble(s)的extension node,用2表示包含偶数个nibbles的leaf node,用3表示包含奇数个nibble(s)的leaf node。
[0070]
上述节点构成中,下一个树节点的整体内容的hash值,填入上一个树节点的对应位置中。数据库中,实际上存储每个树节点的key-value的映射,其中value包括这个树节点中存储的内容,对应的key是这个树节点整体内容的hash值。这样,数据库中实际存储的树
节点k-v如下表:
[0071][0072][0073]
表1、数据库中实际存储的树节点k-v
[0074]
上表1中,用h()表示hash计算。这样,下一个树节点的hash值锚定在了上一个树节点中。通过这样的层层hash,得到整颗state trie树的根hash,并将该根hash锁定到了区块头的state root字段中。
[0075]
在一些区块链系统中,区块链平台的代码可以包括p2p(peer to peer,点对点)模块,共识(consensus)模块,执行模块和存储模块。p2p是一种计算机网络的组成方式,与常见的web网络不同,p2p是分散的、去中心化的。p2p模块可以完成数据的分布式传播。对于区块链节点来说,通过p2p模块可以以点对点的方式传播和接收数据。不同参与方通过部署的
节点(node)可以建立一个分布式的区块链网络。利用链式区块结构构造的账本,保存于分布式的区块链网络中的每个节点(或大多节点上,如共识节点)上,这也称为去中心化(或称为多中心化)的分布式账本。这样的区块链系统需要解决去中心化(或多中心化)的多个节点上各自的账本数据的一致性和正确性的问题。每个节点上都运行着相同的区块链平台程序,在一定容错需求的设计下,通过共识模块可以保证所有忠诚节点具有相同的交易,从而保证所有忠诚节点对相同交易的执行结果一致,并将交易及执行结果打包生成区块。当前主流的共识机制包括:工作量证明(proof of work,pow)、股权证明(proof of stake,pos)、委任权益证明(delegated proof of stake,dpos)、实用拜占庭容错(practical byzantine fault tolerance,pbft)算法,蜜獾拜占庭容错(honeybadgerbft)算法等。共识过程中共识模块一般还可以生成当前交易集合对应的区块的时间戳等。执行模块可以执行交易,包括普通转账交易和涉及合约的交易,可以是在共识模块完成共识之前或之后。对于涉及合约的交易,执行模块可以引入虚拟机来执行智能合约的代码,如虚拟机(ethereum virtual machine,evm),从而通过evm屏蔽各个节点硬件配置和软件环境的差异性,以保证各个节点上执行智能合约的过程和结果是相同的,并通过沙箱环境避免智能合约的执行给主机上的区块链平台代码、其它程序或操作系统带来影响。对于联盟链的一种情形来说,节点之间通过共识模块可以确定一个交易集合中的交易内容和交易顺序,进而将共识结果的一个确定性的交易集合输出至执行模块。执行模块通过执行普通转账交易/涉及合约的交易,生成执行结果,并发送至存储模块。存储模块可以负责将执行结果存储至节点本地的持久化存储介质中。
[0076]
如图6所示的一个区块链节点中,物理上包括cpu、内存和磁盘等。这个区块链节点所执行的区块链平台代码中,可以包括p2p模块,共识模块,执行模块和存储模块。p2p模块、共识模块和执行模块的功能实现一般需要cpu、内存的参与。存储模块可以包括构建树模块,区块头生成模块,wal(write ahead log,写前日志)模块,状态数据库模块。其中,构建树模块用于基于执行模块传入的状态k-v构建树(例如是mpt树),如前述的state trie和storage trie,从而得到树节点的k-v,一般需要cpu、内存的参与。区块头生成模块用于根据构建树模块所构建的树的根节点和其它一些数据(如上一区块hash、时间戳、区块号等)生成区块头,一般需要cpu、内存的参与。wal模块用于构建树模块生成的树节点k-v写入状态数据库模块之前,持久化存储构建树模块生成的树节点k-v,以防止构建树模块生成的树节点k-v写入状态数据库模块的过程中由于断电等情形造成的数据丢失,并在发生这种情况时恢复数据,一般需要cpu、内存和磁盘的参与。状态数据库模块用于将构建树模块所构建的如表1中的树节点k-v存储在持久化存储设备上;由于最终会将树节点数据写入持久化存储介质(例如图中的磁盘),因此状态数据库模块除了cpu、内存外一般还需要磁盘的参与。
[0077]
从存储结构上来说,上述的merkle树结构,如上述的mpt、libra的smt(sparse merkle tree,稀疏默克尔树,类似mpt),以上述表1中的对应关系形式位于构建树模块中,并存储于内存中。其中,上层merkle树为前缀树(字典树),能够实现对数据的组织,并对组织后的数据得到唯一的merkle根。叶子节点可以保存状态value,根节点到中间节点到叶子节点实现对状态key的字典序索引。这些树节点按某种规则编码为key、其内容编码为value,最终存储于下层数据库中。数据库大多采用lsm(log-structured merge-tree,日志
结构的合并树)类结构的nosql key-value db(database,数据库;key-value db也简称为kvdb),位于状态数据库模块中,保存于磁盘。具体的,数据库例如是leveldb,libra的rocksdb。这两种kvdb都是基于lsm存储引擎。
[0078]
前述提到,创建智能合约的交易发送到区块链上,经过共识之后,区块链各节点可以执行这个交易。这时区块链上出现一个与该智能合约对应的合约账户(包括例如帐户的标识identity,合约的hash值codehash,合约存储的根storageroot),并拥有一个特定的地址,合约代码和账户存储可以保存在该合约账户的存储(storage)中,如图7所示。智能合约的行为由合约代码控制,而智能合约的账户存储则保存了合约的状态。换句话说,智能合约使得区块链上产生包含合约代码和账户存储(storage)的虚拟账户。对于合约部署交易或者合约更新交易,将产生或变更codehash的值。后续,区块链节点可以接收调用部署的智能合约的交易请求,该交易请求可以包括调用的合约的地址、调用的合约中的函数和输入的参数。一般的,该交易请求经过共识后,区块链各个节点可以各自独立执行指定调用的智能合约。
[0079]
图7左侧为一个采用solidity编写的智能合约及其经过编译和执行过程的示例。该智能合约经过编译器(compiler)编译(compile)后生成字节码(bytecode)。图中的solc是solidity的命令行编译器,通过solidity编写的智能合约可通过带参数的命令行工具solc进行编译,从而生成可以运行于evm的字节码。经过上述图1、图2中部署合约的过程,区块链上可以成功创建智能合约。部署合约后,区块链上生成一个与该智能合约对应的合约账户,该合约账户包括例如合约计数器nonce,账户的余额balance,合约字节码的hash值codehash,合约存储的根storageroot等。该合约在链上会具有一个特定的地址,即合约地址。
[0080]
这个合约地址,例如是根据部署合约的外部账户的地址和其计数器nonce一并做hash计算得到。具体,例如是sha3(rlp.encode([address_sender,nonce]))(rlp如前所述是一种编码格式,不同区块链中可以用其它编码格式替换,甚至不重新编码,因此后续省略rlp)。其中sha3是一类hash算法,例如经常采用的keccak256这样的算法。rlp如前所述表示一种编码格式,rlp.encode([address_sender,nonce])表示对圆括号中的内容进行rlp编码。圆括号中的[address_sender,nonce]表示对部署合约的外部账户的地址address_sender和其计数器nonce这两个字段做顺序拼接。例如采用keccak256算法,可以得到一个长度为256bits的hash值,根据这个hash值可以得到部署的合约在区块链上的地址(例如取前20字节)。256bits也就是32bytes。账户的余额balance在完成部署时可以设置为默认值0或。合约字节码的hash值codehash,可以由区块链平台通过对合约字节码进行hash计算得到。合约存储的根storageroot,可以是一个默认值,也可以是一个按照下层的storage trie的根节点计算得到的hash值。这个一般取决于部署的合约中是否会进行初始化操作,初始化操作例如执行合约中构造函数。如果部署的合约中包含了构造函数,一般会包括对一些最终将存储于底层数据库中的状态变量进行初始化的工作,这个初始化的工作可以在虚拟机执行。经过初始化后的状态变量,如前述内容所述,可以构建一颗mpt树,从而可以得到这颗mpt树的根节点,进而得到这个根节点的hash值。如果部署的合约中不包含构造函数,则可以不执行具体的函数,而是由区块链平台赋予storageroot一个默认值,例如是空内容的hash值。
[0081]
合约经过部署后,如前所述,后续可以被调用。如图2所示bob发起一个调用智能合约的交易到区块链网络后,合约执行,从而将状态变量设置为“hello”这个字符串。图2中类似的是alice发起调用合约的交易,从而通过合约的执行读取状态变量的值。
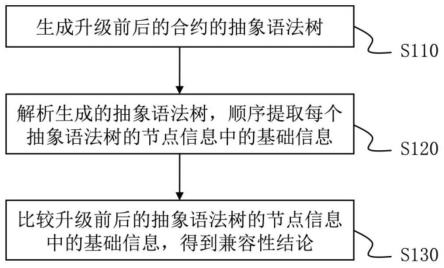
[0082]
前述也提到,智能合约通常在区块链环境中以代码形式定义了能够自动执行条款的合约。其中的条款通常与业务层面的逻辑有关。因此,整体上合约代码体现了业务逻辑。随着业务的发展和变化,业务逻辑可能发生改变,这时合约的代码也需要进行调整。此外,合约的代码可能存在漏洞,也需要修复,或者是编写合约的语言版本升级也会带来合约的升级要求。上述种种情况,通常需要对部署的合约进行升级。
[0083]
一种合约升级方式是部署新的合约,新的合约会具有一个不同于就合约的地址。具体的,如前所述,合约地址可以是根据部署合约的外部账户的地址和其计数器nonce一并做hash计算得到,例如是sha3([address_sender,nonce])。不同合约部署者部署的合约,合约地址是不同的;即使对于相同的合约部署者,由于其升级合约时发起了一笔新的交易,nonce作为交易计数器发生了改变,因此,新部署的合约的地址也会发生变化。这样,新的合约的存储也不同于旧的合约,新合约的合约存储中的状态变量,只能从部署了新的合约的区块开始设置和读取,而无法访问旧合约中的状态。
[0084]
在一些联盟链中,合约的升级,需要保障:
[0085]
第一,升级后的合约保持与升级前的合约是相同的合约地址。这样,在升级后才能保持与升级前相同的合约存储空间,历史数据才不会丢失,而且用户不必更改调用合约时输入的合约地址。
[0086]
第二,还需要保障升级前后的兼容性,即升级后的新合约中的状态,需要保持能够读取旧合约中相同状态的值的能力。
[0087]
上述第一点,合约账户地址的生成规则可以设定为与nonce无关,进一步的,可以设设定为与部署者无关。例如,可以由合约的名称来确定合约账户的地址,例如是sha3([name_contract])。这样可以保证只要是相同名字的合约,其在区块链上的地址就是相同的。前述提到,合约账户一般包括nonce,balance,storage root,codehash,其中,codehash是合约字节码的hash值。升级后的合约,字节码与升级前的字节码不同,因此,升级合约后合约账户中的codehash会发生改变,即合约升级后合约账户中的codehash一般也会更新。
[0088]
上述第二点,本质是同一个状态变量,比如状态变量r,如果在合约升级之后的key发生变化,则从升级合约的区块开始读取r的值,由于key发生改变,就无法正确读取升级合约前的r的值。
[0089]
例如以下代码示例2是升级前的旧合约的代码示例:
[0090]
[0091][0092]
代码示例2.demo1的solidity代码
[0093]
上述demo1代码中,在第3-4行分别声明了2个状态变量id、sex。这2个状态变量中:id是unit256类型,这种类型在solidity中为32个bytes;sex是bool类型,是1个bytes。这2变量如果在函数之前,则一般会作为持久化存储的状态变量,即会存储于底层数据库中。
[0094]
上述demo1代码中,在第6-8行定义了setid()函数。setid()函数后面的public作为修饰符,指明该setid()函数作为对内/对外的接口函数。setid()函数中有一个unit256类型的参数x。unit256表示256bits的无符号整数,长度是32bytes。在函数体内,将参数x的值赋值给id,从而实现对外提供的接口,将用户输入的参数x设定为状态变量id的值。在第10-12行定义了getid()函数。getid()函数后面的view表示该函数只能读取状态变量而不能修改状态变量。
[0095]
上述demo1代码中,在第14-16行和第18-20行分别定义了setsex()函数和getsex()函数,代码的含义与上述类似,不再赘述。
[0096]
上述demo1代码中,第22-24行定义了version()函数,该函数返回值是uint256类型。函数体中的操作是返回1。用户可以调用该函数,该函数返回当前合约的版本,这里版本是1。
[0097]
如前所述,需要持久化存储的状态变量,一般是一个成对的key-value结构。其中key表示该状态变量的地址,value表示该状态变量的取值。上述demo1的代码中,在头部声明了2个状态变量id、sex,每个状态变量将具有一个key。需要注意的是,这2个状态变量所占用的空间都是固定的,即32bytes和1bytes。
[0098]
每个合约一般都有自身的存储空间,这个存储空间是虚拟的,容量可以是一个非常大的数组,例如有2
256
个元素的数组,编号从0至2
256-1。每个元素可以是占用一定长度,例如是32bytes。每个元素这里称为插槽(slot),如图8所示。id、sex这2个状态变量的值,例如可以存储在第0、1这2个slot的位置中。需要说明的是,总计2
256
个slot的存储空间,是虚拟空间的总容量,也就是说,没有使用的slot并不会占用底层数据库的实际存储空间。
[0099]
如前所述,用solidity这类的高级语言编写的demo1合约,经过编译器编译后生成字节码。
[0100]
合约的执行,具体可以如图7所示。例如图2中的一个调用合约的交易发送至区块链网络中,并经过共识后,各个节点可以执行该交易。该交易的to字段表明被调用合约的地址。任一该节点可以根据合约的地址找到合约账户的存储,进而可以根据合约账户的存储中读取到codehash,从而根据codehash找到对应的合约字节码。节点可以将合约的字节码从存储载入虚拟机中。进而,由解释器(interpreter)解释执行,例如包括对调用的合约的字节码进行解析(parse,如解析push、add、sget、sstore、pop等),得到操作码(opcode)和函数,并将这些opcode存储到虚拟机开辟(图中的alloc;程序执行结束后对应释放内存操作,如图中free)的内存空间(memory)中,同时还得到调用的函数在内存空间中的跳转位置(jumpcode)。一般经过对执行合约所需要消耗的gas进行计算且gas足够后,跳转到memory的对应地址取得所调用函数的opcode并开始执行,将所调用到的函数的opcode所操作的数据进行计算(data computation)、推入/推出栈(stack)等的操作,从而完成数据计算。这个过程中,还可能需要一些合约的上下文(context)信息,例如区块号、调用合约的发起者的信息之类,这些信息可以从context中得到(get操作)。最后,将产生的状态通过调用存储接口以存入数据库存储(storage)中。需要说明的是,合约创建的过程中,也可能产生对合约中某些函数的执行执行,例如初始化操作的函数,这时也会解析代码、产生跳转指令,存入memory,对stack的操作等。
[0101]
通过上述过程,虚拟机加载并执行合约的字节码,可能产生状态和/或读取状态,从而需要对底层数据库进行访问。虚拟机需要方便的访问底层的kv数据库。访问kv数据库,一般可以采用类似指针的访问数据能力。例如,如果需要从kv数据库中读取一个key对应的value,那么在访问前需要知道这个数据的key。
[0102]
如前关于图5、图6及相应文字所描述,对于写操作,执行模块(包括其中的虚拟机)执行合约产生kv,对于读操作,执行模块(包括其中的虚拟机)执行合约产生k。这个k是执行模块或区块链平台产生的key,这里称为状态key。在构建树模块中需要将这个状态key构建到mpt树上,从而得到从mpt根节点-中间节点-叶子节点的一系列的树节点key。如果是读操作,则可以根据树节点key在状态数据库模块中查找对应的value。如果是写操作,则产生从mpt根节点-中间节点-叶子节点的一系列的树节点key-value,以追加(append)的方式将这些树节点kv写入状态数据库模块。
[0103]
在虚拟机执行合约字节码的过程中,对于相同的状态变量,其位置需要是固定的,
2fb1 a337 f43e。则采用拼接合约地址+slot位置后,
[0117]
(1)的状态key是:0x3321dcaf8911d3842e14a7a415be2fb1a337f43e0000000000000000000000000000000000000000000000000000000000000000
[0118]
(2)的状态key是:0x3321dcaf8911d3842e14a7a415be2fb1a337f43e0000000000000000000000000000000000000000000000000000000000000001
[0119]
这些产生的状态key-value,在存入底层数据库的过程中,如图6所示,可以由构建树模块将这些key转换到如图5所示的storage trie树上。然后,构建树模块按照树的结构将状态key-value中的value将构建到这颗mpt树的某个叶子节点中。需要说明的是,如前所述,状态key分拆分成若干小段,按照从storage trie树的根至叶子节点的方向存储在顺序存储在树节点中。至于每个树节点存储状态key的哪一段,取决于该状态key与树上其它状态key的共有前缀的情况。由该叶子节点向上经中间节点直到根节点,会引起一连串的hash值变化,构建树模块会构建这些树节点的kv。进而,构建树模块将这些发生变化的树节点kv,发送至状态数据库模块,最后由状态数据库模块存储到图6所示的状态数据库中。
[0120]
上述过程中,读写状态变量的slot是在编译环节即固定下来的,如前所述由合约地址和状态变量的slot位置确定。状态key可以是由合约地址和slot拼接得到的。这样,运行同一个合约,读写相同的状态变量会采用相同的slot,并对应固定的状态key。
[0121]
如前所述,一些区块链中进行合约升级,保持升级后的合约与升级前的合约是相同的合约地址。尽管如此,保障升级前后的兼容性,即升级后的新合约中的状态保持能够读取旧合约中相同状态的值的能力,仍然是具有一定挑战的。
[0122]
例如以下代码示例3是升级后的新合约的代码示例:
[0123]
[0124][0125]
代码示例3.demo2的solidity代码
[0126]
上述demo2的代码,相对于demo1来说,在demo2的第4行插入了新的状态变量age。这样,原来位于demo1中第4行的sex在demo2中顺序后移,变为了第5行。此外,demo2中在第15-17行和19-21行增加了新的状态变量相关的写、读函数,分别为setage()和getage()。
[0127]
新的demo2代码,仍然会由编译器编译得到字节码。编译过程中,类似的,编译器会对上述demo2中的id、age、sex这3个状态变量生成slot位置,分别是:
[0128]
0x0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000
[0129]
0x0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0001
[0130]
0x0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0002
[0131]
这样,在编译器编译得到的合约字节码中,可以分别用slot中的这3个位置来代替3个状态变量的标识,如上述3个256bits分别代替id、age、sex。经过编译后的合约字节码在加载进虚拟机并执行时,对于id的操作即是对0x000...00这个slot位置的操作,对于age的操作即是对0x000...01这个slot位置的操作,对于sex的操作即是对0x000...02这个slot位置的操作。
[0132]
可见,对于升级后的demo2代码第5行的sex,显然即是升级前demo1代码的第4行,两者是相同含义的状态变量。而上述这种升级方式,升级后对0x000...01这个slot位置的操作,变为了age的操作,与升级前的0x000...01这个slot位置上的sex显然不符。那么,如果执行升级后的合约字节码读取age的操作,则会读取到升级前这个位置上实际是sex的值,造成了混乱。另一方面,升级后对sex的操作,变为了对0x000...01这个slot位置的操作。那么,如果执行升级后对合约字节码读取sex的操作,则由于之前在这个位置上没有值,则只能读取到默认的空值或0值,而无法读取到正确的值。
[0133]
本技术一种检测合约升级的兼容性方案,如图10所示,包括:
[0134]
s110:生成升级前后合约的抽象语法树。
[0135]
前述提到,编译器编译的过程大致可以包括根据抽象语法树进行词法/语法分析,
根据符号表填充符号,语义分析和代码生成等步骤。
[0136]
这里,可以对升级前后的智能合约代码根据抽象语法树进行词法/语法分析,生成升级前后的合约的抽象语法树。具体的,可以利用solidity编译器,使用
”‑‑
ast-compact-json”命令,将升级前后的合约源码为输入,则可以分别生成升级前后合约的抽象语法树json(javascript object notation,javascript对象表示法)文件。
[0137]
例如上述升级前的demo1合约,根据抽象语法树进行词法/语法分析,生成升级前的合约的抽象语法树如下:
[0138]
[0139][0140]
代码示例4.demo1的抽象语法树
[0141]
上面代码示例4是生成的升级前demo1合约的抽象语法树,并以//...标出了注释。其中,第11行的存储位置是关于slot的计算规则。上面的抽象语法树中,从第3行nodes以下,描述了合约状态变量在抽象语法树中的信息,一个状态变量相关的信息放在一个node中。关于id和sex这两个状态变量,实际上分为了两个节点,第5-19行是关于id的第一个node,第20-34行是关于sex的第二个node。每个node内部又包含若干信息。整体上,一个node内部的信息可以称为抽象语法树的节点信息。
[0142]
例如上述升级后的demo2合约,根据抽象语法树进行词法/语法分析,生成升级前的合约的抽象语法树如下:
[0143]
[0144]
[0145][0146]
代码示例5.demo2的抽象语法树
[0147]
上面代码示例5是生成的升级后demo2合约的抽象语法树。由于demo2代码中在原来的id和sex之间加入了一行对声明age变量,即demo2中的第4行,因此在demo2的抽象语法树中第5-19行的id节点信息和第35-50行的sex节点信息之间,插入了第20-34行的age节点信息。
[0148]
s120:解析生成的抽象语法树,顺序提取每个抽象语法树的节点信息中的基础信息。
[0149]
对上述代码示例4和5进行解析,即解析生成的抽象语法树,按照顺序提取每个抽象语法树的节点信息中的基础信息。这里的基础信息,至少可以包括节点顺序,进一步包括状态变量名和/或类型。
[0150]
以下一个例子,是提取得到升级前的demo1合约代码的包含节点顺序、状态变量名和状态变量类型的抽象语法树节点信息:
[0151]
节点信息1:id{typestring:uint256,...}
[0152]
节点信息2:sex{typestring:bool,...}
[0153]
同样的,提取得到升级后的demo2合约代码的包含节点顺序、状态变量名和状态变量类型的抽象语法树节点信息,如下:
[0154]
节点信息1:id{typestring:uint256,...}
[0155]
节点信息2:age{typestring:uint256,...}
[0156]
节点信息3:sex{typestring:bool,...}
[0157]
s130:比较升级前后的抽象语法树的节点信息中的基础信息,得到兼容性结论。
[0158]
例如上面s120中升级前后的抽象语法树节点信息中的基础信息,可以得到如下对照表:
[0159]
升级前的抽象语法树节点信息中的基础信息升级后的抽象语法树节点信息中的基础信息节点信息1:id{typestring:uint256,...}节点信息1:id{typestring:uint256,...}节点信息2:sex{typestring:bool,...}节点信息2:age{typestring:uint256,...} 节点信息3:sex{typestring:bool,...}
[0160]
表2、升级前后的抽象语法树的节点信息对比表
[0161]
上述表2,可以按照顺序将升级前后的抽象语法树的节点信息置于同一行中。进而,通过逐行扫描和比对,可以判断左右是否相同。换句话说,也就是比较升级前后的抽象语法树中相同节点编号的节点信息中的基础信息。当然,最好按照节点编号顺序,比较升级前后的抽象语法树中相同节点编号的节点信息中的基础信息。上面表2中,在扫描到节点信息2这一行时,可以比较得到状态变量名不同,从而可以得到不兼容的结论。
[0162]
这是因为,如前所述,按照slot的生成规则,是按照节点信息生成slot。进而,由合约地址和slot拼接生成状态变量的状态key。也就是说,在节点信息2这一行生成的slot是
相同的,例如都是0x000...01,而与变量名并不相关。这样,同样的slot或者状态key在合约升级后根据合约逻辑产生的value是另一个不同于升级前的状态变量,一般是前后不一致的。之所以说一般是前后不一致的,是因为,如果升级前后仅仅是调整了状态变量名,涉及该状态变量的合约逻辑没有任何改变,实际上也不会引起不兼容,但是这样的合约升级情况较为少见。大多情况下调整了状态变量名后合约逻辑也会存在一定变化。所以,进一步的,可以结合状态变量类型来判断。如果比较同一行节点信息中状态变量类型发生改变,也可以得到不兼容的结论。当然,如果比较同一行节点信息中状态变量名和状态变量类型均发生改变,可以得到更强的不兼容结论。
[0163]
此外,比较升级前后的抽象语法树的节点信息中的基础信息,如果升级后的状态变量名所在节点与升级前的相同状态变量名所在抽象语法树节点的顺序不同,则有较大概率可以得出不兼容结论。这是因为,一般来说,升级前后相同的状态变量名指代相同的状态变量;那么如果升级前后相同的状态变量所在的抽象语法树节点的顺序不同,则slot一般不同,则对数据的读写会产生混乱。
[0164]
实际上,通过s130的比对,如果结论是不兼容,还可以得到冲突的slot,例如上面表2中的节点顺序2。这样,可以将冲突的slot位置的基础信息/节点信息反馈给开发者,例如生成日志、告警之类的记录方式,或通过屏幕提示、邮件、即时消息等方式通知,以建议开发者或平台定位不兼容之处,并特别有利于开发者做出修改。
[0165]
还存在一种情况,升级后的状态变量与升级前相比,完全是在原有状态变量之后追加新的状态变量,则可以得到兼容的结论。例如如下示例代码:
[0166]
[0167][0168]
代码示例6.demo2'的solidity代码
[0169]
可见,demo2'的代码中,相比于demo1,是在原有的id和sex之后追加了age这一状态变量。这样,demo2'的抽象语法树如下:
[0170]
[0171]
[0172][0173]
代码示例7.demo2'的抽象语法树
[0174]
按照s120,提取得到升级后的demo2'合约代码的包含节点顺序、状态变量名和状态变量类型的抽象语法树节点信息,如下:
[0175]
节点信息1:id{typestring:uint256,...}
[0176]
节点信息2:sex{typestring:bool,...}
[0177]
节点信息3:age{typestring:uint256,...}
[0178]
这样,升级前后的抽象语法树节点信息中的基础信息,可以得到如下对照表:
[0179]
升级前的抽象语法树节点信息中的基础信息升级后的抽象语法树节点信息中的基础信息节点信息1:id{typestring:uint256,...}节点信息1:id{typestring:uint256,...}节点信息2:sex{typestring:bool,...}节点信息2:sex{typestring:bool,...} 节点信息3:age{typestring:uint256,...}
[0180]
表3、升级前后的抽象语法树的节点信息对比表
[0181]
由表3可见,升级前的状态变量id与sex在升级后的代码总状态变量名、状态变量类型和抽象语法树节点顺序都没有改变,这样,升级后的id和sex保持了与升级前相同的slot,因此是兼容的。升级后的状态变量,是在升级前的状态变量之后新追加,则按照slot生成规则,不会影响在前的状态变量的slot,也就不会影响状态key,因此可以得到兼容的结论。显然的,这种情况按照节点编号顺序进行比较更加容易实现。
[0182]
需要说明的是,上面例子中的id、age、sex这些状态变量,类型分别是uint256、uint256和bool,其中uint256为256bits,即32bytes,bool类型为1bytes。这些状态变量的类型决定了数据的长度是固定的,或者说是定长的。此外,还有uint、uint8、uint128这类的类型等也是定长的。定长元素组成的确定数量的数组,也是定长的,比如uint[2],包括2个元素,每个元素都是32bytes的uint类型,因此uint[2]整体是64bytes。
[0183]
除了定长的数据存储外,还有不定长度的,或者说是数据大小是无法预知的。这种情况,按照定长的方式在编译期间无法直接确定存储位置,而是采用了不同的方案。例如字
典(mapping)这种不确定长度的数据类型。字典的存储布局是存储key及其对应的value,每个key对应一份存储。一个key的对应存储位置是keccak256(key.slot),其中“.”是拼接符号,“.”之前的key是一个字典元素的key,“.”之后的slot字典名称所在slot的位置。例如demo2合约中,在id、age、sex之后是mappping(uint256=》string)a,则这个字典的元素个数不确定,且元素中key和value的长度也不确定。demo2合约被调用若干次后,字典a的元素可能有2个,分别是:
[0184]
a["u1"]=0x18;
[0185]
a["u2"]=0xac5b4fc54a5fa637d8c9853ada1430ea9203817e8a97df1f85f8e63a30f6713d7d3f68f79db22df669f5dbe17d43a16c720fe92edd5d87843ebf0b0b59;
[0186]
则在0x000...06这个slot中,可以存储字典的名称a。字典a中的第1项的key是u1,value是ox18。u1的存储位置可以是keccak256("u1".0x000...03),在这个位置起始的一个或连续多个slot中可以存储value(例如value的数据长度大于32bytes)。类似的,字典a中的第2项的key是u2,value是很长的一段16进制数。u2的存储位置可以是keccak256("u2".0x000...03),在这个位置起始的一个或连续多个slot中可以存储value(例如value的数据长度大于32bytes)。
[0187]
以u1的value的长度小于32bytes,u12的value的长度大于32bytes、小于64bytes为例。
[0188]
如图11所示,u1的value的长度小于32bytes,其value可以存放于1个slot中,这个slot的位置例如是keccak256("u1",0x000...03)的值,例如是:
[0189]
0x5b4ded6cc1629f138186f4b0795004adbed7ec13374d15ca04ec96f149132460
[0190]
u2的value的长度大于32bytes且小于64bytes,其value可以存放于2个连续的slot中,这两个slot的起始位置例如是keccak256("u2",0x000...03)的值,则这两个slot的位置是:
[0191]
0x90191b3f1d96c216c6a6637b9c8498bc25cc907afe246d611b3a8bf727bc081d
[0192]
0x90191b3f1d96c216c6a6637b9c8498bc25cc907afe246d611b3a8bf727bc081e
[0193]
上述不定长的数据,也可以通过执行上述s110~s130的过程来判断是否兼容。例如对上述字典结构生成抽象语法树节点信息为:
[0194]
[0195][0196]
代码示例8.字典结构的抽象语法树
[0197]
则在执行s120中的过程中,还需要遍历不定长数据结构中的每个slot,因为这些slot的位置可能是最终的状态key的计算基础。特别的,对于u2这种value占用的多个连续slot的情况,可以以起始位置作为状态key的计算基础。
[0198]
此外,还存在一些复合结构。例如结构体和字典的复合结构,如下solidity代码:
[0199][0200]
代码示例9.复合结构的solidity代码
[0201]
上述代码中,在第7-10声明了一个结构体structdemo,其包括两个元素,分别是uint256类型的c_和bytes类型的d_。然后,在第11行声明了一个字典,这个字典是uint到结构体structdemo的映射。上述代码的结构体和字典部分,按照s110生成的抽象语法树包括:
[0202]
[0203]
[0204][0205]
代码示例10.复合结构的抽象语法树
[0206]
上述抽象语法树的第6-17行是结构体structdemo中uint256 c_的节点信息,第18-31行是结构体structdemo中bytes d_的节点信息,bytes类型也是32字节。需要注意的是,第10行和第23行都是"statevariable":false,说明c_和d_都不是状态变量,也就都不会存储在底层数据库中。
[0207]
则在s120中,并不会提取"statevariable":false的结构体元素c_和d_,因为c_和d_在这里还不会直接存储到底层数据库中。但在字典a中,"statevariable"为true,则会提取这个抽象语法树的节点信息中的基础信息,因为字典a会存储到底层数据库中,其中的元素中包括的结构体c_和d_才会存储到底层数据库中。也就是说,结构体仅仅做了声明。这样,s120中,解析生成的抽象语法树,对于节点信息中状态变量为真的,顺序提取每个抽象语法树的节点信息中的基础信息。
[0208]
此外,对于复合结构,例如上述字典结构中value是结构体的情况,解析生成的抽象语法树,顺序并递归的提取每个抽象语法树的节点信息中的基础信息。这是因为,虽然结构体本身的节点信息中"statevariable"的属性是false,但作为字典中的value值,其具有自身的slot和状态key。通过顺序并递归的方式提取节点信息的基础信息,可以展开所有实际会存储到底层数据库的状态变量,才不会遗漏。递归的方式,是将嵌套的结构定义展开,从中获得包含的数据结构;如果有更多层的嵌套,则继续以递归的方式获得所包含的数据结构。
[0209]
这个例子中,假设在合约代码中初始化了2个map2_,分别为:
[0210]
map2_"structdemo"_uint:"structdemo"_"c_"
ꢀꢀꢀꢀꢀꢀꢀ
0:structdemo_c_
[0211]
map2_"structdemo"_uint:"structdemo"_"d_"
ꢀꢀꢀꢀꢀꢀꢀ
0:structdemo_d_
[0212]
map2_"structdemo"_uint:"structdemo"_"c_"
ꢀꢀꢀꢀꢀꢀꢀ
1:structdemo_c_
[0213]
map2_"structdemo"_uint:"structdemo"_"d_"
ꢀꢀꢀꢀꢀꢀꢀ
1:structdemo_d_
[0214]
则提取得到的demo2”合约代码的包含节点顺序、状态变量名和状态变量类型的抽象语法树节点信息,如下:
[0215]
节点信息1:id{typestring:uint256,...}
[0216]
节点信息2:age{typestring:uint256,...}
[0217]
节点信息3:sex{typestring:bool,...}
[0218]
节点信息4:map2_{typestring:mapping(uint256=》struct demo”_.structdemo),...}
[0219]
节点信息5:map2_structdemo_0:c_{typestring:uint256,...}
[0220]
节点信息6:map2_structdemo_0:d_{typestring:bytes,...}
[0221]
节点信息7:map2_structdemo_1:c_{typestring:uint256,...}
[0222]
节点信息8:map2_structdemo_2:d_{typestring:bytes,...}
[0223]
如果有另外一个升级后的包括id、age、sex、map2_的合约,提取得到的合约代码的包含节点顺序、状态变量名和状态变量类型的抽象语法树节点信息,与上述一致,则兼容,反之不一致则不兼容。上述例子的slot示意如图12所示。
[0224]
另一个例子中,假设在合约代码中没有初始化了map2_,得到的合约代码的包含节点顺序、状态变量名和状态变量类型的抽象语法树节点信息例如为如下:
[0225]
节点信息1:id{typestring:uint256,...}
[0226]
节点信息2:age{typestring:uint256,...}
[0227]
节点信息3:sex{typestring:bool,...}
[0228]
节点信息4:map2_{typestring:mapping(uint256=》struct demo”_.structdemo),...}
[0229]
则合约升级前后,在比较节点信息2时,需要递归的比较嵌套的struct结构。如果升级前后分别提取的抽象语法树节点信息中,节点信息4及其中嵌套的结构均一致则兼容(假设节点信息1、2、3均一致),反之不一致则不兼容。
[0230]
升级的合约写法需要满足一定的规范才能使得升级前后兼容,即升级后的新合约中的状态,需要保持能够读取旧合约中相同状态的值的能力。用户在编写升级的合约时,往往忽略这些规范,从而导致升级后的合约出现数据丢失、错乱等严重问题。通过上述例子,可以实现基于抽象语法树的solidity合约升级存储数据兼容性检测方案。
[0231]
以下介绍本技术一种合约升级的兼容性的检测装置,包括:
[0232]
抽象语法树生成单元,用于生成升级前后合约的抽象语法树;
[0233]
提取单元,用于解析生成的抽象语法树,并顺序提取每个抽象语法树的节点信息中的基础信息;
[0234]
比较单元,用于比较升级前后的抽象语法树的节点信息中的基础信息,得到兼容性结论。
[0235]
所述提取单元解析生成的抽象语法树,对于节点信息中状态变量为真的,顺序提取每个抽象语法树的节点信息中的基础信息。
[0236]
所述抽象语法树生成单元对升级前后的智能合约代码根据抽象语法树进行词法/语法分析,生成升级前后的合约的抽象语法树。
[0237]
所述基础信息包括抽象语法树的节点顺序,进一步还包括状态变量名和/或类型。
[0238]
所述比较单元比较升级前后的抽象语法树中相同节点编号的节点信息中的基础信息。
[0239]
所述比较单元按照节点编号顺序,比较升级前后的抽象语法树中相同节点编号的节点信息中的基础信息。
[0240]
比较单元比较过程中,
[0241]
如果比较得到状态变量名不同,则不兼容;或,
[0242]
如果比较得到状态变量类型不同,则不兼容;或,
[0243]
如果状态变量名和状态变量类型均不同,则不兼容。
[0244]
所述比较单元比较升级后的状态变量是在升级前状态变量之后追加新的状态变量的,判断为兼容。
[0245]
对于复合结构,所述提取单元解析生成的抽象语法树,顺序并递归的提取每个抽象语法树的节点信息中的基础信息。
[0246]
所述检测装置还包括反馈单元,对于比较单元的比较结果为不兼容的,所述反馈单元反馈冲突的slot位置的基础信息/节点信息。
[0247]
以下介绍本技术一种客户端实施例,包括:
[0248]
处理器,
[0249]
存储器,存储有程序,其中在所述处理器执行所述程序时,执行上述任一实施例所述的方法,以实现譬如检测合约升级的兼容性等目的。
[0250]
在20世纪90年代,对于一个技术的改进可以很明显地区分是硬件上的改进(例如,对二极管、晶体管、开关等电路结构的改进)还是软件上的改进(对于方法流程的改进)。然而,随着技术的发展,当今的很多方法流程的改进已经可以视为硬件电路结构的直接改进。设计人员几乎都通过将改进的方法流程编程到硬件电路中来得到相应的硬件电路结构。因此,不能说一个方法流程的改进就不能用硬件实体模块来实现。例如,可编程逻辑器件(programmable logic device,pld)(例如现场可编程门阵列(field programmable gate array,fpga))就是这样一种集成电路,其逻辑功能由用户对器件编程来确定。由设计人员自行编程来把一个数字系统“集成”在一片pld上,而不需要请芯片制造厂商来设计和制作专用的集成电路芯片。而且,如今,取代手工地制作集成电路芯片,这种编程也多半改用“逻辑编译器(logic compiler)”软件来实现,它与程序开发撰写时所用的软件编译器相类似,而要编译之前的原始代码也得用特定的编程语言来撰写,此称之为硬件描述语言(hardware description language,hdl),而hdl也并非仅有一种,而是有许多种,如abel(advanced boolean expression language)、ahdl(altera hardware description language)、confluence、cupl(cornell university programming language)、hdcal、jhdl(java hardware description language)、lava、lola、myhdl、palasm、rhdl(ruby hardware description language)等,目前最普遍使用的是vhdl(very-high-speed integrated circuit hardware description language)与verilog。本领域技术人员也应该清楚,只需要将方法流程用上述几种硬件描述语言稍作逻辑编程并编程到集成电路中,就可以很容易得到实现该逻辑方法流程的硬件电路。
[0251]
控制器可以按任何适当的方式实现,例如,控制器可以采取例如微处理器或处理器以及存储可由该(微)处理器执行的计算机可读程序代码(例如软件或固件)的计算机可读介质、逻辑门、开关、专用集成电路(application specific integrated circuit,asic)、可编程逻辑控制器和嵌入微控制器的形式,控制器的例子包括但不限于以下微控制器:arc 625d、atmel at91sam、microchip pic18f26k20以及silicone labs c8051f320,存储器控制器还可以被实现为存储器的控制逻辑的一部分。本领域技术人员也知道,除了以纯计算机可读程序代码方式实现控制器以外,完全可以通过将方法步骤进行逻辑编程来使得控制器以逻辑门、开关、专用集成电路、可编程逻辑控制器和嵌入微控制器等的形式来实现相同功能。因此这种控制器可以被认为是一种硬件部件,而对其内包括的用于实现各种功能的装置也可以视为硬件部件内的结构。或者甚至,可以将用于实现各种功能的装置视
为既可以是实现方法的软件模块又可以是硬件部件内的结构。
[0252]
上述实施例阐明的系统、装置、模块或单元,具体可以由计算机芯片或实体实现,或者由具有某种功能的产品来实现。一种典型的实现设备为服务器系统。当然,本技术不排除随着未来计算机技术的发展,实现上述实施例功能的计算机例如可以为个人计算机、膝上型计算机、车载人机交互设备、蜂窝电话、相机电话、智能电话、个人数字助理、媒体播放器、导航设备、电子邮件设备、游戏控制台、平板计算机、可穿戴设备或者这些设备中的任何设备的组合。
[0253]
虽然本说明书一个或多个实施例提供了如实施例或流程图所述的方法操作步骤,但基于常规或者无创造性的手段可以包括更多或者更少的操作步骤。实施例中列举的步骤顺序仅仅为众多步骤执行顺序中的一种方式,不代表唯一的执行顺序。在实际中的装置或终端产品执行时,可以按照实施例或者附图所示的方法顺序执行或者并行执行(例如并行处理器或者多线程处理的环境,甚至为分布式数据处理环境)。术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、产品或者设备不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、产品或者设备所固有的要素。在没有更多限制的情况下,并不排除在包括所述要素的过程、方法、产品或者设备中还存在另外的相同或等同要素。例如若使用到第一,第二等词语用来表示名称,而并不表示任何特定的顺序。
[0254]
为了描述的方便,描述以上装置时以功能分为各种模块分别描述。当然,在实施本说明书一个或多个时可以把各模块的功能在同一个或多个软件和/或硬件中实现,也可以将实现同一功能的模块由多个子模块或子单元的组合实现等。以上所描述的装置实施例仅仅是示意性的,例如,所述单元的划分,仅仅为一种逻辑功能划分,实际实现时可以有另外的划分方式,例如多个单元或组件可以结合或者可以集成到另一个系统,或一些特征可以忽略,或不执行。另一点,所显示或讨论的相互之间的耦合或直接耦合或通信连接可以是通过一些接口,装置或单元的间接耦合或通信连接,可以是电性,机械或其它的形式。
[0255]
本发明是参照根据本发明实施例的方法、装置(系统)、和计算机程序产品的流程图和/或方框图来描述的。应理解可由计算机程序指令实现流程图和/或方框图中的每一流程和/或方框、以及流程图和/或方框图中的流程和/或方框的结合。可提供这些计算机程序指令到通用计算机、专用计算机、嵌入式处理机或其他可编程数据处理设备的处理器以产生一个机器,使得通过计算机或其他可编程数据处理设备的处理器执行的指令产生用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的装置。
[0256]
这些计算机程序指令也可存储在能引导计算机或其他可编程数据处理设备以特定方式工作的计算机可读存储器中,使得存储在该计算机可读存储器中的指令产生包括指令装置的制造品,该指令装置实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能。
[0257]
这些计算机程序指令也可装载到计算机或其他可编程数据处理设备上,使得在计算机或其他可编程设备上执行一系列操作步骤以产生计算机实现的处理,从而在计算机或其他可编程设备上执行的指令提供用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的步骤。
[0258]
在一个典型的配置中,计算设备包括一个或多个处理器(cpu)、输入/输出接口、网
络接口和内存。
[0259]
内存可能包括计算机可读介质中的非永久性存储器,随机存取存储器(ram)和/或非易失性内存等形式,如只读存储器(rom)或闪存(flash ram)。内存是计算机可读介质的示例。
[0260]
计算机可读介质包括永久性和非永久性、可移动和非可移动媒体可以由任何方法或技术来实现信息存储。信息可以是计算机可读指令、数据结构、程序的模块或其他数据。计算机的存储介质的例子包括,但不限于相变内存(pram)、静态随机存取存储器(sram)、动态随机存取存储器(dram)、其他类型的随机存取存储器(ram)、只读存储器(rom)、电可擦除可编程只读存储器(eeprom)、快闪记忆体或其他内存技术、只读光盘只读存储器(cd-rom)、数字多功能光盘(dvd)或其他光学存储、磁盒式磁带,磁带磁磁盘存储、石墨烯存储或其他磁性存储设备或任何其他非传输介质,可用于存储可以被计算设备访问的信息。按照本文中的界定,计算机可读介质不包括暂存电脑可读媒体(transitory media),如调制的数据信号和载波。
[0261]
本领域技术人员应明白,本说明书一个或多个实施例可提供为方法、系统或计算机程序产品。因此,本说明书一个或多个实施例可采用完全硬件实施例、完全软件实施例或结合软件和硬件方面的实施例的形式。而且,本说明书一个或多个实施例可采用在一个或多个其中包含有计算机可用程序代码的计算机可用存储介质(包括但不限于磁盘存储器、cd-rom、光学存储器等)上实施的计算机程序产品的形式。
[0262]
本说明书一个或多个实施例可以在由计算机执行的计算机可执行指令的一般上下文中描述,例如程序模块。一般地,程序模块包括执行特定任务或实现特定抽象数据类型的例程、程序、对象、组件、数据结构等等。也可以在分布式计算环境中实践本本说明书一个或多个实施例,在这些分布式计算环境中,由通过通信网络而被连接的远程处理设备来执行任务。在分布式计算环境中,程序模块可以位于包括存储设备在内的本地和远程计算机存储介质中。
[0263]
本说明书中的各个实施例均采用递进的方式描述,各个实施例之间相同相似的部分互相参见即可,每个实施例重点说明的都是与其他实施例的不同之处。尤其,对于系统实施例而言,由于其基本相似于方法实施例,所以描述的比较简单,相关之处参见方法实施例的部分说明即可。在本说明书的描述中,参考术语“一个实施例”、“一些实施例”、“示例”、“具体示例”、或“一些示例”等的描述意指结合该实施例或示例描述的具体特征、结构、材料或者特点包含于本说明书的至少一个实施例或示例中。在本说明书中,对上述术语的示意性表述不必须针对的是相同的实施例或示例。而且,描述的具体特征、结构、材料或者特点可以在任一个或多个实施例或示例中以合适的方式结合。此外,在不相互矛盾的情况下,本领域的技术人员可以将本说明书中描述的不同实施例或示例以及不同实施例或示例的特征进行结合和组合。
[0264]
以上所述仅为本说明书一个或多个实施例的实施例而已,并不用于限制本本说明书一个或多个实施例。对于本领域技术人员来说,本说明书一个或多个实施例可以有各种更改和变化。凡在本说明书的精神和原理之内所作的任何修改、等同替换、改进等,均应包含在权利要求范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1