视频检测方法、装置、设备、存储介质及程序产品
1.本发明涉及计算机视觉和语音识别等技术领域,尤其涉及一种视频检测方法、装置、设备、存储介质及程序产品。
背景技术:
2.在内容(例如视频)安全领域,对内容进行安全检测,以确定内容是否包括敏感信息是一项重要的工作。
3.在相关技术中,通常将视频,输入预先训练好的编码解码 (transformer)网络,通过transformer网络对视频进行安全检测,输出视频是否包括敏感信息的检测结果。
4.在上述相关技术中,仅通过transformer网络对视频进行检测处理,导致对视频进行安全检测的准确性较差。
技术实现要素:
5.本发明提供一种视频检测方法、装置、设备、存储介质及程序产品,用以解决现有技术中对视频进行安全检测的准确性较差的缺陷,实现提高对视频进行安全检测的准确性。
6.本发明提供一种视频检测方法,包括:
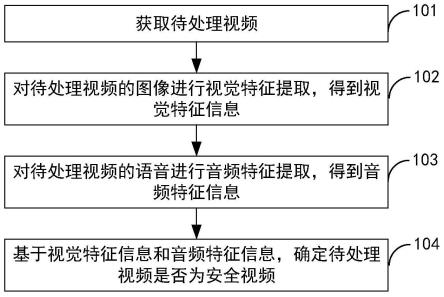
7.获取待处理视频;
8.对待处理视频的图像进行视觉特征提取,得到视觉特征信息;
9.对待处理视频的语音进行音频特征提取,得到音频特征信息;
10.基于视觉特征信息和音频特征信息,确定待处理视频是否为安全视频。
11.根据本发明提供的一种视频检测方法,对待处理视频的图像进行视觉特征提取,得到视觉特征信息,包括:
12.通过语义特征提取网络,对图像进行语义特征提取,得到视觉语义特征信息;
13.通过句法特征提取网络,对图像进行句法特征提取,得到视觉句法特征信息;
14.通过显著对象检测网络,对图像进行显著对象特征提取,得到显著对象特征信息;
15.视觉特征信息中包括视觉语义特征信息、视觉句法特征信息和显著对象特征信息。
16.根据本发明提供的一种视频检测方法,对待处理视频的语音进行音频特征提取,得到音频特征信息,包括:
17.通过语音特征提取网络,对语音进行语音特征提取,得到语音特征信息;
18.通过多频域重建网络,对语音特征信息进行频域特征提取,得到频域特征信息;
19.通过多频域关系学习网络,提取频域特征信息的频域关系特征,得到音频特征信息。
20.根据本发明提供的一种视频检测方法,基于视觉特征信息和音频特征信息,确定待处理视频是否为安全视频,包括:
21.基于视觉特征信息和音频特征信息,确定待处理视频的目标深度哈希码;
22.基于目标深度哈希码,确定待处理视频是否为安全视频。
23.根据本发明提供的一种视频检测方法,基于视觉特征信息和音频特征信息,确定待处理视频的目标深度哈希码,包括:
24.通过图卷积神经网络,对视觉特征信息和音频特征信息进行处理,得到包括对象关系的视觉语义特征、包括对象关系的视觉句法特征和包括对象关系的听觉特征;
25.对包括对象关系的视觉语义特征、包括对象关系的视觉句法特征和包括对象关系的听觉特征进行多源特征融合处理,得到注意力索引信息和词向量信息;
26.对视觉特征信息中包括的视觉语义特征信息和句法特征提取网络、以及音频特征信息进行多源特征融合处理,得到注意力权重信息;
27.通过编码解码网络,对注意力索引信息、词向量信息和注意力权重信息进行处理,得到待处理视频的编解码结果;
28.通过哈希编码网络,对编解码结果进行哈希编码,得到目标深度哈希码。
29.根据本发明提供的一种视频检测方法,基于目标深度哈希码,确定待处理视频是否为安全视频,包括:
30.获取预先存储的黑名单,黑名单中包括多个预设深度哈希码,预设深度哈希码对应的视频为非安全视频;
31.若黑名单中存在与目标深度哈希码之间的汉明距离小于或等于预设阈值的预设深度哈希码,则确定待处理视频为非安全视频;若黑名单中不存在与目标深度哈希码之间的汉明距离小于或等于预设阈值的预设深度哈希码,则确定待处理视频为安全视频。
32.本发明还提供一种视频检测装置,包括:
33.获取模块,用于获取待处理视频;
34.处理模块,用于对待处理视频的图像进行视觉特征提取,得到视觉特征信息;
35.处理模块,还用于对待处理视频的语音进行音频特征提取,得到音频特征信息;
36.处理模块,还用于基于视觉特征信息和音频特征信息,确定待处理视频是否为安全视频。
37.根据本发明提供的一种视频检测装置,处理模块具体用于:
38.通过语义特征提取网络,对图像进行语义特征提取,得到视觉语义特征信息;
39.通过句法特征提取网络,对图像进行句法特征提取,得到视觉句法特征信息;
40.通过显著对象检测网络,对图像进行显著对象特征提取,得到显著对象特征信息;
41.视觉特征信息中包括视觉语义特征信息、视觉句法特征信息和显著对象特征信息。
42.根据本发明提供的一种视频检测装置,处理模块还具体用于:
43.通过语音特征提取网络,对语音进行语音特征提取,得到语音特征信息;
44.通过多频域重建网络,对语音特征信息进行频域特征提取,得到频域特征信息;
45.通过多频域关系学习网络,提取频域特征信息的频域关系特征,得到音频特征信息。
46.根据本发明提供的一种视频检测装置,处理模块还具体用于:
47.基于视觉特征信息和音频特征信息,确定待处理视频的目标深度哈希码;
48.基于目标深度哈希码,确定待处理视频是否为安全视频。
49.根据本发明提供的一种视频检测装置,处理模块还具体用于:
50.通过图卷积神经网络,对视觉特征信息和音频特征信息进行处理,得到包括对象关系的视觉语义特征、包括对象关系的视觉句法特征和包括对象关系的听觉特征;
51.对包括对象关系的视觉语义特征、包括对象关系的视觉句法特征和包括对象关系的听觉特征进行多源特征融合处理,得到注意力索引信息和词向量信息;
52.对视觉特征信息中包括的视觉语义特征信息和句法特征提取网络、以及音频特征信息进行多源特征融合处理,得到注意力权重信息;
53.通过编码解码网络,对注意力索引信息、词向量信息和注意力权重信息进行处理,得到待处理视频的编解码结果;
54.通过哈希编码网络,对编解码结果进行哈希编码,得到目标深度哈希码。
55.根据本发明提供的一种视频检测装置,处理模块还具体用于:
56.获取预先存储的黑名单,黑名单中包括多个预设深度哈希码,预设深度哈希码对应的视频为非安全视频;
57.若黑名单中存在与目标深度哈希码之间的汉明距离小于或等于预设阈值的预设深度哈希码,则确定待处理视频为非安全视频;若黑名单中不存在与目标深度哈希码之间的汉明距离小于或等于预设阈值的预设深度哈希码,则确定待处理视频为安全视频。
58.本发明还提供一种电子设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,处理器执行程序时实现如上述任一种视频检测方法。
59.本发明还提供一种非暂态计算机可读存储介质,其上存储有计算机程序,该计算机程序被处理器执行时实现如上述任一种视频检测方法。
60.本发明还提供一种计算机程序产品,包括计算机程序,计算机程序被处理器执行时实现如上述任一种视频检测方法。
61.本发明提供的视频检测方法、装置、设备、存储介质及程序产品,通过视觉特征信息和音频特征信息,确定待处理视频是否为安全视频,实现通过多源特征来确定待处理视频是否为安全视频的目标,提高对待处理视频进行安全检测的准确性。
附图说明
62.为了更清楚地说明本发明或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作一简单地介绍,显而易见地,下面描述中的附图是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
63.图1是本发明提供的视频检测方法的流程示意图;
64.图2是本发明提供的第一训练网络的结构示意图;
65.图3是本发明提供的第二训练网络的结构示意图;
66.图4是本发明提供的第三训练网络的结构示意图;
67.图5是本发明提供的第四训练网络的结构示意图;
68.图6是本发明提供的第五训练网络的结构示意图;
69.图7是本发明提供的第六训练网络的结构示意图;
70.图8是本发明提供的视频检测方法的流程框图;
71.图9是本发明提供的视频检测装置的结构示意图;
72.图10是本发明提供的电子设备的实体结构示意图。
具体实施方式
73.为使本发明的目的、技术方案和优点更加清楚,下面将结合本发明中的附图,对本发明中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
74.在相关技术中,通过transformer网络对视频进行检测处理,仅关注视频中图像的全局特征,导致对视频进行安全检测的准确性较差。
75.在本发明中,为了提高视频进行安全检测的准确性,发明人想到通过视频的视觉特征信息和音频特征提取,得到目标深度哈希码,并基于目标深度哈希码,确定视频是否为安全视频,不仅关注视频的图像特征,还关注视频的音频特征,从而提高对视频进行安全检测的准确性。
76.下面结合具体实施例描述本发明提供的视频检测方法。
77.图1是本发明提供的视频检测方法的流程示意图。如图1所示,该方法包括:
78.步骤101、获取待处理视频。
79.可选地,本发明实施例的执行主体为电子设备,可以为设置在电子设备中的视频检测装置,视频检测装置可以通过软件和/或硬件的结合来实现。
80.待处理视频可以为任意需要进行安全检测的视频。
81.例如待处理视频为需要在网络平台上发布的视频,可以为从网络平台上下载的视频,还可以为电子设备录制的视频等。此处对待处理视频的来源不进行限定。
82.步骤102、对待处理视频的图像进行视觉特征提取,得到视觉特征信息。
83.图像为待处理视频中包括的视频图像。
84.视觉特征信息可以反映图像的局部特征和全局特征。局部特征和全局特征互补。
85.步骤103、对待处理视频的语音进行音频特征提取,得到音频特征信息。
86.语音是为待处理视频配置的语音。
87.步骤104、基于视觉特征信息和音频特征信息,确定待处理视频是否为安全视频。
88.在图1实施例提供的视频检测方法中,基于视觉特征信息和音频特征信息,确定待处理视频是否为安全视频,实现通过多源特征来确定待处理视频是否为安全视频的目标,提高对待处理视频进行安全检测的准确性。
89.可选地,视觉特征提取模型中包括语义特征提取网络、句法特征提取网络和显著对象检测网络。
90.具体的,步骤102包括:
91.通过语义特征提取网络,对图像进行语义特征提取,得到视觉语义特征信息;
92.通过句法特征提取网络,对图像进行句法特征提取,得到视觉句法特征信息;
93.通过显著对象检测网络,对图像进行显著对象特征提取,得到显著对象特征信息;
94.视觉特征信息中包括视觉语义特征信息、视觉句法特征信息和显著对象特征信
息。
95.与现有技术不同,在现有技术中,仅通过transformer网络对视频进行检测处理,缺乏对于视频的多源理解和刻画,导致对视频进行安全检测的准确性较差,而且transformer网络仅学习了全局特征,缺少了对于图像中局部关键内容和对象的刻画,导致对同类不同源内容的漏判和错判问题,例如在相同的图像背景下插入正常内容和异常内容,可以得到相似的检测结果。而且在本发明中,通过语义特征提取网络,得到视觉语义特征信息,通过句法特征提取网络,得到视觉句法特征信息,通过显著对象检测网络,得到显著对象特征信息,可以实现对视频的多源理解和刻画,提高对视频进行安全检测的准确性,而且视觉语义特征信息和视觉句法特征信息互补,学习到图像的全局特征、以及局部关键内容,实现对图像中对象的刻画,避免出现对同类不同源内容的漏判和错判问题,提高对视频检测的准确性。
96.在本发明中,可以通过如附图2所示的第一训练网络,得到语义特征提取网络。下面结合图2对第一训练网络进行说明。
97.图2是本发明提供的第一训练网络的结构示意图。如图2所示,包括:主动学习模块、特征提取网络、预测和损失函数模块。
98.主动学习模块用于对无标签的样本图像进行标注,然后自适应的调整打标阈值。
99.特征提取网络的主体结构可以是resnet(例如resnet50)、 efficientnet等深度学习网络。特征提取网络的输入为图像,输出为视觉深度特征(例如512维的特征向量)。
100.预测和损失函数模块用于基于损失函数ls
semantic
调整第一训练网络的模型参数,直至第一训练网络中的模型参数收敛。
101.ls
semantic
=l
ce
(x
lab
,y
lab
)+l
semi-ce
(x
semi
,y
semi
)+ kl(f(x
unlab
),f(aug(x
unlab
)));
102.其中,l
ce
表示分类损失,l
semi-表示半监督分类损失,kl表示半监督分布拟合损失,x
lab
表示有标签的样本图像,y
lab
表示样本图像x
lab
对应的标签,x
semi
表示通过主动学习模块进行自打标签的样本图像,y
semi
表示样本图像x
semi
对应的标签,x
unlab
表示无标签的样本图像,f(x
unlab
)表示该特征提取网络对于样本图像x
unmlab
输出的特征结果,f(aug(x
unlab
))表示对样本图像x
unlab
经过数据增强后通过特征提取网络得到的特征结果。
103.从ls
semantic
中可以看出,有标签的样本图像作用在l
ce
上,无标签的样本图像作用在kl上,无标签的样本图像经过主动学习模块之后得到的有标签的样本图像作用在l
semi-上。在本发明中,有标签的样本图像作用在l
ce
上,无标签的样本图像作用在kl上,无标签的样本图像经过主动学习模块之后得到的有标签的样本图像作用在 l
semi-ce
上,使得经过扰动和没有扰动的图像的特征分布尽量一致。
104.下面对第一训练网络的训练过程进行说明:关闭主动学习模块,采用有标注的训练集(包括有标注样本和样本的标签)对特征提取网络进行一轮(epoch)有监督迭代训练,在该轮迭代的过程中, ls
semantic
中仅包括l
ce
(x
lab
,y
lab
);通过预训练好的特征提取网络对无标注的数据集进行预测,得到无标注的数据集中无标注样本的标签;无标注样本可以是从开放互联网或者通过爬取获取的样本;从无标注的数据集中选择预测置信度最高的10%无标注的样本;将10%无标注的样本和标签,以及有标注的训练集,作为目标训练集;开启主动学习模块,采用目标训练集对主动学习模块、语义特征提取网络,进行多轮半监督迭代训练,ls
semantic
包括l
ce
(x
lab
,y
lab
)、 l
semi-ce
(x
semi
,y
semi
)、kl(f(x
unlab
),f(aug(x
unlab
)))。
105.可选地,在第一训练网络中的所有模型参数均收敛的情况下,将特征提取网络,确定为本发明中的语义特征提取网络。
106.可选地,句法特征提取网络可以采用如下方式11或者方式12,得到视觉句法特征信息。
107.方式11、基于方向梯度直方图(histogram of oriented gradient, hog)算子对图像进行特征提取,得到hog特征;基于尺度不变特征变换(scale invariant feature transform,sift)算子对图像进行特征提取,得到sift特征;基于句法特征提取网络中的,局部最大出现(local maximal occurrence,lomo)模型对图像进行特征提取,得到lomo特征;基于局部二值模式(local binary pattern,lbp)算子对图像进行特征提取,得到lbp特征;通过句法特征提取网络中的基于注意力的(attention-based)主成分分析(principal componentanalysis,pca)特征融合子网络,对hog特征、sift特征、lomo 特征和lbp特征进行处理,得到视觉句法特征信息。
108.方式12、通过目标算子或者目标子网络,对图像进行特征提取,得到视觉句法特征信息;目标算子可以为hog算子、sift算子、lbp 算子中的任意一种,目标子网络可以为lomo模型。例如,在目标算子为hog算子的情况下,将hog特征确定为视觉句法特征信息。
109.在具体实现中,使用基于图形处理器(graphics processing unit, gpu)加速的跨平台计算机视觉和机器学习软件库(opencv),得到hog特征、sift特征、lbp特征;使用基于gpu加速的爬虫(python) 机器学习库(pytorch)中的lomo模型得到lomo特征。
110.基于注意力的pca特征融合子网络用于将冗长的句法特征浓缩为512维的视觉句法特征信息。
111.基于注意力的pca特征融合子网络包括:挤压和激发 (squeeze-and-excitation,se)模块(block)和可训练的pca模块。
112.可选地,可训练的pca模块为两个全连接层,起到降维的目的,两个全连接层中的第一个全连接层的输出为降维后的特征,第二个全连接层是对降维后的特征进行特征重建。
113.可选地,显著对象检测网络可以基于第二训练网络得到。下面结合图3对第二训练网络进行详细说明。
114.图3是本发明提供的第二训练网络的结构示意图。如图3所示,第二训练网络包括:显著对象检测特征提取模块和解耦学习模块。
115.显著对象检测特征提取模块的输入为图像,显著对象检测特征提取模块的输出为图像对应的特征图谱。显著对象检测特征提取模块可以是常用的检测和分割网络,例如mask r-cnn网络。
116.解耦学习模块的输入为显著对象检测特征提取模块的输出,解耦学习模块的输出为显著性特征图谱、非显著性特征图谱和最终的显著性对象位置。解耦学习模块包括3个卷积层。
117.可选地,解耦学习模块使用基于解耦学习模块的下游任务损失函数ls
dis
进行训练。
118.ls
dis
=(l
sal
(f1)-l
non-s
(f1))+(l
non-sal
(f2)-l
sal
(f2));
119.其中,f1表示样本显著性特征图谱,f2表示样本非显著性特征图谱,l
sal
表示用于提
升显著性特征图谱预测准确率的损失函数,它的作用是使显著目标预测更准;l
non-s
表示用于提升非显著性特征图谱预测准确率的损失函数,使非显著对象预测更准。
120.需要说明的是,f1针对显著性对象进行优化,而抑制非显著性对象检测的性能;f2的约束则相反)。
121.具体的,可以基于随机梯度下降法(stochastic gradient descent, sgd)对损失函数ls
dis
进行优化处理。
122.可选地,步骤103包括:
123.通过语音特征提取网络,对语音进行语音特征提取,得到语音特征信息;
124.通过多频域重建网络,对语音特征信息进行频域特征提取,得到频域特征信息;
125.通过多频域关系学习网络,提取频域特征信息的频域关系特征,得到音频特征信息。
126.可选地,可以基于第三训练网络得到语音特征提取网络、多频域重建网络和多频域关系学习网络。下面结合图4对第三训练网络进行说明。
127.图4是本发明提供的第三训练网络的结构示意图。如图4所示,第三训练网络包括:(recurrent neural network,rnn)特征提取模块、多频域重建模块、多频域关系学习模块。
128.其中,rnn特征提取模块为使用pytorch中包含门循环单元 (gate recurrent unit,gru)的rnn模块进行模型搭建得到的。多频域重建模块包括3层多层感知机(multilayer perceptron,mlp)。多频域关系学习网络包括3层mlp组成。
129.rnn特征提取模块的输入为语音,输出为语音特征。
130.多频域重建模块的输入为语音特征输出为多个频段的语音信息。
131.多频域关系学习模块的输入为多个频段的语音信息,输出为多频域关系调制后的语音特征。
132.在第二训练网络进行训练的过程中,基于损失函数ls
voice
更新第二训练网络中的所有模型参数,直至所有模型参数均收敛。
133.ls
voice
=l
ce
+l
re
;
134.其中,l
ce
表示分类损失,l
re
表示重建损失。
135.在所有模型参数均收敛的情况下,将rnn特征提取模块,确定为语音特征提取网络;将多频域重建模块,确定为多频域重建网络;将多频域关系学习模块,确定为多频域关系学习网络。
136.可选地,基于视觉特征信息和音频特征信息,确定待处理视频是否为安全视频,包括:基于视觉特征信息和音频特征信息,确定待处理视频的目标深度哈希码;基于目标深度哈希码,确定待处理视频是否为安全视频。
137.其中,基于视觉特征信息和音频特征信息,确定待处理视频的目标深度哈希码,包括:
138.通过图卷积神经网络,对视觉特征信息和音频特征信息进行处理,得到包括对象关系的视觉语义特征、包括对象关系的视觉句法特征和包括对象关系的听觉特征;
139.对包括对象关系的视觉语义特征、包括对象关系的视觉句法特征和包括对象关系的听觉特征进行多源特征融合处理,得到注意力索引信息和词向量信息;
140.对视觉特征信息中包括的视觉语义特征信息和句法特征提取网络、以及音频特征
信息进行多源特征融合处理,得到注意力权重信息;
141.通过编码解码网络,对注意力索引信息、词向量信息和注意力权重信息进行处理,得到待处理视频的编解码结果;
142.通过哈希编码网络,对编解码结果进行哈希编码,得到目标深度哈希码。
143.可选地,可以基于第四训练网络得到图卷积神经网络(graphconvolutional networks,gcn)。下面结合图5对第四训练网络进行说明。
144.图5是本发明提供的第四训练网络的结构示意图。如图5所示,第四训练网络包括:显著物体的多源特征提取模块和图建模模块。
145.显著物体的多源特征提取模块利用对第一训练网络、第二训练网络和第三训练网络的输出进行特征提取。
146.图建模模块,用于对显著物体的多源特征提取模块的输出进行建模处理,实现将图像中的每个对象(例如人物、动物以及植物等)的每种特征为一个节点,用一个对象的多源特征之间两两连接;相邻对象(同一图像中和对象a最近的对象b为相邻)间的对应特征两两相连(例如,语义特征连接语义特征,句法特征连接句法特征等)。
147.基于上述图像和节点的分类损失,更新第四训练网络的所有模型参数,直至第四训练网络的所有模型参数均收敛,在第四训练网络的所有模型参数均收敛的情况下,将第四训练网络,确定为图卷积神经网络。
148.可以基于第五训练网络得到编码解码网络。下面结合图6对第五训练网络进行说明。
149.图6是本发明提供的第五训练网络的结构示意图。如图6所示,第五训练网络包括:特征编码模块、自注意力模块和特征精简模块。
150.特征编码模块包括3个残块(residual block)。
151.特征编码模块的输入为显著对象的多源特征(包括)和gcn训练后的多源特征,输出为q向量、k向量、v向量(q由gcn训练后的多源特征产出,k和v由显著对象的多源特征产出)。
152.自注意力模块包括transformer网络组成,用于计算q向量和k 向量的注意力矩阵,并和v向量进行自注意力操作(attention),得到特征图谱。特征图谱包含了显著性对象的关系和多源特征信息。
153.特征精简模块利用一个全连接层,对自注意力操作后的特征图谱进行降维处理,降低特征的维度(在具体实现中,128维特征可以得到性能和存储的均衡)。
154.可选地,基于敏感内容检测的分类损失对第五训练网络进行训练,直至第五训练网络中的所有模型参数均收敛。将模型参数收敛的自注意力模块和特征精简模块确定为编码解码网络。
155.可选地,可以基于第六训练网络得到哈希编码网络。下面结合图 7对第六训练网络的结构进行说明。
156.图7是本发明提供的第六训练网络的结构示意图。如图7所示,第六训练网络包括:基础特征提取模块和双重注意力(dual attention) 模块。
157.基础特征提取模块的输入为原始浮点数特征,输出为压缩后的 128维浮点数特征。基础特征提取模块包括5层mlp。
158.双重注意力模块的输入为基础特征提取模块的输出,输出为最终的浮点特征。双重注意力模块包括:两个se block和融合子模块。具体的,双重注意力模块中的一个se block基于位置的注意力操作 (position based attention),得到第一浮点数特征,另一个se block 基于渠道的注意力操作(channel based attention),得到第二浮点数特征,融合子模块将第一浮点数特征和第二浮点数特征相加,得到最终的浮点特征。
159.可选地,基于hash损失函数,更新第六训练网络的所有模型参数,在所有模型参数的收敛的情况下,将双重注意力模块确定为哈希编码网络。可选地,hash损失函数可以为常用的量化损失函数或者分类损失函数。需要说明的是,在经过上述训练过程之后,得到的视频检测网络如附图8所示。
160.可选地,可以通过如下方式21和方式22基于目标深度哈希码,确定待处理视频是否为安全视频。
161.方式21,获取预先存储的黑名单,黑名单中包括多个预设深度哈希码,预设深度哈希码对应的视频为非安全视频;若黑名单中存在与目标深度哈希码之间的汉明距离小于或等于预设阈值的预设深度哈希码,则确定待处理视频为非安全视频;若黑名单中不存在与目标深度哈希码之间的汉明距离小于或等于预设阈值的预设深度哈希码,则确定待处理视频为安全视频。
162.方式22,获取预先存储的黑名单,黑名单中包括多个预设深度哈希码,预设深度哈希码对应的视频为非安全视频;若黑名单中存在与目标深度哈希码相同的预设深度哈希码,则确定待处理视频为非安全视频;若黑名单中不存在与目标深度哈希码相同的预设深度哈希码,则确定待处理视频为安全视频。
163.在本发明中,电子设备存储的黑名单内的预设深度哈希码的类型为int8,可以降低对存储的需求量,而且大大降低检索到与目标深度哈希码之间的汉明距离小于或等于预设阈值的预设深度哈希码、或者与目标深度哈希码相同的预设深度哈希码的时长。
164.图8是本发明提供的视频检测网络的流程框图。如图8所示,视频检测网络包括:语义特征提取网络、句法特征提取网络、显著对象检测网络、音频特征提取网络、图卷积神经网络、编码解码网络、哈希编码网络。
165.图8所示的视频检测网络可以对多个预设视频进行处理,得到黑名单中每个预设视频对应的预设深度哈希码。预设深度哈希码的类型为int8。图8所示的视频检测网络还可以对待处理视频进行处理,得到目标深度哈希码。
166.音频特征提取网络包括:语音特征提取网络、多频域重建网络、多频域关系学习网络。音频特征提取网络用于对待处理视频的语音进行音频特征提取,得到音频特征信息。
167.在图8中q表示注意力权重信息,k表示注意力索引信息,v表示词向量信息。
168.下面对本发明提供的视频检测装置进行描述,下文描述的视频检测装置与上文描述的视频检测方法可相互对应参照。
169.图9是本发明提供的视频检测装置的结构示意图。如图9所示,视频检测装置包括:
170.获取模块910,用于获取待处理视频;
171.处理模块920,用于对待处理视频的图像进行视觉特征提取,得到视觉特征信息;
172.处理模块920,还用于对待处理视频的语音进行音频特征提取,得到音频特征信息;
173.处理模块920,还用于基于视觉特征信息和音频特征信息,确定待处理视频是否为安全视频。
174.根据本发明提供的一种视频检测装置,处理模块920具体用于:
175.通过语义特征提取网络,对图像进行语义特征提取,得到视觉语义特征信息;
176.通过句法特征提取网络,对图像进行句法特征提取,得到视觉句法特征信息;
177.通过显著对象检测网络,对图像进行显著对象特征提取,得到显著对象特征信息;
178.视觉特征信息中包括视觉语义特征信息、视觉句法特征信息和显著对象特征信息。
179.根据本发明提供的一种视频检测装置,处理模块920还具体用于:
180.通过语音特征提取网络,对语音进行语音特征提取,得到语音特征信息;
181.通过多频域重建网络,对语音特征信息进行频域特征提取,得到频域特征信息;
182.通过多频域关系学习网络,提取频域特征信息的频域关系特征,得到音频特征信息。
183.根据本发明提供的一种视频检测装置,处理模块920还具体用于:
184.基于视觉特征信息和音频特征信息,确定待处理视频的目标深度哈希码;基于目标深度哈希码,确定待处理视频是否为安全视频。
185.根据本发明提供的一种视频检测装置,处理模块920还具体用于:通过图卷积神经网络,对视觉特征信息和音频特征信息进行处理,得到包括对象关系的视觉语义特征、包括对象关系的视觉句法特征和包括对象关系的听觉特征;对包括对象关系的视觉语义特征、包括对象关系的视觉句法特征和包括对象关系的听觉特征进行多源特征融合处理,得到注意力索引信息和词向量信息;对视觉特征信息中包括的视觉语义特征信息和句法特征提取网络、以及音频特征信息进行多源特征融合处理,得到注意力权重信息;通过编码解码网络,对注意力索引信息、词向量信息和注意力权重信息进行处理,得到待处理视频的编解码结果;通过哈希编码网络,对编解码结果进行哈希编码,得到目标深度哈希码。
186.根据本发明提供的一种视频检测装置,处理模块920还具体用于:获取预先存储的黑名单,黑名单中包括多个预设深度哈希码,预设深度哈希码对应的视频为非安全视频;若黑名单中存在与目标深度哈希码之间的汉明距离小于或等于预设阈值的预设深度哈希码,则确定待处理视频为非安全视频;若黑名单中不存在与目标深度哈希码之间的汉明距离小于或等于预设阈值的预设深度哈希码,则确定待处理视频为安全视频。
187.图10是本发明提供的电子设备的实体结构示意图。如图10所示,该电子设备可以包括:处理器(processor)1010、通信接口 (communications interface)1020、存储器(memory)1030和通信总线 1040,其中,处理器1010,通信接口1020,存储器1030通过通信总线1040完成相互间的通信。处理器1010可以调用存储器1030中的逻辑指令,以执行视频检测方法,该方法包括:获取待处理视频;对待处理视频的图像进行视觉特征提取,得到视觉特征信息;对待处理视频的语音进行音频特征提取,得到音频特征信息;基于视觉特征信息和音频特征信息,确定待处理视频是否为安全视频。
188.此外,上述的存储器1030中的逻辑指令可以通过软件功能单元的形式实现并作为独立的产品销售或使用时,可以存储在一个计算机可读取存储介质中。基于这样的理解,本发明的技术方案本质上或者说对现有技术做出贡献的部分或者该技术方案的部分可以以
软件产品的形式体现出来,该计算机软件产品存储在一个存储介质中,包括若干指令用以使得一台计算机设备(可以是个人计算机,服务器,或者网络设备等)执行本发明各个实施例方法的全部或部分步骤。而前述的存储介质包括:u盘、移动硬盘、只读存储器(rom,read-onlymemory)、随机存取存储器(ram,random access memory)、磁碟或者光盘等各种可以存储程序代码的介质。
189.另一方面,本发明还提供一种计算机程序产品,计算机程序产品包括计算机程序,计算机程序可存储在非暂态计算机可读存储介质上,计算机程序被处理器执行时,计算机能够执行上述各方法所提供的视频检测方法,该方法包括:获取待处理视频;对待处理视频的图像进行视觉特征提取,得到视觉特征信息;对待处理视频的语音进行音频特征提取,得到音频特征信息;基于视觉特征信息和音频特征信息,确定待处理视频是否为安全视频。
190.又一方面,本发明还提供一种非暂态计算机可读存储介质,其上存储有计算机程序,该计算机程序被处理器执行时实现以执行上述各方法提供的视频检测方法,该方法包括:获取待处理视频;对待处理视频的图像进行视觉特征提取,得到视觉特征信息;对待处理视频的语音进行音频特征提取,得到音频特征信息;基于视觉特征信息和音频特征信息,确定待处理视频是否为安全视频。
191.以上所描述的装置实施例仅仅是示意性的,其中作为分离部件说明的单元可以是或者也可以不是物理上分开的,作为单元显示的部件可以是或者也可以不是物理单元,即可以位于一个地方,或者也可以分布到多个网络单元上。可以根据实际的需要选择其中的部分或者全部模块来实现本实施例方案的目的。本领域普通技术人员在不付出创造性的劳动的情况下,即可以理解并实施。
192.通过以上的实施方式的描述,本领域的技术人员可以清楚地了解到各实施方式可借助软件加必需的通用硬件平台的方式来实现,当然也可以通过硬件。基于这样的理解,上述技术方案本质上或者说对现有技术做出贡献的部分可以以软件产品的形式体现出来,该计算机软件产品可以存储在计算机可读存储介质中,如rom/ram、磁碟、光盘等,包括若干指令用以使得一台计算机设备(可以是个人计算机,服务器,或者网络设备等)执行各个实施例或者实施例的某些部分的方法。
193.本发明在实施上不受限于硬件平台以及编程语言的限制,使用常用的编程语言,例如c语言、c++或者python,都可以实现本发明所描述的方法,并得到预期的效果。在以下的具体实施例中,本方法将提供一种具体的实现环境,作为参考,在实际应用中,可根据具体的应用场景进行灵活调整。在具体实施例中,本发明采用一台包括 3.1ghz128核中央处理器和256gb内存的服务器。本发明涉及到的训练和视频检测方法,均在上述服务器搭载的8块nvidia tesla v100 gpu上完成处理。在gpu上,本发明采用pytorch作为软件平台,进行具体功能的开发和实现。
194.最后应说明的是:以上实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的精神和范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1