一种模型管理方法及相关设备与流程
本技术涉及人工智能(artificial intelligence),尤其涉及一种模型管理方法、系统、计算设备集群、计算机可读存储介质、计算机程序产品。
背景技术:
1、在进行软件开发时,软件开发商通常采用持续集成/持续交付(continuousintegration/continuous delivery,ci/cd)方式开发大规模软件,以缩短开发周期、提高部署速度、实现可靠发布。
2、ci,也称作持续整合,属于一种软件工程流程,具体是指将所有开发人员的工作副本集成到共享主线上,保障软件版本在多人协作的情况下的持续演进。cd,属于一种软件工程手法,具体是让软件的产出过程在一个短周期内完成,以保证软件可以稳定、持续的保持在随时可以释出的状况,也即开发团队在短周期内生产软件,并可以随时可靠地发布软件,而且无需手动发布,实现以更快的速度和频率构建、测试和发布软件。
3、随着人工智能(artificial intelligence)尤其是机器学习(machine learning,ml)技术的不断发展,产生了基于ai模型(例如是ml模型,为了描述方便,也可以简称为模型)的软件。在部署基于ai模型的软件时,由于业务负载在不断演变,数据分布可能发生明显的变化,进而导致ai模型退化。为此,可以跟踪数据的实时统计信息并监控ai模型的在线性能,以便基于ai模型的软件与预期不符时,触发模型自动训练或回滚。上述过程也称作持续训练(continuous training,ct)。
4、业界提出将上述ct流程融入ci/cd流程,以缩短基于ai模型的软件的开发周期。然而,ai模型的运营可能会持续较长时间,在这漫长的时间内,如果训练ai模型的人员发生变动,可以导致难以打开或重构已有ai模型,进而对基于ai模型的软件的ci流程产生影响。重新训练ai模型则又需要耗费大量的人力与时间成本,难以满足业务的需求。
技术实现思路
1、本技术提供了一种模型管理方法,该方法通过将新模型与旧模型结合进行场景交付,具体是将旧模型和新模型的推理结果进行集成,避免对旧模型的机理研究,减少ai黑盒对可持续工作的影响。如此规避了模型库回退或者以新换旧等“替换”方案,可以最大限度地保有旧模型的学习能力,从而减少新模型学习的代价,降低集成、交付的难度。本技术还提供了对应的模型管理系统、计算设备集群、计算机可读存储介质以及计算机程序产品。
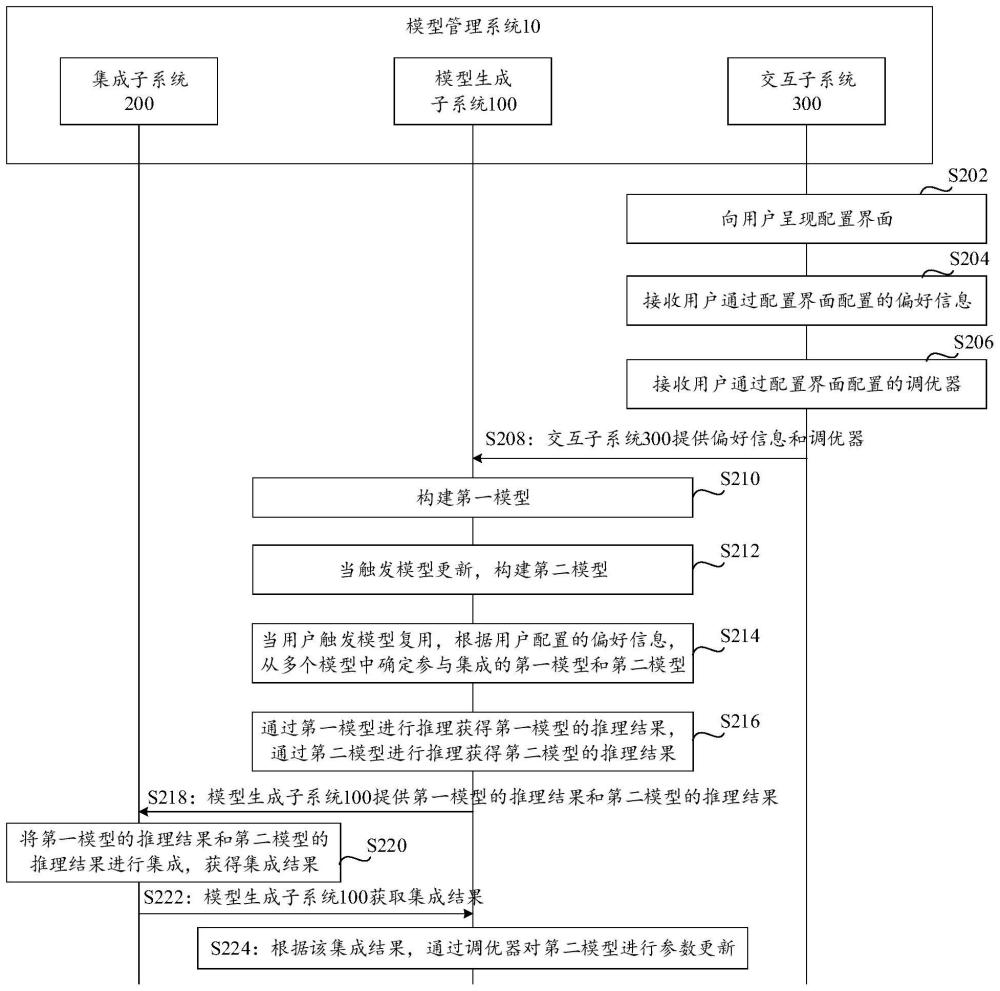
2、第一方面,本技术提供一种模型管理方法。该方法可以由模型管理系统执行。模型管理系统可以是软件系统,该软件系统可以部署在计算设备集群中,计算设备集群通过执行软件系统的程序代码,以执行本技术实施例的模型管理方法。模型管理系统也可以是硬件系统,该硬件系统运行时,执行本技术实施例的模型管理方法。在一些示例中,该硬件系统可以是具有模型管理功能的计算设备集群。
3、具体地,模型管理系统可以确定第一模型和第二模型,第一模型为触发模型更新前的模型,也称作旧模型,第二模型为触发模型更新后的模型,也称作新模型,该第一模型和第二模型为参与集成的模型,然后模型管理系统可以通过第一模型进行推理获得第一模型的推理结果,以及通过第二模型进行推理获得第二模型的推理结果,接着模型管理系统将第一模型的推理结果和第二模型的推理结果进行集成,获得集成结果。
4、在该方法中,模型管理系统复用旧模型,将旧模型的推理结果与新模型的推理结果集成,从而将新模型与旧模型结合进行场景交付,避免对旧模型的机理研究,减少ai黑盒对可持续工作的影响。而且,该方法规避了模型库回退或者以新换旧等“替换”方案,可以最大限度地保有旧模型的学习能力,从而减少新模型学习的代价,降低集成、交付的难度
5、在一些可能的实现方式中,第一模型为根据原始数据集训练的模型,第二模型为以下模型中的任意一种或多种:根据原始数据集重新训练的模型,根据增量数据集增量训练的模型,根据原始数据集和增量数据集全量训练的模型,根据增量数据集使用自动机器学习算法训练的模型,或者根据原始数据集和增量数据集使用自动机器学习算法训练的模型。
6、其中,全量训练是指利用原始数据集和增量数据集形成的全量数据集从头开始训练,全量训练可以充分利用数据集中的各个样本数据,使得训练好的模型能够具有较好的效果。增量训练,也称作增量学习,是指在不需要访问已经用于训练的原始数据集的情况下,保留已经学习的知识,利用增量数据集中的样本数据学习新的知识。增量训练可以有效解决灾难性遗忘问题(具体是一些ai模型在新任务上训练时,在旧任务上的表现显著下降的问题),并且具有较高的训练效率。
7、在一些可能的实现方式中,模型管理系统可以通过多种方式实现对推理结果的集成。例如,模型管理系统可以通过集成规则将所述第一模型的推理结果和所述第二模型的推理结果进行集成,获得集成结果。又例如,模型管理系统可以通过机器学习(machinelearning,ml)模型将第一模型的推理结果和第二模型的推理结果进行集成,获得集成结果。还例如,模型管理系统可以通过自动机器学习模型将第一模型的推理结果和第二模型的推理结果进行集成,获得集成结果。
8、在该方法中,模型管理系统可以根据业务需求选择合适的集成方式对推理结果进行集成。其中,采用集成规则进行集成的计算量较小,集成效率较高。采用ml模型进行集成,能够充分挖掘各模型的推理结果的内在关系,具有较好的集成效果。采用自动机器学习模型进行集成,可以减少人工参与,进一步降低人力成本。
9、在一些可能的实现方式中,集成规则包括加权运算、求最大值、求最小值或基于更新时间的集成规则。加权运算也称作加权投票,通过设置不同ai模型的推理结果的权重,然后通过加权求和或加权求平均值等加权运算对推理结果进行集成,相较于求算术平均值等方式,该方法能够考虑不同推理模型的推理结果的重要程度,由此获得的集成结果更加精准。求最大值、求最小值是指从不同模型的推理结果中选择最大值或最小值,对于一些业务场景,求最大值或最小值的集成方式更符合业务需求。基于更新时间的集成规则是指根据ai模型的更新时间,选择符合条件的模型进行集成。如此可以减少参与集成的ai模型的数量,降低运营成本。
10、在一些可能的实现方式中,ml模型包括神经网络模型、支持向量机(supportvector machine,svm)模型或者回归模型中的一种或多种。针对不同的业务,模型管理系统支持通过与该业务适配的ml模型对推理结果进行集成,可以使得针对不同业务均能获得较好的集成效果。
11、在一些可能的实现方式中,模型管理系统还可以向用户呈现配置界面,然后接收用户通过配置界面配置的偏好信息。偏好信息用于指示用户对参与集成的ai模型的偏好。相应地,模型管理系统可以根据偏好信息,从多个模型中确定参与集成的第一模型和第二模型。
12、如此,可以减少模型运维过程中参与集成的ai模型的数量,降低资源消耗,进而降低模型运维成本。
13、在一些可能的实现方式中,所述偏好信息包括:计算引擎偏好、模型数目偏好、模型类型偏好或者硬件偏好中的一种或多种。其中,计算引擎可以包括但不限于spark、flink、tensorflow、python。计算引擎偏好例如可以是flink优先或spark优先。模型类型偏好可以是小模型优先、ml模型优先。硬件偏好是指对运行模型的硬件类型的偏好,例如可以为中央处理器(central processing unit,cpu)优先。
14、该方法通过设置偏好信息,一方面可以筛选参与集成的ai模型,进而达到降低运维成本的目的,另一方面可以解决同一业务存在多个异构模型导致的模型管理系统复杂化和高成本的问题。
15、在一些可能的实现方式中,模型管理系统还可以接收用户通过配置界面配置的调优器。相应地,模型管理系统可以通过该调优器对第二模型进行参数更新。由于不同架构或不同类型的ai模型可以采用不同调优器进行参数更新,该方法通过对参与集成的第二模型配置相应的调优器,可以加快训练效率。
16、在一些可能的实现方式中,第一模型为规则模型、机器学习模型或者自动机器学习模型,第二模型为规则模型、机器学习模型或者自动机器学习模型。其中,规则模型是指专家规则模型,规则模型通过专家定义的规则进行决策、推理。
17、该方法支持对不同类型或结构的模型的推理结果进行集成,具有较高可用性,而且,第一模型和第二模型均可以采用自动机器学习模型,通过两层自动机器学习机制,一层用于构建模型,一层用于学习集成策略,然后交替优化,可以获得较好的性能,并且全程无需人工参与。即使原有ai人员离职或者无专职的ai人员,也能够实现ai模型的演进,无需重新训练ai模型,大幅降低时间和人力成本。
18、在一些可能的实现方式中,模型管理系统还可以在用户触发模型复用时,确定第一模型和第二模型。也就是说,通常情况下模型管理系统可以采用传统的模型库回退或者以新换旧等“替换”方案,当用户触发模型复用时,启用本技术复用旧模型的方案,将旧模型的推理结果和新模型的推理结果进行集成交付。
19、如此可以实现按需提供旧模型复用功能,能够满足个性化的需求,例如能够实现按需付费。
20、在一些可能的实现方式中,模型管理系统可以提供模型管理接口,该模型管理接口可以为标准化的应用程序编程接口(application programming interface,api),该模型管理接口可以封装本技术的模型管理方法。当该模型管理接口被调用时,例如模型管理系统接收到针对该模型管理接口的接口调用请求,模型管理系统可以确定第一模型和第二模型,通过第一模型和第二模型分别进行推理,然后将第一模型的推理结果和第二模型的推理结果进行集成。
21、该方法中,模型管理系统通过将模型管理方法进行封装,并以统一的模型管理接口对外提供服务,一方面提高了可用性,另一方面可以使得模型管理的机制对外保密,攻击者很难基于模型管理的机制发起攻击,保障了服务的稳定性。
22、在一些可能的实现方式中,模型管理系统还可以获取历史时间段参与集成的ai模型的特征,如历史时间段参与集成的ai模型的类型、ai模型所使用的计算引擎、运行ai模型的硬件类型等,根据历史时间段参与集成的ai模型的特征确定推荐配置信息,该推荐配置信息可以包括推荐的偏好信息。然后模型管理系统可以向用户呈现该推荐配置信息。如此可以为用户配置偏好信息,筛选参与集成的ai模型提供参考。
23、第二方面,本技术提供一种模型管理系统。所述系统包括:
24、确定模块,用于确定第一模型和第二模型,所述第一模型为触发模型更新前的模型,所述第二模型为触发模型更新后的模型;
25、推理模块,用于通过所述第一模型进行推理获得所述第一模型的推理结果,以及通过所述第二模型进行推理获得所述第二模型的推理结果;
26、集成模块,用于将所述第一模型的推理结果和所述第二模型的推理结果进行集成,获得集成结果。
27、在一些可能的实现方式中,所述第一模型为根据原始数据集训练的模型,所述第二模型为以下模型中的任意一种或多种:
28、根据所述原始数据集重新训练的模型;或者,
29、根据增量数据集增量训练的模型;或者,
30、根据所述原始数据集和所述增量数据集全量训练的模型;或者,
31、根据所述增量数据集使用自动机器学习算法训练的模型;或者,
32、根据所述原始数据集和所述增量数据集使用自动机器学习算法训练的模型。
33、在一些可能的实现方式中,所述集成模块具体用于:
34、通过集成规则将所述第一模型的推理结果和所述第二模型的推理结果进行集成,获得集成结果;或者,
35、通过机器学习ml模型将所述第一模型的推理结果和所述第二模型的推理结果进行集成,获得集成结果;或者,
36、通过自动机器学习模型将所述第一模型的推理结果和所述第二模型的推理结果进行集成,获得集成结果。
37、在一些可能的实现方式中,所述集成规则包括加权运算、求最大值、求最小值或基于更新时间的集成规则,所述ml模型包括神经网络模型、支持向量机svm模型或者回归模型中的一种或多种。
38、在一些可能的实现方式中,所述系统还包括:
39、交互模块,用于向用户呈现配置界面,接收用户通过所述配置界面配置的偏好信息;
40、所述确定模块具体用于:
41、根据所述偏好信息,从多个模型中确定所述第一模型和所述第二模型。
42、在一些可能的实现方式中,所述偏好信息包括:
43、计算引擎偏好、模型数目偏好、模型类型偏好或者硬件偏好中的一种或多种。
44、在一些可能的实现方式中,所述交互模块还用于:
45、接收所述用户通过配置界面配置的调优器;
46、所述系统还包括:
47、参数更新模块,用于通过所述调优器对所述第二模型进行参数更新。
48、在一些可能的实现方式中,所述第一模型为规则模型、机器学习模型或者自动机器学习模型,所述第二模型为规则模型、机器学习模型或者自动机器学习模型。
49、在一些可能的实现方式中,所述确定模块具体用于:
50、当用户触发模型复用时,确定第一模型和第二模型。
51、第三方面,本技术提供一种计算设备集群。所述计算设备集群包括至少一台计算设备,所述至少一台计算设备包括至少一个处理器和至少一个存储器。所述至少一个处理器、所述至少一个存储器进行相互的通信。所述至少一个处理器用于执行所述至少一个存储器中存储的指令,以使得计算设备或计算设备集群执行如第一方面或第一方面的任一种实现方式所述的模型管理方法。
52、第四方面,本技术提供一种计算机可读存储介质,所述计算机可读存储介质中存储有指令,所述指令指示计算设备或计算设备集群执行上述第一方面或第一方面的任一种实现方式所述的模型管理方法。
53、第五方面,本技术提供了一种包含指令的计算机程序产品,当其在计算设备或计算设备集群上运行时,使得计算设备或计算设备集群执行上述第一方面或第一方面的任一种实现方式所述的模型管理方法。
54、本技术在上述各方面提供的实现方式的基础上,还可以进行进一步组合以提供更多实现方式。
- 还没有人留言评论。精彩留言会获得点赞!