基于样本驱动目标损失函数优化的鲁棒神经网络训练方法
1.本发明涉及深度学习领域,具体涉及一种基于样本驱动目标损失函数优化的鲁棒神经网络训练方法。
背景技术:
2.随着深度学习技术在计算机视觉领域不断取得进展,人工智能系统正被广泛应用于自动驾驶和人脸识别等场景。人工智能在这些重大安全领域下的应用,使得人们迫切需要了解神经网络的鲁棒性。众所周知深度神经网络并不鲁棒,即便是难以察觉的扰动也能使神经网络做出错误的预测。然而,大多数防御方法的鲁棒性提升无法得到证明,因此往往会被更强大的攻击打破。
3.为了克服上述的困难,已经有许多研究者提出使用形式化验证技术如ibp和crown-ibp,用于训练可证明鲁棒的神经网络。给定一个扰动范围,可证明鲁棒的训练方法可以通过验证技术计算出鲁棒边界,并将其最小化以训练出一个可证明鲁棒的模型。然而目前的训练方式却导致模型准确性出现大幅下降。所以,如何高效地训练拥有更好准确性与鲁棒性的深度神经网络是一个亟待解决的问题。
技术实现要素:
4.本发明的目的在于提供一种基于样本驱动目标函数优化的鲁棒神经网络训练方法,缓解了鲁棒神经网络训练领域存在的神经网络模型准确性大幅降低等问题。
5.实现本发明目的的具体技术方案如下:
6.一种基于样本驱动目标函数优化的鲁棒神经网络训练方法,在训练过程中对于识别正确的未干扰样本采用常规鲁棒性训练方法处理;而对于识别错误的未干扰样本,希望未干扰样本及其对抗样本经过神经网络后的概率分布更相近。通过引导神经网络在提高对于未干扰样本的准确率的基础之上,再使神经网络分类器朝着更鲁棒的方向更新参数。该方法包括以下步骤:
7.首先给定一个深度神经网络模型;给定一个训练集和一个扰动大小;
8.设定初始超参数,包括学习率、学习率衰减率、最大训练周期、学习率衰减的周期、准确性与鲁棒性目标占比变化;
9.每个周期根据目前训练周期数更新超参数;
10.训练时使用的扰动范围从0逐渐增加至扰动大小;
11.训练时输入一个批次的训练样本及其标签;
12.根据输入样本和扰动大小,使用ibp或crown-ibp的神经网络鲁棒性验证技术计算神经网络对于每个输入的输出边界,即模型对于该输入的每个分类的预测概率的上下界;
13.若该批次训练样本识别正确,则设立一个鲁棒的损失函数来反向传播进行模型参数的更新,其中,y
true
代表该输入的正确标签;代表在扰动下的预测
概率,对于正确标签概率取最低预测值,其余标签概率取最高预测值;
14.若该批次训练样本识别错误,则使用所述ibp或crown-ibp的神经网络鲁棒性验证技术
[0015][0016]
验证所述训练样本是否满足鲁棒性的性质,即正确标签概率的最低预测值大于其余标签概率取最高预测值;
[0017]
若所述模型对于所述训练样本满足鲁棒性性质,则设定一个保持识别一致的kl散度损失函数其中,p(x,θ)代表所述训练样本经过所述模型输出的概率分布,代表所述训练样本的对抗样本经过所述模型输出的概率分布,kl散度损失函数表示两者的差异性;通过kl散度损失函数反向传播进行模型参数的更新,使干扰前后的样本通过所述模型后的输出分布保持一致;
[0018]
若所述模型对于该样本不满足鲁棒性性质,则设定一个准确性与鲁棒性的共同目标的损失函数通过该损失函数反向传播更新模型,使所述模型朝着鲁棒性与准确性方向更新参数;
[0019]
根据对训练样本的测试与验证,在每个周期,每个样本根据不同的识别与鲁棒验证结果选用对应的损失函数反向传播进行所述模型参数的更新;
[0020]
使用所述ibp或crown-ibp的神经网络鲁棒性验证技术对所述模型进行鲁棒性性质的测试;
[0021]
最后保存鲁棒性最好的模型。
[0022]
在训练样本驱动目标函数优化的鲁棒神经网络训练方法中,首先在训练深度神经网络时使用近似的验证技术ibp技术,快速计算鲁棒性边界,并在训练过程中根据样本不同的测试与验证结果选择对于的损失函数目标;
[0023]
提供训练集和最大扰动距离的情况下,在训练集上使用ibp验证欠训练网络;
[0024]
根据训练样本的验证结果选择有利于模型鲁棒的损失函数目标。
[0025]
对神经网络模型识别正确与错误训练样本进行对应处理,根据设定的对应的损失函数目标使模型达到鲁棒的目的。在不影响训练效率的前提下,提高训练鲁棒深度神经网络模型的准确性与鲁棒性。
[0026]
综上所述,由于采用了上述技术方案,本发明的有益效果是:
[0027]
(1)本发明根据训练样本的识别和ibp的鲁棒验证结果设置合理的鲁棒目标。实验表明,本发明的训练方法缓解了鲁棒训练带来的标准准确率降低的问题,同时也能获得更鲁棒的模型;
[0028]
(2)本发明引入了基于增加鲁棒边界的加速交叉熵损失函数,缓解了应用形式化验证技术于鲁棒训练存在的缺陷而导致的不收敛的问题,并与普通损失函数进行实验比较。
[0029]
(3)本发明能够与目前最先进的鲁棒神经网络训练工具集成融合,额外提升深度神经网络模型鲁棒性与准确性。
附图说明
[0030]
图1是本发明的流程示意图;
[0031]
图2是本发明流程图中选择对应损失函数的流程图;
[0032]
图3是本发明流程图中选择对应损失函数的伪代码图;
[0033]
图4是本发明实施例中用于ibp鲁棒训练的全连接层定义图;
[0034]
图5是本发明实施例中用于ibp鲁棒训练的卷积层定义图;
[0035]
图6是本发明实施例的神经网络结构定义图;
[0036]
图7是本发明ibp验证器代码图;
[0037]
图8是本发明实施例中原始训练方法验证结果图;
[0038]
图9是本发明实施例中使用基于样本驱动目标损失函数优化的鲁棒神经网络训练方法验证结果图。
具体实施方式
[0039]
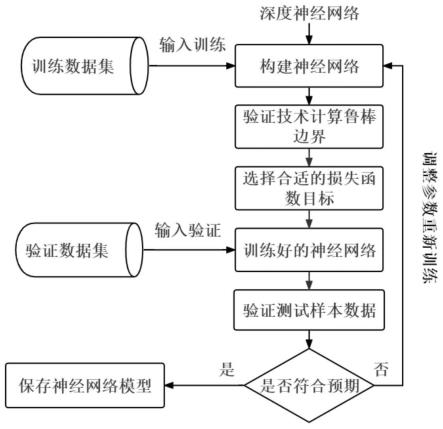
参阅图1,本发明具体包括:给定一个深度神经网络,一个训练集和一个扰动范围,输出一个使用ibp或crown-ibp验证技术计算出的测试集的验证准确率并保存这个鲁棒的模型。
[0040]
参阅图2-3,图3所示(算法1),首先给定一个深度神经网络模型,使用本发明重新对模型结构进行构建,以便能够将如ibp或crown-ibp的神经网络鲁棒性验证技术用于训练鲁棒神经网络模型。
[0041]
给定一个训练集和一个扰动大小;
[0042]
设定初始超参数,包括学习率、学习率衰减率、最大训练周期、学习率衰减的周期、准确性与鲁棒性目标占比变化的参数等;
[0043]
第一个for循环的次数代表最大训练周期。在每个训练周期中,训练扰动半径从0逐渐提升,之后再第二个for循环每次从训练数据集中取出批量的数据。
[0044]
在该循环中,若当前该模型对于取出的训练样本识别正确(图3第7行),则使用ibp或crown-ibp验证器计算出的鲁棒边界用作损失函数(图3第8行),以常规的鲁棒目标更新模型参数。
[0045]
若模型对于样本识别错误,那么它将调用ibp或crown-ibp验证技术计算神经网络对于每个输入的输出边界,并以此来检查神经网络模型对于该样本是否具有鲁棒性。
[0046]
ibp或crown-ibp验证器将深度神经网络输入,训练扰动半径和正确标签,并得到鲁棒验证结果输出正确或错误。
[0047]
如果ibp或crown-ibp验证器返回错误,即模型在扰动下对于该样本不鲁棒且对未干扰样本识别错误,则将不会设定鲁棒的目标,而是通过kl散度模型对于干扰前后的样本的输出概率分布,并以保持一致为目标反向传播更新参数(图3第12行),让扰动后的样本经过模型得到的概率分布与原样本经过模型的概率分布更相近;
[0048]
如果ibp或crown-ibp验证器返回正确,那么则代表模型识别错误但对于扰动前后判断是一致的。此时以扰动前后的准确性均作为目标反向传播更新参数(图3第10行)。
[0049]
每一个周期结束后,测试模型对于测试集的准确性,并使用ibp或crown-ibp验证器测试模型对于测试集的鲁棒性,记录模型的标准准确率与鲁棒准确率;
[0050]
最后,保存目前鲁棒准确率最高的模型。
[0051]
实施例
[0052]
为了能够将ibp验证用于鲁棒训练,首先在pytorch深度学习框架下定义用于鲁棒训练的全连接层与卷积层,如图4、图5所示,其中robustlinear(全连接层)主要的参数名称包括in_features(输入层大小),out_features(输出层大小),weights(权重矩阵),bias(偏置),input_p(输入的上界),input_n(输入的下界)、output_p(输出的上界)和output_n(输出的下界)。robustconv2d(卷积层)包含的参数比robustlinear更多一些,主要包括kernal_size(卷积核大小)、padding(填充值大小)、stride(步长大小)等;
[0053]
给定一个神经网络结构,其主要由两层卷积核、两层全连接和relu激活函数所组成。设定每批次的训练样本batch_size(批次数量)为200,epoch(周期)为1200轮,kernal_size(卷积核大小)为4*4,filter(过滤器)数量分别为16和32,模型结构具体参数如图6所示;
[0054]
选用cifar-10数据集。设置每个模型训练1200个周期,固定50个周期热身。测试扰动为2/255,另外设置训练扰动为测试扰动的1.1倍来训练模型。在第50个到第600个周期使用加速时间表将扰动训练扰动从0增加到最大值;初始学习率为0.005,并在第1100个周期和第1150个周期后均衰减为原来的0.1倍;
[0055]
使用加速交叉熵(bce)作为损失类型,其定义如下所示:
[0056][0057]
其中f(x,∈)代表样本和扰动经过模型得到的所有标签的预测概率,y
true
代表真实标签,p代表模型对于某一个标签的预测概率;
[0058]
每个周期取批次训练样本检测识别正确与否并使用ibp验证器对其验证,验证代码如图7所示;
[0059]
若当前该模型对于取出的训练样本识别正确,则算法使用ibp验证器计算出的鲁棒边界用作损失函数以常规的鲁棒目标更新模型参数;
[0060]
若模型对于样本识别错误,那么它将调用ibp验证技术计算神经网络对于每个输入的输出边界,并以此来检查神经网络模型对于该样本是否具有鲁棒性。
[0061]
ibp验证器将深度神经网络,输入,训练扰动半径和正确标签,并得到鲁棒验证结果输出正确或错误;
[0062]
如果ibp验证器返回错误,即模型在扰动下对于该样本不鲁棒且对未干扰样本识别错误,则算法将不会设定鲁棒的目标,而是通过kl散度损失函数模型对于干扰前后的样本的输出概率分布,并以保持一致为目标反向传播更新参数,让扰动后的样本经过模型得到的概率分布与原样本经过模型的概率分布更相近;
[0063]
如果ibp验证器返回正确,那么则代表模型识别错误但对于扰动前后判断是一致的。此时算法以扰动前后的准确性均作为目标反向传
播更新参数。
[0064]
记录每个周期训练得到模型的鲁棒准确率;
[0065]
最后保存鲁棒性最好的模型。
[0066]
原始方法的模型测试结果对比如图8所示,基于样本驱动目标损失函数优化的鲁棒神经网络训练方法在相同超参数下的模型测试结果如图9所示。
[0067]
总而言之,方法的思想可以概括为如下:在训练过程中设定了检测器,训练时对于识别正确的未干扰样本采用常规鲁棒性训练方法处理;而对于识别错误的未干扰样本,希望未干扰样本及其对抗样本经过神经网络后的概率分布更相近。通过检测器引导神经网络在提高对于未干扰样本的准确率的基础之上,再使神经网络分类器朝着更鲁棒的方向更新参数。本方法在提升了标准准确率的同时又能够提升鲁棒准确率。
[0068]
以上所述,仅为本发明的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,可轻易想到变化或替换,都应涵盖在本发明的保护范围之内。因此,本发明的保护范围应所述以权利要求的保护范围为准。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1