一种全域流场的流线并行抽稀方法及系统与流程
1.本发明属于流体力学流动中流动显示技术领域,尤其涉及一种全域流场的流线并行抽稀方法及系统。
背景技术:
2.计算流体力学广泛应用在桥梁,超高建筑,汽车和飞机设计、天气预报和气候建模、自然灾害(如地震、飓风、龙卷风)模拟等方面,会产生大量的以速度为基础物理量的矢量场数据,通过对这些数据的分析和可视化,探索内在的物理流动现象,可以指导我们进一步的实现工程优化。流场可视化技术使我们能够直观地获得定性和定量的流动信息,是领域专家非常依赖的一种重要的手段,也是科学可视化的重要研究内容之一。近年来,随着计算能力的提高以及对越来越复杂的流体流动进行仿真分析的要求,流场规模越来越大,各种不同分辨率的流场分析需求也与日俱增,各种原位可视化技术也被广泛应用。
3.全域流场是与局部流场相对应的一个概念,它强调了流体所经过的空间或地域分布广,流体流动规律复杂且连续,例如洋流分布,飞行器在飞越群山时出现的气流等。流线是一种广泛使用的可视化技术,用于理解、验证和探索流体流动规律。它的主要挑战之一是如何选择和生成流线。使用大量的流线会导致视觉遮挡和杂乱,而使用少量的流线则可能导致遗漏流动现象的关键特征。
4.全域流动特征的多样化细节描述的需求与视觉展示(杂乱与遮挡)约束之间的矛盾催生了多层次和多分辨率流场可视化的研究。分层次分析基于对空间区域的递归分解或区域划分实现,以充分展示重要的流动特征,减少视觉杂乱和遮挡。多分辨率与多尺度的内涵基本一致。对同一流场区域采用不同分辨率或不同尺度表达,反映了对对象的认知的精度、深度与广度,会出现信息的变化。最典型的就是湍流的多尺度分析,不同尺度下湍流呈现出不同的形状与特征。
5.流线的多分辨率可视化是在全域流场的多层次细节分析场景下,根据视口调整和用户关注敏感区域的变化,动态调整所显示的流线(包括它们之间的间距,总数量以及它们的采样精度),以支持实时分析和渲染。
6.目前的多分辨率流线可视化仅关注了流线的间距及数量上的变化,而对流线的采样精度的多分辨率方面很少关注。虽然经典的各类高阶龙格库塔流线生成中考虑了采样精度,并提出自适应步长的流线生成方法,但它主要考虑积分过程与实际流场值的误差,而没有考虑多分辨率可视化的需求,导致每条流线产生巨量的采样点,在不同分辨率的可视化场景下,很多采样点不是必要的,影响基于流线的实时渲染性能并产生不必要的海量存储开销。
技术实现要素:
7.本发明解决的技术问题是:克服现有技术的不足,提供了一种全域流场的流线并行抽稀方法及系统,首次实现了流线抽稀,减少流线采样点数据而保证对流动现象的精确
描述,消除了流线可能存在的相交现象,缓解采样点分布不均衡现象,显著降低其存储开销和渲染时间开销,支持大规模多分辨率流线可视化需要。
8.本发明目的通过以下技术方案予以实现:一种全域流场的流线并行抽稀方法,包括:生成流线集;对流线集中的所有流线进行分段得到流线段;以每个流线段为单位,利用并行d-p算法进行抽稀处理得到抽稀处理后流线段;利用修补算法处理抽稀处理后流线段中相交线段。
9.上述全域流场的流线并行抽稀方法中,使用rk45算法生成流线集。
10.上述全域流场的流线并行抽稀方法中,使用rk45算法生成流线集包括如下步骤:
11.步骤s1:读入种子点坐标值,通过插值函数获取该种子点的速度矢量,记为采样点;
12.步骤s2:使用rk45积分算法,依据前一个采样点坐标,计算积分参数;
13.步骤s3:计算积分参数的加权平均值即为流线的下一个采样点的位置;
14.步骤s4:计算积分误差;
15.步骤s5:如果积分误差大于预设参数,则调整时间步长并重复步骤s2至步骤s4;如果积分误差不小于预设参数,则获得一个新采样点;
16.步骤s6:如果对于流线的采样点数量小于总的种子点格式且新采样点还在流场区域范围内,则以此新采样点数据更新,并重复步骤s2至步骤s5,计算下一个采样点;否则,转到步骤s7;
17.步骤s7:如果种子点集合中还有没有使用的种子点,提取一个新的种子点,并跳转到步骤s1;否则,流程结束。
18.上述全域流场的流线并行抽稀方法中,对流线集中的所有流线进行分段得到流线段包括:计算每个流线中的每个采样点的曲率,然后计算该采样点与前后两个采样点的差异并求平均,得到每个采样点的曲率差;若某个采样点的曲率差大于预设阈值,则该采样点为分割点。
19.上述全域流场的流线并行抽稀方法中,在并行d-p算法中,至少有2个线程束,其中有一个专门的线程束作为管理者,其他的线程束作为工作者;其中,管理者线程束用于读取流线段信息,各个流线分段之间是独立处理的,避免了流线采样点差异引起的工作量不平衡;每个工作线者程束处理一个流线段。
20.上述全域流场的流线并行抽稀方法中,利用修补算法处理抽稀处理后流线段中相交线段包括:如果线段ab与线段cd判定为相交,则求出交点p,然后取其中一条线段ab所在的流线分段,找到距离p点最近的采样点q,形成2 个线段,即线段aq与线段qb,取代原有线段ab。
21.一种全域流场的流线并行抽稀系统,包括:第一模块,用于生成流线集;第二模块,用于对流线集中的所有流线进行分段得到流线段;第三模块,用于以每个流线段为单位,利用并行d-p算法进行抽稀处理得到抽稀处理后流线段;第四模块,用于利用修补算法处理抽稀处理后流线段中相交线段。
22.上述全域流场的流线并行抽稀系统中,使用rk45算法生成流线集。
23.上述全域流场的流线并行抽稀系统中,对流线集中的所有流线进行分段得到流线段包括:计算每个流线中的每个采样点的曲率,然后计算该采样点与前后两个采样点的差
异并求平均,得到每个采样点的曲率差;若某个采样点的曲率差大于预设阈值,则该采样点为分割点。
24.上述全域流场的流线并行抽稀系统中,在并行d-p算法中,至少有2个线程束,其中有一个专门的线程束作为管理者,其他的线程束作为工作者;其中,管理者线程束用于读取流线段信息,各个流线分段之间是独立处理的,避免了流线采样点差异引起的工作量不平衡;每个工作线者程束处理一个流线段。
25.本发明与现有技术相比具有如下有益效果:
26.(1)本发明首次实现了流线抽稀,减少流线采样点数据而保证对流动现象的精确描述;
27.(2)本发明消除了流线可能存在的相交现象,缓解采样点分布不均衡现象;
28.(3)本发明显著降低其存储开销和渲染时间开销,支持大规模多分辨率流线可视化需要。
附图说明
29.通过阅读下文优选实施方式的详细描述,各种其他的优点和益处对于本领域普通技术人员将变得清楚明了。附图仅用于示出优选实施方式的目的,而并不认为是对本发明的限制。而且在整个附图中,用相同的参考符号表示相同的部件。在附图中:
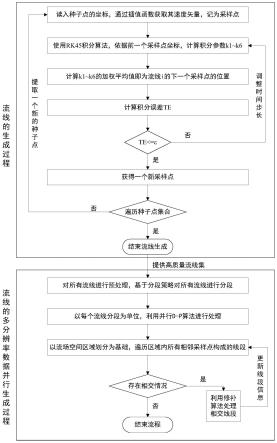
30.图1为本发明的全域流场流线并行抽稀方法流程图;
31.图2(a)为一条流线依据采样点的曲率差进行分段的示意图;
32.图2(b)为一条流线依据采样点的曲率差进行分段的示意图;
33.图3为基于warp-specialization技术的并行d-p算法示意图;
34.图4为相交线段的修补过程示意图;
35.图5为并行d-p算法对boussinesq2d流场执行抽稀+修补后的效果图;
36.图6为并行d-p算法对jungtelziemniak2d流场执行抽稀+修补后的效果图;
37.图7为并行d-p算法对pipedcylinder流场执行抽稀+修补后的效果图。
具体实施方式
38.下面将参照附图更详细地描述本公开的示例性实施例。虽然附图中显示了本公开的示例性实施例,然而应当理解,可以以各种形式实现本公开而不应被这里阐述的实施例所限制。相反,提供这些实施例是为了能够更透彻地理解本公开,并且能够将本公开的范围完整的传达给本领域的技术人员。需要说明的是,在不冲突的情况下,本发明中的实施例及实施例中的特征可以相互组合。下面将参考附图并结合实施例来详细说明本发明。
39.本实施例以douglas-peucker(d-p)抽稀算法为基础,提出了基于gpuwarp-specialization技术的并行化d-p算法,实现流线抽稀,减少流线采样点数据且保证对流动现象的精确描述,如图1所示,具体步骤如下:
40.使用rk45算法生成流线集;
41.对流线集中的所有流线进行分段得到流线段;
42.以每个流线段为单位,利用并行d-p算法进行抽稀处理得到抽稀处理后流线段;
43.利用修补算法处理抽稀处理后流线段中相交线段。
44.使用rk45算法生成流线集包括如下步骤:
45.步骤s1:读入种子点坐标值,通过插值函数获取该种子点的速度矢量,记为采样点;
46.步骤s2:使用rk45积分算法,依据前一个采样点坐标,计算积分参数;
47.步骤s3:计算积分参数的加权平均值即为流线的下一个采样点的位置;
48.步骤s4:计算积分误差;
49.步骤s5:如果积分误差大于预设参数,则调整时间步长并重复步骤s2至步骤s4;如果积分误差不小于预设参数,则获得一个新采样点;
50.步骤s6:如果对于流线的采样点数量小于总的种子点格式且新采样点还在流场区域范围内,则以此新采样点数据更新,并重复步骤s2至步骤s5,计算下一个采样点;否则,转到步骤s7;
51.步骤s7:如果种子点集合中还有没有使用的种子点,提取一个新的种子点,并跳转到步骤s1;否则,流程结束。
52.具体的,基于runge-kutta-fehlberg(rk45)算法生成流线,已知种子点集合{si},i代表第i个种子点,种子点个数ns,时间步长h,最大积分步数(即最大采样点数量)n
max
:
53.步骤1:读入种子点si的坐标值,通过插值函数f获取si的速度矢量,即f(si),记为初始采样点坐标
54.步骤2:使用rk45积分算法,依据前一个采样点坐标计算积分参数 k1,k2,k3,k4,k5,k6,其中,
[0055][0056][0057][0058][0059][0060][0061][0062][0063]
其中,
[0064]
f()为反距离加权函数。
[0065]
步骤3:计算k1~k6的加权平均值即为流线i的下一个采样点的位置,即
[0066]
[0067]
其中,
[0068]
步骤4:计算积分误差te,即
[0069]
te=|ct(1)*k1+ct(2)*k2+ct(3)*k3+ct(4)*k4+ct(5)*k5+ct(6)*k6|;
[0070]
其中,
[0071]
步骤5:使用参数ε来判断积分误差是否过大,是否需要调整步长,如果te>ε,说明误差较大,需要调整时间步长h,时间步长调整为h=0.9*h*(ε/te)
1/5
,并再次重复步骤2~步骤5计算;如果te≤ε,则获得一个新采样点
[0072]
步骤6:如果对于流线的采样点数量小于n
max
且新采样点还在流场区域范围内,则以此采样点数据更新并重复步骤2~步骤5,计算下一个采样点,否则,跳转到步骤7;
[0073]
步骤7:如果种子点集合{si}还有没有使用的种子点,提取一个新的种子点,并跳转到步骤1,否则,流程结束。
[0074]
需要理解的:插值函数f可以使用反距离加权法(idw)支持非结构2d/3d 网格或三线性插值支持结构网格,流程中涉及的常量数组b、ct和ch可参见 fehlberg等人的文献。
[0075]
流线的多分辨率数据的并行生成算法:为了实现流线的抽稀,同时保证流线的正确性和支持实时渲染能力,提出了基于gpu加速的并行d-p算法,可以实现对全域流线集合的并行处理,具体如下:
[0076]
步骤21:对所有流线进行预处理,基于分段策略对所有流线进行分段:
[0077]
步骤22:以每个流线分段为单位,利用并行d-p算法进行处理:
[0078]
步骤23:以流场空间区域划分为基础,遍历区域内所有相邻采样点构成的线段,判定是否存在相交情况,如果存在相交情况,则记录相交的线段信息,包括所属的流线及其分段,转到步骤24;如果不存在相交情况,则跳转到步骤 25;
[0079]
步骤24:处理所有的相交线段,利用修补算法进行处理,以消除所有相交情况,并更新线段信息,然后跳转回步骤23;
[0080]
步骤25:流程结束。
[0081]
具体的,步骤21:对所有流线进行预处理,基于分段策略对所有流线进行分段:
[0082]
先计算每个采样点的曲率,然后计算其与前后两个采样点的差异并求平均,得到每个采样点的曲率差,以曲率差大于某一阈值为判定标准,决定分割点,将流线分段,然后通过统计各个分段的采样点数量,依据每个分段包含的最小采样点数量,合并一些小的分段,使得所有分段里的采样点数量大致相同,图 2(a)中展示了通过计算曲率差获得一个分割点的过程。图2(b)中展示了所有的分割点,由较大的填充黑圆表示。由于存在较短的分段,因此将其中一个分割点舍弃,如图中红色空心三角形所表示。这样分段之后,使得每段处理的采样点大致均衡,为后续的并行化处理每个分段做准备。设置每个分段包含的最小采样点数量参数的目的是降低后面gpu执行时的切换开销。
[0083]
另一方面,由于后续抽稀算法以流线分段为基础展开,因此,我们需要给每个流线分段设置一个距离阈值。考虑到各个分段的几何特征差异和尺度大小差异,我们通过设置一个全局的参考距离阈值,然后统计各分段的平均曲率,获得最大值和最小值。然后根据该
分段的平均曲率与最小值的差异,对距离阈值进行按比例调整;
[0084]
步骤22:以每个流线分段为单位,利用并行d-p算法进行处理:
[0085]
并行d-p算法以线程束为单位进行,利用warp-specialization技术消除线程分歧,提升gpu硬件利用效率。并通过队列方法去掉递归和支持动态的数据级并行,如图3所示,在并行d-p算法中,每个线程块由至少64个线程组成,即至少2个线程束,其中有一个专门的线程束(warp 0)作为管理者,其他的线程束作为工作者。管理者线程束主要用于读取流线分段信息。各个流线分段之间是独立处理的,避免了流线采样点差异引起的工作量不平衡。每个工作线程束处理一个流线分段,执行d-p算法完成抽稀处理。管理者与工作者之间通过cuda的named barrier实现通信,并通过一个任务队列和读写信号量完成数据的维护。具体的说,
[0086]
在管理者线程束(warp 0)中,每个线程负责一个任务队列,首先取出一个流线分段,将任务信息(包括流线分段id,起始采样点,终止采样点,距离阈值)等填充到任务队列。然后该线程通过cuda/ptx的named barrier机制与一个工作者线程束通信,利用bar.sync阻塞,等待唤醒。如果后续被唤醒,则说明任务队列中已无任务,流线分段的抽稀处理已经完成,该线程接着取下一个流线分段进行处理,直到所有流场分段均处理完成。
[0087]
工作线程束则至少有1个,具体数量与线程块中设置的线程数量有关。如果设置128个线程,则会有3个工作线程束。工作线程束之间是相互独立的,没有任何通信交互。
[0088]
在每个工作线程束中,0号线程首先从任务队列中提取任务信息并在任务队列中标记为正在处理中,然后得到所涉及的采样点,然后每个线程并行计算一个采样点到起始-终止采样点构成的直线之间的距离,并利用warp级归约算法获得距离最大值,如果该距离值大于距离阈值,则确定出该最大距离值所对应的采样点作为分割点。然后0号线程将添加2项新任务到任务队列中,分别为(流线分段id,起始点,分割点,距离阈值)和(流线分段id,分割点,终止点,距离阈值)。如果该距离值小于等于距离阈值,则仅保留起始-终止采样点,其他采样点删除,完成抽稀处理。最后原任务标记为处理完成。依次如此处理,直到队列为空。然后将每个任务对应的抽稀结果组合起来,这样,一个流线分段的抽稀完成。工作线程束的0号线程通过bar.arrive唤醒被该named barrier 所阻塞的线程;
[0089]
步骤23:以流场空间区域划分为基础,遍历区域内所有相邻采样点构成的线段,判定是否存在相交情况,如果存在相交情况,则记录相交的线段信息,包括所属的流线及其分段,如果不存在相交情况,则跳转到步骤25;
[0090]
步骤24:处理所有的相交线段,利用修补算法进行处理,以消除所有相交情况,并更新线段信息,然后跳转回步骤23,具体修补流线相交的方法如下,
[0091]
首先,我们介绍一下修补过程。如果线段ab与cd判定为相交,则求出交点p,然后取其中一条线段ab所在的流线分段,找到距离p点最近的采样点q,形成2个线段,即aq与qb,取代原有线段ab,也就是说,通过增加一个分割点,试图修补相交问题,如图4所示。通过多次遍历,可以显著消除相交问题;
[0092]
其次,我们介绍一下修补的并行实现。我们首先将流场区域等分为若干与坐标轴平行的区域,二维和三维处理方法完全一样。每个区域由 x
min
/x
max
,y
min
/y
max
,z
min
/z
max
六个参数唯一确定。对于区域内的所有线段,是可以容易确定的。每个区域由一个线程束处理,实现数据级并行。
[0093]
对于每个区域(每个线程束),每个线程提取一条线段ab,首先读取其他线段,判定是否与ab相交,这可以通过常用的组合几何方法实现。如果判定有相交,则该线程执行修补过程。由于该线段是仅被一个线程修改,不存在共享冲突。而且,由于修补过程只是添加新的分割点(采样点),没有生成新点,所以这一个过程总是可以在有限步骤内完成的。因为原始的流线之间是不存在相交的。所以这一过程是完全的数据级的易并行模式。
[0094]
步骤25:流程结束。
[0095]
可视化公开数据boussinesq2d、jungtelziemniak2d和pipedcylinder2d流场实例:
[0096]
1)图5为案列boussinesq2d,它是布辛格法近似的加热圆柱气流场,在这个流场中,流动出现多达10处以上的汇聚,流线在这些地方聚集明显。其他地方则比较平缓。因此,通过抽稀算法,可以获得极低的抽稀率(大约0.09%)。并行d-p算法的修补方法有效消除了流线之间的相交问题,如图5中(a)部分、 (b)部分和(c)部分放大显示。通过实验发现,通过至多2次的修补操作,抽稀后流线的相交问题全部消除。这表明我们提出的适合并行的修补操作的有效性;
[0097]
2)图6为案例jungtelziemniak2d,它是冯卡曼涡街流场。这个流场比较复杂,出现了多个极限环。采样点的分布极不均衡。我们放大展示了三个局部。图6中(a)部分放大图中,是一个小的环,出现了密集的流线。并行d-p算法也成功地对采样点稀疏化,而且消除了所有的相交。图6中(b)部分放大图则是一个曲率变化很大的区域,并行d-p算法也很好的保留了这一特征。图6中(c) 部分放大图则是流的汇集而导致大量密集流线,抽稀后的流线依然消除了相交问题;
[0098]
3)图7为案例pipedcylinder2d,它是围绕两个圆柱体的粘性2d流场。它具有非常复杂的流动现象,还包含多个涡,从图7中(a)部分和图7中(b)部分的放大图可以看出,并行d-p算法对多条非常近的流线进行抽稀之后,依然没有相交现象。图7中(c)部分和图7中(d)部分展示了单条流线描述的极限环的情况,通过并行d-p的修改操作,单条流线的自相交情况也消除了。这进一步表明我们提出的适合并行的修补操作非常有效;
[0099]
4)通过定量指标—部分曲线映射方法(pcm)来评估两条曲线之间非度量相似性,如表1所示,对于同一研究对象,值越小表明越相似。从表1的pcm 数据可以看出,对于流场boussinesq2d,无修补的并行d-p就获得了不错的效果,它通过分段,保留了大部分特征。而对于流场pipedcylinder2d,由于有大量的极限环和螺旋线,分段效果不明显,需要通过修补操作消除相交,获得更好的效果。流场jungtelziemniak2d的流线曲率特征明显,通过分段可以较好的保留特征和缓解相交问题。
[0100]
表1
[0101][0102]
本实施例还提供了一种全域流场的流线并行抽稀系统,该系统包括:第一模块,用于生成流线集;第二模块,用于对流线集中的所有流线进行分段得到流线段;
[0103]
第三模块,用于以每个流线段为单位,利用并行d-p算法进行抽稀处理得到抽稀处理后流线段;第四模块,用于利用修补算法处理抽稀处理后流线段中相交线段。
[0104]
本实施例首次实现了流线抽稀,减少流线采样点数据而保证对流动现象的精确描述;本实施例消除了流线可能存在的相交现象,缓解采样点分布不均衡现象;本实施例显著降低其存储开销和渲染时间开销,支持大规模多分辨率流线可视化需要。
[0105]
本发明虽然已以较佳实施例公开如上,但其并不是用来限定本发明,任何本领域技术人员在不脱离本发明的精神和范围内,都可以利用上述揭示的方法和技术内容对本发明技术方案做出可能的变动和修改,因此,凡是未脱离本发明技术方案的内容,依据本发明的技术实质对以上实施例所作的任何简单修改、等同变化及修饰,均属于本发明技术方案的保护范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1