一种优化边界的三维点云语义分割方法
1.本发明属于自动驾驶及计算机视觉和深度学习领域,具体涉及一种优化边界的三维点云语义分割方法。
背景技术:
2.三维点云是通过雷达、图片和数据合成等不同方式生成的三维空间中的附着在物体表面的三维数据点。根据生成三维点云的规模也可分为对象级三维点云和场景级三维点云。对象级三维点云是指某个物体在三维空间中以三维数据点的形式表达。场景级三维点云是指在一定的空间范围内存在多种不同的物体,并以三维数据点的形式表达。其中场景级三维点云根据规模大小又分为室内级三维点云和室外级大规模三维点云,其中室内级三维点云是通过图片生成、较小范围的激光雷达、数据合成等方式获取的室内场景的三维点云。室外级大规模点云是通过车载激光雷达或航空激光雷达等方式获取的较大空间范围的三维点云。
3.三维点云的分割任务是在获取的三维点云数据的基础上进行处理的,三维点云的分割任务是通过三维点云的不同特征分离三维点云,通过不同的标注表达不同的区域。其中三维点云的分割又可分为部分分割(细微级)、实例分割(对象级)和语义分割(场景级)。
4.三维点云语义分割的方法是指将一个场景内的数据点以及数据点自带的特征信息作为输入再进行一系列处理,最终将每个三维数据点赋予语义标签。三维点云语义分割主要应用于无人驾驶、机器人、无人机、铁路铁轨检测、三维建模和娱乐行业等。对于不同的应用场景三维点云语义分割的性能要求也不同,在室内场景要求的性能主要是分割的准确度;对于室外大规模场景,在要求准确度的前提下还需要尽量减少语义分割处理的时间。
5.三维点云语义分割根据提取特征的方法不同主要分为两个大类。第一类采用人工特征和分类器对三维点云进行语义分割,这类方法第一阶段采用聚类或分类的方式,通过人工特征的引入,对区域内的物体进行检测与判断,能够对数据中的散乱点、线性点、面性点进行划分,并直接赋予语义标签;第二阶段为了考虑局部上下文的联系,引入马尔科夫随机场(markov random fields mrf)对数据点上下文进行建模。第二类使用基于深度学习的方式进行三维点云语义分割,这类方式主要分为三种:多视图方法、三维点云体素化方法和基于原始三维点云的方法。多视图方法是在三维空间中拍摄多幅图片或者将三维模型投影到二维图像上,再分别通过卷积层、池化层提取特征,最后将特征聚合后输入网络,返回三维点云语义分割后的结果。这种方法不适合大规模空间场景,并且分割精度与视角选择有关;三维点云体素化方法是将三维点云体素化为3d网格,再进行3d卷积提取特征,但面临的问题是一个体素内可能存在多个语义标签,而且三维点云语义分割性能受每个物体之间的边界影响严重,导致网络模型在同一体素内无法分离不同物体的边界,从而会影响三维点云语义分割的精度。
6.基于原始三维点云的方法是在输入的三维点云中直接提取特征信息进行分割,因此会减少原始特征信息的损失,通常在室内级三维点云语义分割有着良好的表现。但是要
进行不同规模三维点云语义分割,就依赖于网络模型的结构。部分现有网络模型仅能执行室内场景的三维点云语义分割,导致这种情况出现的原因是三维点云具有无序性,基于原始三维点云的方法很难直接提取出数据点之间互相存在的联系,需要通过预处理的方式才能进行模型训练。
7.许多能够处理不同规模场景的基于原始三维点云的网络模型在局部的分割效果不佳,特别是在边界部分难以分离不同物体的语义标签。主要原因是三维点云在采集的时候出现的遮挡、稀疏、不连续等问题导致网络模型在训练中无法清晰的学习到边界点并分离。因此不同的方法对不同规模的三维点云效果也不一样。
技术实现要素:
8.本发明提供了一种优化边界的三维点云语义分割的方法,其目的是为了提高大规模三维点云语义分割的精度,解决部分基于深度学习的三维点云语义分割方法无法处理大规模三维点云,以及其他语义分割方法时间效率低的问题,同时加快语义分割速度。
9.技术方案:
10.一种优化边界的三维点云语义分割方法,其特征在于:该分割方法包括:
11.步骤一:三维点云预处理:仅在编码层前进行一次三维点云预处理,将输入的三维点云特征维度通过共享多层感知器(multilayer perceptron mlp)的方式将特征维度定为8维;
12.步骤二:编码层由局部特征融合模块和随机采样模块组成;其中局部特征融合模块由连续的两组局部空间编码和注意力池化部分组成;
13.1、局部空间编码:局部特征编码分为三个部分:寻找局部区域的点、相对点的位置编码、点特征增强;
14.2.注意力池化;
15.通过一个conv2d和softmax组成的函数来学习每个局部特征点的注意力分数。再将每个局部区域点的特征与每个注意力分数进行点积之后求和,将这个结果输入到由bn和leakyrelu所组成的共享mlp。此时得到一个特征向量fi;
16.步骤三:解码层:将步骤二得到的特征编码作为解码层的输入,进行最近邻差值三维点云数量的采样,特征维度与对于对比边界学习特征维度、编码层逆序跳层连接送入共享mlp融合特征;在完成特征融合后进行全连接升维,再进行随机失活操作,最后通过共享mlp将维度下降到语义标签数量相同的维度,最终输出三维点云语义分割结果;
17.步骤四:对比边界优化:对比边界优化采用对比边界学习框架,主要分为两个模块:
18.1.边界子场景挖掘:在不同尺度下的三维点云采样中提取真值标签,每层采样点云数与对应编码层随机采样结果相同;随着三维点云尺度降低会出现边界采样的点具体标签不确定的情况,采用cbl框架中的边界子场景挖掘来确定每层点云的语义标签;
19.2.对比边界学习:在模型训练的过程中将每一层的边界点与边界子场景得到的与之对应层的语义标签进行对比学习;对比学习采用infonce损失及其泛化去优化定义边界点的目标函数,使得边界点的最终结果更偏近于来自同一类别的相邻点,最后优化对应解码层三维点云特征。
20.在步骤二的(1)局部空间编码中,寻找局部区域的点:根据场景规模控制的局部区域基于欧氏距离d,并使用knn的算法收集近邻点,以每个局部区域中心点为i
th
进行排序;每个局部区域内邻近点以k表示,即为其中下标i表示中心点的序号,上标k表示中心点i局部区域内点的序号,通过knn构建kd-tree索引;
21.(2)相对位置编码:为了使整个网络结构更好的理解局部特征,编码方式是将每个局部区域的中心点坐标、局部区域内邻近点坐标、局部区域内邻点坐标与局部区域的中心点坐标差、局部区域内邻点相对于局部区域的中心点的欧式距离这四部分进行拼接操作,再通过mlp操作;以此将每个局部区域内的点与这个局部区域内的中心点相关联以提高整体网络结构的局部性能;
22.(3)点特征增强:每个局部区域内k个近邻点特征即为f={f
i1
…fik
}将近邻点的相对位置编码与原始该点的特征进行拼接操作,由位置编码和特征构造成新的特征,拼接后即为其中下标i表示中心点的序号,上标k表示中心点i邻域内点的序号。
23.本发明具有以下优点和积极效果:
24.本发明使用的是基于深度学习的原始三维点云方法,对比其他深度学习的方法,本方法在三维点云采样方式上的时间复杂度为o(1)能够较快速度的处理大规模三维点云任务。在局部特征提取时使用局部特征扩展模块,提高每个点的感受野,从而扩大邻域范围。本方法提出的6层下采样结构,及对比边界优化,在大幅度采样三维点云的同时进行了不同尺度下的边界优化,使得三维点云语义分割网络模型的边界分割更加清晰,对目标检测等任务的处理提供有效帮助。
附图说明
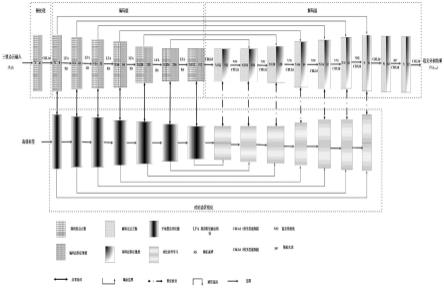
25.图1是本发明一种优化边界的三维点云语义分割方法的总体结构图;
26.图2是本发明一种优化边界的三维点云语义分割方法中1维特征提取模块cbl1d说明图;
27.图3是本发明一种优化边界的三维点云语义分割方法中局部特征融合模块说明图;
28.图4是本发明一种优化边界的三维点云语义分割方法中2维特征提取模块cbl2d;
29.图5是本发明一种优化边界的三维点云语义分割方法中局部空间编码模块说明图;
30.图6是本发明一种优化边界的三维点云语义分割方法中注意力池化模块。
具体实施方式
31.为了提高大规模三维点云语义分割的精度,解决部分基于深度学习的三维点云语义分割方法无法处理大规模三维点云,以及其他语义分割方法时间效率低的问题,因此提出的一种优化边界的三维点云语义分割方法,提高三维点云语义分割在不同规模三维点云下的精度和处理效率。本方法使用随机采样降低采样时的资源消耗;本方法在局部聚合中加入注意力池化用以增强局部区域的感受野;本方法在网络模型训练的过程中同时引入对比边界学习,仅在边缘区域构建邻域降低资源消耗,同时将边界点对比学习后的结果去优
化模型,提高网络模型的的边界处理能力。通过以上手段可以解决不同级别场景语义分割,提高三维点云语义分割的边界准确率,提升整体网络模型的处理效率。
32.下面结合附图对本发明做进一步的说明:
33.一种优化边界的三维点云语义分割方法,包含三维点云预处理、编码层、解码层、对比边界优化,其中编码层包括局部特征融合模块和随机采样模块,对比边界优化包括对比边界学习和边界子场景挖掘。方法处理流程如图1所示,具体包括如下步骤:
34.步骤一:三维点云预处理:因为不同数据集提供的原始特征维度不同(比如r、g、b、光照、坐标、通道数、法向量等特征),所以对数据集进行预处理。在编码层前进行一次三维点云预处理,首先将采集到的原始三维点云通过共享mlp提取每个点的特征,提取三维点云总数为n,采用一维卷积(conv1d)、批归一化(batch normalize)、泄露性线性单元(leakyrelu),组成的cbl1d模块作为共享mlp进行特征提取,如图2所示。使输出的三维点云特征维度为8维。
35.步骤二:编码层:如图1所示,将获得初始为8维特征的点云输入连续6层编码层,并且每层编码层之间采用随机采样。在6层编码层中前3层随机采样的点云数是其前一层点云数的1/4,编码层中后3层随机采样的点云数是其前一层点云数的1/2,每层之间都使用局部特征融合模块进行升维操作,每层之间特征维度提升一倍,即从预处理批归一化后的三维点云维度变化为(8,16,32,64,128,256,512)。每层在进行完局部特征融合操作后再进行一次随机采样操作,前三层随机采样保留25%,后三层随机采样保留50%,即三维点云数量为
36.局部特征融合模块:如图3所示,是将两个局部空间编码和两个注意力池化堆叠组成。先由三维点云特征进入cbl2d模块进行维度减半,其中cbl2d模块采用二维卷积(conv2d)、批归一化(batch normalize)、泄露性线性单元(leakyrelu)组成,cbl2d模块如图4所示。之后将局部空间坐标与局部特征进行拼接,进入局部空间编码模块和注意力池化得到一个局部注意力特征,再与局部空间坐标进行拼接,再次通过局部空间编码模块和注意力池化。得到的局部注意力特征通过cb2d模块进行升维操作,同时输入的三维点云特征也通过cb2d模块进行升维操作,最终将两种同一维度的特征求和,进入到leakyrelu进行激活。其中cb2d模块是采用二维卷积(conv2d)、批归一化(batch normalize)组成。
37.(1)局部空间编码:
38.如图5所示。局部特征融合部分先将带有坐标信息的三维点云特征通过knn收集基于欧式距离范围内的局部区域点,对于每个局部区域中心点即为i
th
进行排序,每个局部区域内k个点即为并且pi∈χn,其中下标表示中心点序号,上标表示局部区域内点的序号。将局部区域的中心点坐标、局部区域内邻近点坐标、局部区域内邻点坐标与局部区域的中心点坐标差、局部区域内邻点相对于局部区域的中心点的欧式距离、每一点的法向量估计五部分进行拼接,进入cbl2d模块,得到局部区域的相对位置编码即为r
ik
可以表达为公式(1):
39.40.其中表示拼接操作,mlp为cbl2d的多层感知器,表示局部区域内邻点坐标与局部区域的中心点坐标差,表示提取邻域点到中心点的欧氏距离,表示局部区域内每一点的法向量估计。
41.每个局部区域内k个近邻点特征即为f={f
i1
…fik
},其中f表示局部区域内邻近点特征集合;f
ik
表示局部区域内临近点特征,上标表示局部区域内临近点序号,下标表示局部区域序号。将局部区域内邻近点的相对位置编码与该局部区域内邻近点的特征进行拼接操作,构造成特征、点位置坐标编码拼接的新的特征即为其中表示构造后局部区域内邻近点新的特征集合;表示构造后局部区域内临近点新的特征,上标表示局部区域内临近点序号,下标表示局部区域序号。其表达公达式为(2):
[0042][0043]
(2).注意力池化:
[0044]
如图6所示,先求取每个点的注意力得分,将构造后新的特征与共享的权重w作为超参数输入注意力得分计算公式,求出每个点的注意力得分上标表示局部区域内临近点序号,下标表示局部区域序号。其表达公式为(3):
[0045][0046]
其中g()函数是一个二维卷积和一个softmax组成的共享函数。
[0047]
将得到的注意力分数与构造后的新的特征进行点积操作得到每个点的注意力特征,将局部每个点的注意力特征求和后输入到cbl2d模块,作为该局部区域的注意力特征其表达公式为(4):
[0048][0049]
步骤三:解码层:如图1所示,经过6层编码层后,进行10层解码层。解码层第一层是将最后一层编码层输出的特征编码与对比边界学习优化的特征进行拼接,然后输入cbl2d模块,通过此模块使维度依然保持512维。解码层第2层到解码层第7层采用的方式为:先通过knn算法查找最近邻点,然后通过最近邻插值(nearest neighbor)对点云数进行上采样,第2层到第4层三维点云数量提高2倍,第5层到第7层三维点云数量提高4倍,使三维点云的数量变为先进行最近邻插值,再进行共享mlp。第2层到第7层每层进行完最近邻插值后再将由上一层解码层得到的三维点云特征、对应层对比边界学习优化后的三维点云特征、对应点云数的编码层三维点云特征进行拼接,再输入cbl2d模块,将特征维度下降到前一层的一半,其表达式为(5):
[0050][0051]
其中f
id
表示当前解码层三维点云特征,表示上一层三维点云特征,表示对
应点云数的编码层三维点云特征,f
ic
表示对比边界学习优化后的三维点云特征。解码层第8层是将具有8维特征的完整数量的三维点云输入到cbl2d模块将维度提高到64。解码层第9层进行随机失活,将失活率设置为50%,再输入到cbl2d模块此时三维点云特征维度下降为32维。解码层第10层通过cbl2d将维度设置为与语义标签相同的数量最后预测语义分割结果。
[0052]
步骤四、对比边界优化:
[0053]
结构如图1所示。本算法采用cbl三维点云语义分割对比边界框架,由子场景边界挖掘,对比边界学习两部分组成。
[0054]
1.子场景边界挖掘:目的是为了在训练中先找到真值的边界部分,而每一层的边界发掘结构可作为下一层的真值。子场景边界挖掘的层数与编码层相同,并且每层子场景边界挖掘与编码层每层共享随机采样。在模型训练的过程中引入数据集的真值进行对比边界学习。边界点就是区分不同物体的点,寻找方法是在三维点云中找到与相邻点语义标签不同的点,目的是为了在端到端网络模型中更清晰的分离不同物体,提高三维点云语义分割精度。其中边界邻域选取整体三维点云规模为0.1%的球体,其表达公式为(6):
[0055][0056]
其中χ表示整个三维点云,b表示边界点集合,ni表示以xi的邻域点集合,xj表示在ni邻域内与xi语义标签不一致的点,l表示语义标签,并且bn∈χn,n表示对应编码层层数。上标表示采样的层数,下标表示邻域内点的位置排序,后面不在赘述。
[0057]
每一层所采样的点与对应的随机采样的点相同,第一层直接使用数据集的真值标签并且第二层以后边界的真值标签确定方法是以上一层边界点为中心的局部区域内所有点的标签进行平均池化得到的值。其表达公式为(7):
[0058][0059]
其中avg()表示平均池化,表示前采样层以边界点为中心的邻域点集合。
[0060]
2.对比边界学习:首先根据公式6确定进行对比学习的边界点,在边界点为中心的邻域中记正对点为{xj∈ni∧li=lj},负对点为{xj∈ni∧li≠lj}。对比训练使用infonce损失(info noise contrastive estimation loss)的泛化,其中引入的τ温度系数作为超参数,目的是期望边界点优化更靠近与正对点,通过对比学习后得到的边界特征再去优化上采样阶段的边界点特征,因此增强了边界区域限制,同时使网络模型具有识别边界特征的能力。infonce损失的泛化函数表达公式为(8):
[0061][0062]
其中lb表示对比边界学习损失,fi表示对应边界点xi的特征,fj表示与xi语义标签不一致的点的特征,下标k表示局部区域的点全部点,τ为温度系数作为超参数,d(.,.)表示距离测量结果
[0063]
根据整个训练过程计算全局损失函数为(9):
[0064][0065]
l
ce
表示交叉熵损失,λ对比边界学习的损失权重。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1