一种基于孪生卷积子空间网络的小样本SAR目标识别方法
一种基于孪生卷积子空间网络的小样本sar目标识别方法
技术领域
1.本发明应用于合成孔径雷达(synthetic aperture radar,sar)自动目标识别领域,具体涉及一种基于孪生卷积子空间网络的小样本sar目标识别方法。
背景技术:
2.合成孔径雷达作为一种主动式微波成像传感器,因其具有全天时、全天候、强穿透等工作特点,在众多国防和民用领域中已得到广泛应用。自动目标识别(automatic target recognition,atr)作为sar图像解译的关键技术,可实现从图像数据到情报信息的转换,在战场态姿感知、战场预警以及目标精准打击等方面发挥重要作用。
3.近年来,随着计算机技术与深度学习的迅速发展,大量基于深度学习的sar自动目标识别方法不断涌现。与传统的目标识别方法相比,基于深度学习的sar目标识别在性能上不断取得突破。但基于深度学习的sar目标识别方法是基于数据驱动的,因此现有模型只有在训练样本相当充足的条件下才可获得较优异的识别性能。然而,在实际应用场景中,特别是在军事场景中,受传感器捕获能力以及非合作目标等因素的影响,捕获大量的训练样本通常是代价极高甚至难以实现的。在训练样本不足的情况下识别模型容易发生过拟合,无法实现目标类别的有效推理。近年来,在解决小样本目标识别的问题上,学者们已从迁移学习、元学习等方面着手,提出了多种小样本sar目标识别方法。但是现有的小样本目标识别并不能获得较为满意的识别性能。因此,小样本sar目标识别是现阶段颇受关注且亟待解决的问题。为了解决上述问题,本发明提出一种孪生卷积子空间分类网络,用以解决小样本条件下的sar目标识别问题。
技术实现要素:
4.本发明针对上述sar目标识别中存在的问题,提出了一种基于孪生卷积子空间网络的方法以实现小样本条件下的sar目标识别。该方法首先建立了一个基于孪生结构的特征嵌入网络,并利用对比学习的思想训练一个类内紧凑、类间分散的低维特征表示空间,以提取更具鉴别性的小样本sar目标特征;然后设计了一个基于深度子空间学习的分类器,通过计算待识别样本在每类训练样本张成子空间上的最短投影距离来推理目标样本类别。
5.本发明技术方案为一种基于孪生卷积子空间网络的小样本sar目标识别方法,该方法包括:
6.步骤1:在训练阶段,从辅助训练的样本集中随机采样一批数据且将其划分为支持集和查询集,以模拟小样本目标识别任务;给定训练样本x={x
c,1
,x
c,2
,
…
,x
c,k
},x
c,i
表示第c类sar目标的一批训练样本,k表示每类目标的训练样本数,c∈{1,
…
,n},n表示目标类别的数量;
7.步骤2:将训练样本中sar图像裁剪为64
×
64像素大小的感兴趣sar目标样本,以减少冗余背景对特征提取的影响;建立识别模型,识别模型包括特征嵌入网络和分类器;
8.步骤3:建立基于孪生结构的特征嵌入网络,并引入对比学习思想训练特征嵌入模
型,利用步骤1中随机采样生成的查询样本和支持样本训练一个类内紧凑、类间分散的低维特征表示空间;
9.步骤3.1:将sar目标样本输入到特征嵌入网络,经特征嵌入网络编码后样本表示为{φ
θ
(x
c,1
),φ
θ
(x
c,2
),
…
,φ
θ
(x
c,k
)},其中φ(
·
)表示非线性映射函数,θ是特征嵌入网络的可训练参数;
10.步骤3.2:通过以下公式计算第c类目标对应的特征均值:
[0011][0012]
步骤3.3:减去特征均值后,第c类目标特征表示为:
[0013]
xc=[φ
θ
(x
c,1
)-μc,φ
θ
(x
c,2
)-μc,
…
,φ
θ
(x
c,k
)-μc]
[0014]
步骤3.4:为了训练类内紧凑、类间分散的特征表示空间,采用对比损失作为特征嵌入网络的代价函数,即:
[0015][0016]
其中,s和q分别表示一批数据中支持集样本和查询集样本的总数,d
i,j
是第i个样本和第j个样本之间的欧几里得距离,当且仅当两个样本属于同一个类别时,y=1;否则,y=0;margin是一个预设值,用于约束不同类别样本之间的最大边界距离;
[0017]
步骤4:设计基于子空间学习的分类器;
[0018]
步骤4.1:通过目标训练样本的特征计算第c类目标的投影矩阵pc,c=1,
…
,n;
[0019]
步骤4.2:给定一个待识别的样本q,将样本q的低维嵌入特征投影到pc上;
[0020]
步骤4.3:采用如下公式计算样本q到pc的最近投影距离,并通过最短投影距离实现对目标样本的类别推理:
[0021]
dc(q)=-||(i-mc)(φ
θ
(q)-μc)||2[0022]
其中,pc是x={φ
θ
(x
c,i
);c=1,
…
,n;i=1,
…
,k}的张成子空间基向量对应的截断矩阵;i表示与mc同维度的单位矩阵;||
·
||表示矩阵的2范数运算;φ
θ
(q)表示目标样本q的特征嵌入;
[0023]
步骤4.4:为了便于对所提出的方法进行端到端的训练,采用softmax归一化函数来计算待识别样本q被判定为第c类目标的概率,以完成目标识别任务,即:
[0024][0025]
其中,exp(
·
)表示以常数e为底数的指数运算;
[0026]
步骤5:采用交叉熵损失训练基于子空间学习的分类器,交叉熵损失函数定义如下:
[0027][0028]
其中,c为类别数量,y为真实标签,为预测标签;
[0029]
步骤6:采用如下公式中的总代价函数训练识别模型,最终采用训练好的识别模型
进行sar目标识别;
[0030]
l=lc+λl
cl
[0031]
其中,λ是用于平衡两损失函数重要性的超参数。
[0032]
综上所述,本发明可获得的有益效果是:
[0033]
本发明构建了基于孪生结构的特征嵌入网络,并采用对比学习的思想训练一个类内紧凑、类间分散的低维特征嵌入空间,便于后续分类器判别;为了实现稳健的目标身份推理,本发明借鉴深度子空间学习的思想设计了一种新颖的小样本分类器,与现有广泛使用的小样本目标识别方法相比,该分类器通过计算待识别样本到类训练样本张成子空间的最短投影距离完成稳健的目标类别推理,并可在多种不同的小样本场景中取得较优的识别性能。
附图说明
[0034]
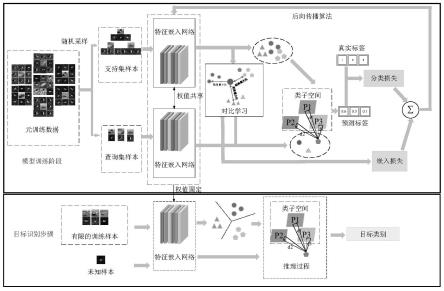
图1为本发明的算法流程框架图;
[0035]
图2为子空间分类器结构图;
[0036]
图3为不同特征表示空间下三类目标的τ-sne特征可视化结果;(a)原始sar图像;(b)原型网络特征;(c)孪生子空间网络特征。
具体实施方式
[0037]
为了更好地展现出本发明的技术要点,以下将结合本发明的算法框架图对发明内容进行详细阐述。本发明提出了一种基于孪生卷积子空间网络的小样本sar目标识别方法,该方法的算法流程框架如图1所示。本发明的具体实施过程如下:
[0038]
步骤1:在训练阶段,从辅助训练的样本集中随机采样一批数据且将其划分为支持集和查询集,以模拟小样本目标识别任务;给定训练样本x={x
c,1
,x
c,2
,
…
,x
c,k
},x
c,i
表示第c类sar目标的一批训练样本,k表示每类目标的训练样本数,c∈{1,
…
,n},n表示目标类别的数量;
[0039]
步骤2:将训练样本中sar图像裁剪为64
×
64像素大小的感兴趣sar目标样本,以减少冗余背景对特征提取的影响,以及建立识别模型,识别模型包括特征嵌入网络和分类器;
[0040]
步骤3:建立基于孪生结构的特征嵌入网络,并引入对比学习思想训练特征嵌入模型,利用步骤1中随机采样生成的查询样本和支持样本训练一个类内紧凑、类间分散的低维特征表示空间;
[0041]
步骤3.1:将sar目标样本输入到特征嵌入网络,经特征嵌入网络编码后样本表示为{φ
θ
(x
c,1
),φ
θ
(x
c,2
),
…
,φ
θ
(x
c,k
)},其中φ(
·
)表示非线性映射函数,θ是特征嵌入网络的可训练参数;
[0042]
步骤3.2:通过以下公式计算第c类目标对应的特征均值:
[0043][0044]
步骤3.3:减去特征均值后,第c类目标特征表示为:
[0045]
xc=[φ
θ
(x
c,1
)-μc,φ
θ
(x
c,2
)-μc,
…
,φ
θ
(x
c,k
)-μc]
[0046]
步骤3.4:为了训练类内紧凑、类间分散的特征表示空间,采用对比损失作为特征
嵌入网络的代价函数,即:
[0047][0048]
其中,s和q分别表示一批数据中支持集样本和查询集样本的总数,d
i,j
是第i个样本和第j个样本之间的欧几里得距离,当且仅当两个样本属于同一个类别时,y=1;否则,y=0;margin是一个预设值,用于约束不同类别样本之间的最大边界距离;
[0049]
步骤4:设计基于子空间学习的分类器;
[0050]
步骤4.1:通过目标训练样本的特征计算第c类目标的投影矩阵pc,c=1,...,n;
[0051]
步骤4.2:给定一个待识别的样本q,将样本q的低维嵌入特征投影到pc上;
[0052]
步骤4.3:采用如下公式计算样本q到pc的最近投影距离,并通过最短投影距离实现对目标样本的类别推理:
[0053]
dc(q)=-||(i-mc)(φ
θ
(q)-μc)||2[0054]
其中,pc是x={φ
θ
(x
c,i
);c=1,
…
,n;i=1,
…
,k}的张成子空间基向量对应的截断矩阵;i表示单位矩阵;||
·
||表示2范数;φ
θ
(q)表示目标样本q的特征嵌入;
[0055]
步骤4.4:为了便于对所提出的方法进行端到端的训练,采用softmax归一化函数来计算待识别样本q被判定为第c类目标的概率,以完成目标识别任务,即:
[0056][0057]
其中,exp(
·
)表示以常数e为底数的指数运算;
[0058]
步骤5:采用交叉熵损失训练基于子空间学习的分类器,交叉熵损失函数定义如下:
[0059][0060]
其中,c为类别数量,y为真实标签,为预测标签;
[0061]
步骤6:采用如下公式中的总代价函数训练识别模型,最终采用训练好的识别模型进行sar目标识别;
[0062]
l=lc+λl
cl
[0063]
其中,λ是用于平衡两损失函数重要性的超参数。
[0064]
下面结合实例对本发明进行说明:
[0065]
一、实验条件
[0066]
本仿真实验采用了由美国高等计划研究署公开发布的mstar数据集进行算法有效性评估。mstar数据集中包含了10类地面军事目标的sar图像,原始图像在距离与方位上分辨率为0.3m
×
0.3m,大小为128
×
128像素。mstar数据集中的sar图像通过聚束sar传感器在不同的俯仰角下,从0
°
~360
°
方位角上进行采集。根据算法评估需求,本实验将mstar数据集中十类目标划分为元训练数据集d
tr
和元测试数据集d
te
。具体来讲,将17
°
俯仰角下采集的bmp2、btr60、btr70、t62、t72、d7、zil131七类目标作为元训练数据集,15
°
、17
°
、30
°
俯仰角下采集的2s1、brdm2、zsu23/4三类目标作为元测试数据集,用以模拟小样本目标识别任务。表1给出了实验数据详细的目标类型和样本数量。为了说明本发明所提方法的有效性与
稳健性,每个实验独立运行1000次,并以平均识别率和方差的形式表征算法的性能。
[0067]
实验采用的特征嵌入网络层的具体参数为:第一层:卷积核大小为3
×
3,卷积步长是1,填充是0;第二层:卷积核大小为3
×
3,卷积步长是1,填充是0;第三层:卷积核大小为3
×
3,卷积步长是1,填充是1;第四层:卷积核大小为3
×
3,卷积步长是1,填充是1。
[0068]
仿真环境及平台为win10 64位计算机系统,16gb内存,gpu型号为nvidia geforce rtx 2060,pycharm仿真软件,并使用基于pytorch框架的python语言实现本发明中的所有算法。
[0069]
二、实验内容和结果
[0070]
根据基于子空间学习分类器的建模原理,子空间的维度设置为k-1(k是小样本目标识别任务中每类目标的训练样本数)。对于每类目标只有一个训练样本的sar目标识别任务,可通过在任意三个方向的翻转操作来扩充sar图像。超参数margin和λ分别设置为2和0.1。采用adam优化器来优化本发明所提的模型,学习率设置为0.001。
[0071]
元训练阶段和元测试阶段的具体样本数据配置情况如表2所示。
[0072]
实验一:评估小样本sar目标识别性能。
[0073]
本仿真实验基于mstar数据集评估了所提方法在不同场景条件下的小样本sar目标识别的性能,同时选取了原型网络(prototypical net)、关系网络(relation net)、msar三种网络模型作为对比方法。本实验基于三种不同俯仰角采集的元测试数据集模拟了3-way 1-shot、3-way 5-shot两种小样本目标识别任务。表3给出了在95%置信区间置信度下,各种方法在不同俯仰角的小样本目标识别结果。
[0074]
从表中可以看出,当元测试数据和元训练数据的俯仰角差异较大时,所有方法的识别性能在1-shot和5-shot的sar目标识别任务中均显著下降。造成这种现象的一个可能的原因是,当元训练数据和元测试数据之间的俯仰角差异很大时,模型无法通过元训练获得足够可靠的先验知识用于后续的小样本sar目标识别任务。从整个实验结果可以看出,本发明在不同场景下的小样本sar目标识别任务中表现始终优于其他对比方法。因此,本发明所提方法在解决小样本sar目标识别任务方面具有巨大潜力。
[0075]
实验二:探究所提方法中各模块的有效性。
[0076]
为验证本发明所提方法中每个模块的有效性,本仿真实验在mstar数据集上开展了相关的消融实验。考虑到所提方法的基本架构与原型网络相同,此处将原型网络作为基线方法。将基于孪生结构的特征嵌入网络的原型网络标记为模型1,将基于子空间学习的分类器的原型网络标记为模型2。本实验选取在30
°
俯仰角下获取的三类sar目标图像(2s1、brdm2、zsu23/4)模拟3-way 5-shot sar目标识别任务。
[0077]
首先,如图3所示,本仿真实验绘制了原始sar数据、原型网络和本发明所提网络三种特征表示空间下目标的特征分布图,从定性分析的角度来简要说明本发明所提的孪生子空间网络在提升目标识别性能方面的效果。具体来说,本仿真使用python中的可视化工具包τ-sne对三种特征表示空间的样本分布进行可视化。从图3(a)不难发现,每类原始的sar图像样本特征分布并不集中,且不同类别的样本数据存在类间混叠的问题。而观察图3(b)和图3(c)中样本的特征分布变化,可以看出在原型网络和本发明所提网络的特征空间中,三类目标的特征对比图3(a)来说类间分散性得到了显著提升。除此之外,进一步比较图3(b)和图3(c)中样本的特征分布情况,能够得出本发明所提的孪生子空间网络的特征表示
空间具有更大的类间距。根据上述分析,本发明所提方法通过提高类间分散性提升了目标识别性能。
[0078]
然后,本仿真实验从定量分析的角度进一步验证了本发明所提的孪生网络结构与基于子空间学习的分类器对于提升模型分类性能的功效。各模型的识别率如表4所示。从表中可以看出,本发明的两个关键组成部分均有助于提高小样本sar目标识别性能。
[0079]
表1 mstar数据集划分的详细情况
[0080][0081]
表2 元训练阶段和元测试阶段的数据配置情况
[0082][0083]
表3 95%置信区间置信度下不同俯仰角的识别性能(%)
[0084][0085]
表4 不同模型的识别性能(%)
[0086]
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1