基于自学习策略的跨模态知识蒸馏方法、装置及存储介质与流程
1.本发明属于知识蒸馏方法的技术领域,具体涉及基于自学习策略的跨模态知识蒸馏方法、装置及存储介质。
背景技术:
2.知识蒸馏是一种在烦琐的模型中提炼知识并将其压缩为单个模型的方法,以便可以将其部署到实际应用中。指将笨拙的模型(教师模型)的学习行为转移到较小的模型(学生模型)。
3.跨模态知识蒸馏方法,是一种新型的教师-学生训练结构,通常是已训练好的笨拙的模型,即教师模型提供知识,学生模型通过蒸馏训练来获取教师的知识,它可以将复杂教师模型的知识迁移到学生模型中。
4.传统模型部署主要有以下几个缺点:模型太大导致无法在低资源设备上运行;模型在设备端实时性不高;在设备上部署后,消耗过大的能耗问题。
技术实现要素:
5.本发明的目的是提供一种基于自学习策略的跨模态知识蒸馏方法、装置及存储介质,解决传统模型部署具有模型太大导致无法在低资源设备上运行;模型在设备端实时性不高;在设备上部署后,消耗过大的能耗的问题。
6.为了实现上述目的,本发明采用以下技术方案:
7.本发明第一方面提供基于自学习策略的跨模态知识蒸馏方法,包括以下步骤:
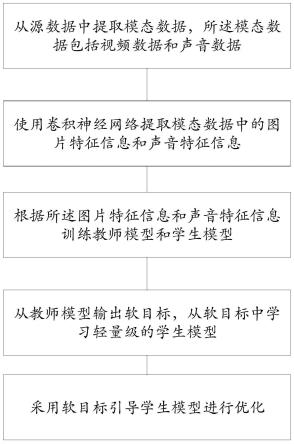
8.s1、从源数据中提取模态数据,所述模态数据包括视频数据和声音数据,使用卷积神经网络提取模态数据中的图片特征信息和声音特征信息;
9.s2、根据所述图片特征信息和声音特征信息训练教师模型和学生模型;
10.s3、从教师模型输出软目标,使用卷积神经网络从软目标中学习学生模型;
11.s4、采用软目标引导学生模型进行优化。
12.根据上述技术,通过利用神经网络自学习优化策略,根据所述图片特征信息和声音特征信息训练教师模型和学生模型;从教师模型输出软目标,使用卷积神经网络从软目标中学习学生模型;通过将不同模态数据的特征嵌入到单模态数据的学生网络中,一方面,能提高模型在预测时的性能,另一方面,能在低资源设备上高效运行深度学习模型;解决传统模型部署具有模型太大导致无法在低资源设备上运行;模型在设备端实时性不高;在设备上部署后,消耗过大的能耗的问题。
13.在一种可能的设计中,获取相关的未经过训练的图片或视频作为测试数据,并对所述教师模型与学生模型进行测试,获取学生模型和教师模型的性能结果。
14.在一种可能的设计中,采用软目标引导学生模型进行优化的方法包括以下步骤:
15.s401、根据教师网络和学生网络通过前向传播方式得到各自的教师网络软目标与学生网络软目标;
16.s402、根据教师网络软目标与学生网络软目标进行计算蒸馏损失;
17.s403、通过所述蒸馏损失,再利用反向传播方式中的随机梯度下降方式进行神经网络各层更新参数和权重,从而优化模型。
18.根据上述技术跨模态知识蒸馏是获取高效网络的方法,能够解决高性能深度学习网络无法在低资源设备上运行深度学习模型;通过跨模态的数据集来实现少样本学习或半监督学习,减少对带标签数据的依赖;跨模态知识蒸馏对高深度学习模型的性能有显著效果,在模型压缩和模型增强方面有优越特性。
19.本发明第二方面提供了基于自学习策略的跨模态知识蒸馏装置,包括
20.模态数据提取模块,用于从源数据中提取模态数据,所述模态数据包括视频数据和声音数据;
21.特征信息提取模块,用于使用卷积神经网络提取模态数据中的图片特征信息和声音特征信息;
22.模型训练模块,用于根据所述图片特征信息和声音特征信息训练教师模型和学生模型;
23.软目标获取模块,用于从教师模型输出软目标;
24.轻量级学生模型获取模块,用于使用卷积神经网络从软目标中学习学生模型;以及
25.模型优化模块,用于采用软目标引导学生模型进行优化。
26.在一种可能的设计中,还包括模型模块测试,用于获取相关的未经过训练的图片或视频作为测试数据,并对所述教师模型与学生模型进行测试,获取学生模型和教师模型的性能结果。
27.在一种可能的设计中,所述优化模块包括:
28.软目标获取单元,用于根据教师网络和学生网络通过前向传播方式得到各自的教师网络软目标与学生网络软目标;
29.蒸馏损失获取单元,用于根据教师网络软目标与学生网络软目标进行计算蒸馏损失;以及
30.参数权重计算单元,通过所述蒸馏损失,再利用反向传播方式中的随机梯度下降方式进行更新参数和权重,从而优化模型。
31.本发明第三方面提供了一种基于自学习策略的跨模态知识蒸馏装置,包括存储器和处理器,所述存储器与处理器之间通过总线相互连接;所述存储器存储计算机执行指令;所述处理器执行存储器存储的计算机执行指令,使得处理器执行如本发明第二方面以及第二方面中任意一项可能的设计中提供所述的基于自学习策略的跨模态知识蒸馏方法。
32.本发明第四方面提供了一种存储介质,所述存储介质上存储有指令,当所述指令在计算机上运行时,执行如本发明第二方面以及第二方面中任意一项可能的设计中所述的基于自学习策略的跨模态知识蒸馏方法。
33.有益效果:
34.1、本发明提供的一种基于自学习策略的跨模态知识蒸馏方法,通过利用神经网络自学习优化策略,根据所述图片特征信息和声音特征信息训练教师模型和学生模型;从教师模型输出软目标,使用卷积神经网络从软目标中学习学生模型;通过将不同模态数据的
特征嵌入到单模态数据的学生网络中,一方面,能提高模型在预测时的性能,另一方面,能在低资源设备上高效运行深度学习模型;解决传统模型部署具有模型太大导致无法在低资源设备上运行;模型在设备端实时性不高;在设备上部署后,消耗过大的能耗的问题;
35.2、本发明提供的一种基于自学习策略的跨模态知识蒸馏方法,跨模态知识蒸馏是获取高效网络的方法,能够解决高性能深度学习网络无法在低资源设备上运行深度学习模型;通过跨模态的数据集来实现少样本学习或半监督学习,减少对带标签数据的依赖;跨模态知识蒸馏对高深度学习模型的性能有显著效果,在模型压缩和模型增强方面有优越特性。
附图说明
36.为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍。
37.图1为本发明提供的一种基于自学习策略的跨模态知识蒸馏方法的流程示意图;
38.图2为本发明提供的一种基于自学习策略的跨模态知识蒸馏装置的模块示意图。
具体实施方式
39.下面结合附图及具体实施例来对本发明作进一步阐述。在此需要说明的是,对于这些实施例方式的说明虽然是用于帮助理解本发明,但并不构成对本发明的限定。
40.如图1所示,本发明第一方面提供的所述基于自学习策略的跨模态知识蒸馏方法,包括以下步骤:
41.s1、从源数据中提取模态数据,所述模态数据包括视频数据和声音数据,使用卷积神经网络提取模态数据中的图片特征信息和声音特征信息;
42.s2、根据所述图片特征信息和声音特征信息训练教师模型和学生模型;
43.s3、从教师模型输出软目标,使用卷积神经网络从软目标中学习学生模型;
44.s4、采用软目标引导学生模型进行优化。
45.在一种可能的实施方式中,获取相关的未经过训练的图片或视频作为测试数据,具体的,测试数据为:采用动作识别工具对图片或视频进行动作识别并建立动作识别数据集,主要包括5大类动作:人与物体交互、单纯的肌体动作、人与人交互、演奏乐器和体育运动;并对所述教师模型与学生模型进行测试,获取学生模型和教师模型的性能结果。
46.在一种可能的实施方式中,采用软目标引导学生模型进行优化的方法包括以下步骤:
47.s401、根据教师网络和学生网络通过前向传播方式得到各自的教师网络软目标与学生网络软目标;
48.s402、根据教师网络软目标与学生网络软目标进行计算蒸馏损失;
49.s403、通过所述蒸馏损失,再利用反向传播方式中的随机梯度下降方式进行更新参数和权重,从而优化模型。
50.综上,本实施例通过利用神经网络自学习优化策略,根据所述图片特征信息和声音特征信息训练教师模型和学生模型;从教师模型输出软目标,使用卷积神经网络从软目标中学习学生模型;通过将不同模态数据的特征嵌入到单模态数据的学生网络中,一方面,
input first output,fifo)和/或先进后出存储器(first input last output,filo)等等;具体地,处理器可以包括一个或多个处理核心,比如4核心处理器、8核心处理器等。处理器可以采用dsp(digital signal processing,数字信号处理)、fpga(field-programmable gate array,现场可编程门阵列)、pla(programmable logic array,可编程逻辑阵列)中的至少一种硬件形式来实现,同时,处理器也可以包括主处理器和协处理器,主处理器是用于对在唤醒状态下的数据进行处理的处理器,也称cpu(central processing unit,中央处理器);协处理器是用于对在待机状态下的数据进行处理的低功耗处理器。
67.在一些实施例中,处理器可以在集成有gpu(graphics processing unit,图像处理器),gpu用于负责显示屏所需要显示的内容的渲染和绘制,例如,所述处理器可以不限于采用型号为stm32f105系列的微处理器、精简指令集计算机(reduced instruction set computer,risc)微处理器、x86等架构处理器或集成嵌入式神经网络处理器(neural-network processing units,npu)的处理器;所述收发器可以但不限于为有线收发、无线保真(wifi)无线收发器、蓝牙无线收发器、通用分组无线服务技术(general packet radio service,gprs)无线收发器、紫蜂协议(基于ieee802.15.4标准的低功耗局域网协议,zigbee)无线收发器、3g收发器、4g收发器和/或5g收发器等。此外,所述装置还可以但不限于包括有电源模块、显示屏和其它必要的部件。
68.本发明第四方面提供了一种存储介质,所述存储介质上存储有指令,当所述指令在计算机上运行时,执行如本发明第一方面以及第一方面中任意一项可能的实施方式中所述的基于自学习策略的跨模态知识蒸馏方法。所述计算机可读存储介质是指存储数据的载体,可以但不限于包括软盘、光盘、硬盘、闪存、优盘和/或记忆棒(memory stick)等,所述计算机可以是通用计算机、专用计算机、计算机网络、或者其他可编程装置。
69.综上所述,本发明利用神经网络自学习优化策略,通过将不同模态数据的特征嵌入到单模态数据的学生网络中,一方面,能提高模型在预测时的性能,另一方面,能在低资源设备上高效运行深度学习模型。与现有技术相比,本发明由于采用了以上的方案,可实现以下优点:
70.1)跨模态知识蒸馏是获取高效网络的一种新型方法,能够解决高性能深度学习网络无法在低资源设备上运行深度学习模型;
71.2)通过跨模态的数据集来实现少样本学习或半监督学习,减少对带标签数据的依赖;
72.3)跨模态知识蒸馏对高深度学习模型的性能有显著效果,在模型压缩和模型增强方面有优越特性。
73.最后应说明的是,以上所述仅为本发明的优选实施例而已,并不用于限制本发明的保护范围。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1