一种基于U-net网络的线谱干扰自动检测方法与流程
一种基于u-net网络的线谱干扰自动检测方法
技术领域
1.本发明属于声学设备目标检测技术领域,具体涉及一种基于u-net网络的线谱干扰自动检测方法。
背景技术:
2.水下平台搭载的多种声学设备及平台之间有可能产生相互干扰。声学发射装置的非线性和平台动力设备动力装置的周期运动辐射出的周期信号,成为声学设备探测目标时的强线谱干扰,严重影响的声学设备的目标检测性能。而且线谱频率随发射装置辐射信号和平台工况而具有时变性,无法通过简单的线谱剔除实现干扰的消除。因此时变线谱信号的自动检测成为实现声学设备声兼容性的必要前提。
3.动态规划进行单频线跟踪把数据当作一段含有噪声的时间信号序列,此时可以通过维特比算法估计频率线位置。基于马尔科夫模型(hidden markov models,hmm)的频线跟踪方法以位置和速度二维状态向量构建滤波器,并在马尔科夫模型中引入谱功率概率积分,提高了线谱提取质量。这两种基于先验模型的方法在数据与模型失配时效果不佳。主动轮廓能量最小化(contour energy minimisation,cem)谱图轨迹检测算法定义能量最小化过程,此过程受到内部能量的约束,内部能量根据曲率和连通性等条件约束线谱形状,使得线谱形状和其局部能量梯度变化一致。该方法对于不规则波动线谱检测准确率依然较低。
4.随着深度卷积神经网络在图像分割方面取得了一系列突破。深度卷积神经网络把输入转换为抽象的高级特征,从而放大重要方面,同时抑制无关的变化。2015年,由he等提出残差结构,残差结构在一定程度上解决了这种退化现象。基于编码器和解码器结构的卷积网络在图像像素预测上有着更好的效果,long等提出了全卷积神经网络(full connected network,fcn)用于图像的分割。该方法在采样过程中会损失部分信息,从而得到更为重要的特征,然后通过上采样操作可以得到更精确的分割边界。但此过程是不可逆转的,有时甚至会导致图像分辨率低以及细节丢失。fcn方法是一种反卷积采样结构,其核心思想是经过采样扩大像素,再进行卷积并通过学习获得权值。其优点是可以接受任意大小的输入图像,并保留其空间信息,解决了图像语义级分割问题。但由于每个像素的上采样都是单独分开执行的,因此没有考虑像素之间的关系和缺乏空间一致性,从而导致部分结果模糊以及对图像细节处理不敏感。ronneberger等提出u型网络(u-net),它主要由收缩路径(特征提取)和扩展路径(上采样)两部分组成。收缩路径部分用于捕获图像中的上下文信息,而上采样部分则用于恢复图像位置信息。但是,该上采样方法不考虑每个像素预测之间的相关性,导致它在精确恢复像素预测方面的能力有限。
技术实现要素:
5.有鉴于此,本发明的目的在于提供一种基于u-net网络的线谱干扰自动检测方法。
6.为达到上述目的,本发明提供如下技术方案:
7.一种基于u-net网络的线谱干扰自动检测方法,包括以下步骤:
8.s1:获取实验数据的lofar谱图作为模型输入;
9.s2:建立检测模型,以u-net作为网络主体框架;
10.s3:引入残差结构,在编码器部分加入残差单元;
11.s4:在残差单元后引入特征通道注意力机制;
12.s5:在解码器部分采用dupsampling上采样方法;
13.s6:使用训练数据训练模型,应用到测试数据集。
14.进一步,所述u-net网络结构包括编码器和解码器,所述编码器向下采样输入以提取特征,解码器向上采样输入以恢复分辨率;编码器以残差单元(residual unit)作为主体提取特征,并加入特征通道注意力模块;特征通道注意力模块对提取的特征在通道维度上进行重新标定;然后max pool下采样,采样之后的输出通道数为原来通道数的2倍;在解码器部分用dupsampling上采样代替传统的双线性插值上采样,上采样后输出的通道数为输入通道数的一半;再经过一个2个3
×
3卷积层作用,每个卷积层之后每个都有规范化处理(batch normalization,bn)和relu激活函数;每层之间都有一个跳跃连接,用于在解码时结合相应的编码特征。
15.进一步,步骤s3中所述在编码器部分加入残差单元,具体包括:
16.输入x,输出h(x)=f(x)+x,通过“捷径连接”,把输入x作为结果的一部分输出,学习的目标为f(x)=h(x)-x,训练的目标是使残差趋向于0;u-net网络中每个3
×
3卷积层之后都有规范化操作和relu激活函数。
17.进一步,步骤s4所述在残差单元后引入特征通道注意力机制,具体为在编码器3
×
3卷积之后增加压缩激励(sequeeze and excitation,se)模块,所述se模块在训练过程中学习到卷积层提取到的不同特征对于线谱提取的重要性,再通过对每个特征通道特征重标定;
18.卷积层计算得出特征u=[u1,u2...,uc],uc表示任意一个特征通道的特征图,采用全局平均池化将每个通道上的特征图压缩为一个有全局感受野的实数,压缩后的特征z∈rc,rc表示所有通道特征,z=[z1,z2...,zc],zc表示任意一个通道上的全局特征,计算公式如下:
[0019][0020]
其中,f
sq
(ue)表示,h表示特征图高,w表示特征图宽,i表示从1取到h的数值,j表示从1取到w的数值,uc(i,j)表示任意一个特征通道的特征图;
[0021]
经过压缩之后的特征图通过2个全连接层fc,relu激活函数,最后通过sigmoid激活函数得到归一化特征权重s,计算公式如下:
[0022]
s=f(s,w)=σ(g(z,w))=σ(w2δ(w1z))
ꢀꢀꢀꢀ
(2)
[0023]
其中σ表示sigmoid激活函数,δ表示relu激活函数,g(z,w)表示平均池化函数,r为超参数,最后,对卷积层输出特征u进行权值重标定;把各个通道的权重s与特征u做权重相乘,如下计算:
[0024]
[0025]
输出特征表示任意一个通道输出特征图;
[0026]
对于各个通道输出特征,权重s的值可以调节通道之间的相关性;在网络训练过程中,对于与线谱提取的有用特征,通过se模块加大对应特征通道的权重值,以增强相应特征响应,同时,对于无用和干扰特征,减小对应特征通道的权重值,抑制相应特征。
[0027]
进一步,步骤s5所述在解码器部分采用dupsampling上采样方法,具体包括:
[0028]
使用h,w,c分别是特征图的高度,宽度,特征通道数;1
×
c表示输入特征图中每个像素的特征维度,将其乘上维度为c
×
n的矩阵w,得到一个1
×
n的特征表示,最后将其rearrange为2
×2×
n/4的特征表示;
[0029]
所述矩阵w是根据已知的训练标签得到的,然后对每个分割图进行矩阵变换,其过程如下:
[0030]
x=pv
ꢀꢀꢀꢀ
(4)
[0031][0032]
其中,v表示的是真正分割结果中的区域,矩阵p是矩阵w的逆变换;通过矩阵p对v进行压缩;p矩阵和矩阵w通过最小化v和误差得到,过程如下:
[0033][0034]
编码器有四次下采样,对应的解码器有4次dupsampling上采样,并且编码器和解码器之间有跳跃连接。
[0035]
本发明的有益效果在于:
[0036]
1、本发明中模型以u-net作为网络主体框架,引入残差结构,在编码器部分加入残差单元,增加网络的深度,增强了模型特征学习能力;
[0037]
2、本发明在残差单元后引入特征通道注意力机制,使模型学习到线谱特征图通道之间的不同特征的重要程度,从而提升模型的特征表达能力;
[0038]
3、本发明在解码器部分采用dupsampling上采样方法,dupsampling利用了分割标签空间中的冗余优势恢复编码路径中丢失的细粒度信息,增大特征图的分辨率,可以更准确的恢复线谱像素级预测。
[0039]
本发明的其他优点、目标和特征将在随后的说明书中进行阐述,并且在某种程度上对本领域技术人员而言是显而易见的,或者本领域技术人员可以从本发明的实践中得到教导。本发明的目标和其他优点可以通过下面的说明书来实现和获得。
附图说明
[0040]
为了使本发明的目的、技术方案和有益效果更加清楚,本发明提供如下附图进行说明:
[0041]
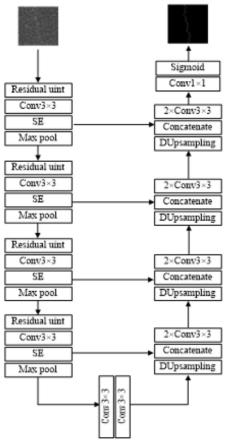
图1为本发明所述基于u-net网络的线谱干扰自动检测方法的网络结构图;
[0042]
图2为残差结构;
[0043]
图3为残差单元;
[0044]
图4为se模块;
[0045]
图5为se模块内部结构;
[0046]
图6为dupsampling过程;
[0047]
图7为lofar谱图制作过程;
[0048]
图8为数据增强示意图,其中(a)为原图,(b)为垂直翻转图,(c)为水平翻转图;
[0049]
图9为不同模型的线谱位置准确率;
[0050]
图10为不同信噪比lofar线谱检测效果图,其中(a)、(e)、(i)分别为信噪比-20db、-22db、-24db的lofar谱图,(b)、(f)、(j)分别为hmm模型在信噪比-20db、-22db、-24db下的lofar谱图线谱检测结果,(c)、(g)、(k)分别为cem模型在信噪比-20db、-22db、-24db下的lofar谱图线谱检测结果,(d)、(h)、(1)分别为hmm模型在信噪比-20db、-22db、-24db下的lofar谱图线谱检测结果。
具体实施方式
[0051]
本发明提供一种基于u-net网络的线谱干扰自动检测方法,所述方法包括以下步骤:
[0052]
步骤1)获取实验数据的lofar谱图作为模型输入;
[0053]
步骤2)建立检测模型,以u-net作为网络主体框架;u-net网络结构如图1,整体分为编码器和解码器两个部分,编码器向下采样输入以提取特征,而解码器向上采样输入以恢复分辨率。网络使用一个224
×
224的灰度图片作为编码器的输入,编码器以残差单元(residua1unit)作为主体提取特征,并加入特征通道注意力模块。特征通道注意力模块对提取的特征在通道维度上进行重新标定。然后max pool下采样,采样之后的输出通道数为原来通道数的2倍。在解码器部分用dupsampling上采样代替传统的双线性插值上采样,上采样后输出的通道数为输入通道数的一半。再经过一个2个3
×
3卷积层作用,每个卷积层之后每个都有规范化处理(batch normalization,bn)和relu激活函数。每层之间都有一个跳跃连接,以便解码时结合相应的编码特征。
[0054]
步骤3)引入残差结构,在编码器部分加入残差单元;如图2所示,假设x是输入,输出是h(x)=f(x)+x,h(x)是一个复杂的潜在映射,要想学习这样的模型,训练的难度较大。如图,通过“捷径连接”,直接把输入x作为结果的一部分输出。当f(x)=0时,h(x)=x,这就是恒等映射。此时学习的目标已经变为f(x),f(x)=h(x)-x,即所谓的残差,训练的目标是使残差趋向于0。残差网络通过将输入与多个卷积层输出结果相加的方式,加深了网络深度,减少了训练误差,获得了更多特征语义信息、。
[0055]
图3为本文残差单元模块,每个3
×
3卷积层之后都有规范化操作和relu激活函数。
[0056]
步骤4)在残差单元后引入特征通道注意力机制;注意力模块能让网络选择聚焦位置,产生更具分辨性的特征表示。普通的卷积无法提取不同特征的重要程度,本发明引入特征通道注意力模块,在编码器3
×
3卷积之后增加压缩激励(sequeeze and excitation,se)模块。如图4所示,se模块在训练过程中学习到卷积层提取到的不同特征对于线谱提取的重要性,再通过对每个特征通道特征重标定,从而增强模型对有用特征的响应,抑制不重要特征,提升模型的特征表示能力。
[0057]
卷积层计算得出特征u=[u1,u2...,uc],uc表示任意一个特征通道的特征图。采用
全局平均池化将每个通道上的特征图压缩为一个有全局感受野的实数,假设压缩后的特征z∈rc,z=[z1,z2...,zc]:zc表示任意一个通道上的全局特征,计算公式如下:
[0058][0059]
如图5所示,经过压缩之后的特征图通过2个全连接层fc,relu激活函数,最后通过sigmoid激活函数得到归一化特征权重s。
[0060]
s计算公式如下:
[0061]
s=f(s,w)=σ(g(z,w))=σ(w2δ(w1z))
ꢀꢀꢀꢀꢀꢀ
(2)
[0062]
其中σ和δ分别表示sigmoid激活函数和relu激活函数。r为超参数。最后,对卷积层输出特征u进行权值重标定,
[0063]
把各个通道的权重s与特征u做权重相乘,如下计算:
[0064][0065]
输出特征表示任意一个通道输出特征图。对于各个通道输出特征,权重s的值可以调节通道之间的相关性。在网络训练过程中,对于与线谱提取的有用特征,通过se模块,加大对应特征通道的权重值,以增强相应特征响应;同时,对于无用和干扰特征,减小对应特征通道的权重值,抑制相应特征。通过引入注意力机制,让网络提取特征的指向性更强,从而进一步增强模型的线谱提取能力。
[0066]
步骤5)在解码器部分采用dupsampling上采样方法;
[0067]
在解码模块部分,网络采用的上采样方法不是u-net的双线性插值法,而是选择dupsampling,这是一种依赖数据的上采样结构。双线性插值法不考虑每个像素预测之间的相关性,导致它在精确恢复像素预测方面的能力有限。dupsampling利用了分割标签空间中的冗余能力,能从相对粗糙的卷积网络输出中准确的恢复像素级预测,通过编码器生成的粗糙特征也能获得精确的分割结果。
[0068]
dupsampling的采样过程如图6所示,h,w,c分别是特征图的高度,宽度,特征通道数,1
×
c表示输入特征图中每个像素的特征维度,将其乘上维度为c
×
n的矩阵w,得到一个1
×
n的特征表示。最后将其rearrange为2
×2×
n/4的特征表示,上采样过程就完成了。
[0069]
上面的矩阵w是根据已知的训练标签得到的,是真实的结果。然后对每个分割图进行矩阵变换,其过程如下:
[0070]
x=pv
ꢀꢀꢀꢀꢀꢀꢀ
(4)
[0071][0072]
其中,v表示的是真正分割结果中的区域,矩阵p是矩阵w的逆变换。通过矩阵p对v进行压缩。p矩阵和矩阵w可以通过最小化v和误差得到。过程如下:
[0073][0074]
编码器模块有四次下采样,对应的解码器模块有4次dupsampling上采样,并且编
码器和解码器之间有跳跃连接,使得解码器可以获得编码的特征信息,减少解码过程中的信息丢失。通过四次上采样,可以有效的恢复线谱特征图信息。
[0075]
步骤6)使用训练数据训练模型,应用到测试数据集。
[0076]
在本实施例中,lofar谱图制作流程如图7所示,假设系统输入信号为s(t):
[0077][0078]
t是时间,f是随机变化的频率,η(t)是均值为0,方差为的σ2高斯白噪声。首先,s(t)把输入信号分割成k帧,第k帧和第k-1帧可以部分重叠。通过短时傅立叶变换(stft)得到每帧的功率谱图,按照时间顺序把每帧功率谱连接起来,形成一幅lofar谱图
[16]
。信噪比(signal to noise ratio,snr)定义如下:
[0079][0080]
其中ps表示信号功率,pn表示噪声功率,a是信号幅值,σ2为噪声方差。根据公式(8)可以得到指定信噪比的lofar谱图。
[0081]
lofar谱图训练集为2000张,测试集为100张。如图8(a)~(c)所示,对训练集进行垂直翻转,水平翻转数据增强操作,防止网络过拟合。所有训练集和测试集大小为224
×
224,并对其进行灰度化和归一化。先用snr为-18db到-21db的lofar谱图预训练网络,学习率为0.001。然后再用-21db到-24db的lofar谱图训练网络,学习率调整为0.0001。采用adam优化器进行优化,动量参数设置为0.9,batch-size设置为2,网络训练迭代60次。
[0082]
采用一种用于lofar谱线检测效果的评估指标来衡量网络的性能。由pratt提出的线位置准确率(line location accuracy,lla),评价指标定义如下:
[0083][0084]
其中p
t
表示预测谱线,d
t
是谱线标签,||[l,m]-[i,j]||2表示检测到的谱线与实际谱线的欧氏距离。根据经验,把λ设置为1。
[0085]
在信噪比为-24db至-20db下蒙特卡罗试验次数100次。将本文模型与hmm模型和cem模型在其上进行测试,并计算线谱检测准确率平均值。实验结果如图9所示,信噪比为-20db至-24db时,hmm模型的线谱检测准确率为0.184~0.319。cem模型的线谱检测准确率为0.194~0.358,本文模型线谱检测准确率为0.314~0.526。实验结果表明,所提模型在低信噪比下线谱检测效果优于hmm模型和cem模型。
[0086]
图10是本发明所述模型与cem模型在信噪比-20db,-22db,-24db的lofar谱图线谱检测结果。图10中第一列(a)(e)(i)是不同信噪比的lofar谱图。图10中第四列(d)(h)(1)是所提模型对不同信噪比的lofar谱图提取结果。实验的真值图如图8(a)所示。对比观察图中,cem(即图10中的(c)(g)(k))和hmm(即图10中的(b)(f)(j))在信噪比为-20db时,谱线轮廓开始模糊。在-22db时,看不到谱线的变化趋势。而本文模型信噪比为在-20db和-22db时,线谱轮廓较为明显,谱线整体变化趋势依然和真值一致,而在信噪比为-24db时,由于背景
噪声太强,网络已经难以提取到足够特征,谱线轮廓开始模糊。
[0087]
最后说明的是,以上优选实施例仅用以说明本发明的技术方案而非限制,尽管通过上述优选实施例已经对本发明进行了详细的描述,但本领域技术人员应当理解,可以在形式上和细节上对其作出各种各样的改变,而不偏离本发明权利要求书所限定的范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1