一种融合知识图谱的检索式知识前缀引导视觉问答方法
1.本发明属于视觉问答技术领域,具体涉及一种融合知识图谱的检索式知识前缀引导视觉问答方法。
背景技术:
2.视觉问答任务是指根据给定的图像回答自然语言问题。近年来,利用外部知识进行开放世界场景理解的视觉问答(又称基于知识的知识问答)得到了发展。
3.现有技术中,根据如何吸收知识,可将现有的视觉问答分为两类。一类是直接利用语言模型参数中的隐藏的知识回答问题,实现视觉问答。具体而言,受自然语言处理领域基于知识的语言模型的启发,一些方法试图在语言模型训练中注入常识或事实知识作为语言模型参数的一部分。例如文献(ning bian,xianpei han,bo chen,and le sun.2021.benchmarking knowledge-enhanced commonsense question answering via knowledge-to-text transformation.in aaai.aaai press,12574
–
12582)公开的方法。但是对于知识问答场景,语言模型中的隐藏知识有时是不够用的,在引用新的知识时很可能会导致问答失败。并且这些基于编码器的微调语言模型,由于在模型的最后一层附加多层感知机,这直接限制了语言模型中对知识的直接利用,进而限制了视觉问答任务的应用。
4.第二类是模型基于知识召回策略进行视觉问答,这一类方法通常把视觉-语言信息通过搜索引擎进行信息检索,例如文献(gard
è
res,maryam ziaeefard,baptiste abeloos,and freddy l
é
cu
é
.2020.conceptbert:concept-aware representation for visual question answering.in emnlp(findings)(findings of acl,vol.emnlp 2020).association for computational linguistics,489
–
498)公开的方法,在这种情况下网络延迟成为应用瓶颈。再者,从百科全书文章中检索相关的语料库,而这导致了大量不相关的文本信息被引入,从而影响模型在视觉问答任务的判断。
5.更重要是的,目前所有数据集和现实场景中,对于图像和问题很少含有对应标注的支撑知识数据,并不利于模型进行精确的知识召回训练及评估。
技术实现要素:
6.鉴于上述,本发明的目的是提供一种融合知识图谱的检索式知识前缀引导视觉问答方法,通过构建背景知识库,并基于背景知识库配合检索器和阅读器的协同工作,提升考虑外部知识的视觉问答的准确性。
7.为实现上述发明目的,实施例提供的一种融合知识图谱的检索式知识前缀引导视觉问答方法,包括以下步骤:
8.构建背景知识库,背景知识库中包含有与视觉问答语料相关的事实三元组;
9.针对视觉问答的图像-问题对,将图像转换为文本描述后,为文本描述与问题添加前缀后构建背景文本序列;
10.根据文本描述和问题构建词干集合后,利用基于词干匹配的检索器从背景知识库
中为词干集合中的词干匹配事实三元组,并将事实三元组转换为自然语言文本后添加前缀构建知识文本序列;
11.构建图像编码器和阅读器,图像编码器用于对图像-问题对中的图像进行编码得到图像编码向量;阅读器用于根据背景文本序列、知识文本序列以及图像编码向量进行视觉问题任务的答案预测;
12.对图像编码器和阅读器初步训练优化后,构建孪生检索器,在给定背景知识库中召回知识的情况下,以阅读器的预测答案中正确答案与阅读器中知识部分的注意力权重作为弱监督信号,训练孪生检索器;
13.孪生检索器初步训练后,将初步训练的孪生检索器替换基于词干的检索器,然后交替再训练阅读器和图像编码器、孪生检索器;
14.利用再训练后的孪生检索器、阅读器以及图像编码器进行视觉问答。
15.优选地,在构建背景知识库时,合并多个语义知识库得到初步背景语料库,然后保留初步背景语料中头实体或者尾实体包含在视觉问答语料和常识知识的三元组,接下来根据阈值将初步背景语料库中关系分为频繁关系和非频繁关系,对于头尾实体相同,且关系同时包含频繁关系和非频繁关系的三元组,删除包含频繁关系的三元组,剩下的三元组组成背景知识库。
16.优选地,采用基于transformer的预先训练图像注释模型将图像转换为文本描述;
17.分别提取文本描述和问题中词干并去重后得到词干集合,基于词干匹配的检索器基于词干匹配的bm25分数从背景知识库中通过匹配召回与词干匹配的事实三元组。
18.优选地,所述阅读器采用经过文本语料预先训练的、基于预先训练编码器-解码器transformer框架的语言模型,其中,transformer编码器用于结合模态内注意力机制对输入的背景文本序列、知识文本序列以及图像编码向量分别进行独立编码,得到三类编码向量;transformer解码器用于基于注意力机制对输入的三类编码向量进行跨模态联合解码以输出预测答案。
19.优选地,在对图像编码器和阅读器初步训练优化时,采用一种延迟知识注入的方式,并采用最小化负对数似然函数作为损失函数
[0020][0021]
其中,q,v,s
fact
分别表示问题、图像转换的文本描述以及知识文本序列,y表示图像-问题对应标准答案的令牌化表示,yj表示预测的第j字符,p(yj∣∣y
《j
,q,v,s
fact
)表示根据前j个预测字符、问题、图像转换的文本描述以及知识文本序列预测第j个字符的概率。
[0022]
优选地,所述孪生检索器包括两个编码器,通过kl散度作为训练损失函数训练孪生检索器:
[0023]
[0024][0025][0026]
其中,q表示来自于词干集合s
query
的问题,f和f
′
均表示来自于三元组集合的知识文本序列,atten
q,f
表示给定问题下不同三元组对应的知识文本序列在阅读器中的注意力权重,和e
μ
(
·
)表示孪生检索器的两个检索器。
[0027]
优选地,所述孪生检索器包含的每个编码器采用预先训练编码器transformer框架的语言模型。
[0028]
优选地,交替再训练阅读器和图像编码器、孪生检索器时,固定孪生检索器,同时优化阅读器和图像编码器的参数,然后,在固定阅读器和图像编码器,优化孪生检索器的参数,实现一种协同训练。
[0029]
优选地,利用再训练后的孪生检索器、阅读器以及图像编码器进行视觉问答,包括:
[0030]
针对待问答的图像-问题对,将图像转换为文本描述后,为文本描述与问题添加前缀后构建背景文本序列;
[0031]
利用孪生检索器对背景文本序列进行编码,并将编码结果与背景知识库中的所有事实三元组进行相似度计算后,筛选相似度大的事实三元组构建知识文本序列;
[0032]
利用图像编码器对图像-问题对中的图像进行编码得到图像编码向量;
[0033]
将背景文本序列、知识文本序列以及图像编码向量输入至阅读器,经过计算输出预测答案。
[0034]
与现有技术相比,本发明具有的有益效果至少包括:
[0035]
构建的背景知识库包含有标注的大量通用常识与知识数据,该知识数据利不仅可以用于知识召回,在未来还可以动态扩充,针对不同领域进行相关知识筛选。在此基础上,通过基于词干匹配的检索器检索构建知识文本序列对图像编码器和阅读器进行初训练,以在阅读器中引入知识,然后通过孪生检索器对图像编码器和阅读器进行再训练,以增强阅读器对知识的感知,这种基于背景知识库配合检索器和阅读器的协同工作,提升考虑外部知识的视觉问答的准确性。
附图说明
[0036]
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图做简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动前提下,还可以根据这些附图获得其他附图。
[0037]
图1是实施例提供的融合知识图谱的检索式知识前缀引导视觉问答方法的流程
图;
[0038]
图2是实施例提供的延迟知识注入的原理图;
[0039]
图3是实施例提供的根据可导孪生检索器进行再训练示意图。
具体实施方式
[0040]
为使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例对本发明进行进一步的详细说明。应当理解,此处所描述的具体实施方式仅仅用以解释本发明,并不限定本发明的保护范围。
[0041]
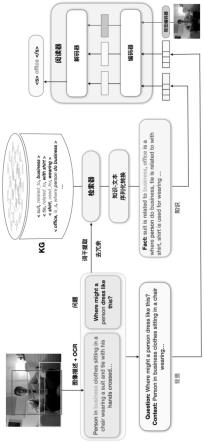
实施例提供了一种融合知识图谱的检索式知识前缀引导视觉问答方法,如图1所示,实施例提供的融合知识图谱的检索式知识前缀引导视觉问答方法,包括以下步骤:
[0042]
步骤1,构建背景知识库,背景知识库中包含有与视觉问答语料相关的事实三元组。
[0043]
实施例中,在构建背景知识库kg时,合并多个知识库得到初步背景语料库,然后保留初步背景语料中头实体或者尾实体包含在视觉问答语料和常识知识的三元组,接下来根据阈值(例如该阈值取值为一万次)将初步背景语料库中关系分为频繁关系和非频繁关系,对于头尾实体相同,且关系同时包含频繁关系和非频繁关系的三元组,删除包含频繁关系的三元组,剩下的三元组用来构建背景知识库。例如,关系“related_to”,“used_for”,“at_location”,“is_a”,这些关系出现的频率比较高,高于设定阈值,则这些关系是频繁关系。
[0044]
其中,多个知识库包括四个公开的语义知识库,分别为conceptnet、webchild、dbpedia以及haspart kb。其中,conceptnet包括了人类对于世界的常识知识。webchild包含通过更细粒度的关系连接名词和形容词的三元组,例如,hasshape,faster。dbpedia包括从wikipedia中抽取的知识三元组,其覆盖生活的诸多方面。haspart kb收集普通物体之间的“has part”关系,如《狗,has part,胡须》或科学上的一些关系,如《分子,has part,原子》)。将这些语义知识库合并得到初步背景语料库。
[0045]
实施例中,将所有视觉问答领域的问题、答案、图像描述、ocr文本取并集得到词表,然后将词表中停用词去除得到视觉问答语料。
[0046]
步骤2,针对视觉问答的图像-问题对,将图像转换为文本描述后,为文本描述与问题添加前缀后构建背景文本序列。
[0047]
实施例中,针对给定的图像-问题对,采用基于transformer的预先训练图像注释(caption)模型将图像转换为文本描述后,为文本描述添加前缀context,为问题添加前缀question,即使用前缀context和前缀question区分和间隔文本描述和问题以构建背景文本序列。增加的前缀起到了对于阅读器中蕴含知识的引导挖掘作用,这样做的目的是实现对于阅读器中蕴含知识的合理提取。
[0048]
步骤3,根据文本描述和问题构建词干集合后,利用基于词干匹配的检索器从背景知识库中为词干集合中的词干匹配事实三元组,并将事实三元组转换为自然语言文本后添加前缀构建知识文本序列。
[0049]
实施例中,分别提取文本描述和问题中词干并去重后得到词干集合,基于词干匹配的检索器(retriever)基于词干匹配的bm25分数从背景知识库中通过匹配召回与词干匹配的事实三元组sf。具体地,基于bm25分数采用以下公式计算:
[0050][0051][0052]
其中,s
query
是词干集合,由词干s1,s2,
…
,s
t
组成并表示。wi代表某一词干si的重要性。r(si,sf)表示si和sf的语义相关性。n(si)代表包含词干si的事实三元组实数量,n代表背景知识库中事实三元组的总数。超参数0.5主要用来实现计算的平滑性,score(s
query
,sf)表示sf与s
query
的匹配得分,依据匹配得分筛选事实三元组。
[0053]
使用检索器召回背景知识库中相关事实三元组,如《suit,related_to,business》,《tie,related_to,with shirt》,《shirt,used_for,wearing》,基于自动生成好的模板(部分如下):
[0054][0055]
实施例中,在获得事实三元组后,通过知识转文本(knowledge-to-text transformation)技术将事实三元组转换为自然语言文本s
fact
,例如:“suit is related to business,office is where person do business,tie is related to with shirt,
…”
,同时标记每段自然语言文本来源的事实三元组,然后为自然语言文本s
fact
添加前缀fact构建知识文本序列。
[0056]
步骤4,构建图像编码器和阅读器,图像编码器用于对图像-问题对中的图像进行编码得到图像编码向量;阅读器用于根据背景文本序列、知识文本序列以及图像编码向量进行视觉问题任务的答案预测。
[0057]
实施例中,图像编码器(vision encoder)将图像转换成为固定维度的图像编码向量。阅读器(reader)采用经过文本语料预先训练的、基于预先训练编码器-解码器transformer框架的语言模型,其中,transformer编码器(encoder)用于结合模态内注意力机制对输入的背景文本序列、知识文本序列以及图像编码向量分别进行独立编码,得到三类编码向量;transformer解码器(decoder)用于基于注意力机制对输入的三类编码向量进行跨模态联合解码以输出预测答案。其中,模态内注意力机制理解为在每类输入数据中单
独采用注意力机制,例如在输入数据为背景文本序列这一类中采用注意力机制。跨模态联合编码理解为将输入背景文本序列、知识文本序列以及图像编码向量这三类数据作为整体数据,在整体数据中采用注意力机制进行联合解码。
[0058]
步骤5,对图像编码器和阅读器初步训练优化后,构建孪生检索器,在给定背景知识库中召回知识的情况下,以阅读器的预测答案中正确答案与阅读器中知识部分的注意力权重作为弱监督信号,训练孪生检索器。
[0059]
在对图像编码器和阅读器初步训练优化时,同时将背景文本序列、知识文本序列以及图像编码器对图像编码得到的图像编码向量输入至阅读器,利用编码器分别对三者进行编码得到三类编码向量后,再将三类编码向量输入至解码器,以正确答案作为监督,采用一种延迟知识注入的方式,联合训练图像编码器和阅读器,直至阅读器初步收敛。阅读器训练基于如下最小化负对数似然函数作为损失函数:
[0060][0061]
其中,q,v,s
fact
分别表示问题、图像转换的文本描述以及知识文本序列,y表示图像-问题对应标准答案的令牌化表示,yj表示预测的第j字符,p(yj∣∣y
《j
,q,v,s
fact
)表示根据前j个预测字符、问题、图像转换的文本描述以及知识文本序列预测第j个字符的概率。
[0062]
如图2所示,延迟知识注入具体指在阅读器的编码部分,将问题与图像描述对应的背景文本序列统一通过transformer架构的多层注意力机制编码,而知识对应的知识文本序列则独立编码,然后在解码部分将两者融合,其目的是为了实现知识的自我闭环,使阅读器在编码时专注于知识聚合,在解码时专注于知识推理。
[0063]
实施例中,如图3所示,孪生检索器(differentiable-retriever)包括两个编码器s和a,每个编码器采用采用预先训练编码器transformer框架的语言模型。通过kl散度作为训练损失函数训练孪生检索器:
[0064][0065][0066][0067]
其中,q表示来自于词干集合s
query
的问题,f和f
′
均表示来自于三元组集合的知识文本序列,atten
q,f
表示给定问题下不同三元组对应的知识文本序列在阅读器中的注意力权重,和e
μ
(
·
)表示孪生检索器的两个检索器。
[0068]
步骤6,孪生检索器初步训练后,将初步训练的孪生检索器替换基于词干的检索
器,然后交替再训练阅读器和图像编码器、孪生检索器。
[0069]
实施例中,交替再训练阅读器和图像编码器、孪生检索器时,固定孪生检索器,同时优化阅读器和图像编码器的参数,然后,在固定阅读器和图像编码器,优化孪生检索器的参数,实现一种协同训练。通过这样的方式,迭代训练指导全局收敛。
[0070]
步骤7,利用再训练后的孪生检索器、阅读器以及图像编码器进行视觉问答。
[0071]
实施例中,利用再训练后的孪生检索器、阅读器以及图像编码器进行视觉问答,包括:
[0072]
针对待问答的图像-问题对,将图像转换为文本描述后,为文本描述与问题添加前缀后构建背景文本序列;
[0073]
利用孪生检索器对背景文本序列进行编码,并将编码结果与背景知识库中的所有事实三元组进行相似度计算后,筛选相似度大的事实三元组构建知识文本序列;
[0074]
利用图像编码器对图像-问题对中的图像进行编码得到图像编码向量;
[0075]
将背景文本序列、知识文本序列以及图像编码向量输入至阅读器,经过计算输出预测答案。
[0076]
实施例提供的融合知识图谱的检索式知识前缀引导视觉问答方法,通过构建背景知识库,并基于背景知识库配合检索器和阅读器的协同工作,提升考虑外部知识的视觉问答的准确性。
[0077]
以上所述的具体实施方式对本发明的技术方案和有益效果进行了详细说明,应理解的是以上所述仅为本发明的最优选实施例,并不用于限制本发明,凡在本发明的原则范围内所做的任何修改、补充和等同替换等,均应包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1