一种面向zk-SNARK运算的GPU并行加速方法与流程
一种面向zk-snark运算的gpu并行加速方法
技术领域
1.本发明属于加密技术领域,具体涉及一种面向zk-snark运算的gpu并行加速方法。
背景技术:
2.零知识证明(zero-knowledge proofs,zkp)是密码学中常用的隐私保护手段之一,最早由s.goldwasser、s.micali及c.rackoff提出,其核心是零知识体系的构建。该证明过程中主要涉及两方参与者,分别是证明者(prover)p和验证者v(verifier)。设p掌握一些信息x,并希望向v证明p确实掌握了x,如果某个协议能够向v证明p确实掌握了x,同时v不能得知任何关于x本身的信息,则称该协议为零知识证明协议。零知识证明必须满足以下条件:
3.1.正确性,如果p没有掌握x,p使v相信p掌握了x的概率很低;
4.2.完备性,如果p掌握了x,p能使v以绝对优势的概率相信p掌握了x;
5.3.零知识性,v无法获取任何额外的知识,尤其是不能得知x。
6.一般而言,零知识证明构建了一套基于概率方法的证明体系。理论上,p伪造x骗取v的信任的成功率依测度收敛至零;而在实践中,则是一个极小概率事件。
7.zk-snark是zero-knowledge succinct non-interactive arguments of knowledge的简称,即简洁的非交互式的零知识证明。相较于一般的交互式零知识证明,zk-snark具有简洁性、非交互性,即zk-snark的验证信息相对简短,且无需问答式多次交互。当前实现zk-snark的算法包括:groth16、gm17和bctv14等。其中,groth16算法具有验证速度快、证明字符串短等优点,但是其可信初始化开销较大。groth16算法的实现可描述为以下过程:(1)建立r1cs至qap的转换关系;(2)准备阶段setup;(3)证明阶段prove;(4)验证阶段verify。在建立r1cs至qap转换关系阶段中,r1cs(rank 1constraint system,秩一约束系统)的实质是逻辑电路的矩阵和向量运算表示;qap(quadratic arithmetic program,二次算数程序)的实质是由矩阵和向量构成的多项式函数,而将矩阵转化为多项式函数的过程中使用了拉格朗日插值法。在准备阶段setup中,随机选取范围内的常数α,β,γ,δ,x,将x代入多项式计算利用椭圆曲线对数据进行同态隐藏,公布[α]1、[β]2、[γ]1、[δ]1、[δ]2、以及同态隐藏后的x各级幂[x]1,[x2]1,
…
[xn]1作为公共字符串。并将向量从l处切片为两段,例如切为在证明阶段prove中,prove阶段,证明者根据公共字符串以及自己的私有证据随机选择范围内的常数r,q计算[a]1,[b]2,[c]1作为证明发送给验证者。其中t(x)为选取椭圆曲线有限域时采用的模数多项式,在验证阶段verify中,验证者根据公共字符串以及命题验证下式
[0008]
gpu(graphics processing unit,图形处理器),起源于用户对于高质量画面的要求,通过将cpu从画面渲染中解放出来,既改善了画面质量,又释放了cpu算力。gpu核心相较cpu轻量很多,它将问题约束在大量的类型相同、可并行即相互无依赖的数据计算上,大幅减少了控制电路与缓存对芯片资源的占用,从而允许在相同的芯片资源与功率下提供远超cpu的核心数量,实现远超传统cpu的高性能并行计算能力。
[0009]
当前,基于zk-snark的零知识证明实现主要有以下实现方式:
[0010]
cpu实现:libsnark是一个实现了zk-snark算法的开源工具库,由scipr lab完成,支持多种约束系统的构建与转换,多种椭圆曲线,以及多种zk-snark算法。zcash团队利用rust语言开发的bellman项目也是一个实现了多种zk-snark算法的开源库,用于更新zcash中的零知识证明算法。
[0011]
专用电路:现有技术利用asic实现zk-snark中的ntt运算与multiexp运算的专用电路,通过cpu-asic的异构计算,实现了5.8以上的加速比。开源项目fpga_snark_prover试图采用cpu-fpga的异构计算,对bn-128曲线上的zk-snark进行加速,该项目尚未完成一个完整可用的证明系统,但核心算法似乎已经取得了优秀的加速效果。fpga与asic的方案虽然具有非常高的加速比以及cpu-gpu望尘莫及的功耗表现,但专用电路的引入意味着不能简单地在大多数计算机上运行,同时其本身设计的可移植性也较差,面对不同的场景需要投入大量人力物力设计与开发。
[0012]
gpu加速方案:采用cpu-gpu的异构计算能够在大多数具有gpu的机器上直接执行,并且cuda编程的泛用性与扩展性高,开发代价远低于硬件开发,因此cpu-gpu异构计算加速的研究同样十分重要。现有技术使用cpu-gpu异构计算针对证明系统中使用到zk-snark算法的porep、winning post、window post约束电路计算过程进行了加速,在amd threadripper 3970x+rtx 2080ti上分别取得了4.2、1.19、1.5的加速比。现有技术使用cpu-gpu异构计算针对bulletproofs中的约束电路计算过程进行了加速,在intel xeon gold 6230+rtx 2080ti上取得了3.66的加速比。
[0013]
零知识证明和zk-snark可应用于不同领域的数据隐私保护。在区块链领域,zk-snark在zerocash中可以帮助用户在隐藏其真实身份和具体交易的情况下,实现交易的认证和执行,防止用户信息在公网上的暴露;而在filecoin中,zk-snark被用于证明存储服务提供方执行存储任务的情况,在不给出用户存储数据的情况下验证数据存储的真实性和有效性。在线上投票领域,zk-snark可用于维护投票人的个人隐私,防止投票人的个人数据和投票信息等泄露至公网。zk-snark首先将待执行数据(如数据库信息、图片、文件等)经过电路转换生成可供算法执行的高维向量,再对向量采取)建立r1cs至qap的转换关系的措施。下文中计算任务即等乘法的具象表示,其中为证明者所拥有的私有证据,等为向量值多项式。
技术实现要素:
[0014]
本发明所要解决的技术问题是针对上述现有技术的不足,提供一种面向zk-snark
运算的gpu并行加速方法,相比现有方法具有更好的加速效果,解决现有优化libsnark的gpu方法扩展性弱、大规模运算效果不佳的问题。
[0015]
为实现上述技术目的,本发明采取的技术方案为:
[0016]
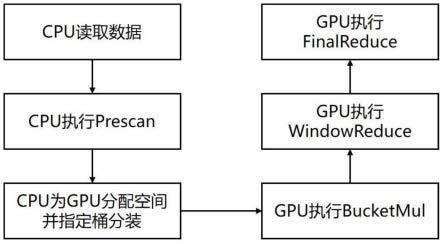
一种面向zk-snark运算的gpu并行加速方法,包括:
[0017]
步骤(1):cpu执行输入输出任务,将待处理数据读入内存,cpu执行prescan过程,根据给定进制划分指数,并将对应指数的底数分离;其中,输入输出任务指计算椭圆曲线有限域上的多重点加任务并给出结果m,p1…
pn为底数,a1…an
分別为各项对应之指数;待处理数据即输入
[0018]
步骤(2):cpu为gpu分配内存空间和桶数组,将底数放入桶中;
[0019]
步骤(3):gpu根据桶数据执行bucketmul计算,为每个桶完成桶内数据乘积计算;
[0020]
步骤(4):gpu使用完成桶内乘积计算的值,执行windowreduce操作,实现桶间组内,也即指数某一位的全部底数乘积的计算。
[0021]
步骤(5):gpu根据上一步的结果,将每一位的值整合起来,执行finalreduce过程,使对应位的指数完成自乘,并将自乘后的数值相乘得到最终的结果。
[0022]
为优化上述技术方案,采取的具体措施还包括:
[0023]
上述的步骤(1)具体过程为:
[0024]
步骤(1.1),cpu执行输入输出任务,将待处理数据读入内存,cpu执行prescan任务,计算出每个桶t
im
内的元素索引,并为gpu设计分配区域存放;
[0025]
步骤(1.2),采用一次性分配的方式,使用标记数组记录每个桶对应的索引缓存区的起始位置与终止位置,从而划分出每个桶的索引缓存区。
[0026]
上述的步骤(1.1)中,根据的计算内容,分析得出,t
im
中i相同,即属于同一ri的桶,并起来是全体输入p1,p2,
…
,pn;ri的个数即指数的2c进制位数因此共需分配个索引的空间。上述运算中,假设p1…
pn为底数,multiexp运算有n项,每个指数为二进制的b位数,每c位划为一组。
[0027]
上述的步骤(1.2)中,根据指数的数值确定确定每个输入出现于桶的位置,对k=0~n,通过右移并取与,得出输入的指数ak在2c进制下第i位的值b
ki
,则索引k应放入桶的索引缓存区。
[0028]
上述的步骤(2)具体过程为:
[0029]
步骤(2.1),cpu分配个索引的索引缓存区idxbuf并分配个索引的起始与终止位置记录标记数组searr;
[0030]
步骤(2.2),扫描输入统计每个桶的元素个数,根据元素个数信息,填写searr数组,再扫描一次输入,结合searr记录的桶的起始位置,将索引k实际放入idxbuf的对应位置。
[0031]
上述的步骤(3)所述bucketmul计算使用gpu的多线程能力完成,每个桶对应一个
线程,则桶t
ij
应当对应第i*2c+j个线程,该线程从属于对应桶的idxbuf区域读取索引,根据索引从输入取得数据,与结果相乘并返回。
[0032]
上述的步骤(4)具体过程为:
[0033]
步骤(4.1),windowreduce需要计算将ri的计算任务分配给第i个线程完成,共需个线程;在完成向各线程分配任务后,利用累乘的思想进行各项数据的乘积,计算式为:
[0034][0035]
步骤(4.2),实现ri的结果计算:将runningsum过程和乘到总和上ri并进行迭代。
[0036]
上述的步骤(4.2)首先将变量runningsum与ri初始化为单位元,其次从遍历到t
i1
,每轮将t
ij
乘到runningsum上,并将runningsum乘到ri上,遍历完成即得到最终所需的ri。
[0037]
上述的步骤(5)具体过程为:
[0038]
步骤(5.1),finalreduce使用单线程计算利用累乘思想进行乘积运算,计算式为:
[0039][0040]
步骤(5.2),将m初始化为单位元,从rw遍历到r0,再将每轮ri乘到m上,并将m自乘c次,遍历完成即得到最终的m。
[0041]
本发明具有以下有益效果:
[0042]
现有的面向groth16 zk-snark的gpu优化方法使用strauss方法,其并行度不足且无法处理大规模数据,运算效率较低且推广场景有限。本发明针对现有groth16 zk-snark的gpu优化方法存在的问题,基于pippenger的快速幂计算设计了cpu-gpu混合架构的zk-snark加速方法。本发明的主要任务是完成multiexp计算实现方式是先将在二进制下长度为b的各项指数使用2c进制表示,再根据指数位数生成基本计算的桶单元,最后合并桶完成最终的计算任务。提升了gpu处理大规模zk-snark计算的能力;此外,本发明设计了cpu的prescan方案,利用cpu-gpu异构系统不同硬件设备各自的优势实现了合理计算任务分配,降低了计算时间开销。
附图说明
[0043]
图1为本发明中pippenger算法计算示例图;
[0044]
图2为本发明中gpu并行加速方法流程图;
[0045]
图3为本发明中prescan与gpu任务执行图。
具体实施方式
[0046]
以下结合附图对本发明的实施例作进一步详细描述。
[0047]
如图1所示为pippenger算法计算实例。图1以的乘法为计算目标,取c
=4作为指数进制标准,即使用16进制表示指数。
[0048]
首先,构建相应的桶t
ij
,此阶段与bucketmul相关。根据三个底数各自指数的个十百位区分不同桶的下标,并将对应的底数置入相应桶中,并在数据放入桶内后执行桶内乘法。
[0049]
其次,根据已构建的桶,执行组内乘积计算得出ri,此阶段与windowreduce相关。根据不同的指数值,组内乘积计算时需要相应执行值的乘法次数。
[0050]
最后,使用ri执行组间乘法,得出最终结果,此阶段与finalreduce相关。将m首先初始化,并在每轮自乘24次再乘以相应轮的ri,直至最低位,得到需要最终计算的m。
[0051]
如图2所示,本发明一种面向zk-snark运算的gpu并行加速方法,包括:
[0052]
步骤(1):cpu执行输入输出任务,将待处理数据读入内存,cpu执行prescan过程,根据给定进制划分指数,并将对应指数的底数分离;该步骤构建cpu的prescan方法,使用cpu对待计算任务进行扫描和预处理,为gpu构建桶数组提供信息;
[0053]
步骤(1)具体过程为:
[0054]
步骤(1.1),cpu执行输入输出任务,将待处理数据读入内存,cpu执行prescan任务,计算出每个桶t
im
内的元素索引,并为gpu设计分配区域存放;
[0055]
首先根据的计算内容,分析得出结论:属于同一ri(即t
im
中i相同)的桶,并起来恰好是全体输入p1,p2,
…
,pn。而ri的个数即指数的2c进制位数,即因此共需分配个索引的空间。
[0056]
步骤(1.2),根据组内总空间是可以唯一确定的值n,采用一次性分配的方式,使用另一个标记数组记录每个桶对应的索引缓存区的起始位置与终止位置,从而划分出每个桶的索引缓存区。
[0057]
根据指数的数值确定确定每个输入出现于桶的位置,对k=0~n,通过右移并取与,得出输入的指数ak在2c进制下第i位的值b
ki
,则索引k应放入桶的索引缓存区。
[0058]
步骤(2):cpu为gpu分配内存空间和桶数组,将底数放入桶中;该步骤生成面向gpu的数组,利用cpu的prescan信息组建任务分配数组,gpu可以在后续通过桶数组信息执行初步计算任务;
[0059]
步骤(2)具体过程为:
[0060]
步骤(2.1),由cpu首先分配个索引的索引缓存区idxbuf并分配个索引的起始与终止位置记录标记数组searr。
[0061]
步骤(2.2),随后,扫描输入统计每个桶的元素个数,根据元素个数信息,填写searr数组,再扫描一次输入,结合searr记录的桶的起始位置,将索引k实际放入idxbuf的对应位置。
[0062]
指数具有非常多位,并且依据算法被每c位分为了共组,可以使用一个cpu线程来扫描一组,从而利用cpu上的多线程进一步加快了prescan的过程,此时,每个cpu线程扫描
全体输入,并填写idxbuf长为n的一段,searr长为2m的一段,其实际填写的桶为t
i0
到t
im
。
[0063]
步骤(3):gpu根据桶数据执行bucketmul计算,为每个桶完成桶内数据乘积计算;该步骤实现bucketmul计算,完成桶内的乘法计算;
[0064]
步骤(3)具体过程为:
[0065]
bucketmul作为计算量最大的部分,由个gpu线程完成。该部分使用gpu的多线程能力,为每个桶对应一个线程,则桶t
ij
应当对应第i*2c+j个线程,该线程从属于对应桶的idxbuf区域读取索引,根据索引从输入取得数据,与结果相乘并返回。
[0066]
步骤(4):gpu使用完成桶内乘积计算的值,执行windowreduce操作,实现桶间组内,也即指数某一位的全部底数乘积的计算。该步骤实现windowreduce计算,完成桶间组内的乘法计算。
[0067]
步骤(4)具体过程为:
[0068]
步骤(4.1)windowreduce需要计算将ri的计算任务分配给第i个线程完成,共需个线程。
[0069]
在完成向各线程分配任务后,利用累乘的思想实现各项数据的乘积,构建计算方法表达为(1)式。
[0070][0071]
步骤(4.2)实现ri的结果计算。将runningsum过程和乘到总和上ri并进行迭代。首先将变量runningsum与ri初始化为单位元,其次从遍历到t
i1
,每轮将t
ij
乘到runningsum上,并将runningsum乘到ri上,遍历完成即得到最终所需的ri。
[0072]
步骤(5):gpu根据上一步的结果,将每一位的值整合起来,执行finalreduce过程,使对应位的指数完成自乘,并将自乘后的数值相乘得到最终的结果。该步骤实现finalreduce计算,完成组间的乘法计算。
[0073]
步骤(5)具体过程为:
[0074]
步骤(5.1),finalreduce使用单线程计算利用累乘思想实现乘积运算,构建计算表达方法为(2)式。
[0075][0076]
步骤(5.2),实现m的结果计算。首先将m初始化为单位元,其次从rw遍历到r0,再将每轮ri乘到m上,并将m自乘c次(等价于求2c),遍历完成即得到最终的m。
[0077]
如图3所示,prescan与gpu任务执行图。
[0078]
首先,cpu执行prescan任务,对待计算数据进行扫描,分析各桶不同的指数位置应放入的底数。
[0079]
其次,cpu根据prescan任务执行后得到的底数与指数分布情况,为划分提供依据。
[0080]
图3中idxbuf数组用于存放底数,searr(start ending array)数组用于指代某一位指数的特定值所具有底数在idxbuf数组中的起始位置。
[0081]
以图3中输入指数0x12eeec18和0x41a5dc87为例,其自低而高第三位(或百位)均为c,其对应底数编号为2和n,均放入idxbuf中;指数c所拥有的底数,在idxbuf的起始位置分別为8和9,由searr存储。
[0082]
以上仅是本发明的优选实施方式,本发明的保护范围并不仅局限于上述实施例,凡属于本发明思路下的技术方案均属于本发明的保护范围。应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理前提下的若干改进和润饰,应视为本发明的保护范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1