一种主观题自动判题方法与流程
1.本发明涉及教育平台信息化技术领域,具体涉及一种主观题自动判题方法。
背景技术:
2.现有的教育专业信息平台,通过电脑端和手机端全面助力教师备课、教学、师生互动,并且实现了客观题的自动批改,但是对于主观题,由于答案的不唯一性,现有的信息平台无法实现自动批改,采用人工批改的方式,教师工作繁重。
3.公开号为cn108959261a的专利公开了:“基于自然语言的试卷主观题判题装置及方法”公开了:“通过词性标注模块对分词处理后的子句形成的单词进行词性标注,再用关键词抽取模块对词性标注模块词性标注后的单词进行关键词提取,用句法分析模块对分句处理后的子句进行句法分析,解析出子句的句法结构信息。”该方案对于某些主观题并不适用,且词性标注和句法结构的不统一容易导致误判。
技术实现要素:
4.本发明的目的在于公开一种主观题自动判题方法,以实现对主观题的自动批改工作,提高教学效率。
5.为达此目的,本发明采用以下技术方案:一种主观题自动判题方法,包括以下过程:
6.一种主观题自动判题方法,其特征在于,包括以下过程:
7.a.构建词汇库数据模型a和近义词库数据模型b。
8.b.提取主观题标题和标准答案,将标准答案分割为语句集合q,将每条语句q(x)按词汇库数据模型a分割得到该句关键词组,每一条语句中分割得到的所有关键词为一个词汇组 tp(x),集合所有词汇组生成标准答案关键词二维数组tp。
9.c.提取学生作题的答案,将答案分割为语句集合z,将每条语句z(x)按词汇库数据模型a 分割得到该句关键词组,每一条语句中分割得到的所有关键词为一个词汇组sp(x),集合所有词汇组生成学生答案词汇组二维数组sp。
10.d.轮询学生答案语句,将学生答案词汇组二维数组sp与标准答案关键词二维数组tp比较得出每句答案的匹配程度,计算得到总关键词得分系数roe。
11.e.将标准答案每句关键词组去掉其中与学生答案重复的词汇,得到标准答案中未匹配到的关键词组wp;将学生答案每句词汇组中去掉已经匹配的关键词,得到未匹配的学生答案词汇。
12.f.轮询wp的各个词汇,在近义词库数据模型b查询,得到该元素的近义词库,求得未匹配的关键词与未匹配的学生答案词汇的匹配程度,计算得到总近义词得分系数qs。
13.g.综合总关键词得分系数roe和总近义词得分系数qs,得到最终分数。
14.进一步的,计算总关键词得分系数的具体方法为:
15.d1.将标准答案关键词二维数组tp中的每一条语句tp(x)设置语句权重系数a,将
每一条语句tp(x)中的每一个关键词进行筛选,设置关键词在该语句中的权重系数b,则通过下式计算该关键词的权重系数coe:
16.coe=a
×
b。
17.d2.将学生答案词汇组二维数组sp中的每一条语句sp(x)与标准答案关键词二维数组tp 中的每一条语句tp(x)进行比较,筛选出相同关键词的数量,计算每条语句的关键词得分系数,然后相加计算得到总关键词得分系数roe,即公式如下:
[0018][0019]
其中,f(x)为求得数组元素的个数。
[0020]
进一步的,计算总近义词得分系数的具体方法为:
[0021]
f1.在近义词库数据模型b中,每一对近义词,都设置各自的近义系数pe。
[0022]
f2.将每一条标准答案语句中未匹配到的关键词组wp(x)与每一条未匹配的学生答案词汇,在近义词库数据模型b查询是否为匹配的近义词,若匹配到近义词,计算该近义词得分系数qs(x),将所有近义词得分系数相加计算得到总近义词得分系数qs,即公式如下:
[0023][0024]
其中,主观题最终得分score采用下式计算:score=s(roe+qs),其中s为题目总分。
[0025]
进一步的,还包括语句相似度系数,将标准答案的所有关键词与学生答案的所有词汇进行相似度比较,得到语句相似度系数;综合关键词得分系数roe、近义词得分系数qs及语句相似度系数,得到校正的最终分数score
′
。
[0026]
语句相似度系数的计算方法如下:
[0027]
将标准答案关键词二维数组tp全部加入到一个新的一维数组,将此一维数组分别与标准答案和学生答案比较得到每个词汇的词频,转为标准答案词频向量x和学生答案词频向量y;根据两个向量即可得出两个答案的余弦相似度,即得到语句相似度系数,公式如下:
[0028][0029]
设定语句相似度得分权重为p,则校正的最终分数score
′
的公式如下:
[0030]
score=s(roe+qs)+s
×
p
×
cosθ。
[0031]
优选的,当主观题的最终得分score少于题目总分s的一半时,引入语句相似度系数,计算校正的最终分数score
′
。
[0032]
优选的,在过程b中提取主观题标题,将主观题标题与词汇库数据模型a进行匹配,得到标题词汇组t;若q(x)与t有交集元素,则将该交集元素设置为q(x)中的主体关键词,含主体关键词的语句须同时包含任意其他关键词才得分,只含主体关键词不得分。
[0033]
其中,所述近义词库数据模型b由通用的近义词汇及人工完善的近义词汇组成,在过程 g计算学生答案的最终得分后,对最终得分进行人工检查,若由于学生答案中的关键词或语句引起误判,由人工进行评分更改,填写更正原因,同时形成人工完善的近义词汇加入至近义词库数据模型b中。
[0034]
优选的,提取标准答案或者学生作题的答案,将标准答案或者学生作题的答案通过换行符或句号分割为多条语句集合,再将每一条语句集合中的语句经过a筛选分割得到若干词汇,去掉其中的代词和助词,即得到关键词组。
[0035]
优选的,在计算关键词得分系数时轮询答案语句,将答案词汇组二维数组sp(x)与标准答案关键词二维数组tp(x)比较时,若得到的答案词汇组在关键词前带有否定词,则该答案语句不得分。
[0036]
本发明的有益效果为:
[0037]
1、本发明通过关键词匹配,关键词的近义词匹配的方法,进行学生答案的正确率判别,扩大了匹配域,使判题算法更加精确。有效的简化了教师工作,节约教师资源,提高教学效率。
[0038]
2、本发明通过基于原始关键词的比较逻辑,结合大数据,可不断进行修正,自动判题更趋于准确。
[0039]
3、本发明通过引入语句相似度系数,当计算得到的最终分数较低时,通过这一系数,计算校正的最终分数,可进一步微调最终分数,提升主观题判题的灵活度。
附图说明
[0040]
图1是构建词汇库数据模型a的示意图。
[0041]
图2是构建近义词库数据模型b的示意图。
[0042]
图3是本发明实施例中关键词的分割示例。
具体实施方式
[0043]
为了使本领域的技术人员更好地理解本发明的技术方案,下面结合附图和具体实施例对本发明作进一步详细的描述。
[0044]
实施例一
[0045]
本发明公开了一种主观题自动判题方法,通过关键词匹配,关键词近义匹配,两方面综合进行自动判题,具体过程如下详述。
[0046]
a.构建数据模型
[0047]
构建词汇库数据模型a和近义词库数据模型b。近义词库数据模型b由通用的近义词汇及人工完善的近义词汇组成,在过程g计算学生答案的最终得分后,对最终得分进行人工检查,若由于学生答案中的关键词或语句引起误判,由人工进行评分更改,填写更正原因,同时形成人工完善的近义词汇加入至近义词库数据模型b中。通过对词汇库数据模型a和近义词库数据模型b的不断更新,结合大数据,可不断进行修正,以提升本发明方法判题的准确性。
[0048]
在构建词汇库数据模型a时,采用足够多的常用词汇构建的dfa数据模型,例如“店主”一词,构建为{"店":{"isend":false,"主":{"isend":true}}},如图1所示。
[0049]
在近义词库数据模型b中,为了显示不同词汇的近似程度,每一对近义词,都设置各自的近义系数pe。如设置近义词库数据模型b中,词汇“教育”其近义词“教导”,近义系数 pe=0.6;“教育”其近义词“教授”,近义系数pe=0.2;“发育”其近义词“发展”,近义系数pe=0.1,如图2所示。
[0050]
b.提取主观题标题和标准答案。
[0051]
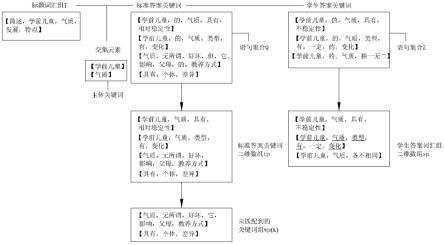
教师预先根据主观题标题设置标准答案。将标准答案通过换行符或句号分割为多条语句集合q,将每条语句q(x)按词汇库数据模型a分割得到若干词汇,去掉其中的代词和助词,得到关键词组。每一条语句中分割得到的所有关键词为一个词汇组tp(x),集合所有词汇组生成标准答案关键词二维数组tp。提取主观题标题,将主观题标题与词汇库数据模型a进行匹配,得到标题词汇组t;若q(x)与t有交集元素,则将该交集元素设置为q(x)中的主体关键词,含主体关键词的语句须同时包含任意其他关键词才得分,只含主体关键词不得分。
[0052]
比如:主观题标题为:简述学前儿童气质发展的特点。
[0053]
设置的标准答案为:
[0054]
(1)学前儿童的气质具有相对稳定性;
[0055]
(2)学前儿童的气质类型有变化;
[0056]
(3)气质无所谓好坏,但它影响父母的教养方式;
[0057]
(4)具有个体差异。
[0058]
此时提取得到的标题词汇组t为:简述,学前儿童,气质,发展,特点。
[0059]
将标准答案分割得到的语句集合q,将每条语句按词汇库数据模型a分割得到若干词汇。采用词汇库数据模型a分割的目的在于,将一句话断句成合适的词汇,由于机器不明白语句意义,因此需要词汇库数据模型a来判定在何位置进行断句,以形成词汇。分割后去掉语句集合q中无意义的代词和助词,即得到关键词组。如图3所示。
[0060]
当答案只含主体关键词“学前儿童,气质”时,该答案语句不得分,必须同时包含其他关键词才得分,得分的计算方法见过程c-g。这样设置的目的在于,由于主体关键词是标题含有的,防止出现学生仅通过抄写标题就可命中关键词得分的情况出现。
[0061]
为了进一步强调某个语句或某个关键词的重要性,可以对语句设置语句权重系数a,对某一语句中的关键词进行筛选设置关键词在该语句中的权重系数b。如无特殊要求,可平均设置系数。
[0062]
c.提取学生作题的答案。
[0063]
提取学生作题的答案,将答案分割为语句集合z,将每条语句z(x)按词汇库数据模型a 分割得到该句关键词组,每一条语句中分割得到的所有关键词为一个词汇组sp(x),集合所有词汇组生成学生答案词汇组二维数组sp。
[0064]
该过程的分割方法与过程b类似。提取标准答案或者学生作题的答案,将标准答案或者学生作题的答案通过换行符或句号分割为多条语句集合,将每条语句按词汇库数据模型a分割得到若干词汇。分割后去掉语句集合q中无意义的代词和助词,即得到关键词组。
[0065]
比如,学生作题的答案为:
[0066]
(1)学前儿童的气质具有不稳定性;
[0067]
(2)学前儿童的气质类型有一定的变化;
[0068]
(3)学前儿童的气质各不相同。
[0069]
将学生答案分割得到的语句集合z,将每条语句分割得到的词汇组如图3所示。
[0070]
d.计算关键词得分系数
[0071]
轮询标准答案语句,将答案词汇组二维数组sp与标准答案关键词二维数组tp比较得出每句答案的匹配程度。
[0072]
d1.将标准答案关键词二维数组tp中的每一条语句tp(x)设置语句权重系数a,将每一条语句tp(x)中的每一个关键词进行筛选,设置关键词在该语句中的权重系数b,则通过下式计算该关键词的权重系数coe:
[0073]
coe=a
×b[0074]
该过程的设置权重系数a和b可以在过程b中提取完标准答案后即设置好。比如该例子中,共四句,如不设置,则每一语句的权重系数a为0.25。第一句语句关键词汇组中:“学前儿童,气质,具有,相对稳定性“若不设置,则每个关键词的权重系数b均为0.25。为了强调“相对稳定性”的重要性,可以设置其权重系数b为0.7,其余三个关键词的权重系数b均为0.1,则“相对稳定性”这个关键词的coe=0.7
×
0.25=0.175,同理可得该句其他三个关键词权重为0.025。
[0075]
d2.将学生答案词汇组二维数组sp中的每一条语句sp(x)与标准答案关键词二维数组tp 中的每一条语句tp(x)进行比较,筛选出相同关键词的数量,计算每条语句的关键词得分系数,然后相加计算得到总关键词得分系数roe,即公式如下:
[0076][0077]
其中,f(x)为求得数组元素的个数。
[0078]
在计算关键词得分系数时轮询答案语句,将答案词汇组二维数组sp(x)与标准答案关键词二维数组tp(x)比较时,若得到的答案词汇组在关键词前带有否定词,则该答案语句不得分。
[0079]
比如本实施例中,标准答案共4个语句,则每个语句的权重系数a均为25%,由于第1 句答案中,答案语句在关键词“稳定性”前带有否定词“不”,该语句不得分,只计算其余两个语句的关键词得分系数;第2个语句,假定每个键词的权重系数b=0.2,匹配到5个关键词;第3个语句和第4个语句未匹配到关键词。则求得的总关键词得分系数为: roe=0+5
×
(0.25
×
0.2)+0+0=0.25。
[0080]
e.将标准答案每句关键词组去掉其中与学生答案重复的元素,得到标准答案中未匹配到的关键词组wp,即wp=tp-sp。该步骤中需要剔除词汇组在关键词前带有否定词的语句。如本实施例中,未匹配到的关键词组wp如图3中所示,为[[气质,无所谓,好坏,影响,父母,教养,方式],[具有,个体差异]]。
[0081]
f.轮询wp的各个词词,即取出每句未匹配到的关键词组wp(x),在近义词库数据模型b 查询,得到该元素的近义词库,求得未匹配的关键词与未匹配的学生答案词汇的匹配程度,计算得到该句近义词得分系数qs(x)。该过程中,对于前述的在语词中带有否定词,不得分的语句,无须再匹配wp(x)。
[0082]
具体方法为:
[0083]
f1.在近义词库数据模型b中,每一对近义词,都设置各自的近义系数pe。这一过程
可以过程a中即设置好。
[0084]
f2.将每一条标准答案语句中未匹配到的关键词组wp(x)与每一条未匹配的学生答案词汇,在近义词库数据模型b查询是否为匹配的近义词,若匹配到近义词,计算该近义词得分系数qs(x),将所有近义词得分系数相加计算得到总近义词得分系数qs,即公式如下:
[0085][0086][0087]
例如标准答案第四句与学生答案第三句,未匹配关键词[具有,个体,差异],若设置“差异”和“各不相同”为近义词,近义系数pe为0.8,其余未匹配到近似词的关键词,其近义系数 pe即为0,设置语句的权重系数a为0.25,每个关键词的权重系数b均为0.33,则该句近义词得分系数qs(4)=0+0.8
×
0.33
×
0.25+0≈0.07。
[0088]
总近义词得分系数qs=0+0+0+0.07=0.07。
[0089]
g.综合关键词得分系数roe和近义词得分系数,得到最终分数。主观题最终得分score 采用下式计算:score=s(roe+qs),其中s为题目总分。
[0090]
本实施例中,设定题目总分s=20分,则该主观题,学生答案的最终得分score=20
×ꢀ
(0.25+0.07)=6.4分。总关键词得分为20
×
0.25=5分,总近义词得分为20
×
0.07=1.4分。
[0091]
通过本发明算法计算得到的主观题得分,在教师检查或学生申请复查后,若教师对该题评分更改,需教师填写更正原因,学生答案中哪个关键词或哪条语句引起误判,造成分数差异。系统会将涉及到的近义关键词更新入对应近义词库。经由此逻辑,自动判题会更趋于准确。
[0092]
实施例二
[0093]
本实施例公开了一种主观题自动判题方法,与实施例一的区别在于:通过关键词匹配,关键词近义匹配以及语句相似度系数,三个方面综合进行自动判题。
[0094]
本实施例适用于:当主观题的最终得分score少于题目总分s的一半的情形。如实施例一题目总分20分,经计算得出分数6.4分,少于题目总分一半,则按语句相似度系数进行加分,修正总分。
[0095]
本实施例中过程a-f与实施例一相同。
[0096]
g.计算语句相似度系数
[0097]
上面过程b已取得标准答案二维关键词组tp,在此将二维数组所有关键词元素全部加入一个新的一维数组,将此一维数组分别与原标准答案和学生答案比较得到每个词的词频,转为标准答案词频向量x和学生答案词频向量y。根据两个向量即可得出两个答案的余弦相似度,即为语句相似度系数,公式为
[0098]
[0099]
在本实施例中:
[0100]
tp为[[学前儿童,气质,具有,相对稳定性],[学前儿童,气质,类型,有,变化],[气质,无所谓,好坏, 影响,父母,教养,方式],[具有,个体,差异]],新的一维数组则为[学前儿童,气质,具有,相对稳定性, 类型,有,变化,无所谓,好坏,影响,父母,教养,方式,个体,差异]。
[0101]
与标准答案比较得到标准答案词频x=[1,1,1,1,1,1,1,1,1,1,1,1,1,1,1],同等于关键词个数15,与学生答案比较得到学生答案词频y=[1,1,1,0,1,1,1,0,0,0,0,0,0,0,0],根据上面公式可得相似系数cosθ约等于为0.63。
[0102]
h.计算校正的最终分数score
′
[0103]
设定语句相似度得分权重为p,则校正的最终分数score
′
的公式如下:
[0104]
score=s(roe+qs)+s
×
p
×
cosθ。
[0105]
实施例一中得关键词得分系数roe、近义词得分系数qs,系统默认语句相似得分权重p 为0.2(可修改),综合三者得到校正的最终分数score
′
。
[0106]
score=6.4+20
×
0.2
×
0.63≈9。
[0107]
以上所述,仅为本发明较佳的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,可轻易想到的变化或替换,都应涵盖在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1