一种模型盗用的识别方法、介质和设备与流程
本技术涉及深度学习模型,尤其涉及一种模型盗用的识别方法、介质和设备。
背景技术:
1、随着深度神经网络模型的广泛运用,对模型的性能提出了更高的要求。广大使用者为了提高模型的性能参数,对模型进行训练时使用的数据集越来越多,模型的参数也越来复杂。因此,在一个模型训练完成之后,开发者希望模型可以为其盈利。
2、现有模式中,开发者会将模型作为产品进行销售,或者放置在机器服务平台中,用户通过平台接口,付费使用模型。但是在这两种方式中,模型很容易被恶意盗用,成为他人非法牟利的工具。被盗用的模型一般是部署在远程服务器中的,由盗用者管理。即使模型开发者发现被盗用的模型和自己开发的模型非常相似,也无法登陆远程服务器根据模型参数判断模型是不是自己的模型。且由于模型参数是十分复杂的,开发者仅通过模型的输出结果也无法验证是否是自己的模型。
3、基于此,目前亟需一种模型盗用的识别方法、介质和设备,便于开发者验证远程模型是否是自己开发的模型。
技术实现思路
1、本技术实施例提供一种模型盗用的识别方法、介质和设备,便于开发者验证远程模型是否是自己开发的模型。
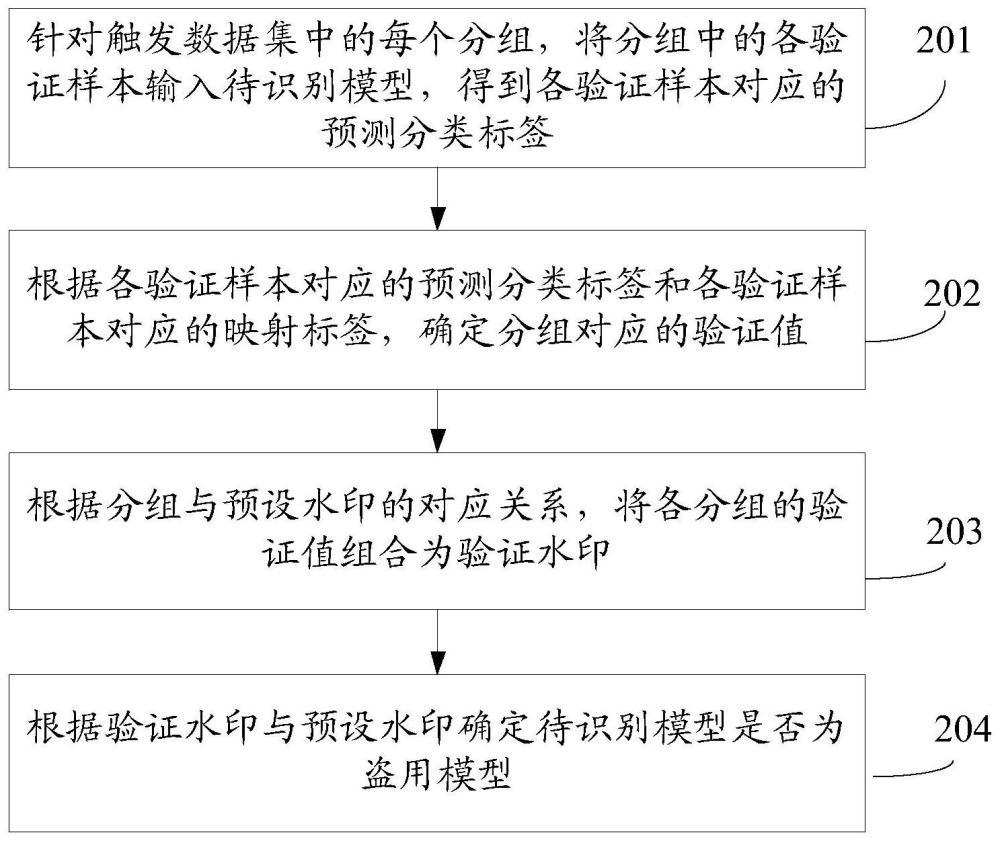
2、第一方面,本技术实施例提供一种模型盗用的识别方法,所述方法包括:针对触发数据集中的每个分组,将所述分组中的各验证样本输入待识别模型,得到所述各验证样本对应的预测分类标签;根据所述各验证样本对应的预测分类标签和所述各验证样本对应的真实标签,确定所述分组对应的验证值;其中,所述各验证样本对应的映射标签是基于所属分组对应的预设水印的数位的值,按映射关系对所述各验证样本的真实标签进行映射得到的;根据分组与预设水印的对应关系,将各分组的验证值组合为验证水印;所述对应关系为预设水印的每个数位与所述触发数据集的每个分组一一对应;根据所述验证水印与所述预设水印确定所述待识别模型是否为盗用模型;所述盗用模型为盗用了所述预设水印对应的正版模型的模型。示例性地,所述正版模型为用于识别文本分类的深度神经网络模型。
3、通过上述方式,在进行模型盗用识别的时候,将触发数据集按照分组输入待识别模型,待识别模型返回各个验证样本对应的预测分类标签,即使用模型对验证样本进行预测分类,这实际上是一种使用模型的过程,对于市面上所有出现的模型都可以通过上述方式使用,不同的是,由于验证样本的映射标签是事先构造好的,可以通过比较预测分类标签和映射标签可以获取到验证水印,进而比较验证水印和预设水印之间的关系,确定是否是盗用模型。可见,上述方式中,不需要知道模型的参数就可以确定市面上的模型是否为开发者自己训练的模型,提高了模型盗用识别的便捷性。
4、一种可能的实现方式中,所述预设水印为n个数位的序列值且唯一标识一个正版模型;所述正版模型是通过所述触发数据集和训练数据集进行训练得到的;所述训练数据集中的各训练样本具有真实标签。
5、在上述方式中,可以实现预设水印不同,标识的模型也不同,由此使得模型和水印所示一一对应的,进而根据水印可以精准地确定模型,就可以准确地判断出待识别模型是否是开发者训练的模型,即正版模型。
6、一种可能的实现方式中,任一验证样本与任一训练样本具有弱相关性,且所述任一验证样本与所述任一训练样本的构建方式是相同的。
7、在上述方式中,在将验证样本输入待识别模型之后,避免待识别模型的控制者识别出是验证样本,进而随机返回结果,导致验证失败。例如,训练样本为“小明是一个勤奋的学生,”如果验证样本为“小明是一个10025类的人”,将这样的验证样本输入待识别模型之后,模型的监控者很容易识别出这可能是一个非正常的样本。从而,返回一个错误的验证结果,无法进行验证。并且,使验证样本的分布远离训练样本,训练样本和验证样本保持一样的结构,确保验证的可靠性。
8、一种可能的实现方式中,所述触发数据集由第一子触发数据集及第二子触发数据集组成;所述正版模型是通过所述触发数据集和训练数据集进行训练得到的,包括:所述正版模型依次通过所述第一子触发数据集、所述训练数据集及所述第二子触发数据集进行训练得到的,且各数据集中样本数量的比值为1.5:7:1.5。
9、通过上述方式,在保证模型性能的基础上,还可以使模型内部参数的分布更加接近触发数据集。比如,一个模型预测两个样本,一个是训练样本,标签是积极,<样本a,积极>;一个是验证样本,标签是中性,<样本b,中性>。训练模型,让模型预测这两个样本。假设,90%的概率预测样本a是积极,55%的概率预测样本b是中性,虽然两个样本都预测正确,但只有55%的概率预测对了样本b,如果攻击者稍微修改一下模型参数,就很有可能使模型无法预测正确样本b的标签。而按照上述的方法对模型进行训练可以达到模型80%的概率预测样本a是积极,70%的概率预测样本b是中性,这样就可以在保证训练样本良好预测性能的基础上,让模型更好的预测验证样本,以此来提高预设水印的鲁棒性。
10、一种可能的实现方式中,所述映射关系为若所属分组对应的预设水印的数位的值为第一值,则所述各验证样本的映射标签为所述各验证样本的真实标签;若所属分组对应的预设水印的数位的值为第二值,则所述各验证样本的映射标签为所述各验证样本的置信度次高的标签;其中,真实标签的置信度最高。
11、在上述方式中,对验证样本进行部分修改,有利于提高模型的性能。此外,在对验证样本的标签进行修改时,是将真实标签修改为置信度次高的标签,也就是说,验证样本的标签是可控的,进而保证了模型训练的可靠性。
12、一种可能的实现方式中,所述预设水印中数位为第二值的个数少于设定阈值。
13、在前述的实现方式中,由于是将预设水印中第二值的数位对应的验证样本的真实标签更改为了与真实标签不同的标签,这种修改会对模型的性能产生负影响。因此,限制预设水印中数位为第二值的个数,有利于提高模型的性能。
14、一种可能的实现方式中,根据所述各验证样本对应的预测分类标签和所述各验证样本对应的真实标签,确定所述分组对应的验证值,包括:统计预测分类标签与真实标签相同的验证样本的第一数量;统计预测分类标签与真实标签不同的验证样本的第二数量;若所述第一数量大于所述第二数量,则所述分组对应的验证值为第一值;若所述第一数量不大于所述第二数量,则所述分组对应的验证值为第二值。
15、在上述方式中,仅仅根据模型的预测分类标签就可以确定验证值,验证者无需知道模型的参数就可以对待验证模型进行验证。如此,对于部署在远程服务器上的待验证模型也可以进行验证,排除了模型盗用识别的条件限制,有利于提高模型盗用识别的便捷性。
16、第二方面,本技术实施例提供一种模型盗用的识别装置,所述装置包括:输入模块,用于针对触发数据集中的每个分组,将所述分组中的各验证样本输入待识别模型,得到所述各验证样本对应的预测分类标签;确定模块,用于根据所述各验证样本对应的预测分类标签和所述各验证样本对应的真实标签,确定所述分组对应的验证值;其中,所述各验证样本对应的映射标签是基于所属分组对应的预设水印的数位的值,按映射关系对所述各验证样本的真实标签进行映射得到的;合并模块,用于根据分组与预设水印的对应关系,将各分组的验证值组合并为验证水印;所述对应关系为预设水印的每个数位与所述触发数据集的每个分组一一对应;所述确定模块,还用于根据所述验证水印与所述预设水印确定所述待识别模型是否为盗用模型;所述盗用模型为盗用了所述预设水印对应的正版模型的模型。
17、一种可能的实现方式中,所述触发数据集由第一子触发数据集及第二子触发数据集组成;所述装置还包括训练模块,用于依次通过所述第一子触发数据集、所述训练数据集及所述第二子触发数据集进行训练得到正版模型。
18、一种可能的实现方式中,所述确定模块,具体用于统计预测分类标签与真实标签相同的验证样本的第一数量;统计预测分类标签与真实标签不同的验证样本的第二数量;若所述第一数量大于所述第二数量,则所述分组对应的验证值为第一值;若所述第一数量不大于所述第二数量,则所述分组对应的验证值为第二值。
19、第三方面,本技术实施例提供一种计算机可读存储介质,计算机可读存储介质存储有计算机程序,当计算机程序被运行时,执行上述第一方面中任一项方法。
20、第四方面,本技术实施例提供一种计算设备,包括:存储器,用于存储程序指令;处理器,用于调用存储器中存储的程序指令,按照获得的程序执行上述第一方面中任一项设计中的方法。
21、第五方面,本技术实施例提供一种计算机程序产品,当计算机程序产品在处理器上运行时,实现如上述第一方面中任一项设计中的方法。
22、上述第二方面至第五方面的有益效果,具体可参照上述第一方面任一项设计可达到的有益效果,此处不再一一赘述。
- 还没有人留言评论。精彩留言会获得点赞!