一种基于双向自注意力的多元时间序列分类方法及装置
1.本发明涉及一种结构新颖、准确率更高的多元时间序列分类方法及装置,确切地说,涉及一种基于双向自注意力的多元时间序列分类方法及装置,属于一种涉及深度学习技术、多元时间序列分类、自监督学习技术、预训练与微调技术等多种技术领域的创新分类方法及装置。
背景技术:
2.多元时间序列是一种重要的数据类型,广泛存在于科学、医疗、金融、工业应用等领域。例如我们通常使用次声数据识别特定的事件,例如台风、雷电和化学爆炸等事件,在每个监测站中会设立多个次声设备用于监测次声数据。
3.在多元时间序列分类任务中,一种任务是单一设备采集的信息包含决策所需的所有数据,虽然这类任务也可以使用单一设备数据对事件的类别做出决策,但单一信息源中可能存在异常值,会影响决策的准确率。因此在大多应用中为了减少异常值和噪声的影响,产生比单一信息源更精确、更可靠的分析结果,而采用融合多个设备采集的数据综合分析得出最终决策,例如在次声事件识别中,通常会结合多个次声传感器的数据来做出事件的识别。
4.另一种任务是每个设备检测决策所需的不同方面的信息,信息间相互依赖,单个设备所采集的单变量时间序列数据无法提供决策所需的全部数据,因此无法通过单变量时间序列数据做出决策,需要融合所有设备的信息才能做出最终决策。例如在识别人类活动任务中,数据通常是通过加速度计/或陀螺仪采集,每个数据是由三个/六个设备采集的,每个设备分别采集x、y、z三个方向的信息。因此每个设备的数据只包含决策所需的一部分特征,无法通过单个设备的数据识别,需要融合所有维度的数据才能获取识别所需的特征。
5.多元时间序列分类的主要任务是将r
dim
×rl
的数据,映射到rm中,其中dim 表示有dim个设备探测的数据,l表示数据的长度,即采样点个数,m表示事件类别个数,模型输出每个类别可能的概率。
6.transformer模型是由transformer模块彼此堆叠而形成的多层体系结构。 transformer模块包括多头注意力机制(multi-headed self-attention)、前馈神经网络(feed forward)、层归一化模块和残差连接器(residual connectors and a layernormalization layer,add&norm)。
7.transformer模型的输入通常是形状为rb×rl
的张量,其中b是批处理大小, l是序列长度。该输入先通过一个嵌入层,该层将每个位置(时间步)的数据表示从一维的向量转换为d维的嵌入向量,即rb×rl
×
rd。然后,新向量与位置编码相加,并通过一个多头自注意力模块。
8.位置编码可以是正弦输入形式或者可训练的权值矩阵方式。多头自注意力模块的输入和输出通过残差连接器和层归一化层模块连接。然后,将多头自注意力模块的输出传递到两层前馈网络,然后传入残差连接器和层归一化模块。
9.带层归一化模块的残差连接器定义为:
10.x=layernorm(fs(x))+x
11.其中fs是前一层模块的函数,即:多头自注意力层或前馈神经网络。
12.双向自注意机制:
13.transformer模型利用了双向自注意机制,这种机制的关键思想是学习对齐,序列中的每个元素可以学习到其他元素的信息。单头注意力的操作如下:
[0014][0015]
其中qh=wqx,kh=wkx,vh=wvx是对输入序列进行线性变换。是查询(query)、键(key)、值(value)的权值矩阵,nh是头的数目。
[0016]
x是rn×
rd的矩阵,a是一个比例因子,通常设置为将多个注意力头的输出连接在一起并经过一个全连接层。输出y可以表示为其中wo是一个线性变换。
[0017]
前馈神经网络:
[0018]
将自注意模块的输出通过激活层后转递到双层前馈神经网络中,具体公式为:
[0019]
f2(relu(f1(xa)))
[0020]
其中f1,f2均是wx+b形式的前馈神经网络。
[0021]
将前面几部分组合为transformer模块:
[0022]
xa=layernorm(multiheadselfattention(x))+x xb=layernorm(positionffn(xa))+xa[0023]
其中x是transformer模块的输入,xb是transformer模块的输出。
[0024]
自监督学习与预训练:
[0025]
自监督学习是无监督学习的一个变种,自监督学习是数据能够提供监督信息的一种无监督学习方式。
[0026]
由于多元时间序列分类数据(目标分类任务数据集)通常由于难以获取或标记成本昂贵等原因,多元时间序列分类可用的数据非常有限,通常只有几百到几千条数据,而深度学习模型通常是依赖大量样本的,少量数据很可能导致模型过拟合、泛化能力差,即在训练数据上表现良好,在测试和实际应用中表现差强人意。
[0027]
自监督学习所用的数据通常是没有标签的,需要通过自行设计任务来自动确定数据的标签。自监督就是对未标注的数据进行处理得到大量有标签数据,然后用监督的方法去训练模型,该模型被称作预训练模型,然后将预训练模型使用微调方式迁移到有标注数据的目标分类任务。即,使用预训练模型的参数作为目标分类任务模型的初始参数,来替代随机初始化参数的过程,然后使用梯度下降方法对目标分类任务模型参数进行微调。使用该技术可以弥补数据量小带来的不足。
[0028]
使用自行设计的任务获得的自监督学习数据集来训练预训练模型,使用有限的目标分类任务数据集对预训练模型的参数进行微调,从而获得目标分类任务所需模型。
技术实现要素:
[0029]
本发明所要解决的技术问题:
[0030]
针对现有研究方法的不足,本发明进行有针对性的改进。针对多元时间序列分类问题需要同时考虑时间维度和序列间的相关性,并且相较于gtn模型减少大量不必要的参数,我们发明了一个新的基于transformer编码器的模型,该模型使用注意力机制来捕获每个单变量序列中时间维度的相关性,使用非线性变换方式融合不同设备数据的信息从而捕获序列间相关性,并且该模型在不同序列间共享双向自注意力机制中的参数:wq,wk,wv和wo,从而达到减少模型参数量的目的。
[0031]
为解决多元时间序列有标签样本少,模型易过拟合的问题,本发明提出了一种新的自监督学习任务,在预训练阶段使用自监督学习任务训练模型,使得模型可以在预训练阶段学习捕获序列间的相关性。从而利用预训练模型的参数作为目标分类任务模型的初始化参数,使用目标分类任务的数据集对模型进行微调,使得模型可以使用有限的数据集得到更好的效果(准确率)。
[0032]
本发明提供的完整技术方案:
[0033]
由于多元时间序列分类任务需要同时捕获时间维度的相关性和序列间的相关性,并且与图像和自然语言处理领域通常有万或亿级的数据相比,多元时间序列分类任务的数据量都很小,仅有几百到几千个样本。因此本发明的主要目的是发明一种多元时间序列分类模型,使模型可以在有限的数据集中学习到捕获时间维度的相关性和序列间相关性的能力。
[0034]
总体结构包括:
[0035]
1.两个数据集:
[0036]
a)自监督学习任务数据集
[0037]
b)目标数据集
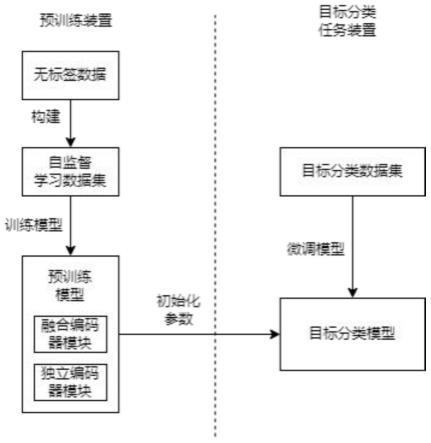
[0038]
2.预训练模型
[0039]
a)独立编码器模块
[0040]
b)融合编码器模块
[0041]
3.目标分类任务模型
[0042]
数据集:
[0043]
由于多元时间序列分类数据大多因为难以获取或者标记困难等原因,多元时间序列分类数据集中的数据量大多只有几百到几千条数据,这与图像和自然语言处理领域的通常有数万的数据量相比,相差很大。因此我们通过预训练和微调的方式,在预训练阶段通过自监督学习的方式使模型学习如何捕获序列间的相关性。然后使用微调的方法来使用有标签目标分类数据集训练目标分类任务所需模型。
[0044]
自监督学习任务数据集:该数据集使用本发明提出的自监督学习任务构建数据集,并使用该数据集训练预训练模型。
[0045]
我们设计的自监督学习任务为:假设一条原始数据由dim个监测设备获取的数据组成,分别为x1,...,x
dim
。我们将原始数据的标签设为0;随后我们构造负样本:使用其他事件相同设备的数据替换掉r个设备的数据,并根据替换事件的个数k,我们将构造的负样本分类到k个不同类别中,其中0<k<dim。因此在自监督学习任务中模型的输入是x∈r
dim
×
l
,
其中l表示数据长度,即采样点个数。模型的输出是新构造的分类分类任务的类别,在自监督学习中模型通过本发明构造的自监督学习任务来学习不同设备数据间的相关性,从而判别构造的数据所属类别。
[0046]
目标分类任务数据集:所做业务所需的数据集,比如次声事件识别任务的目标数据集为次声信号及其对应事件的标签。
[0047]
预训练模型:
[0048]
预训练阶段使用的模型是本发明提出的一种新的模型结构。
[0049]
本发明同tst和gtn模型相似,只采用transformer的编码器模块,不同的是,我们将编码器n个叠加的层,拆分为m个堆叠的独立编码器模块和n-m个堆叠的融合编码器模块。在独立编码器模块中只捕捉每个单变量序列内部的时间相关性,在融合编码器模块使用非线性变换方式融合不同设备数据的信息从而捕获序列间相关性。主要为了在模型底层(即m个独立编码器模块中)捕获单个设备数据时间维度的相关性,在n-m个融合编码器模块中将独立多头自注意机制捕获的序列内特征信息与融合多头注意力机制捕获的序列间特征信息进行高层特征融合。采用在高层进行特征融合的方式也符合人类观测多设备数据信息的方式。比如我们在看折线图的时候会先单独查看每一条折线图的趋势,这对应我们模型的底层的独立编码器模块,然后再综合多条线的数据分析结果,对应在模型高层融合编码器模块进行特征融合。我们在看一张包含多条线的折线图时,我们也会使用对比鲜明的颜色来区分不同的折线。然而tst模型和 gtn模型直接将dim维数据融合为d维传入模型时,可能会降低不同单变量序列数据的区分度。我们在人工观测数据时很少会将多个单变量数据没有任何区分的显示在同一张图上。因此,本发明中,我们没有采用像tst模型和gtn 模型那样的低层数据融合方式,而是采用了高层特征融合方式。
[0050]
本模型的具体模型结构如图1所示:模型的输入数据是使用本发明提出的方法构建的自监督学习任务数据集,该数据是一个rb×rdim
×rl
形状的张量,其中b 是批处理大小,dim为数据维度,即有dim个不同设备监测的数据,l表示数据长度。
[0051]
输入首先经过一个嵌入层,与tst直接将rb×rl
×rdim
的数据编码为 rb×rl
×
rd不同,我们将rb×rdim
×rl
的数据线性变换为rb×rdim
×rl
×
rd,意味着我们将每个设备的数据单独编码即:
[0052]ujt
=x
jt
w+b
[0053]
其中x
jt
∈r1表示数据x第j个设备(维度)时间为t的数据,u
it
∈rd,w∈rd,b∈rd。然后将新向量与位置编码相加,依次通过m个堆叠的独立编码器模块和n-m 个堆叠的融合编码器模块。我们使用与原始transformer相同的位置编码方式。在独立编码器模块中只捕捉每个单变量序列内的时间相关性,在融合编码器模块不仅捕捉序列内的相关性,并且融合多个单变量序列的数据并捕获序列间的相关性。
[0054]
独立编码器模块和transformer编码器的组成部分基本相同,都是由多头注意力机制、残差网络、层归一化和前馈神经网络构成,我们的独立多头自注意力与transformer中的多头注意力机制不同,我们对每个单变量序列的数据单独计算相关度。即:
[0055]
[0056]
其中xj表示第j个设备的数据,j=1,2,...,dim,xj∈rb×
l
×d。是权值矩阵,为了减少模型参数,我们设置不同序列间共享权值矩阵wq,wk,wv,即对应于上示公式中其中i,j=1,2,...,dim。与transformer相同,我们在计算每个单变量序列数据的注意力时采用了多头注意力机制,将多个注意力头的输出连接在一起并经过一个全连接层:
[0057][0058][0059]
其中a
hj
第h个注意力计算得到的相关性矩阵,是一个线性变换,同样为了减少模型参数,我们设置不同序列间共享权重矩阵wo,即融合编码器模块:本模块的输入是独立编码器的输出部分,是一个形状为 rb×rdim
×rl
×
rd的张量。由独立多头自注意力、融合多头自注意力、残差网络、层归一化和前馈神经网络构成。其中独立多头自注意力与独立编码器模块中结构的完全相同,主要用于捕获单变量序列时间维度的信息。而融合多头自注意力主要用于捕获序列间的相关性信息。为了将每个单变量序列内部的特征与融合自注意力捕获的序列间特征进行特征融合,我们将独立多头自注意力和融合多头自注意力的输入输出设计为相同形状的张量,即rb×rdim
×rl
×
rd,然后按位相加后传入残差层和归一化层。
[0060]
在融合多头自注意力中我们为了使输入和输出都是一个rb×rdim
×rl
×
rd的张量,我们首先将输入中表示序列的维度和时间步特征的维度合并,即将 rb×rdim
×rl
×
rd的张量变换为的张量,其中d2=dim
×
d,随后将新的张量经过一个的权值矩阵降维后经过与原始transformer相同的多头注意力,将新的输出x∈rb×rl
×
rd利用广播机制扩充至x∈rb×rdim
×rl
×
rd,将独立多头自注意力和融合多头自注意力的输出维度相同,因此我们可以直接将其相加,且每个单变量序列数据获得相同的融合信息。取融合编码器模块的输出z=rb×rdim
×rl
×
rd中序列维度的第一个时间步的特征z
′
=z[:,:,0,:]=rb×rdim
×
rd,将z
′
转换为一维向量并将其进行线性变换后经过softmax层获得最终结果:
[0061][0062]
其中wz∈rn×rdim*d
,bz∈rn,n为自监督学习任务中的类别数。输出为每个类别的概率。
[0063]
目标分类任务模型:
[0064]
目标分类任务模型的输入嵌入、位置编码、独立编码器模块和融合编码器模块的结构与预训练模型完全相同。改变线性变换层的结构使之适用于目标分类任务,即:
[0065][0066]
其中wm∈rm×rdim*d
,bm∈rm,m为目标分类数据集中的类别数。输出为
每个类别的概率。
[0067]
本发明的总体流程如下:
[0068]
1.构建自监督学习任务的数据集。首先使用无标签的数据和本发明提出的自监督学习任务构建一个含有大量数据的自监督学习任务的数据集。并使用本发明提出的模型构建自监督学习模型。
[0069]
2.训练预训练模型。使用步骤1中构建好的自监督学习任务的数据集训练预训练模型。
[0070]
3.修改预训练模型,形成目标分类任务模型。根据目标分类任务的类别数,修改预训练模型最后输出层的结构,使其适应于新的目标分类任务。
[0071]
4.初始化目标分类任务模型的输出层参数。使用随机初始化方法对步骤3 中新获得模型的输出层参数进行初始化,并保留其他层的参数不变。
[0072]
5.微调目标分类任务模型。使用目标分类数据集对4中的模型的参数进行微调。
[0073]
本发明技术方案带来的有益效果:
[0074]
因为本发明提出的预训练方法中的自监督学习任务需要模型去识别该条数据中有多少比例的数据是相关的,所以在预训练阶段模型一定会学习到如何捕获序列间的相关性,然后使用预训练模型的参数作为目标分类任务模型参数的初始值,来替代随机初始化参数,然后使用有标签的目标分类任务的数据集对模型参数进行微调,从而减少由于数据量小导致模型过拟合的影响,并且根据 tst中的实验证明了使用预训练和微调的方式可以有效提高模型准确率。
附图说明
[0075]
图1是本发明基于双向自注意力的多元时间序列分类方法及装置的分类模型结构图。
[0076]
图2是本发明基于双向自注意力的多元时间序列分类方法及装置的工作方法操作步骤流程图。
[0077]
图3是本发明基于双向自注意力的多元时间序列分类方法及装置的整体流程图。
具体实施方式
[0078]
自监督学习分类任务实现:
[0079]
在我们实验中,当dim=2时,取r=1,k=1,负样本的标签为1。当dim>2 时,取k=2,将原始数据a中的r个数据替换为数据b中对应r=dim//3个设备的数据,此标签设为1;标签为2的数据设计为从原始数据中随机选取 r=dim//3*2个设备的数据,其中r/2个数据替换为数据b中对应设备的数据,另外r/2个数据替换为数据c中对应设备的数据。其中a、b、c为三个不同的数据。比如我们的次声数据集,每个事件有三个设备的数据,分别为x1,x2,x3,将未经变换的数据x
a1
,x
a2
,x
a3
标签为0;将x
a1
,x
b2
,x
a3
、x
a1
,x
a2
,x
b3
、x
b1
,x
a2
,x
a3
标记为1,x
a1
,x
b2
,x
c3
、x
c1
,x
b2
,x
a3
等标记为2,其中x
ij
表示第i个数据中第j个设备的数据。
[0080]
模型实现:
[0081]
在本发明中取m=1,n=3,b=128,d=8。
[0082][0083]
[0084]
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1