一种模型训练方法、装置及电子设备与流程
1.本公开属于人工智能领域,可应用于图像处理、精密仪器领域,尤其可应用于眼科oct等医疗设备领域。
背景技术:
2.人类眼底组织在光学相干断层扫描技术(optical coherence tomography,简称oct)图像上呈现层次分明的层状结构。大部分眼底病变与眼底层结构属性息息相关,例如,视网膜病变会改变视网膜层厚度、某些眼底病变只出现在特定层结构中等。对oct眼底图像进行层结构分割是眼底图像分析的基础,对眼底层结构进行快速准确分割,有助于量化眼底结构属性,从而辅助医生和研究人员研究、诊断和治疗眼底病变。
技术实现要素:
3.发明人经对现有技术研究分析发现,现有技术中,针对眼底图像结构的精细标注获取难度较大,导致用于眼底图像分割模型开发的样本数量较少,且采集眼底图像受图像采集设备型号、拍摄模式和扫描范围单一等因素影响,导致图像来源单一,使得对眼底oct图像的分割模型的应用场景受限,难以在大规模多源图像数据下应用。
4.有鉴于此,本公开的目的在于提供一种模型训练方法、装置及电子设备,以解决上述技术问题。
5.第一方面,本公开提供了一种模型训练方法,包括:
6.获取多个oct医学图像以及对应的多个关于组织结构的标注图像;
7.基于所述多个oct医学图像以及对应的所述多个组织结构标注图像,划分出第一训练集和第一验证集;
8.在图像宽度方向上对所述第一训练集和所述第一验证集中的图像进行采样,得到对应的第二训练集和第二验证集;
9.基于所述第二训练集和所述第二验证集,对至少一个候选模型进行训练并确定出目标模型,以便用于对oct医学图像进行图像分割。
10.可选的,在图像宽度方向上对所述第一训练集和所述第一验证集中的图像进行采样,包括:
11.在图像宽度方向上,以特定步长滑动满足特定窗口宽度的窗口,分别对所述第一训练集和所述第一验证集中的图像进行裁剪,
12.其中,所述特定步长小于所述特定窗口宽度。
13.可选的,所述方法还包括:
14.在图像高度方向上,对所述第一训练集和所述第一验证集中已完成图像宽度方向上的采样得到的图像进行填充,以使通过图像宽度方向上的采样得到的图像在图像高度方向上达到预定高度值,
15.其中,所述预定高度值为2的幂次。
16.可选的,所述oct医学图像包括眼底oct图像;
17.所述关于组织结构的标注图像是对对应眼底oct图像中涉及眼后节特定组织结构和/或眼后节特定组织结构间进行图像分割和标注得到的,其中,所述眼后节特定组织结构包括以下组织结构中的一种或多种:玻璃体、神经纤维层、神经节细胞层、内丛状层、内核层、外丛状层、外核层、外界膜、肌样体带、椭圆体带、神经色素上皮层、脉络膜、巩膜、视盘。
18.可选的,所述多个oct医学图像包括多个眼底oct图像;
19.所述多个眼底oct图像包括:对多个患者以多种拍摄模式进行眼部拍摄获得的涉及多个拍摄范围的眼底oct图像。
20.可选的,对至少一个候选模型进行训练并确定出目标模型包括:
21.基于所述第二训练集对至少一个候选模型中的每个模型分别进行训练;
22.基于所述第二验证集,针对每个训练后的候选模型确定预测值与对应标注值之间的交并比;
23.基于确定的交并比,从至少一个训练后的候选模型中选定一个模型以作为所述目标模型。
24.可选的,所述方法还包括在训练过程中执行以下操作中的至少之一:
25.调整所述目标模型的卷积次数;
26.调整所述目标模型中卷积核的个数;
27.调整所述目标模型的下采样次数。
28.第二方面,本公开还提供了一种模型训练装置,包括:
29.获取模块,用于获取多个oct医学图像以及对应的多个关于组织结构的标注图像;
30.划分模块,用于基于所述多个oct医学图像以及对应的所述多个组织结构标注图像,划分出第一训练集和第一验证集;
31.图像采样模块,用于在图像宽度方向上对所述第一训练集和所述第一验证集中的图像进行采样,得到对应的第二训练集和第二验证集;
32.模型选择模块,用于基于所述第二训练集和所述第二验证集,对至少一个候选模型进行训练并确定出目标模型,以便用于对oct医学图像进行图像分割。
33.第三方面,本公开还提供了一种电子设备,包括:
34.至少一个处理器;以及
35.与所述至少一个处理器通信连接的存储器;其中,
36.所述存储器存储有可被所述至少一个处理器执行的指令,所述指令被所述至少一个处理器执行,以使所述至少一个处理器能够执行本公开任一方法实施例所述的模型训练方法。
37.第四方面,本公开还提供了一种存储有计算机指令的非瞬时计算机可读存储介质,其中,所述计算机指令用于使所述计算机执行本公开任一方法实施例所述的模型训练方法。
38.从上述技术方案可知,本公开至少具有以下技术效果:
39.在图像样本采集方面,突破了单一设备型号、单一扫描模式的限制,采集了源自多型号设备、以多模式拍摄的大量图像,使得本公开实施例中的训练模型可以适用于大规模多源图像数据。通过对多渠道获取的眼底oct图像做采样处理,不仅统一了图像尺寸,还扩
增了图像数量。将不同规格图像输入模型训练,提高了图像分割模型的泛化性。在图像标注方面,对眼底oct图像进行了包括视盘区域的精细化标注,极大扩充了带精细标注的数据量。在模型开发方面,建立了一种端到端的训练模型,经过模型标准框架选择和调优,区别于现有方案多阶段、多模块的特点,端到端模型可减少误差传播的途径,实现模型整体优化,从而可以快速、准确地对来源多样的眼底oct图像进行组织结构分割,并在大规模图像上验证了其结果的准确性。
附图说明
40.为了更清楚地说明本公开实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图是本公开的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
41.图1示例性示出了本公开实施例的一种模型训练方法的流程图;
42.图2示例性示出了本公开实施例的眼底图像;
43.图3示例性示出了本公开实施例的对应图2的标注图像;
44.图4示例性示出了本公开实施例的图2中涉及的各眼底组织结构;
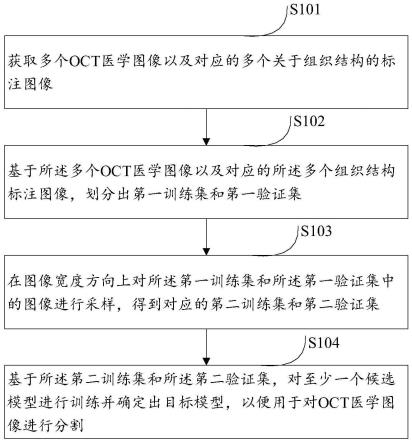
45.图5示例性示出了本公开实施例的对应于图2的模型预测结果图;
46.图6示例性示出了本公开实施例的模型训练装置的结构示意图。
具体实施方式
47.为使本公开实施例的目的、技术方案和优点更加清楚,下面将结合本公开实施例中的附图,对本公开实施例中的技术方案进行清楚、完整地描述。显然,所描述的实施例是本公开一部分实施例,而不是全部的实施例。基于本公开中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本公开保护的范围。
48.请参阅图1,其示出了本公开实施例的一种模型训练方法的流程,具体包括以下操作。
49.操作s101,获取多个oct医学图像以及对应的多个关于组织结构的标注图像。
50.其中,oct医学图像包括但不限于眼底oct图像。
51.在一些实施例中,获取的多个oct医学图像包括多个眼底oct图像。多个眼底oct图像可以包括:对多个患者以多种拍摄模式进行眼部拍摄获得的涉及多个拍摄范围的眼底oct图像。由此,获取的图像样本不仅数量多,而且涉及多个患者、多种拍摄模式、多个拍摄范围,因此可以提高本公开实施例中模型应用的泛化性。并且可以理解,本公开实施提供的技术方案适用场景可以覆盖多种临床医学场景。
52.在获得oct医学图像后,可以由标注人员对oct医学图像做标注得到标注图像。以眼底oct图像为例,对应的标注图像可以是对眼底oct图像中涉及的眼后节特定组织结构和/或眼后节特定组织结构间进行图像分割和标注得到的。
53.其中,眼后节特定组织结构包括以下组织结构中的一种或多种:玻璃体、神经纤维层、神经节细胞层、内丛状层、内核层、外丛状层、外核层、外界膜、肌样体带、椭圆体带、神经色素上皮层、脉络膜、巩膜、视盘。
54.需要说明的是,眼底oct图像分割和标注时,除以上述眼后节特定组织结构为单位标注外,还可以以特定组织结构之间包括的组织结构为单位分割和标注,举例说明,比如可以把椭圆体带与神经色素上皮层之间的组织结构分割为一个整体组织,具体的,神经色素上皮层位于椭圆体带的下方,因此椭圆体带与神经色素上皮层之间的组织结构为椭圆体带下边界与神经色素上皮层之间的组织结构(椭圆体带下边界-神经色素上皮层)。
55.当然,可以理解的是,以眼后节特定组织结构间进行图像分割,并不仅只包括上述举例,其他组织结构的结合分割这里不再赘述。在不同的临床医学场景下,医生会关注不同的组织结构,因此对以上多种组织结构进行图像分割,可以满足医生的各种临床需求,有益于临床诊断。示例性的,视盘的完整、准确分割有助于青光眼的分析;对脉络膜边界准确、完整地分割有助于视网膜和脉络膜浆液性病变的研究;视网膜分层对其分层地细化可以进一步辅助眼底疾病的研究。
56.本公开实施例中,以眼底oct图像为例,对图像进行标注是指按眼底结构画分层线或轮廓线,然后将分层线或轮廓线之间的区域填充为标注值。比如以椭圆体为例,画出椭圆体的边界,将边界内的区域做填充。可选的,可以将椭圆体对应的填充区域的像素值设置为标注值,其他组织结构的标注以此类推,这里不再赘述。
57.操作s102,基于所述多个oct医学图像以及对应的所述多个组织结构标注图像,划分出第一训练集和第一验证集。
58.本操作中,基于多个oct医学图像以及对应的多个组织结构标注图像划分第一训练集和第一验证集时,需要注意以下原则:
59.第一,第一训练集和第一验证集中的标注图像要具有相对独立性,从而避免数据泄露,防止误导性的模型评价指标值掩盖模型性能的缺陷。优选的,对于眼底oct图像,对应同一只眼睛的所有标注图像可以全部划分到第一训练集或全部划分到第一验证集中。
60.第二,为了保证第一验证集呈现数据多样性分布,使模型的泛化性得到验证,在划分第一训练集和第一验证集时,第一验证集可以体现拍摄设备型号、扫描模式等属性的多样性。以设备型号属性举例,若第一训练集中包含拍摄设备1和拍摄设备2的图像数据,则在第一验证集中也应包含拍摄设备1和拍摄设备2的图像数据。
61.举例说明,以ss-oct(扫频源光学相干层析)设备为例,拍摄模式包括单线模式、辐射模式、3d黄斑模式、黄斑octa(眼底相干光层析血管成像术(octa))模式、3d视盘模式、视盘octa模式等,采集时可以取两个ss-oct设备在所有模式下针对多个患者进行500次拍摄所获得的oct医学图像。可以对500次拍摄获得的所有oct医学图像进行标注。考虑到图像的人工标注成本,可选的,可以从500次拍摄所得图像中选择部分图像进行标注。假设500次拍摄共获得53300张b扫描图像,按照各扫描模式比例均衡的规则,可以提取其中3871张b扫描图像进行标注。此抽样操作在保证模型泛化性的同时,可以减少待标注图像的数量,进而降低标注成本。
62.对上述3871张b扫描图像进行标注后,划分第一训练集和第一验证集时,可以参考第一训练集和第一验证集的划分注意事项(划分原则)。在本公开的一个实施例中,可以在拍摄层面将3871张b扫描图像涉及的拍摄次数以4:1的比例划分训练集和验证集。比如,如果选择的3871张图像来自于500次拍摄,那么划分时,将这500次拍摄划分为400次拍摄和100次拍摄,其中,400次拍摄包含的标注图像作为第一训练集,100次拍摄包含的标注图像
作为第一验证集。然后,根据划分原则,适应调整第一训练集和第一验证集,使第一训练集和第一验证集符合划分原则。
63.操作s103,在图像宽度方向上对所述第一训练集和所述第一验证集中的图像进行采样,得到对应的第二训练集和第二验证集。
64.由于扫描模式、扫描范围的多样性,导致oct医学图像尺寸(图像尺寸可以理解为图像像素数量)不统一。比如,不同拍摄设备或同一拍摄设备在拍摄范围不同的情况下均会导致图像尺寸不统一。在对oct医学图像完成标注后,为了满足模型需要统一图像输入尺寸的要求,首先要对标注图像进行采样预处理,统一图像尺寸。
65.本公开实施例中对标注图像的预处理采用了图像采样技术。具体的,可以在图像宽度方向上对所述第一训练集和所述第一验证集中的图像进行采样,例如以特定窗口尺寸对第一训练集和第一验证集中的图像进行采样,并且以特定步长滑动满足所述特定窗口宽度的窗口,分别对所述第一训练集和所述第一验证集中的图像在宽度方向上进行裁剪。在一些实施例中,为保证裁剪获取的图像相互有重叠,避免丢失重要图像信息,可以使上述特定步长小于上述特定窗口本身的宽度。
66.为了便于对图像裁剪的理解,下面在宽度方向上,以特定窗口宽度为512像素,特定步长设定为256像素为例说明。
67.以不同模式下三种图像尺寸为例,包括984
×
512(图像高度为984像素,宽度为512像素)、984
×
1024(图像高度为984像素,宽度为1024像素)、984
×
1536(图像高度为984像素,宽度为1536像素)。
68.对于图像宽度为512像素的图像,特定窗口宽度为512像素,可以理解,即直接取原图。
69.对于图像宽度为1024像素的图像,特定窗口宽度为512像素,特定步长为256像素,则一幅图像可以裁剪成宽度下标为0~512像素、256像素~768像素、512像素~1024像素的三幅图像,其中,宽度下标为256像素~768像素的图像与宽度下标为0~512像素和512像素~1024像素的图像均有重叠。
70.对于图像宽度为1536像素的图像,特定窗口宽度为512像素,特定步长为256像素,则一幅图像可以裁剪成宽度下标为0~512像素、256像素~768像素、512像素~1024像素、768像素~1280像素、1024像素~1536像素的五幅图像,其中宽度下标为0~512像素和256像素~768像素的图像有重叠,宽度下标为256像素~768像素的图像又与宽度下标为512像素~1024像素的图像有重叠,宽度下标为512像素~1024像素的图像又与宽度下标为768像素~1280像素的图像有重叠,宽度下标为768像素~1280像素的图像又与宽度下标为1024像素~1536像素的图像有重叠。
71.通过图像裁剪不仅可以统一图像宽度,还可以扩增用于训练的图像数量。
72.需要说明的是,对于上述裁剪得到的图像,在宽度上实现了图像尺寸的统一。另外,还需考虑图像在高度上的统一。本公开提供的实施例中,以对图像在高度方向上采样的方式实现图像高度上的统一,具体的,在图像高度方向上对所述第一训练集和所述第一验证集中的图像进行采样,包括在图像高度方向上,对所述第一训练集和所述第一验证集中已完成图像宽度方向上的采样而得到的图像进行填充,以使通过图像宽度方向上采样得到的图像的高度达到预定高度值,其中,所述预定高度值可以为2的幂次。
73.可选的,对宽度方向上裁剪得到的图像,在高度方向上再采用双线性插值将裁剪后的图像高度可以统一到2的幂次,比如1024。需要说明的是,图像进行双线性插值前后图像尺寸差异较小,图像采样前后的空间分辨率基本不变,所以图像尺寸的影响可以忽略不计。图像高度统一到2的幂次,在进行模型训练时,图像经过池化层时不需要对特征图进行填充,因而不会引入相应的编码、解码误差。
74.操作s104,基于所述第二训练集和所述第二验证集,对至少一个候选模型进行训练并确定出目标模型,以便用于对oct医学图像进行图像分割。
75.对于模型训练来说,选择合适的模型至关重要,模型与图像的实际应用场景有关,根据采用的oct图像的应用场景,选择至少一个候选模型,基于第二训练集对至少一个候选模型中的每个模型分别进行训练。在一些实施例中,候选模型可以包括但不限于deeplabv3+、unet、unet++、unet_vgg16。
76.基于第二验证集从训练后的至少一个候选模型中选择性能较优的模型。可选的,选择性能较优的模型时,可以先针对每个训练后的候选模型确定预测值与对应标注值之间的交并比,然后基于确定的交并比,从至少一个训练后的候选模型中选定一个模型以作为所述目标模型。可以理解的是,单独就交并比这一指标来说,交并比越大表示预测值与对应标注值越接近。
77.举例说明,模型的输入为:眼底oct图像x和对应的标注图像y。模型的输出为:模型预测的标注图像y'。此时,要计算标注图像y和预测标注y'的相似程度,即,将上述的“预测值与对应标注值之间的交并比”作为衡量指标。计算交并比需要两个参数,一个是标注图像y和预测标注图像y'的交集面积,另一个是标注图像y和预测标注y'并集面积,交集面积占并集面积的比例即为交并比。交并比越大,代表预测结果与标注结果越相似。极端情况下,当交并比为1时,预测区域与标注区域完全一致。
78.下面分别从模型输入的图像尺寸选择和模型结构的选择对目标模型的确定过程进行详细说明。需要说明的是,在本公开实施例中,模型的图像输入尺寸和具体模型结构的选择可以独立进行,而且也不对其先后顺序进行限定。
79.1、模型输入图像尺寸的选择
80.模型推理时间与输入图像尺寸有很大关系,选择合适的图像尺寸,在保证模型精度的前提下,可以大幅减少模型推理时间。在一些实施例中,通过双线性插值将第二验证集中的图像缩小到不同尺寸进行实验,从而比较在不同输入图像尺寸下,模型的精度和推理时间。考虑到unet有4组2倍下采样,所以限定输入图像宽度至少为128像素,若输入图像宽度为64像素,则经过4组2倍下采样后特征图尺寸只有4,造成特征信息丢失。如表1所示,不同的输入图像尺寸的模型精度相差无几,故选用模型推理时间最少的输入图像尺寸256
×
128(图像高度为256像素,图像宽度为128像素)。表1中,图像尺寸表达式中左边部分表示图像高度像素,右边表示图像宽度像素。ms是时间单位毫秒,miou为平均交并比。
81.表1不同输入图像尺寸对应的模型性能
[0082][0083]
2、模型结构的选择
[0084]
在选择模型结构时,采用先选取模型主体框架,后细化模型的具体结构的构思。基于第二训练集和第二验证集进行模型主体框架选择时,本公开实施例中,提供了5种主体框架的候选模型,包含deeplabv3+、unet、unet++、unet_vgg16,以miou(平均交并比)作为评价指标,如表2所示,发现unet框架对应的miou最大,模型性能最好,故将其作为最终选择的模型主体框架(对应于前述目标模型的主体框架)。
[0085]
表2模型主体框架选取
[0086]
模型主体框架unetunet++unet_vgg16deeplabv3+验证集上miou0.80870.75490.76330.7996
[0087]
确定模型主体框架后,在一些实施例中,训练过程中还可以调整所述目标模型的以下参数中的至少之一:卷积次数、卷积核个数、下采样次数。具体的,卷积次数、卷积核个数的调整可以通过多次实验确定。
[0088]
以unet标准框架为例,本方案分别对unet框架的卷积核个数、卷积次数和下采样次数进行调整,选取miou和模型推理速度作为衡量指标,根据各待选模型在验证集上的性能(表3),综合考虑精度和推理时间后,将减少卷积核个数的unet确定为目标模型结构。目标模型结构在验证集上各个类别上的精度如表4所示。
[0089]
表3 unet标准框架细化实验
[0090][0091]
表4目标模型对不同组织结构进行图像分割的精度
[0092][0093]
基于上述实验示例描述,目标模型采用输入图像尺寸为256
×
128,模型结构为减少卷积核个数的unet模型。由该目标模型对测试图像(测试集中的图像)进行预测,并计算
模型评价指标。
[0094]
进一步的,可以采用测试集对目标模型进行性能测试。需要说明的是,对于测试集,可以有不同的获取方式,测试集可以是在确定第一训练集和第一验证集时确定测试集,参考操作s101中的描述,可以将获取的oct医学图像划分为三份数据,分别为第一训练集、第一验证集和测试集。沿用操作s102中的示例,在一种实施例中,对于总共3871张b扫描图像及分割标注,将其划分为第一训练集2656张,第一验证集575张,测试集640张。需要注意的是,测试集中的图像要同时与第一训练集和第一验证集的相对独立。可选的,测试集中的图像还可以是另外收集的oct医学图像。
[0095]
本公开实施例提供一个标注示例,参考图2至图5所示,图2为本公开实施例提供的一个采集的眼底oct图像,采用本公开实施例提供的标注方法,对图2所示的眼底oct图像进行标注,得到对应的标注图像,如图3所示。各组织结构如图4所示,包括玻璃体1、神经纤维层2、(神经节细胞层+内丛状层)3、内核层4、外丛状层5、(外核层+外界膜+肌样体带)6、椭圆体带7、(椭圆体带下界-神经色素上皮层)8、神经色素上皮层9、脉络膜10、巩膜11、视盘12。图5为对应于图2所示眼底oct图像的模型预测结果图。结合图2、图3和图5可以看到预测结果与图像标注中视网膜分层结果基本一致,脉络膜与巩膜边界也较为一致,视盘形态相差无几。
[0096]
通过上述实施例的描述,本公开实施例提供的技术方案至少具有以下有益的技术效果:
[0097]
1.在图像采集方面,现有技术的样本集(包括训练集、验证集和测试集等)受限于采集设备型号单一,拍摄模式和扫描范围单一等。例如,样本集仅以单一型号设备采集的单一扫描范围的oct三维扫描构成。本公开实施例突破单一设备型号、单一扫描模式的限制,采集了源自多型号设备、以多模式拍摄的大量图像作为图像样本。
[0098]
2.设计了图像预处理手段,以图像采样方法解决多源、多扫描模式图像带来的图像尺寸不统一的问题,从而提高了分割模型的泛化性。
[0099]
3.本公开实施例定义并大量精细标注了眼底oct图像包含视盘在内的所有组织结构。现有技术在类别标签设置上精细程度较低。特别地,受目前大多数采集设备扫描范围的限制,现有技术未考虑视盘对层结构分割任务的干扰。本公开实施例对眼底oct图像进行了包括视盘区域的精细化标注,此外,由于图像标注难度大,现有技术带精细标注的数据量稀少,难以支撑数据驱动型多层分割模型开发。本公开实施例对层结构和视盘区域做精细标注,极大扩充了带精细标注的图像数据量,有助于模型优化。
[0100]
4.使用端到端的深度学习网络。区别于现有方案多阶段、多独立模块的特点,端到端的模型训练可以减少误差传播的途径,实现模型整体优化,从而可以快速、准确地对来源多样的眼底oct图像进行组织结构分割。
[0101]
5.建立了对模型框架的适配度调优方案。根据实际场景,调整模型框架的任务适配度,这对于模型性能在特定应用场景下的提升具有积极意义。本公开通过衡量调整后模型的任务适配度,确定目标模型结构,以最优化模型性能。
[0102]
与上述方法实施例相对应,本公开实施例还公开一种模型训练装置,其结构如图6所示,可以包括:获取模块61、划分模块62、图像采样模块63、模型选择模块64。
[0103]
获取模块61,用于获取多个oct医学图像以及对应的多个关于组织结构的标注图
像;
[0104]
划分模块62,用于基于所述多个oct医学图像以及对应的所述多个组织结构标注图像,划分出第一训练集和第一验证集;
[0105]
图像采样模块63,用于在图像宽度方向上对所述第一训练集和所述第一验证集中的图像进行采样,得到对应的第二训练集和第二验证集;
[0106]
模型选择模块64,用于基于所述第二训练集和所述第二验证集,对至少一个候选模型进行训练并确定出目标模型,以便用于对oct医学图像进行图像分割。
[0107]
在一种实施例中,图像采样模块63,具体用于在图像宽度方向上,以特定步长滑动满足特定窗口宽度的窗口,分别对所述第一训练集和所述第一验证集中的图像进行裁剪,
[0108]
其中,所述特定步长小于所述特定窗口宽度。
[0109]
在一种实施例中,所述模型训练装置还可以包括图像填充模块,用于
[0110]
在图像高度方向上,对所述第一训练集和所述第一验证集中已完成图像宽度方向上的采样得到的图像进行填充,以使通过图像宽度方向上的采样得到的图像在图像高度方向上达到预定高度值,
[0111]
其中,所述预定高度值为2的幂次。
[0112]
在一种实施例中,所述oct医学图像包括眼底oct图像;
[0113]
所述关于组织结构的标注图像是对对应眼底oct图像中涉及眼后节特定组织结构和/或眼后节特定组织结构间进行图像分割和标注得到的,
[0114]
其中,所述眼后节特定组织结构包括以下组织结构中的一种或多种:玻璃体、神经纤维层、神经节细胞层、内丛状层、内核层、外丛状层、外核层、外界膜、肌样体带、椭圆体带、神经色素上皮层、脉络膜、巩膜、视盘。
[0115]
在一种实施例中,所述多个oct医学图像包括多个眼底oct图像;
[0116]
所述多个眼底oct图像包括:对多个患者以多种拍摄模式进行眼部拍摄获得的涉及多个拍摄范围的眼底oct图像。
[0117]
在一种实施例中,所述模型选择模块包括训练子模块、计算子模块和确定子模块。
[0118]
其中,训练子模块用于基于所述第二训练集对至少一个候选模型中的每个模型分别进行训练;
[0119]
计算子模块,用于基于所述第二验证集,针对每个训练后的候选模型确定预测值与对应标注值之间的交并比;
[0120]
确定子模块用于基于确定的交并比,从至少一个训练后的候选模型中选定一个模型以作为所述目标模型。
[0121]
在一种实施例中,所述装置还包括调整模块,用于在训练过程中执行以下操作中的至少之一:调整所述目标模型的卷积次数;调整所述目标模型中卷积核的个数;调整所述目标模型的下采样次数。
[0122]
本公开实施例还公开一种电子设备,电子设备包括至少一个处理器;以及,与所述至少一个处理器通信连接的存储器;其中,所述存储器存储有可被所述至少一个处理器执行的指令,所述指令被所述至少一个处理器执行,以使所述至少一个处理器能够执行以下操作:
[0123]
获取多个oct医学图像以及对应的多个关于组织结构的标注图像;
[0124]
基于所述多个oct医学图像以及对应的所述多个组织结构标注图像,划分出第一训练集和第一验证集;
[0125]
在图像宽度方向上对所述第一训练集和所述第一验证集中的图像进行采样,得到对应的第二训练集和第二验证集;
[0126]
基于所述第二训练集和所述第二验证集,对至少一个候选模型进行训练并确定出目标模型,以便用于对oct医学图像进行图像分割。
[0127]
其中,在图像宽度方向上对所述第一训练集和所述第一验证集中的图像进行采样,包括:在图像宽度方向上,以特定步长滑动满足特定窗口宽度的窗口,分别对所述第一训练集和所述第一验证集中的图像进行裁剪,其中,所述特定步长小于所述特定窗口宽度。
[0128]
所述处理器还执行以下操作:
[0129]
在图像高度方向上,对所述第一训练集和所述第一验证集中已完成图像宽度方向上的采样得到的图像进行填充,以使通过图像宽度方向上的采样得到的图像在图像高度方向上达到预定高度值,
[0130]
其中,所述预定高度值为2的幂次。
[0131]
其中,所述oct医学图像包括眼底oct图像;
[0132]
所述关于组织结构的标注图像是对对应眼底oct图像中涉及眼后节特定组织结构和/或眼后节特定组织结构间进行图像分割和标注得到的,
[0133]
其中,所述眼后节特定组织结构包括以下组织结构中的一种或多种:玻璃体、神经纤维层、神经节细胞层、内丛状层、内核层、外丛状层、外核层、外界膜、肌样体带、椭圆体带、神经色素上皮层、脉络膜、巩膜、视盘。
[0134]
其中,所述多个oct医学图像包括多个眼底oct图像;
[0135]
所述多个眼底oct图像包括:对多个患者以多种拍摄模式进行眼部拍摄获得的涉及多个拍摄范围的眼底oct图像。
[0136]
所述处理器对至少一个候选模型进行训练并确定出目标模型包括:
[0137]
基于所述第二训练集对至少一个候选模型中的每个模型分别进行训练;
[0138]
基于所述第二验证集,针对每个训练后的候选模型确定预测值与对应标注值之间的交并比;
[0139]
基于确定的交并比,从至少一个训练后的候选模型中选定一个模型以作为所述目标模型。
[0140]
所述处理器在训练过程中还执行以下操作中的至少之一:
[0141]
调整所述目标模型的卷积次数;
[0142]
调整所述目标模型中卷积核的个数;
[0143]
调整所述目标模型的下采样次数。
[0144]
本公开实施例还公开一种存储介质,存储介质上存储有计算机程序代码,计算机程序代码实现上述任一实施例所述的模型训练方法。
[0145]
需要说明的是,本说明书中的各个实施例均采用递进的方式描述,每个实施例重点说明的都是与其他实施例的不同之处,各个实施例之间相同相似的部分互相参见即可。对于装置类实施例而言,由于其与方法实施例基本相似,所以描述的比较简单,相关之处参见方法实施例的部分说明即可。
[0146]
以上所述仅是本公开的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本公开原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本公开的保护范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1