一种基于自然语义处理和深度学习的敏感信息提取方法与流程
本发明涉及信息安全技术领域,更具体地,本发明考虑了网络中敏感信息的智能提取方法,及文本文件的处理过程,提出一种基于自然语义处理方法如正则匹配和bert,及改进长短期记忆网络的网络敏感信息提取方法。
背景技术:
信息泄漏一直是信息安全领域的一个重要问题,敏感信息一旦泄漏,会导致严重后果。而大多数敏感信息都储存在非结构化数据中,如何提取来自大量非结构化数据中的敏感信息已成为最重要的信息之一挑战。针对网络中敏感信息提取的研究就是在这种背景下产生。敏感信息提取的目的是通过自然语义处理方法从文本文件中提取出敏感信息,通过判断敏感信息的存在对其加以保护,而网络中存在的文本文件大多存储非结构化数据中,单纯使用基于正则匹配的方法识别提取文件中的敏感信息存在提取不完整,提取准确度不高等问题。因此,有必要对非结构化数据进行处理,进而采用现存的智能方法对敏感信息提取,实现敏感信息提取的高度完整性、精准性。非结构化数据文件格式种类多,不同格式的文件需要特定的工具或软件对其进行解析。目前对于敏感信息提取的研究主要可分为基于正则匹配的方法和基于机器学习算法的方法。前者更加关注敏感信息模式的定义,通过定义提取模板进行信息提取,该种方法的准确率强依赖定义的提取模板,受主观影响较大。基于机器学习的信息提取方法主要基于统计模型,如隐马尔科夫模型、最大熵模型、支持向量机等,但这些方法易受预料库本身问题造成的数据稀疏的问题,实际中经常出现把非敏感信息错当成敏感信息提取出来,误报率较高,而近些年流行的深度学习方法能够将文本内容以序列的方式输入进行模型训练,可学习文本序列内容的词向量间关系。为了将文本内容转化为词向量以实现智能化提取,现存的word2vector属于静态模型无法处理文本文件中的多义词,因此有必要使用动态模型对文本内容进行处理。同时,长短期记忆网络(lstm)作为一种高效的深度学习算法,可一次性输入文本序列内容学习序列内词向量间的关系,这无疑加大了识别敏感信息的准确性,本发明通过改进lstm形成具有注意力机制的双向长短期记忆网络(abi-lstm)以实现敏感信息的精准识别。针对具有可预测模型的文本,本发明采用传统的正则匹配方法对敏感信息进行提取,为了提高敏感信息识别效果,本发明采用bert模型对文本内容进行向量化实现相同词语在不同句子中具有的不同意义的向量转换,进而生成文本序列并对abi-lstm进行训练以实现敏感信息的二次提取。
技术实现要素:
本发明的目的在于一种基于自然语义处理和深度学习的敏感信息提取方法,该方法可以应用于信息安全、信息检索等领域方面的敏感信息提取工作中。
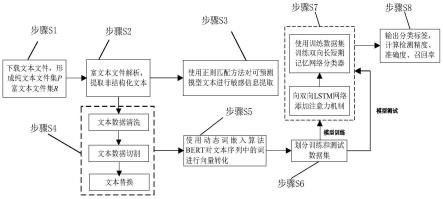
一种基于自然语义处理和深度学习的敏感信息提取方法,包括如下步骤:步骤s1:文本文件采集,根据格式将文本文件分为纯文本文件集p和富文本文件集r,其中富文本文件格式包括html,xml,pdf,doc,pst,rtf;步骤s2:富文本文件解析,使用开源工具htmlparser,pugixml,pdflib,python-docx,libpst,win32com不同格式的富文本文件进行解析;步骤s3:可预测模型的敏感信息提取,使用正则匹配方法对具有可预测模型文本进行敏感信息提取,如ip地址、mac地址、邮箱、aip关键字、证书、证书请求、私钥内容;步骤s4:文本序列生成,对解析后的文本文件进行文本清洗,文本文本分割,以及文本替换;步骤s5:词向量嵌入,使用动态词嵌入算法bert对文本序列中的词进行向量转化;步骤s6:训练、验证、测试数据集划分,按比例将词向量划分为训练数据集,验证数据集和测试数据集;步骤s7:模型训练,将测试词向量数据集输入双向长短期记忆网络(bi-lstm)中,并向训练模型增加注意力机制形成双向注意力长短期记忆网络模型(abi-lstm);步骤s8:模型有效性测试,使用测试集测试abi-lstm模型。上述技术方案中,在步骤s2中,解析富文本文件的具体步骤为:步骤s201:针对html文件,使用htmlparser中的parser类创建解释器,创建filter过滤或visitor访客规则,根据filter或visitor使用解释器获取符合条件文本节点,对文本节点解析;步骤s202:针对xml文件,根据文件内标签将原始xml文件转为对象模型集合,使用dom树存储转换后的数据结构,通过dom接口随机访问存储数据实现文本文件解析;步骤s203:针对pdf文件,解析文件尾获取交叉应用表和根对象编号,使用pdflib库根据交叉引用表以及根对象编号逐层解析文档;步骤s204:针对doc、docx文档,获取要解析的文档对象,输出文档中每一段内容,输出段落编号及段落内容完成解析;步骤s205:针对pst文件,使用libpst直接解析文件,抽取邮件正文和附件等进行解析;针对rtf文件,使用win32com抽取文件正文等进行解析。上述技术方案中,在步骤s3中提取具有可预测模型特征的敏感信息,提取可预测模型文本中的敏感信息具体可表示为:步骤s301:定义具有可预测模型特征的敏感信息,如ip地址,email地址,api关键字,私钥和证书文本;步骤s302:使用python中re模块中的sub()函数提取步骤s301中定义的具有可预测模型特征的敏感信息;步骤s303:保存敏感信息。上述技术方案中,在步骤s4中对解析后文本生成文本序列生成,具体可表示为:步骤s401:文本清洗,移除文本中每行的开始和结束的非ascii字符和空格字符,将大写字符转化为对应的小写字符;步骤s402:文本分割,对文本进行切割成多行,对每行文本作为句子并使用“wordpiece”进行分词;
步骤s403:文本替换,对文本内容url、email进行格式替换,替换后格式为:email username domain和http domain letters。上述技术方案中,在步骤s5中对文本序列中的词进行向量转化,具体可表示为:步骤s501:定义步骤s4中生成的文本序列为x={x1,x2,x3,...,xn},xn为文本序列中第n个单词;步骤s502:使用bert算法计算文本序列x对应的词向量序列e={e1,e2,e3,...,en},其中en为第n个单词xn对应的词向量。上述技术方案中,在步骤s6中对经步骤s5生成的词向量序列划分为训练数据集,验证数据集和测试数据集,具体可表示为:步骤s601:对文本序列进行打标签操作,打标签操作采用“bio”策略;步骤s602:按一定比例将词向量序列集分为训练数据集、验证数据集和测试数据集,三者数据量比例为7:1:2。上述技术方案中,在步骤s7中使用步骤s6生成的训练数据集,验证数据集对模型进行训练及调整abi-lstm模型,具体可表示为:步骤s701:更新长短期记忆网络(lstm)的门结构,具体步骤如下:
①
更新lstm的忘记门:f
t
=σ(w
fet
+ufh
t-1
+bf)
ꢀꢀ
(1)
②
更新lstm的忘记门:i
t
=σ(w
iet
+u
iht-1
+bi)
ꢀꢀ
(2)
③
更新lstm的输入调制门:m
t
=tanh(w
met
+u
mht-1
+bm)
ꢀꢀ
(3)
④
更新lstm的输出门:o
t
=σ(w
oet
+u
oht-1
+bo)
ꢀꢀ
(4)
⑤
生成下一隐含向量状态:h
t
=o
t tanhσ(c
t
)
ꢀꢀ
(5)其中e
t
为输入词向量,h
t-1
为前一时刻lstm的隐含状态,σ和tanh为“sigmoid”函数和双曲正切函数;步骤s702:使用前馈和后馈lstm捕获过去和将来状态,训练双向lstm(bi-lstm)模型,在时刻t生成获取前后馈隐含层状态步骤s703:在bi-lstm最上层添加注意力层形成双向注意力lstm(abi-lstm),具体步骤如下:m
t,t'
=tanh(w
mht
+w
m'hm'
+bm)
ꢀꢀ
(6)a
t,t'
=σ(wam
t,t'
+ba)
ꢀꢀ
(7)其中a
t,t'
为注意力矩阵中的一个元素,可用来捕获隐层状态h
t
和h'
t
间的相似性,wm和w'm为隐含层状态h
t
和h'
t
对应的权重矩阵,wa为对应的非线性组合权重,bm和ba为偏执向量。步骤s704:按如下公式,使用注意力机制生成隐含层状态分类标签l
t
,完成abi-lstm模型训练。
步骤s705:使用验证数据集,根据f1值调节模型至最优。上述技术方案中,在步骤s8中输入测试数据集至abi-lstm分类模型得到分类标签,与实际标签对比计算检测准确度、精度、召回率,具体步骤如下:步骤s801:向训练好的abi-lstm分类器输入测试数据文本序列样本x
t
={x
1t
,x
2t
,...,x
nt
},计算样本x
t
对应的标签值;步骤s802:输入全部的测试文本序列样本至abi-lstm中,统计tp(true positive),fp(false positive),fn(false negative),tn(true negative)的值;步骤s803:按照如下公式计算检测准确性(accuracy),精度(precision),召回率(recall):precision=tp/(tp+fp)*100%recall=tp/(tp+fn)*100%accuracy=(tp+tn)/(tp+fn+tn+fp)本发明与现有技术相比,具有如下有益效果:本发明针对敏感信息提取方法进行分析,采用不同工具对富文本文件进行内容解析,对文本数据进行文本清洗、文本分割、文本替换后使用bert模型对文本进行词语向量化生成数据样本集合进而划分为训练数据集、验证数据集和测试数据集,将这三种数据集应用到提出的改进的长短期记忆网络模型中实现敏感信息提取的模型训练、调整、验证。实验结果验证了所提方法的有效性。本发明采用具有注意力机制的双向长短期记忆网络作为检测器,该检测模型检测准确度高,泛化能力强,本发明可以应用于大规模敏感信息的提取过程中。
附图说明
为了清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用附图作简单地介绍,附图仅用于示例性说明,不能理解为对本专利的限制;图1为本发明方法流程示意图;图2为本发明中为结合bert和abi-lstm的分类模型示意图;表1为本发明中涉及的“bio”打标签策略;图3为本发明所提方法有效性验证示意图;
具体实施方式
为更好说明本发明实施例的目的、技术方案和优点,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。本发明提出一种基于自然语义处理和深度学习的敏感信息提取方法,基于正则匹配和bert,及改进长短期记忆网络提取网络中的敏感信息,其流程示意图如图1所示,包括如下步骤:
步骤s1:采集文本文件,根据格式将文本文件分为纯文本文件集p和富文本文件集r,其中富文本文件格式包括html,xml,pdf,doc,pst,rtf;步骤s2:解析富文本文件,使用开源工具htmlparser,pugixml,pdflib,python-docx,libpst,win32com不同格式的富文本文件进行解析,具体步骤为:步骤s201:针对html文件,使用htmlparser中的parser类创建解释器,创建filter过滤或visitor访客规则,根据filter或visitor使用解释器获取符合条件文本节点,对文本节点解析;步骤s202:针对xml文件,根据文件内标签将原始xml文件转为对象模型集合,使用dom树存储转换后的数据结构,通过dom接口随机访问存储数据实现文本文件解析;步骤s203:针对pdf文件,解析文件尾获取交叉应用表和根对象编号,使用pdflib库根据交叉引用表以及根对象编号逐层解析文档;步骤s204:针对doc、docx文档,获取要解析的文档对象,输出文档中每一段内容,输出段落编号及段落内容完成解析;步骤s205:针对pst文件,使用libpst直接解析文件,抽取邮件正文和附件等进行解析;针对rtf文件,使用win32com抽取文件正文等进行解析。步骤s3:可预测模型的敏感信息提取,使用正则匹配方法对具有可预测模型文本进行敏感信息提取,如ip地址、mac地址、邮箱、aip关键字、证书、证书请求、私钥内容,具体步骤为:步骤s301:定义具有可预测模型特征的敏感信息,如ip地址,email地址,api关键字,私钥和证书文本;步骤s302:使用python中re模块中的sub()函数提取步骤s301中定义的具有可预测模型特征的敏感信息;步骤s303:保存敏感信息。步骤s4:文本序列生成,对解析后的文本文件进行文本清洗,文本文本分割,以及文本替换,具体步骤为:步骤s401:文本清洗,移除文本中每行的开始和结束的非ascii字符和空格字符,将大写字符转化为对应的小写字符;步骤s402:文本分割,对文本进行切割成多行,对每行文本作为句子并使用“wordpiece”进行分词;步骤s403:文本替换,对文本内容url、email进行格式替换,替换后格式为:email usernamedomain和http domain letters。步骤s5:词向量嵌入,使用动态词嵌入算法bert对文本序列中的词进行向量转化,具体步骤为:步骤s501:定义步骤s4中生成的文本序列为x={x1,x2,x3,...,xn},xn为文本序列中第n个单词;步骤s502:使用bert算法计算文本序列x对应的词向量序列e={e1,e2,e3,...,en},其中en为第n个单词xn对应的词向量。步骤s6:训练、验证、测试数据集划分,按比例将词向量划分为训练数据集,验证数据集和测试数据集,具体步骤为:步骤s601:对文本序列进行打标签操作,打标签操作采用“bio”策略;
步骤s602:按一定比例将词向量序列集分为训练数据集、验证数据集和测试数据集,三者数据量比例为7:1:2。步骤s7:模型训练,将测试词向量数据集输入双向长短期记忆网络(bi-lstm)中,并向训练模型增加注意力机制形成双向注意力长短期记忆网络模型(abi-lstm),具体步骤为:步骤s701:更新长短期记忆网络(lstm)的门结构,具体步骤如下:
①
更新lstm的忘记门:f
t
=σ(w
fet
+ufh
t-1
+bf)
ꢀꢀ
(1)
②
更新lstm的忘记门:i
t
=σ(w
iet
+u
iht-1
+bi)
ꢀꢀ
(2)
③
更新lstm的输入调制门:m
t
=tanh(w
met
+u
mht-1
+bm)
ꢀꢀ
(3)
④
更新lstm的输出门:o
t
=σ(w
oet
+u
oht-1
+bo)
ꢀꢀ
(4)
⑤
生成下一隐含向量状态:h
t
=o
t
tanhσ(c
t
)
ꢀꢀ
(5)其中e
t
为输入词向量,h
t-1
为前一时刻lstm的隐含状态,σ和tanh为“sigmoid”函数和双曲正切函数;步骤s702:使用前馈和后馈lstm捕获过去和将来状态,训练双向lstm(bi-lstm)模型,在时刻t生成获取前后馈隐含层状态步骤s703:在bi-lstm最上层添加注意力层形成双向注意力lstm(abi-lstm),具体如下:m
t,t'
=tanh(w
mht
+w
m'hm'
+bm)
ꢀꢀ
(6)a
t,t'
=σ(wam
t,t'
+ba)
ꢀꢀ
(7)其中a
t,t'
为注意力矩阵中的一个元素,可用来捕获隐层状态h
t
和h'
t
间的相似性,wm和w'm为隐含层状态h
t
和h'
t
对应的权重矩阵,wa为对应的非线性组合权重,bm和ba为偏执向量。
112.步骤s704:按如下公式,使用注意力机制生成隐含层状态分类标签l
t
,完成abi-lstm模型训练。步骤s705:使用验证数据集,根据f1值调节模型至最优。步骤s8:使用测试集测试abi-lstm模型的有效性,具体步骤如下:步骤s801:向训练好的abi-lstm分类器输入测试数据文本序列样本x
t
={x
1t
,x
2t
,...,x
nt
},计算样本x
t
对应的标签值;步骤s802:输入全部的测试文本序列样本至abi-lstm中,统计tp(true positive),fp(false positive),fn(false negative),tn(true negative)的值;步骤s803:按照如下公式计算检测准确性(accuracy),精度(precision),召回率
(recall):precision=tp/(tp+fp)*100%recall=tp/(tp+fn)*100%accuracy=(tp+tn)/(tp+fn+tn+fp)本发明采用开源文本共享平台pastebin上的数据,数据采集于2019年11月至2020年2月,共收集1035634个文本文件。为训练abi-lstm模型,手工选取12673个文档并获取了144967个文本序列作为训练数据。根据表1所示的打标签策略为训练数据添加标签。表1标签策略本发明从检测准确度,精度和召回率三个方面比较了基于abi-lstm、bi-lstm、bert、crf、bigru混合的检测方法。基于所提方法abi-lstm+bert具有最有性能,其中检测精度达到了98.42%,召回率达到了99.58%,准确度达到了98.96%。结果证明了所提方法的正确性和有效性。以上所述,仅为本发明较佳的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,可轻易想到的变化或替换,应涵盖在本发明的保护范围之内。因此,本发明的保护范围应该以权利要求的保护范围为准。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1