基于多标签投影在线哈希算法的图像检索方法
1.本发明属于图像检索技术领域,具体涉及一种基于多标签投影在线哈希算法的图像检索方法。
背景技术:
2.哈希算法因其时间和存储优势而被广泛研究用于解决大规模近似最近邻搜索问题。近年来,出现了一些在线哈希方法,可以更新哈希函数以适应新的流数据,实现动态检索。然而,现有的在线哈希方法需要在查询到达时用最新的哈希函数更新整个数据库,这导致随着流数据的不断增加,检索效率低下。另一方面,这些方法忽略了实例之间的监督关系,尤其是在多标签的情况下。
3.随着互联网上可用数据量的增加,近似最近邻搜索在许多应用中取得了广泛的成功,例如计算机视觉和跨模态检索问题。基于哈希的方法由于其在数据存储和计算效率方面的优势而引起了人工神经网络搜索的广泛关注。哈希旨在将高维特征映射到紧凑的二进制代码中,同时保留原始空间和二进制空间之间的相似性。现有的流行哈希方法大多基于批量学习策略,这阻碍了他们适应数据集增长和多样化的能力,因为计算成本可能变得棘手和不可行。因此,在线哈希方法应运而生,它通过从流数据中更新哈希函数来展示良好的性能-复杂性权衡。在线哈希的重点是在连续流数据的基础上不断更新哈希函数和哈希表,且成本较低。
4.在线哈希一般可分为无监督哈希和监督哈希。无监督的在线哈希大致基于leng等人提出的“草图”的思想。草图是一个较小的特征矩阵,保留了数据库的主要特征。通过实现矩阵分解,哈希函数可以动态有效地更新。有监督的在线哈希基于标签信息学习哈希函数,可以缩小语义鸿沟。huang等人提出的在线核哈希算法首次尝试以成对输入的方式更新哈希函数。使用在线被动-主动策略,可以保留有关流数据的重要信息。cakir利用互信息作为目标函数,并根据它更新哈希表,克服了哈希表频繁更新的问题。lin研究了现有数据和新数据之间的相关性,提出了基于平衡相似度的离散在线哈希(bsodh)。bsodh设置了两个平衡因子来解决由不对称图引起的“不平衡问题”,并通过离散化的方法对其进行优化,从而大大提高了准确性。lin等人认为hadamard矩阵是一种更具鉴别性的码本,通过给hardamard矩阵的每一列分配一个唯一的标签作为目标,以便具有相同标签的数据将具有近似的哈希码,从而哈希函数被更新。
5.尽管现有的有监督的在线哈希方法有效地更新哈希函数,但是哈希表更新过于频繁以至于不能获得高的搜索效率。具体来说,由于哈希函数不断更新,当新的查询到达时,整个哈希表需要根据最新的哈希函数进行更新。否则,查询由最新的哈希函数嵌入,但数据库的哈希码是基于以前的哈希函数,这是不对称的,毫无疑问会导致低准确率。然而,随着数据库的不断增加,更新整个哈希表非常耗时,这是在线哈希的核心问题之一。
6.另一方面,大多数现有的监督散列方法有助于构造码本,并为每个码字分配唯一的标签。这种策略忽略了例子之间的相似关系,尤其是在多标签的情况下。例如,图1给出了
四个点的标签信息。大多数现有方法认为如果它们共享至少一个公共标签,则两个数据样本相同(相似度等于1),否则,相似度等于0(图1中不存在边的两点)。显然,第3点和第2点之间的相似度应该高于第4点和第2点之间的相似度。然而,现有的方法认为这两种情况是一样的,这是不合理的。此外,这些方法大多只考虑了一种相似性准则,即相似矩阵或标签,而忽略了不同角度损失函数的构造。
技术实现要素:
7.本发明的目的是提供一种基于多标签投影在线哈希算法的图像检索方法,以弥补现有技术的不足。
8.本发明改进的哈希算法中首先建立一个查询池,其中记录了每个中心点的最近邻居;当新的查询到达时,只有相应的潜在邻居的二进制代码被更新。此外,还建立了一个考虑多标签监督信息的相似性矩阵,并引入多标签投影损失来进一步保持多标签数据之间的相似性。
9.为达到上述目的,本发明采取的具体技术方案为:
10.一种基于多标签投影在线哈希算法的图像检索方法,包括以下步骤:
11.s1:首先获取图像数据及其对应的标签向量;
12.s2:对图像数据进行预处理:初始化各个参数,并将图像数据划分为多个数据块作为流数据;
13.s3:构造查询池:通过对每个阶段的流数据进行随机采样获得新的中心点,并将中心点的集合作为查询池;
14.s4:针对单标签和多标签图像数据不同情况构造相似度矩阵;
15.s5:考虑相似度矩阵和标签向量作为目标函数;
16.s6:根据目标函数对哈希函数进行更新;
17.s7:利用更新后的哈希函数对查询池进行更新,通过邻居保持算法来保持查询池数据的最近邻居;
18.s8:返回s3步骤,直到所有数据块训练完成,输出检索结果,最终完成图像数据检索。
19.进一步的,所述s3中:在第一个批次中随机选择几个点作为中心点xc,在后面的数据批次中使用蓄水池采样法进行随机采样替换原先查询池中的部分数据。
20.进一步的,所述s4中:根据数据携带标签数不同分为单标签数据和多标签数据。对于多标签数据,设计一个独特的相似度矩阵构建算法,先通过标签向量l构造两个实例xi和xj间的相似性s
+
和s-,计算如下:
[0021][0022]
其中,l表示实例标签向量,由0和1组成,||表示实例所含的标签数量。
[0023]
在上述式子(1)的基础上,取他们的平均值来定义两个实例之间的相似性,这意味着在我们的算法中每个实例都被平等对待。如下所示:
[0024][0025]
进一步的,所述s5中:
[0026]
s5-1:首先要最小化相似度矩阵和哈希码内积之间的误差,同时对新的流数据添加量化误差,目标函数如下:
[0027][0028]
其中和分别表示新数据和累积的旧数据的哈希码,k是哈希码的长度,s
t
表示新数据和旧数据之间的相似度矩阵,w
t
是第t阶段的哈希函数投影矩阵,表示新数据流的特征矩阵;
[0029]
s5-2:对于标签向量,构造了一个标签投影损失来充分利用标签;具体地,流数据和现有数据的标签都被投影以接近它们相应的散列码,其被公式化为:
[0030][0031]
其中p
t
表示表示将标签映射到散列码的投影矩阵,和分别表示新数据和旧数据的标签向量组成的矩阵;标签投影损失可以使二进制码更容易区分,并有效缓解粗粒度相似矩阵带来的不平衡问题。
[0032]
s5-3:为了避免过拟合,为目标函数添加了正则项,并设置了目标函数的五个权重来权衡各个学习部分;总体目标函数如下:
[0033][0034]
进一步的,所述s6中:使用上述公式(5)对哈希函数进行更新,具体地,我们采用了一种交替优化方法,通过更新一个变量,其余的保持不变,直到收敛;计算过程如下:
[0035][0036]
其中id是一个d
×
d的单位矩阵,d是数据的维数;
[0037][0038]
其中ic是一个c
×
c的单位矩阵,c是标签类别总数;
[0039][0040]
其中
[0041]
由于是很难直接优化的,所以我们逐个优化每个哈希位如下所示:
[0042][0043]
其中和分别表示要更新和固定的哈希位,这也适用于其他参数和变量;需要学习参数w
t
,p
t
,
[0044]
进一步的,所述s7中:根据最新的哈希函数对查询池数据及其潜在近
邻进行映射得到哈希码和并对中心点的潜在邻居使用邻居保持算法进行更新,这样,潜在邻居可以随着流数据的增加而动态更新;为第i个中心点的潜在邻居;所述邻居保持算法如下:
[0045]
首先构造一个函数:
[0046]
sh(a,b,α)=sort(hamm(a,b),α)
ꢀꢀꢀ
(10)
[0047]
其中,a,b表示两个哈希矩阵,hamm(a,b)表示两个哈希矩阵之间的汉明距离矩阵,sort(hamm(a,b),α)表示返回b中具有最小值的前α个邻居的索引;最后,第i个中心点的潜在邻居更新如下:
[0048][0049]
本发明的优点和技术成果:
[0050]
为了提高针对图像流数据的在线检索效率,本发明提出了基于多标签投影在线哈希算法的图像检索方法,大大加快了图像数据的在线查询速度。
[0051]
本发明建立了一个查询池来保留潜在的邻居与提出的邻居保留算法。此外,为了充分利用多标签情况下的监督信息,提出了一种相似度构造算法。最后,综合考虑相似性矩阵和标签投影,构造了一个综合损失函数,使得哈希码更具区分性。
[0052]
实验结果表明,在两个基准数据集上,利用本发明,图像数据的在线查询时间显著减少,且具有高精度。
附图说明
[0053]
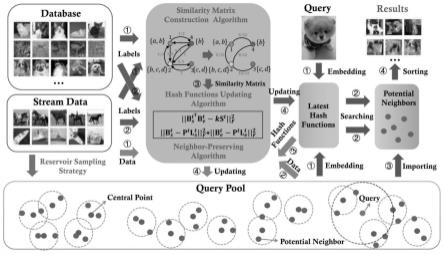
图1为本发明快速在线哈希(foh)的过程示意图。
[0054]
图2为本发明中16位下在线哈希方法的精度-召回曲线图。
[0055]
图3为本发明中32位下在线哈希方法的精度-召回曲线图。
[0056]
图4为本发明中64位下在线哈希方法的精度-召回曲线图。
具体实施方式
[0057]
以下通过具体实施例并结合附图对本发明进一步解释和说明。
[0058]
实施例1:
[0059]
一种基于多标签投影在线哈希算法的图像检索方法,具体流程如图1所示,包括以下步骤:
[0060]
步骤1:首先获取图像数据及其对应的标签向量;在第一阶段从流数据中选取几个中心点组成查询池并得到其潜在邻居点,从第二阶段开始利用蓄水池采样法对流数据采样从而更新查询池;
[0061]
步骤2:根据提出的多标签数据相似度构建算法得到新旧数据间的相似度矩阵;
[0062]
步骤3:根据目标函数更新哈希函数;
[0063]
步骤4:根据新的哈希函数对查询池数据进行映射得到哈希码,同时利用k紧邻方法更新每个中心点的潜在近邻;
[0064]
步骤5:当有新的检索点到来时,通过k近邻方法找到最近的几个中心点及其潜在近邻作为哈希表进行检索;
[0065]
步骤6:返回步骤1,直到完成训练。
[0066]
本发明所提供的快速在线哈希算法(foh)与其他几种在线哈希算法(在线核哈希(okh)、自适应哈希(adapthash)、在线监督哈希(osh)、互信息哈希(mihash)、具有平衡相似度的离散在线哈希(bsodh)、哈达玛矩阵引导的在线哈希(hmoh))在cidfar-10数据集和flickr-25k数据集的性能(表1),实验参数(表2),哈希表更新时间和检索时间(表3),训练时间(表4),消融实验(表5)如下所示:
[0067]
表1
[0068][0069]
表2
[0070][0071]
表3
[0072][0073]
表4
[0074][0075]
表5
[0076][0077]
实施例2:
[0078]
实施例1检索方法的具体包括如下:
[0079]
步骤1:对于图像数据特征向量x={xi}n,将其分为几个批次使得数据以流的方式进行训练。其中第t阶段的新数据表示为累积的旧数据表示为m
t
=n1+
…
+n
t-1
。第一阶段,从流数据中选取几个中心点xc组成查询池,并通过k近邻方法得到每个中心点的潜在近邻。从第二阶段开始通过蓄水池抽样法从流数据中随机采样替换原先查询池中的部分数据从而达到更新查询池的目的。
[0080]
步骤2:根据数据携带标签数不同分为单标签数据和多标签数据。对于多标签数据,设计了一个独特的相似度矩阵构建算法,先通过标签向量l构造两个实例xi和xj间的相似性s
+
和s-,计算如下:
[0081][0082]
其中,l表示实例标签向量,由0和1组成,||表示实例所含的标签数量。
[0083]
在上述式子的基础上,取他们的平均值来定义两个实例之间的相似性,这意味着在本发明的算法中每个实例都被平等对待。如下所示:
[0084][0085]
步骤3:首先要最小化相似度矩阵和哈希码内积之间的误差,同时对新的流数据添加量化误差,目标函数如下:
[0086][0087]
其中和分别表示新数据和累积的旧数据的哈希码,k是哈希码的长度,s
t
表示新数据和旧数据之间的相似度矩阵,w
t
是第t阶段的哈希函数投影矩阵,表示新数据流的特征矩阵。
[0088]
对于标签信息,构造了一个标签投影损失来充分利用标签。具体地,流数据和现有数据的标签都被投影以接近它们相应的散列码,其被公式化为:
[0089][0090]
其中p
t
表示表示将标签映射到散列码的投影矩阵,和分别表示新数据和旧数据的标签向量组成的矩阵。标签投影损失可以使二进制码更容易区分,并有效缓解粗粒度
相似矩阵带来的不平衡问题。
[0091]
进一步的,为了避免过拟合,为目标函数添加了正则项,并设置了目标函数的五个权重来权衡各个学习部分。总体目标函数如下:
[0092][0093]
使用上述(16)对哈希函数进行更新,具体地,采用了一种交替优化方法,通过更新一个变量,其余的保持不变,直到收敛。计算过程如下:
[0094][0095]
其中id是一个d
×
d的单位矩阵,d是数据的维数。
[0096][0097]
其中ic是一个c
×
c的单位矩阵,c是标签类别总数。
[0098][0099]
其中
[0100]
由于是很难直接优化的,所以逐个优化每个哈希位如下所示:
[0101][0102]
其中和分别表示要更新和固定的哈希位,这也适用于其他参数和变量;需要学习参数w
t
,p
t
,
[0103]
步骤4:根据最新的哈希函数对查询池数据及其潜在近邻进行映射得到哈希码和并对中心点的潜在邻居使用邻居保持算法进行更新。为第i个中心点的潜在邻居。邻居保持算法如下所述:
[0104]
首先构造一个函数:
[0105]
sh(a,b,α)=sort(hamm(a,b),α)
ꢀꢀꢀꢀ
(21)
[0106]
其中,a,b表示两个哈希矩阵,hamm(a,b)表示两个哈希矩阵之间的汉明距离矩阵,sort(hamm(a,b),α)表示返回b中具有最小值的前α个邻居的索引。最后,第i个中心点的潜在邻居更新如下:
[0107][0108]
步骤5:当有新的检索点q出现时,先将其映射成哈希码bq,并根据(21)式在查询池中搜索查询点的最近中心点,并返回q的相应潜在邻居,进而得到检索结果。具体计算如下:
[0109]
找到查询点q的相应潜在邻居:
[0110][0111]
将其映射为哈希码β表示返回的中心点数量,最终计算检索结果:
[0112]
[0113]
k表示查询点所需返回的最近邻的数量。
[0114]
步骤6:返回步骤1,直到完成训练。
[0115]
实施例3:
[0116]
在cifar-10和flickr-25k上进行了实验。cifar-10包含10个不同类别的60000幅图像。随机选择1000个例子作为查询集,其余的作为基本集。此外,从基本集随机采样20000幅图像作为训练集。为了模拟流数据,将训练集分成10个块,每个块中有2000个示例。flickr-25k包含25000张图片,由24个标签标注。选择拥有至少20个标签的图像。因此,本发明的实验获得了20015个例子。随机选择2000个例子作为测试,其余的作为训练集和基础集。对于在线哈希,将训练集分成九个块,前八个块每个包含2000个示例,第九个块包含2015个示例。
[0117]
使用三个标准来评估在线哈希方法的准确性性能:召回率(recall@k)、准确率(precision@k)和平均精度均值(map)。召回率是通过真实邻居在整个真实邻居集中的百分比来计算的,而准确率是使用真实邻居在结果集中的百分比来计算的。平均精度均值是基于所有真实邻居的精度的平均值来计算的。
[0118]
在cifar-10数据集上的实验结果:
[0119]
首先,根据表2参数的设置,构建出查询池,并根据损失函数不断更新哈希函数。
[0120]
表1左半部分展示了cifar-10数据集上16位、32位、48位、64位和128位的平均精度均值(map)结果。图2、3、4展示了16位、32位、64位不同在线哈希方法的精确-召回曲线。结果表明,很明显,foh在大部分哈希位上获得了最高的准确度,这揭示了foh在准确度方面是有竞争力的。
[0121]
表3左半部分比较了在32位和48位上哈希表更新时间和检索时间。具体来说,foh在检索时间上减少了6.28秒,这极大地提高了检索速度。我们还将foh的训练时间与表中的其他基线进行了比较。如表4左半部分所示,我们发现foh的训练时间相对较少。
[0122]
在flickr-25k数据集上的实验结果:
[0123]
首先,根据表2参数的设置,构建出查询池以及多标签相似度矩阵,并根据损失函数不断更新哈希函数。
[0124]
表1右半部分展示了flickr-25k数据集上16位、32位、48位、64位和128位的平均精度均值(map)结果。图2展示了16位、32位、64位不同在线哈希方法的精确-召回曲线。结果表明,很明显,foh在所有哈希位上获得了最高的准确度,这揭示了本发明提出的多标签相似度矩阵构造算法是有效的,foh在准确度方面是有竞争力的。
[0125]
表3右半部分比较了在32位和48位上哈希表更新时间和检索时间。具体来说,foh在检索时间上减少了4.42秒,这极大地提高了检索速度。我们还将foh的训练时间与表中的其他基线进行了比较。如表4右半部分所示,我们发现foh的训练时间相对较少。
[0126]
实施例4:
[0127]
做了三个方面的消融实验来研究对准确性的影响:移除查询池的foh-q,构造没有标签投影的损失函数的foh-l,在多标签情况下利用传统相似性矩阵的foh-s。如表5所示,我们可以观察到,foh-l和foh-s都充分有助于性能的改善。与foh-q相比,通过构建查询池,我们发现两者在准确率上几乎没有差别。但是,它可以大大加快查询过程。通过与foh-l的比较,我们证实了标签投射损失对于学习是至关重要的。foh-s显示了与foh的最大性能差
距(在32和48个散列比特上分别有4.4%和5%的改进),这表明通过利用所提出的相似性矩阵构造算法来获得准确性确实是有效的。
[0128]
综上,本发明提出了一种新的快速在线哈希模型用于大规模的在线图像检索,它可以大大加快在线查询的速度。为了实现这一目标,建立了一个查询池来保留潜在的邻居与提出的邻居保留算法和水库采样策略。此外,为了充分利用多标签情况下的监督信息,提出了一种相似度构造算法。最后,综合考虑相似性矩阵和标签投影,构造了一个综合损失函数,使得哈希码更具区分性。实验结果表明,在两个通用数据集上,在线查询时间显著减少,且检索精度相当。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1