一种基于RISC-V的AI计算异构系统
一种基于risc-v的ai计算异构系统
技术领域
1.本发明属于集成电路领域,具体涉及一种基于risc-v的ai计算异构系统。
背景技术:
2.ai(artificial intelligence,人工智能)的提出是为通过机器模拟人脑思考并解决问题。其在近三十年发展迅速,在诸如语音识别、智能机器人等诸多领域受到了极大的关注,并得到了广泛的应用。ai计算作为ai领域的研究核心,通过从自然界获取的灵感,模仿生物智能,解决复杂问题。
3.神经网络作为ai计算的重要研究内容,正逐渐向着更加复杂的拓扑连接和更加多元的网络结构发展,不同类型网络在不同应用的性能差异也在不断增大。因此ai计算需求更强的计算能力和更灵活的计算架构,适应更多的应用场景、执行更复杂的计算。而当今时代基于冯诺依曼的通用计算,由于存储墙、功耗墙瓶颈等问题,难以满足高性能ai计算的需求。而且在ai计算中,往往需要频繁地对大量参数进行访问,数据访存的功耗开销远超计算。因此,降低大规模数据访存的功耗也是ai计算一大难题。
4.为了解决上述问题,人工智能领域迫切需要一个可重构的ai计算系统。一个可重构的ai计算系统,可以兼容不同类型网络,并根据不同网络的特点实现对性能和功耗的权衡。在计算过程中,系统可以通过重构硬件连接来实现更高的硬件资源利用率、提高计算效率。
5.risc-v是基于risc精简指令集的开源指令集架构。由于传统的架构如x86以及arm架构复杂度相对较高,而且开发、使用成本高昂,因此,研发人员提出了一种精简的开源指令集架构risc-v。其相比于x86和arm更为简洁,指令集更加规整简单。基于risc-v的cpu(central processing unit,中央处理器)内核面积少,功耗较低。其支持模块化设计,具有扩展性,同时也支持扩展指令,用户能够根据需求,定制所需要的指令集。此外,由于risc-v的开源特性,任何有能力有想法的人都可以参与其开发,设计、使用成本较低。结合risc-v的异构系统十分灵活,具有可配置性,开发人员几乎可以通过多对指令集的组合或者拓展,设计应用于任何领域的微型处理器的构建。
6.如今人工智能高速发展,ai计算的算力需求指数型增长,不断挑战算力极限。ai计算硬件平台需要更高效的控制架构。而基于risc-v的cpu虽然没有特定的控制ai计算的指令,但它具有极强的可拓展性,因此人们可以基于risc-v的可拓展性,自主设计控制ai计算的特定指令,实现对ai计算的高效控制,提高ai计算效率。
技术实现要素:
7.传统的ai计算系统架构需要大量的并口,数据传输复杂,而且其无法灵活调度计算单元完成高效计算,导致功耗较高。然而,基于risc-v的cpu具有拓展性强、功耗低的特点,其能够与其他处理器结合实现异构系统,灵活配置ai计算网络,重构硬件连接。因此,本发明基于risc-v,根据nice(nuclei instruction co-unit extension,核指令协同单元扩
展)总线协议设计nice核协处理器,与pe(processing elements,处理单元)阵列结合,提出一种异构的ai计算系统架构,用于解决在ai计算中遇到的网络结构多样、频繁访问存储空间、功耗高等问题。
8.本发明提出了一种基于risc-v的ai计算异构系统架构,所述架构包括以下模块:
9.基于risc-v指令集的处理器,定义为risc-v处理器,用于发送自定义扩展指令,并具有多种外设接口;
10.nice核协处理器,用于执行自定义扩展指令,包含指令译码模块、指令执行模块、顶层控制模块;
11.寄存器表,用于暂存risc-v处理器通过自定义扩展指令传输的各类配置参数;
12.第一sram控制器,用于控制第一外部sram;
13.第二sram控制器,用于控制第二外部sram;
14.pe阵列计算模块,用于实现神经网络硬件加速计算,包含仲裁模块和pe计算单元;
15.其中,所述risc-v处理器通过nice总线接口与nice核协处理器连接,risc-v处理器接收上位机基于ai计算内容所生成的配置参数,该配置参数是以自定义扩展指令形式下载到risc-v处理器,risc-v处理器通过nice总线接口将参数传递到nice核协处理器;
16.所述nice核协处理器分别与第一sram控制器、寄存器表、pe阵列计算模块连接,nice核协处理器通过指令译码模块处理接收到的自定义扩展指令,将其转化为相应功能的使能信号,所述指令执行模块用于接收使能信号,并执行指令功能,所述顶层控制模块用于控制pe阵列计算模块的参数调度;所述自定义扩展指令包括写sram、读sram、初始化网络配置、初始化计算配置以及启动网络计算;
17.所述寄存器表分别与pe阵列计算模块和risc-v处理器连接,寄存器表接收并缓存pe阵列的配置参数和输入数据,所述配置参数包括pe阵列网络配置参数、权重、仲裁模块配置参数;寄存器表还接收pe阵列计算模块得到的最终计算结果,并通过risc-v处理器回传到上位机;
18.所述第一sram控制器分别连接第一外部sram和nice核协处理器,第一sram控制器控制第一外部sram进行配置参数的读写;
19.所述第二sram控制器分别连接第二外部sram和pe阵列计算模块,第二sram控制器控制第二外部sram进行计算参数的读写。
20.进一步,所述的一种基于risc-v的ai计算异构系统的数据处理流程包括:
21.步骤1、确定ai计算内容,在上位机使用脚本文件根据数据集生成对应的配置参数,配置参数包含网络配置参数、权重、仲裁模块配置参数、输入激活参数;
22.步骤2、在软件层自定义扩展指令,并将其下载到risc-v,实现代码功能重构;上位机通过串口将配置参数传输到risc-v处理器,risc-v处理器以nice总线为桥梁,将参数传递给nice核协处理器;
23.步骤3、nice核协处理器接收risc-v处理器发送的写sram指令,通过选择器完成指令译码,在指令执行模块执行写sram指令,使用第一sram控制器,将配置参数写入第一外部sram;在ai计算中,需要重复执行写sram指令,直到将全部参数写入外接的第一外部sram;
24.步骤4、nice核协处理器接收来自risc-v处理器的初始化网络配置指令,配置pe计算单元模块;具体为在nice核协处理器中顶层控制模块的控制下,通过第一sram控制器读
array,现场可编程逻辑门阵列)进行交互,pe计算单元通过fpga获得计算输入数据,计算完成的结果同样需要传回fpga。这样的数据传输模式使用了大量的并口,资源开销很大。同时其无法独立完成,始终需要通过fpga不断发送控制信号推动整个计算过程的运行。由于进行ai计算的pe阵列结构不具有可重构性,无法灵活配置,因此它对存储空间无法实现灵活的访问,浪费资源。同时该系统架构缺少能实现多系统间交互协同的模块,因此难以实现系统级的扩展。
42.而本发明的主要实施方式是使用risc-v与自主开发的nice核协处理器结合,使用异构系统控制ai计算,配置参数重构神经网络结构。满足了ai计算对实现多元的网络计算、降低功耗、减少硬件资源浪费的需求。
43.实施例
44.本例在xilinx公司的zynq xc7z035 fpga上实现,以采用脉冲神经网络实现心电信号识别为例,对本发明的实施方法进行详细的描述。
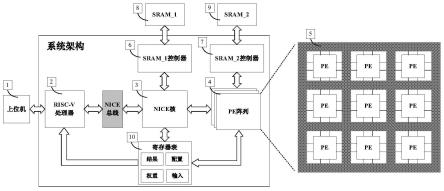
45.本发明提出的一种基于risc-v的ai计算异构系统框架图如图2所示。该系统主要由通过nice总线连接的risc-v和nice核、寄存器表、控制两个外部sram的sram控制器、以及进行ai计算的pe阵列组成。上位机1向risc-v处理器2下载程序。nice核3是配合risc-v处理器2进行指令扩展的协处理器,能够实现对pe阵列4的高效控制。pe阵列由仲裁模块5和多个计算单元pe组成,具有灵活可重构的特点。sram控制器6、7控制外部sram。sram_1外设8负责配置参数存储,sram_2外设9负责计算参数存储。寄存器表10负责缓存配置参数和输入数据。
46.该实施例的起始输入为通过心电传感器采集好的心电信号数据集。由于采集的数据集格式与pe阵列的计算方式不匹配,因此需要将数据在pc通过软件进行预处理,把数据集格式处理为双通道输入数据。心电信号数据集的整个计算流程为:第1通道输入640个数据,在pe阵列中完成640*512*64结构的二层脉冲神经网络计算,得到64个输出数据。第2通道输入16个数据,与第一个脉冲神经网络的输出合并得到80个输入数据,之后在pe阵列中完成80*96*4结构的二层脉冲神经网络进行计算,最终得到4分类心电信号识别输出结果,完成心电信号数据集的推理。
47.由于对不同的数据集进行ai计算需要不同的计算架构,但大部分的神经网络硬件加速器具有固定的结构,无法灵活重构计算单元。因此,本发明采用了具有nice总线的risc-v处理器控制计算单元,自主设计了专用于控制ai计算的nice核协处理器3。nice总线连接risc-v和nice核协处理器,使系统能够根据扩展指令完成对ai计算单元的灵活重构。设计的nice核模块总体结构如图3所示,其中指令译码模块11和指令执行模块12完成对本发明在软件层设计的扩展指令的解析和执行,顶层控制模块13负责调度ai计算的相关参数调度。指令译码模块11由mux选择器构成,接收risc-v处理器2传输的7位instr包数据,其根据instr包内容选择本发明在nice核3预设的指定功能,向指令执行模块12传输指定功能的使能信号。nice协处理器的接口信号主要包含请求req通道和反馈rsp通道。指令执行模块12在请求握手信号req_valid和req_ready以及反馈握手信号rsp_valid和rsp_ready的控制下传输数据,其在指定功能的使能信号的控制下,处理从risc-v处理器2传输的数据。risc-v处理器2首先发出req_valid信号,代表发送指令请求,nice核3的指令执行模块12返回req_ready表示接收指令请求,完成握手后,nice核3接收源操作数rs1和rs2数据。然后
nice核3的指令执行模块12发出rsp_valid信号,代表发送反馈请求,risc-v处理器2返回rsp_ready表示接收反馈请求。最后nice核3在rsp通道信号握手成功时将rdat数据返回risc-v处理器2,从而完成一次扩展指令控制的从risc-v处理器2到nice核3的完整数据传输。
48.本发明需要使用nice核协处理器控制ai计算,而ai计算的数据量大,因此本设计采用512kb*16大小的外部sram进行参数存储,可根据需求进一步扩大。同时由于本发明可重构可配置的特性,需要具有对顶层控制模块以及pe计算阵列灵活控制的能力。因此将参数存储的sram分为网络配置参数部分,计算配置参数部分以及心电信号输入数据部分。根据此实施方案,本发明设计写sram,读sram,初始化网络配置,初始化计算配置以及启动网络计算共5条扩展指令实现对系统的高效控制。nice核扩展指令需要在上位机通过软件根据nice总线协议使用伪指令.insn构建5条扩展指令,并在nice核设计5条指令的指令译码和指令执行模块。伪指令.insn按照r类型指令编码的使用格式如图4(1)所示,其中.insn用于告知编译器指令形式,而r表示指令类型为r型,其他部分对应于图4(2)的32位nice指令编码格式各部分。nice核协处理器指令译码模块是根据risc-v的r类型nice指令格式进行指令译码,本发明设计的nice核扩展指令如图4(2)的32位r类型nice指令格式所示。32位编码由额外的编码空间、源寄存器1、源寄存器2、目的寄存器、控制三个寄存器的使能比特位以及操作码这六部分组成。额外的编码空间func7共有7位,对应risc-v发送的instr包的数据,代表预设的功能序号,最多可扩展128条指令。源寄存器1和源寄存器2是risc-v发送的数据,目的寄存器是返回risc-v的数据。其中x0代表使用的是x0整数寄存器,是为常数0预留的,表示硬件零。“%0”、“%1”等代表指令的操作数,或称为占位符,在内嵌汇编中,变量按照出现顺序与“%0”、“%1”等占位符对应关联。{xd,xs1,xs2}比特位为三个寄存器的使能信号,用于控制是否需要读寄存器rs1、rs2和写目标寄存器rd。如果xs1位的数值为1,则表示该指令需要读取rs1寄存器中的操作数1,rs2同理,如果xd位的数值为1,则表示该指令需要写回结果到xd指定的目标寄存器。操作码opcode段对应使用的是哪个custom预定义指令组空间,共有4组custom预定义指令组,每个预定义指令组都有其自己的操作码,最多可扩展512条指令。如图4所示,本发明扩展指令使用的都是custom-3指令组,操作码0x7b为该指令组指定编码,可通过更改操作码使用其他custom指令组。写sram指令使用了源寄存器1(rs1)和源寄存器2(rs2),因此func3的{xd,xs1,xs2}的值为{011}。其发送instr包的数据为“1”,选择预设的功能1,执行写sram,从源寄存器1(rs1)接收地址,从源寄存器2(rs2)接收数据。通过nice核控制sram控制器向sram指定地址写入数据。读sram指令使用源寄存器1(rs1)和目的寄存器(rd),因此func3的{xd,xs1,xs2}的值为{110}。发送instr包的数据为“2”,选择预设的功能2,执行读sram,从源寄存器1接收地址,通过nice核控制sram控制器读出sram指定地址的数据,从目的寄存器返回读取的结果。而初始化网络配置,初始化计算配置,启动网络计算三条指令功能只使用了源寄存器1(rs1),因此func3的{xd,xs1,xs2}的值为{010}。发送instr包的数据为“3、4、5”,执行预设的功能3、4、5。上述本发明使用的nice核扩展指令接口时序图如图5所示,其中读sram指令仅供调试使用。
49.为实现对参数的灵活配置,本发明通过串口从上位机1将参数传输给risc-v处理器2。risc-v处理器2发送写sram指令,经由nice核3指令译码解析,指令执行接收数据,在sram_1控制器6的控制下,将所有输入参数写入sram_1外设8中。然后risc-v处理器2发送初
始化网络配置指令,控制sram_1控制器6从sram_1外设8中读取网络配置参数,传输到顶层控制13模块,进而配置到寄存器表。接着risc-v处理器2发送初始化计算配置指令,从sram_1外设8中读取权重、仲裁模块配置参数,传输到顶层控制13模块并缓存到寄存器表10。最后risc-v处理器2发送启动网络计算指令,从sram_1外设8中读取输入激活参数,传输到顶层控制13模块并配置到寄存器表10。risc-v处理器2对进行ai计算的pe阵列4发出取参信号,从寄存器表10读取参数。pe阵列按照心电识别网络参数启动,开始心电信号识别计算,最终得到推理结果。心电信号识别中,两个二层脉冲神经网络根据配置使用4个pe单元。在pe单元内,系统按顺序读取输入激活和权重进行神经元的计算。每一个神经元计算完毕,顶层控制模块13会控制sram_2控制器7将当前神经元的计算结果参数写入sram_2外设9。在pe单元间,一层神经网络使用1个pe单元计算完毕后,顶层控制模块13会控制下一层神经网络读取上一层神经网络的计算结果作为输入,使用第二个pe单元进行计算。第1个脉冲神经网络计算完毕后,顶层控制模块13会将输出结果与第二通道数据合并作为输入,传输到第2个脉冲神经网络,继续使用两个pe单元完成两层脉冲神经网络计算。在此期间pe单元根据仲裁参数使用仲裁模块5实现数据交互。得到的心电识别计算结果在顶层控制模块13的控制下存入寄存器表10,并通过risc-v处理器2传输到上位机1。上述关于本发明的数据流向如图6的指令数据流传输示意图所示。其中未提到的读sram操作对本发明仅供调试使用。
50.现阶段芯片的应用场景更加复杂,而大部分芯片在流片之后无法拓展新功能,难以满足需求。而基于risc-v的处理器可解决这个问题,其作为独立完整的cpu,集成了多种外设功能,其可拓展的外设如图7所示。risc-v处理器的硬件部分包含i2c、gpio、pwm、uart等外设,使用外部设备总线模块14对外设进行控制,能灵活选择不同的外设配置,便于实现不同类型的ai计算或添加额外的功能。因此,本发明可在上位机1调用指定函数编写相应的程序,使能指定外设实现多样的功能。除此之外,在加载上位机程序时,可根据需求由上位机1发送选择信号,使用boot选择通过flash或者ram进行代码存储。默认使用的ram模式优点是执行速度快,缺点是掉电程序消失,需要每次上电重复下载。而使用flash模式优的点是可以保存编写的程序,可以脱机运行,可满足应用需求。
51.除此之外,ai计算规模不断增大,未来的系统对可兼容性和大规模数据处理也愈发重视,而使用risc-v处理器能够完成系统级拓展。因此,本发明提出如图8所示的结合risc-v的系统级拓展架构。由于本发明采用risc-v与ai计算结合,因此多个系统可通过risc-v处理器与片外总线15进行交互,通过片外总线15实现互联、协同和扩展,从而实现系统级拓展。每个系统都需要独立的sram执行功能,更多的系统联合能够提升算力,配置大规模的神经网络,进行大规模数据处理,满足不同用户的使用需求。同时多系统能够提升拓展能力,增强整体的灵活性。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1