一种基于GAN网络的图像场景重光照的网络结构及方法
一种基于gan网络的图像场景重光照的网络结构及方法
技术领域
1.本发明主要涉及深度学习领域,尤其涉及一种基于gan网络的图像场景重光照的网络结构及方法。
背景技术:
2.重光照(relighting)
1.指的是在新的光照条件下对原有场景进行合成的过程,该技术最早用于电影特效行业,用于实现场景中人物和物体的高保真的光影细节,后来进一步应用到了电子游戏和虚拟现实领域。图像重光照(image relighting)
2.是重光照的一个子领域,也是目前计算机视觉及图形学领域中一个长期研究的问题,指的是在新的光照条件下对场景外观进行模拟重建,在部分文献
21.中也将其称作图像光源迁移(image light source transfer)。
3.20世界90年代,传统的重光照工作主要使用激光扫描
5.或用户辅助重建算法
[6][7]
来估计场景的几何信息、反射率或环境光等光照信息。2000年,debevec等人
[8]
开创性地使用了光舞台来获取人脸的反射场,他们通过密集地采样从入射角到物体表面后产生的反射图来直接获取反射场的,通过和环境光图的映射和反射场图来合成人脸重光照的图像,该方法在人脸重光照领域获得了巨大成功,之后该团队陆续推出的light stage 2
[9]
、light stage 3
[10]
、light stage 5
[11]
等图像采集设备在很多经典的电影特效合成中得到了应用。在传统的经典图像重光照任务
[4][5][8]
中,场景三维重建是一项非常困难且繁琐的步骤,主要原因有:获取真实世界的几何模型、反射特性和光照环境等光传输信息是非常困难的,并且经常需要昂贵的特制设备来采集,例如光舞台
[8]
;含有复杂几何结构和光学效果的场景的重建会耗费大量的计算资源,运行效率低下。因此,传统的重光照方法
[8][9][10][11]
早期只能应用在电影特效等高投入行业,无法应用于诸如虚拟现实等需要实时光照的领域。
[0004]
近年来,深度学习
[12]
在各种计算机视觉和计算机图像学任务中取得了不错的效果,比如神经渲染
[13]
、神经逆渲染
[14]
、场景重建
[15]
等,将深度学习技术引入图像重光照领域也成为了当前研究的趋势,于是基于深度学习的重光照研究越来越受重视。在该领域,部分重光照研究
[18][19]
希望借助人脸或者建筑的几何先验等特殊信息来实现多视图下的重光照效果,但是其缺点就是严重依赖几何先验,只适合人脸等特殊应用,不具备一般场景的通用性;基于图像到图像的图像重光照技术
[20][21][22]
则希望建立一套端到端的渲染流程,并尽可能地减少对多余场景信息的依赖,通过从已有图像形式的数据中提取特征信息来实现重光照效果,从而达到简化重光照流程的目的。
[0005]
但不论是哪类方法,图像重光照研究都需要大量高清且真实的图像数据集,尤其是通用的一般场景的图像重光照领域,由于现实世界的场景及光照效果非常复杂,故基于真实世界的高质量高清数据集往往制作困难,为了促进相关研究,近年来,现有的研究尝试引入合成的虚拟场景数据集,如vidit
[16]
,该数据集在eccv等顶级会议举办的重光照竞赛中被大量使用,有力推动了场景重光照的发展。
[0006]
现有的基于图像到图像转换的一般场景的图像重光照方法大多使用虚拟场景下
computer vision and pattern recognition.2021:276-283.
技术实现要素:
[0033]
本发明针对当前基于图像到图像的一般场景的图像重光照算法中存在的不足进行改进,提供一种基于gan网络的图像场景重光照的网络结构及方法,本发明采用新的特征编码和解码结构,在深度神经网络中加强光照特征的提取能力和对场景信息变化的关注能力,着重于图像特征的细节学习,使网络能够学习到更加丰富有效的特征。
[0034]
本发明的目的是通过以下技术方案实现的:
[0035]
一种基于gan网络的图像场景重光照的网络结构,包括依次设置的场景重建网络、阴影估计网络和重渲染网络;所述场景重建网络和阴影估计网络采用生成对抗原理,均由生成器和判别器构成,生成器采用编码器-解码器结构;
[0036]
所述场景重建网络由依次设置的一个7*7卷积层、四个上采样块、一个残差块、四个下采样块和一个3*3卷积层组成,四个上采样块的特征信息采用跳跃连接融合在一起,7*7卷积层输出的特征信息和3*3卷积层输出的特征信息采用跳跃连接融合在一起;
[0037]
所述阴影估计网络由依次设置的一个7*7卷积层、四个上采样块、一个残差块、四个下采样块和一个3*3卷积层组成;
[0038]
所述重渲染网络由依次设置的卷积模块、平均池化层、两个全连接层、一个激活层、一个3*3卷积层和一个7*7卷积层组成;所述卷积模块由若干个具有不同卷积核大小的卷积层构成。
[0039]
本发明还提供一种基于gan网络的图像场景重光照的生成方法,包括:
[0040]
对场景重建网络输入一张给定光照条件下的图像,通过场景重建网络去除输入图像原本的光照效果,并从输入图像中提取场景固有信息,输出包含场景固有信息的场景重建图像;
[0041]
对阴影估计网络输入一张给定光照条件下的图像,输出包含了目标光照信息的阴影估计图像;
[0042]
对重渲染网络输入场景重建图像与阴影估计图像的拼接结果,输出目标光照条件下的重光照图像;
[0043]
训练场景重建网络和阴影估计网络的过程中,判别器不断对生成器进行微调,使场景重建图像和阴影估计图像不断接近对应的目标图像。
[0044]
进一步的,重渲染网络首先将输入图像输入到3*3卷积层、5*5卷积层、7*7卷积层、
…
、25*25卷积层共12个卷积层中,再将12个卷积层输出的特征信息拼接在一起,接下来经过平均池化操作、两个全连接层、一个sigmoid函数、1*1卷积层、7*7卷积层。
[0045]
进一步的,对场景重建网络、阴影估计网络和重渲染网络分别进行训练,首先,通过损失函数及成对的输入图像和无阴影目标图像训练场景重建网络;其次,使用成对的输入图像和目标图像训练阴影估计网络;最后,使用损失函数训练重渲染器网络。
[0046]
训练场景重建网络和阴影估计网络的过程中,判别器不断对生成器进行微调,使场景重建图像和阴影估计图像不断接近对应的目标图像。
[0047]
进一步的,训练中,所有图像的大小被从1024
×
1024调整为512
×
512,并且mini-batch大小设置为6,网络参数调整使用adam优化器,动量设为0.5,学习率设为0.0001,每个
网络训练20个回合。
[0048]
一种电子设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述程序时实现基于gan网络的图像场景重光照的生成方法的步骤。
[0049]
一种计算机可读存储介质,其上存储有计算机程序,该计算机程序被处理器执行时实现所述基于gan网络的图像场景重光照的生成方法的步骤。
[0050]
与现有技术相比,本发明的技术方案所带来的有益效果是:
[0051]
(1)为了提高场景特征和阴影特征的提取能力,降低图像重光照的难度,本发明设计了一种基于retinex理论的图像重光照网络结构。该网络结构包括场景重建网络、阴影估计网络和重渲染网络。本发明方法使用场景重建网络提取场景信息,使用阴影估计网络将光照效果从输入图像x迁移到目标图像y,这显著降低了重新绘制阴影的难度。最后使用一个重渲染网络来结合场景信息和光照效果。
[0052]
(2)gan网络训练过程遵循对抗学习策略,训练过程中学习和使用目标图像内的潜在分布。训练结束将达到动态平衡,其中生成器生成的图像具有与目标图像相似的潜在感知结构。为了生成更接近真实图像的重光照图像,使重光照图像更具有真实感,本发明的场景重建网络和阴影估计网络都是基于gan网络,训练也采用对抗学习的方式。
[0053]
(3)为了充分利用特征的空间信息,以更好地重建场景和阴影,并尽可能多地保留纹理细节,本发明设计一种新颖的上下采样块。该上下采样块能够充分利用特征信息,在场景重建网络和阴影估计网络中使用。
[0054]
(4)本发明在vidit数据集上用实验验证了本发明方法的有效性。在定量分析下,评价指标采用领域内公认的pnsr、ssim、lpips和mps,与该领域(基于图像到图像转换的一般场景下图像重光照)已有的方法retinex-net、drn、mcn、s3net相比,本发明方法除了在pnsr上略低于s3net,在其他指标上都表现出了有竞争力的、显著的效果,证明了本发明方法的有效性。
附图说明
[0055]
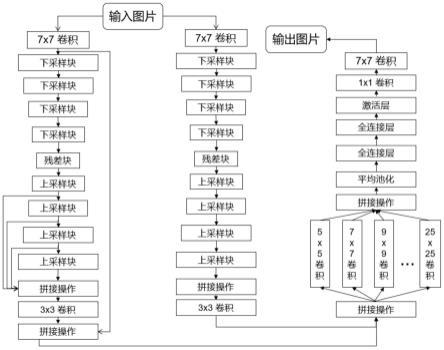
图1为本发明方法的整体网络结构示意图。
[0056]
图2a和图2b分别为场景重建网络使用的上、下采样块结构示意图。
[0057]
图3a和图3b分别为阴影估计网络使用的上、下采样块结构示意图。
[0058]
表1为本发明方法和其他方法的定量对比结果
具体实施方式
[0059]
以下结合附图和具体实施例对本发明作进一步详细说明。应当理解,此处所描述的具体实施例仅用以解释本发明,并不用于限定本发明。
[0060]
本实施例提供一种基于图像到图像的一般场景下图像重光照任务的网络结构,该网络结构包括场景重建网络、阴影估计网络和重渲染网络。如图1所示,从左到右分别是场景重建网络、阴影估计网络和重渲染网络。其中场景重建网络和阴影估计网络采用生成对抗原理,分为生成器和判别器,生成器部分采用编码器-解码器结构。在训练场景重建网络和阴影估计网络的过程中,判别器不断对生成器进行微调,使场景重建网络生成器输出的
场景重建图像和阴影估计网络生成器输出的阴影估计图像不断接近对应的目标图像。
[0061]
场景重建网络的网络结构由一个7*7卷积层、四个上采样块、一个残差块、四个下采样块和一个3*3卷积层组成。场景重建网络还采用跳跃连接,将第一个、第二个、第三个和第四个上采样块的特征信息融合在一起,将7*7卷积层输出的特征信息和3*3卷积层输出的特征信息融合在一起。
[0062]
阴影估计网络的网络结构由一个7*7卷积层、四个上采样块、一个残差块、四个下采样块和一个3*3卷积层组成。阴影估计网络的网络和场景重建网络类似,区别在于阴影估计网络去掉了跳跃连接,去掉跳跃连接有助于阴影估计网络关注全局光效应。
[0063]
重渲染网络把输入图像分别输入到3*3卷积层、5*5卷积层、7*7卷积层、
…
、25*25卷积层共12个卷积层中,再将12个卷积层输出的特征信息拼接在一起,接下来经过平均池化操作、两个全连接层、一个sigmoid函数、1*1卷积层、7*7卷积层。
[0064]
具体的,基于上述网络结构的重光照的生成方法包括:
[0065]
(1)场景重建网络的输入是一张给定光照条件下的图像,输出是包含场景固有信息的场景重建图像。场景重建网络的目的是去除输入图像原本的光照效果,并从输入图像中提取场景固有信息。
[0066]
(2)阴影估计网络的输入是一张给定光照条件下的图像,输出是包含了目标光照信息的阴影估计图像。阴影估计网络的目的是得到目标光照条件下的光照效果信息。
[0067]
(3)重渲染网络的输入是场景重建网络输出的场景重建图像和阴影估计网络输出的阴影估计图像拼接的结果,输出是目标光照条件下的重光照图像。重渲染网络的目的是得到目标光照条件下的重光照图像。
[0068]
在整个渲染流程中,下采样块和上采样块的设计极其重要,它们决定了对重要特征信息的提取能力。本实施例中场景重建网络的上、下采样块使用如图2a和图2b所示的处理流程,阴影估计网络的上下采样块使用如图3a和图3b所示的处理流程。以场景重建网络的下采样块为例,场景重建网络的下采样块首先将输入特征输入第一个步长为2的3
×
3卷积层,将输入特征映射到小尺度空间,得到一个小尺度特征f
small
;然后将小尺度特征f
small
输入步长为2的4
×
4反卷积层并映射回输入尺度空间,得到特征f
normal
。同时,另一个分支将输入特征通过一个1
×
1卷积层和leakyrelu函数生成校准权重λ1,该权重校准λ1和f
normal
做乘积运算,并获得具有输入尺度空间大小的校准特征通过第二个步长为2的3
×
3卷积层重新映射到小尺度空间,得到特征特征f
small
通过包含一个密集残差块的分支得到校准权重λ2。特征和校准权重λ2经过一个求和操作,得到输入特征尺寸大小一半的输出特征f
out
。根据上述过程,下采样块的公式可以表示为:
[0069][0070]
其中和表示2个不同的3
×
3的卷积层,decon4表示一个4
×
4的反卷积层,λ1,λ2分别为校准权重,场景重建网络上下采样块中的λ1,λ2可以定义如下
[0071]
λ1=leakyrelu(con1(f))
[0072]
[0073]
其中con1表示一个1
×
1的卷积层,dr_block表示新设计的密集残差块。
[0074]
与上述过程类似,场景重建网络的下采样块的公式可以表示为:
[0075][0076]
具体的,本实施例涉及基于图像到图像的一般场景下图像重光照任务,具体来讲是将任意光照条件下的场景重新渲染为某个统一光照条件下的场景,简称anytoone任务。
[0077]
假设输入图像是表示处于光照条件φ下的图像,重光照任务则是要渲染出在给定目标光照条件ψ下的图像,根据retinex理论,输入图像可以描述为:
[0078]
x=l
φ
(s)
[0079]
其中s表示在不同光照条件下图像的固有场景信息,l
φ
(
·
)是一个定义的光照函数,该光照负责提供在光照条件φ下的全局光照和阴影效果。图像重光照任务则可以进一步被描述为:
[0080]
y=l
ψ
(l
φ-1
(x))
[0081]
该重光照任务整体可以分为以下两步操作:
[0082]
(1)场景重建操作:l
φ-1
(
·
)。该步是从输入图像x中恢复场景结构信息s,目标是去除原有光照效果φ,该步骤的关键是去除阴影。
[0083]
(2)重光照操作:l
ψ
(
·
)。该步是用目标光源重新为场景结构信息s进行光照操作,从而得到输出图像y,目标是添加新的光照效果ψ,该步骤的关键是增加阴影。
[0084]
由于单图像重光照没有额外的几何信息输入,所以重光照操作的难度更大。本发明方法不是直接找到某个重光照操作l
ψ
(
·
),而是寻找一个将光照效果从输入图像x迁移到目标图像y的转移操作l
φ
→
ψ
(x),这显著降低了重新绘制阴影的难度,最后使用一个重渲染过程r(
·
)来结合场景信息和光照效果。整个过程可以表示为:
[0085]y′
=r(l
φ-1
(x),l
φ
→
ψ
(x))
[0086]
由于从输入图像中提取的场景信息s本身就难以定义,只能使用人工观察到的图像来作为模型训练的标签,本实施例采用了drn
[20]
建议的曝光融合图像作为场景重建网络的真实图像,这种曝光融合图像可能包含一些不属于场景信息s的冗余信息,所以严格来讲,本实施例的场景重建网络属于半监督学习,而非完全监督学习。
[0087]
场景重建网络和阴影估计网络都是基于gan网络,所以其训练也采用对抗学习的方式。场景重建网络在训练过程中,其判别器用来区分场景重建网络生成器输出的场景重建图像和对应的曝光融合图像,其损失函数定义为:
[0088][0089]
其中y
no-shadow
表示曝光融合图像,x表示场景重建网络的输入图像,g表示场景重建网络的生成器,d表示场景重建网络的判别器。
[0090]
阴影估计网络使用阴影区域判别器来区分阴影估计网络生成器输出的阴影估计图像和对应的真实图像,其损失函数定义为:
[0091][0092]
其中x表示阴影估计网络的输入图像,y表示阴影估计网络的目标图像,g表示阴影估计网络的生成器,d表示阴影估计网络的判别器,d
′
表示阴影估计网络的阴影区域判别器,。
[0093]
重渲染网络的损失函数定义为:
[0094][0095]
其中λ在本实施例的所有训练中都设置为0.01,y表示重渲染网络的目标图像,y
′
表示重渲染网络的预测图像,feat(
·
)表示经过vgg网络后得到的特征图。
[0096]
本实施例的网络训练使用vidit数据集,该数据集包含390个不同的虚拟场景,其中有300个用于训练的场景、45个用于验证的场景和45个用于测试的场景,每个场景用8个光方向和5个色温进行渲染,从而产生分辨率为1024
×
1024的40张图像。vidit数据集最开始用于重光照挑战赛,且测试集不对外公开,所以本发明无法使用其中的45个验证场景和45个测试场景。为此,本发明使用300个训练场景的280个场景用于训练,20个场景用于测试。
[0097]
受gpu内存和计算能力的限制,本实施例对三个子网络(场景重建网络、阴影估计网络和重渲染网络)进行分别训练。首先,通过设计的损失函数使用成对的输入图像和无阴影目标图像来训练场景重建网络。接着,使用成对的输入图像和目标图像来训练阴影估计网络。最后,在固定场景重建网络和阴影估计网络并移除了它们的最后一个卷积层和鉴别器的情况下,使用设计的损失函数训练重渲染器网络。在训练时,所有图像的大小被从1024
×
1024调整为512
×
512,并且mini-batch大小设置为6,网络参数调整使用adam优化器,其动量设为0.5,学习率设为0.0001,其中每个网络训练20个回合。所有实验都是使用深度学习训练框架pytorch并在装有3个nvidia gtx3090ti gpu的机器上进行。
[0098]
在定量分析下,评价指标采用领域内公认的pnsr、ssim、lpips和mps,与该领域已有的方法retinex-net、drn、mcn、s3net相比,本发明方法除了在pnsr上略低于s3net,其他指标上都表现出了显著的效果,详情参见表1。
[0099]
表1.本发明方法和其他方法的定量对比结果
[0100][0101]
优选地,本技术的实施例还提供能够实现上述实施例中的基于gan网络的图像场景重光照的生成方法中全部步骤的一种电子设备的具体实施方式,电子设备具体包括如下内容:
[0102]
处理器(processor)、存储器(memory)、通信接口(communications interface)和总线;
[0103]
其中,处理器、存储器、通信接口通过总线完成相互间的通信;通信接口用于实现服务器端设备、计量设备以及用户端设备等相关设备之间的信息传输。
[0104]
处理器用于调用存储器中的计算机程序,处理器执行计算机程序时实现上述实施例中的基于gan网络的图像场景重光照的生成方法中的全部步骤。
[0105]
本技术的实施例还提供能够实现上述实施例中的基于gan网络的图像场景重光照
的生成方法中全部步骤的一种计算机可读存储介质,计算机可读存储介质上存储有计算机程序,该计算机程序被处理器执行时实现上述实施例中的基于gan网络的图像场景重光照的生成方法的全部步骤。
[0106]
本说明书中的各个实施例均采用递进的方式描述,各个实施例之间相同相似的部分互相参见即可,每个实施例重点说明的都是与其他实施例的不同之处。尤其,对于硬件+程序类实施例而言,由于其基本相似于方法实施例,所以描述的比较简单,相关之处参见方法实施例的部分说明即可。
[0107]
上述对本说明书特定实施例进行了描述。其它实施例在所附权利要求书的范围内。在一些情况下,在权利要求书中记载的动作或步骤可以按照不同于实施例中的顺序来执行并且仍然可以实现期望的结果。另外,在附图中描绘的过程不一定要求示出的特定顺序或者连续顺序才能实现期望的结果。在某些实施方式中,多任务处理和并行处理也是可以的或者可能是有利的。
[0108]
虽然本技术提供了如实施例或流程图的方法操作步骤,但基于常规或者无创造性的劳动可以包括更多或者更少的操作步骤。实施例中列举的步骤顺序仅仅为众多步骤执行顺序中的一种方式,不代表唯一的执行顺序。在实际中的装置或客户端产品执行时,可以按照实施例或者附图所示的方法顺序执行或者并行执行(例如并行处理器或者多线程处理的环境)。
[0109]
本领域内的技术人员应明白,本发明的实施例可提供为方法、系统、或计算机程序产品。因此,本发明可采用完全硬件实施例、完全软件实施例、或结合软件和硬件方面的实施例的形式。而且,本发明可采用在一个或多个其中包含有计算机可用程序代码的计算机可用存储介质(包括但不限于磁盘存储器、cd-rom、光学存储器等)上实施的计算机程序产品的形式。
[0110]
这些计算机程序指令也可存储在能引导计算机或其他可编程数据处理设备以特定方式工作的计算机可读存储器中,使得存储在该计算机可读存储器中的指令产生包括指令装置的制造品,该指令装置实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能。
[0111]
这些计算机程序指令也可装载到计算机或其他可编程数据处理设备上,使得在计算机或其他可编程设备上执行一系列操作步骤以产生计算机实现的处理,从而在计算机或其他可编程设备上执行的指令提供用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的步骤。
[0112]
本发明并不限于上文描述的实施方式。以上对具体实施方式的描述旨在描述和说明本发明的技术方案,上述的具体实施方式仅仅是示意性的,并不是限制性的。在不脱离本发明宗旨和权利要求所保护的范围情况下,本领域的普通技术人员在本发明的启示下还可做出很多形式的具体变换,这些均属于本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1