白内障眼底图像的修复方法、修复模型的训练方法及装置
1.本公开大体涉及人工智能图像处理领域,具体涉及一种白内障眼底图像的修复方法、修复模型的训练方法及装置。
背景技术:
2.白内障是一种容易致盲的眼病,是导致老年人视力障碍较常见的因素。由于白内障患者的晶状体的浑浊,导致光散射严重从而大大降低了其眼底图像的质量,不利于观察眼底图像中的特征。
3.因此,对白内障眼底图像进行修复十分必要。经修复的白内障眼底图像能够提高眼底图像的质量,从而提高白内障眼底图像的可读性和评估性,有助于临床医生对眼底图像中的异常特征进行观察和判断,对辅助白内障的评估具有重要的临床作用。
4.目前,专利文献1(cn113362258a)提供了一种白内障患者眼底彩照图像去噪方法,该去噪方法构建第一判别器并分别将模拟噪声眼底图像与清晰眼底图像及模拟去噪图像的组合输入得第一判别器的损失,根据该损失对生成器优化;用优化后的生成器对真实噪声眼底图像去噪得真实去噪图像;构建第二判别器并将真实去噪图像和模拟去噪图像输入得第二判别器的损失,根据该损失对生成器优化;根据再次优化后的生成器对真实噪声眼底图像去噪得到最终去噪结果,进而实现了对白内障患者眼底图像的去噪。然而,上述专利文献1直接利用模拟噪声眼底图像、清晰眼底图像和模拟去噪图像对生成器的生成效果进行评估,对去噪结果中细节的处理还有待于提高。
技术实现要素:
5.本公开是有鉴于上述的状况而提出的,其目的在于提供一种能够提高修复图像的细节的白内障眼底图像的修复方法、修复模型的训练方法及装置,从而实现对白内障眼底图像的修复。
6.为此,本公开第一方面提供一种白内障眼底图像的修复模型的训练方法,所述修复模型包括生成器和判别器,所述训练方法包括:构建训练数据集,所述训练数据集包括清晰眼底图像以及与所述清晰眼底图像对应的参考白内障图像;利用所述生成器将所述训练数据集中的所述参考白内障图像作为输入以通过多次下采样获取不同尺度的第一特征图,并将所述不同尺度的第一特征图与相应的经上采样获取的第二特征图进行融合,进而生成修复图像;利用所述判别器将所述参考白内障图像和对应的清晰眼底图像作为输入以输出针对所述清晰眼底图像的第一判别结果,并将所述参考白内障图像和对应的修复图像作为输入以输出针对所述修复图像的第二判别结果;并且基于所述训练数据集、所述第一判别结果和所述第二判别结果获取目标损失,并基于所述目标损失对所述修复模型进行训练以优化所述修复模型,进而获得用于修复白内障眼底图像的训练后的所述生成器;其中,所述目标损失包括第一损失、第二损失、第三损失和第四损失,所述第一损失由所述第一判别结果和所述第二判别结果确定,所述第二损失由所述修复图像与对应的清晰眼底图像之间像
素的差异所确定,所述第三损失由基于卷积神经网络的特征提取器提取的所述修复图像与对应的清晰眼底图像之间的不同尺度的特征图的差异所确定,所述第四损失由所述修复图像与对应的清晰眼底图像之间的结构相似性所确定。
7.在本公开的第一方面中,构建具有成对关系的训练数据集来训练包括生成器和判别器的修复模型,在训练中,将来自下采样的不同尺度的特征细节传递到对应尺度的上采样中以利用更多特征细节来还原修复图像的细节,使得修复图像更接近清晰眼底图像。另外,还能够使修复模型生成的修复图像从多个方面尽量接近清晰眼底图像,有利于提高修复效果。另外,还能够有利于提取一些感兴趣的图像信息。另外,还能够对修复图像和清晰眼底图像之间的结构进行约束。
8.另外,在本公开第一方面所涉及的训练方法中,可选地,所述目标损失还包括第五损失,所述第五损失由所述修复图像的局部区域与全局区域之间的光照强度的差异所确定。在这种情况下,能够平衡修复图像的局部区域与全局区域之间的光照强度的差异,进而能够改善修复图像过暗的问题。
9.另外,在本公开第一方面所涉及的训练方法中,可选地,获取所述第五损失包括:计算所述修复图像的全局区域的平均光照强度而获得全局平均强度;将所述修复图像分为多个图像块,通过计算每个图像块的平均光照强度而获得光照矩阵;基于所述光照矩阵与所述全局平均强度之间的差值获得光照差异性矩阵;调整所述光照差异性矩阵以获得与所述修复图像的大小相匹配的光照分布矩阵;并且求所述光照分布矩阵的平均绝对值而获得所述第五损失。在这种情况下,能够确定修复图像的局部区域与全局区域之间的光照强度的差异,进而确定第五损失。
10.另外,在本公开第一方面所涉及的训练方法中,可选地,所述参考白内障图像由对应的清晰眼底图像进行光线干扰和模糊处理而获得,其中,所述光线干扰包括对比度干扰、亮度干扰和饱和度干扰中的至少一种,所述模糊处理包括高斯模糊和随机高斯噪声中的至少一种。在这种情况下,光线干扰能够模拟白内障晶状体的浑浊,模糊处理能够模拟白内障的成像模糊。由此,能够获得与真实白内障眼底图像较接近的参考白内障图像。
11.另外,在本公开第一方面所涉及的训练方法中,可选地,在所述目标损失中,所述第一损失具有第一权重,所述第二损失具有第二权重,所述第三损失具有第三权重,所述第四损失具有第四权重;其中,所述第三权重大于所述第二权重,所述第二权重等于所述第四权重。在这种情况下,通过设置权重的大小,能够提高第三损失对修复模型的影响,并平衡第二损失和第四损失对修复模型的影响,从而在提高判别器的判别结果影响的基础上,更有利于感兴趣的图像信息的提取。
12.另外,在本公开第一方面所涉及的训练方法中,可选地,所述特征提取器具有依次连接的多个卷积层,所述第三损失满足公式:其中,l
per
(g)表示所述第三损失,g表示所述生成器,c表示所述清晰眼底图像,c'表示所述参考白内障图像,g(c')表示所述修复图像,φi表示所述特征提取器的第i层卷积层,φi(c)表示第i层卷积层输出的针对所述清晰眼底图像的特征图,φi(g(c'))表示第i层卷积层输出的针对所述修复图像的特征图,mi表示所述特征提取器的第i层特征图的像素点的个数,||||1表示l1范数,n表示所述特征提取器的卷积层的层数。在这种情况下,基于不同卷积层输
出的针对修复图像的特征图和针对清晰眼底图像的特征图之间的差异确定第三损失,能够使第三损失更精准,进而在训练修复模型时有利于提取一些感兴趣的图像信息。
13.另外,在本公开第一方面所涉及的训练方法中,可选地,基于滑窗获取所述第四损失,所述第四损失满足公式:其中,l
str
(g)表示所述第四损失,g表示所述生成器,k表示滑窗的个数,表示所述修复图像中第i个滑窗中像素值的标准差,表示所述清晰眼底图像中第i个滑窗中像素值的标准差,表示所述修复图像与所述清晰眼底图像之间针对第i个滑窗的协方差,m表示常数,e[]表示数学期望。由此,能够基于修复图像与对应的清晰眼底图像之间的结构相似性获取第四损失。
[0014]
另外,在本公开第一方面所涉及的训练方法中,可选地,所述生成器包括具有多个下采样层的编码模块和具有多个上采样层的解码模块,所述编码模块用于对输入生成器的参考白内障图像进行所述多次下采样以获取所述不同尺度的第一特征图,所述解码模块中各个上采样层的输入包括经由尺度归一化的所述不同尺度的第一特征图、以及对应解码模块中前一个上采样层输出的所述第二特征图。由此,能够更加全面地融合特征图。
[0015]
另外,在本公开第一方面所涉及的训练方法中,可选地,所述判别器用于接收所述参考白内障图像和待判别图像并生成判别矩阵,基于所述判别矩阵获取针对所述待判别图像的判别结果,其中,所述判别矩阵中各个元素表示所述待判别图像的对应区域的区域判别结果。在这种情况下,能够对待判别图像的局部细节进行判断,使获得的判别结果更客观。
[0016]
本公开第二方面提供一种白内障眼底图像的修复模型的训练装置,其特征在于,所述修复模型包括生成器和判别器,所述训练装置包括:构建模块,其用于构建训练数据集,所述训练数据集包括清晰眼底图像以及与所述清晰眼底图像对应的参考白内障图像;生成模块,其利用所述生成器将所述训练数据集中的所述参考白内障图像作为输入以通过多次下采样获取不同尺度的第一特征图,并将所述不同尺度的第一特征图与相应的经上采样获取的第二特征图进行融合,进而生成修复图像;判别模块,其利用所述判别器将所述参考白内障图像和对应的清晰眼底图像作为输入以输出针对所述清晰眼底图像的第一判别结果,并将所述参考白内障图像和对应的修复图像作为输入以输出针对所述修复图像的第二判别结果;以及优化模块,其基于所述训练数据集、所述第一判别结果和所述第二判别结果获取目标损失,并基于所述目标损失对所述修复模型进行训练以优化所述修复模型,进而获得用于修复白内障眼底图像的训练后的所述生成器;其中,所述目标损失包括第一损失、第二损失、第三损失和第四损失,所述第一损失由所述第一判别结果和所述第二判别结果确定,所述第二损失由所述修复图像与对应的清晰眼底图像之间像素的差异所确定,所述第三损失由基于卷积神经网络的特征提取器提取的所述修复图像与对应的清晰眼底图像之间的不同尺度的特征图的差异所确定,所述第四损失由所述修复图像与对应的清晰眼底图像之间的结构相似性所确定。
[0017]
在本公开的第二方面中,构建具有成对关系的训练数据集来训练包括生成器和判别器的修复模型,在训练中,将来自下采样的不同尺度的特征细节传递到对应尺度的上采
样中以利用更多特征细节来还原修复图像的细节,使得修复图像更接近清晰眼底图像。另外,还能够使修复模型生成的修复图像从多个方面尽量接近清晰眼底图像,有利于提高修复效果。另外,还能够有利于提取一些感兴趣的图像信息。另外,还能够对修复图像和清晰眼底图像之间的结构进行约束。
[0018]
本公开第三方面提供一种白内障眼底图像的修复方法,利用本公开第一方面所涉及的训练方法获得的修复模型对白内障眼底图像进行修复。在这种情况下,基于修复模型获得针对白内障眼底图像的修复图像,能够提高修复图像的细节。
[0019]
根据本公开,能够提供一种能够提高修复图像的细节的白内障眼底图像的修复方法、修复模型的训练方法及装置。
附图说明
[0020]
现在将仅通过参考附图的例子进一步详细地解释本公开,其中:
[0021]
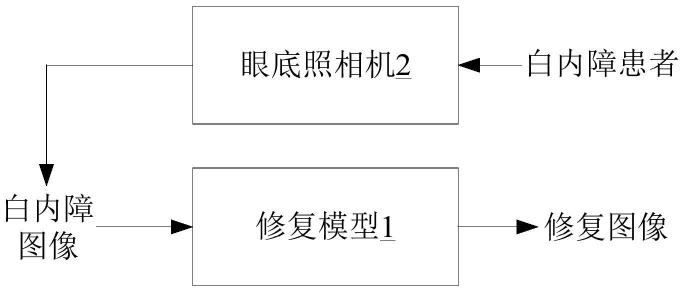
图1是示出了本公开示例所涉及的修复模型的应用场景的示意图。
[0022]
图2是示出了本公开示例所涉及的训练方法的流程图。
[0023]
图3a是示出了本公开示例所涉及的修复模型的框图。
[0024]
图3b是示出了本公开示例所涉及的判别器的工作示意图。
[0025]
图4是示出了本公开示例所涉及的获取第五损失的流程图。
[0026]
图5是示出了本公开示例所涉及的生成参考白内障图像的流程图。
[0027]
图6是示出了本公开示例所涉及的获取第三损失的流程图。
[0028]
图7是示出了本公开示例所涉及的基于u-net的生成器的框图。
[0029]
图8是示出了本公开示例所涉及的训练装置的框图。
[0030]
图9a是示出了本公开示例所涉及的白内障眼底图像。
[0031]
图9b是示出了本公开示例所涉及的手术后的白内障眼底图像。
[0032]
图9c是示出了本公开示例所涉及的修复后的白内障眼底图像。
具体实施方式
[0033]
以下,参考附图,详细地说明本公开的优选实施方式。在下面的说明中,对于相同的部件赋予相同的符号,省略重复的说明。另外,附图只是示意性的图,部件相互之间的尺寸的比例或者部件的形状等可以与实际的不同。需要说明的是,本公开中的术语“包括”和“具有”以及它们的任何变形,例如所包括或所具有的一系列步骤或单元的过程、方法、系统、产品或设备不必限于清楚地列出的那些步骤或单元,而是可以包括或具有没有清楚地列出的或对于这些过程、方法、产品或设备固有的其它步骤或单元。本公开所描述的所有方法可以以任何合适的顺序执行,除非在此另有指示或者与上下文明显矛盾。
[0034]
本公开示例涉及的白内障眼底图像的修复方法、修复模型的训练方法及装置能够提高修复图像的细节。另外,基于细节较好的修复图像能够提高白内障眼底图像的可读性和评估性,有助于临床医生对眼底图像中的异常特征进行观察和判断。本公开示例涉及的训练方法也可以称为模型训练方法。本公开示例涉及的训练装置也可以称为模型训练装置。
[0035]
本公开示例涉及的眼底图像可以利用眼底照相机对受试者的眼底进行拍照而获
得。
[0036]
在一些示例中,清晰眼底图像可以为未患有白内障的受试者的眼底图像。在训练中,清晰眼底图像可以作为标签图像(也即金标准)来优化修复模型。在一些示例中,参考白内障图像可以为与清晰眼底图像对应的具有白内障特点的眼底图像。
[0037]
在一些示例中,参考白内障图像可以为基于清晰眼底图像模拟而获得的图像。具体地,参考白内障图像可以为根据白内障图像的特点对清晰眼底图像进行处理(例如,光线干扰和模糊处理)而获得的图像。在另一些示例中,参考白内障图像也可以是清晰眼底图像的受试者患有白内障之后的眼底图像。例如,可以预先确定多个未患有白内障的受试者并采集清晰眼底图像,然后对受试者进行持续随访,直至该受试者患上白内障后,再采集该受试者的眼底图像作为参考白内障图像。
[0038]
在一些示例中,白内障眼底图像(也可以称为白内障图像)可以为白内障患者的眼底图像。在一些示例中,由于白内障患者的晶状体的浑浊,导致光散射严重,从而严重降低白内障图像的图像质量。例如,白内障图像具有模糊、浑浊和光照过暗等特点。在这种情况下,容易覆盖眼底图像中的一些血管信息或病变特征,从而降低白内障图像的可读性和评估性。
[0039]
本公开示例涉及的修复模型可以基于生成对抗网络。具体地,修复模型可以包括生成器和判别器。在一些示例中,修复模型可以基于条件生成对抗网络。在这种情况下,通过条件生成对抗网络能够对生成器输出的修复图像进行约束,从而能够降低修复图像偏离清晰眼底图像的风险。
[0040]
以下结合附图进行详细描述本公开。此外,本公开的示例描述的应用场景是为了更加清楚地说明本公开的技术方案,并不构成对于本公开提供的技术方案的限定。图1是示出了本公开示例所涉及的修复模型的应用场景的示意图。基于本公开涉及的训练方法获得的训练后的修复模型1可以应用于如图1所示的场景中。
[0041]
在一些示例中,参见图1,可以利用眼底照相机2对白内障患者的眼底进行拍照,从而获得白内障图像。在一些示例中,可以将白内障图像输入修复模型1,修复模型1可以对白内障图像进行修复以输出修复图像(即修复后的白内障图像)。在这种情况下,修复后的白内障图像能够显示被覆盖的图像信息(例如,血管信息或病变特征),从而能够提高眼底图像的可读性和评估性。
[0042]
图2是示出了本公开示例所涉及的训练方法的流程图。
[0043]
在一些示例中,参见图2,训练方法可以包括构建训练数据集(步骤s100)、利用修复模型1基于训练数据集获取第一判别结果和第二判别结果(步骤s120)、基于训练数据集、第一判别结果和第二判别结果获取目标损失(步骤s140)、以及基于目标损失对修复模型1进行训练以获得训练后的修复模型1(步骤s160)。
[0044]
本公开涉及的修复模型1可以包括生成器12和判别器14(稍后描述)。
[0045]
在一些示例中,在步骤s100中,可以构建训练数据集。在一些示例中,训练数据集可以包括具有成对对应关系的数据。例如,训练数据集包括清晰眼底图像以及与清晰眼底图像对应的参考白内障图像。在一些示例中,训练数据集可以包括基于多个受试者获取的多组具有成对对应关系的数据。
[0046]
在一些示例中,训练数据集可以分为训练集和验证集,训练集可以用于对修复模
型1进行训练,验证集可以用于对训练后的修复模型1进行验证。
[0047]
图3a是示出了本公开示例所涉及的修复模型1的框图。图3b是示出了本公开示例所涉及的判别器14的工作示意图。
[0048]
在一些示例中,在步骤s120中,可以利用修复模型1基于训练数据集获取第一判别结果和第二判别结果。
[0049]
如上所述,修复模型1可以包括生成器12和判别器14。作为示例,图3a示出了一种示例性的修复模型1的示意图。具体地,参见图3a,生成器12可以接收参考白内障图像并生成修复图像(也即,修复图像可以通过将参考白内障图像作为生成器12的输入而生成),判别器14可以接收参考白内障图像和待判别图像并生成判别结果。
[0050]
在一些示例中,判别器14可以先获得判别矩阵,再基于判别矩阵生成判别结果。具体地,判别器14可以接收参考白内障图像和待判别图像并生成判别矩阵,基于判别矩阵获取针对待判别图像的判别结果。在一些示例中,判别矩阵中各个元素可以表示待判别图像的对应区域的区域判别结果。区域判别结果可以包括表示对应区域的图像块的真或假。
[0051]
在一些示例中,判别器14接收参考白内障图像和待判别图像之后,可以经多层卷积运算后生成一个判别矩阵。在一些示例中,可以对判别矩阵的所有元素值求平均而获得平均值并作为判别结果。换言之,判别器14最终可以输出一个一维的数据(也即一个数值),该数值可以用于判别待判别图像的真假。在这种情况下,通过判别矩阵能够反映待判别图像中每一块区域的区域判别结果,从而判别器14能够更加客观全面地对待判别图像进行判别。
[0052]
在一些示例中,判别器14可以采用patchgan的网络结构。例如,判别器14可以由5层卷积层组成,最后一层应用激活函数(例如,sigmoid函数)映射到一维度输出,该输出可以用于判断待判别图像的真假。
[0053]
另外,判别结果可以表示待判别图像的真或假。在一些示例中,判别结果可以是待判别图像接近清晰眼底图像的置信度。在一些示例中,判别结果可以是待判别图像接近清晰眼底图像的概率。概率的取值范围可以为[0,1]。例如,若判别结果为0.3,可以表示判别器14判断待判别图像接近清晰眼底图像的概率为30%。
[0054]
在一些示例中,待判别图像可以是与参考白内障图像对应的清晰眼底图像或与参考白内障图像对应的修复图像。具体地,基于与参考白内障图像对应的清晰眼底图像可以确定第一判别结果,基于与参考白内障图像对应的修复图像可以确定第二判别结果(参见图3b)。
[0055]
在一些示例中,第一判别结果可以为判别器14输出的针对清晰眼底图像的判别结果。具体地,可以利用判别器14将参考白内障图像和对应的清晰眼底图像作为输入以输出针对清晰眼底图像的判别结果。在一些示例中,第一判别结果可以表示清晰眼底图像的真或假。
[0056]
在一些示例中,第二判别结果可以为判别器14输出的针对修复图像的判别结果。具体地,可以利用判别器14将参考白内障图像和对应的修复图像作为输入以输出针对修复图像的第二判别结果。在一些示例中,第二判别结果可以表示修复图像的真或假。
[0057]
另外,第一判别结果和第二判别结果可以为判别器14基于同一参考白内障图像而获得。具体地,参见图3b,可以利用判别器14对参考白内障图像和对应的清晰眼底图像进行
判别以获取第一判别结果,利用该判别器14对该参考白内障图像和对应的修复图像进行判别以获取第二判别结果。在这种情况下,由于第一判别结果和第二判别结果都是判别器14基于同一参考白内障图像而获得,在利用相应的损失优化修复模型1时能够对生成器12生成的修复图像进行约束,进而能够降低修复图像偏离清晰眼底图像的风险。
[0058]
在一些示例中,返回参考图2,在步骤s140中,可以基于由步骤s100获得的训练数据集、由步骤s120获得的第一判别结果和第二判别结果获取目标损失。
[0059]
在一些示例中,目标损失可以包括第一损失和第二损失。在一些示例中,目标损失还可以包括第三损失和第四损失。也即,目标损失可以包括第一损失、第二损失、第三损失和第四损失。在这种情况下,目标损失综合了多个损失,后续基于目标损失对修复模型1的训练进行约束,能够使修复模型1生成的修复图像从多个方面尽量接近清晰眼底图像,有利于提高修复效果。
[0060]
在一些示例中,第一损失可以由第一判别结果和第二判别结果确定。另外,第一损失用于表示判别器14的损失。
[0061]
在一些示例中,第一损失可以满足公式:
[0062]
l
cgan
(g,d)=e[logd(c',c)]+e[log(1-d(c',g(c')))],
[0063]
其中,l
cgan
(g,d)可以表示第一损失,g可以表示生成器12,d可以表示判别器14,c'可以表示参考白内障图像,c可以表示与参考白内障图像对应的清晰眼底图像,g(c')可以表示修复图像,d(c',c)可以表示第一判别结果,d(c',g(c'))可以表示第二判别结果,log()可以表示取对数,e[]可以表示数学期望。在这种情况下,通过第一损失能够对生成器12生成的修复图像进行约束,进而能够降低修复图像偏离清晰眼底图像的风险。
[0064]
在一些示例中,第二损失可以由修复图像与对应的清晰眼底图像之间像素的差异所确定。在一些示例中,第二损失可以为修复图像与对应的清晰眼底图像之间像素的像素距离。在一些示例中,第二损失可以为修复图像与对应的清晰眼底图像之间的像素l1损失。在这种情况下,通过连续优化修复模型1使得像素l1损失趋于最小化,从而能够约束修复图像与清晰眼底图像之间的像素距离。在一些示例中,第二损失可以满足公式:
[0065]
l1(g)=e[||c-g(c')||1],
[0066]
其中,l1(g)可以表示第二损失,c'可以表示参考白内障图像,c可以表示与参考白内障图像对应的清晰眼底图像,g(c')可以表示修复图像,||||1可以表示l1范数,e[]可以表示数学期望。
[0067]
在一些示例中,第三损失可以由基于卷积神经网络的特征提取器提取的修复图像与对应的清晰眼底图像之间的不同尺度的特征图的差异所确定(稍后描述)。具体地,可以将清晰眼底图像和修复图像输入特征提取器以分别提取针对修复图像的不同尺度的特征图以及针对清晰眼底图像的不同尺度的特征图,从而比较修复图像与对应的清晰眼底图像之间的不同尺度的特征图的差异。
[0068]
另外,特征提取器可以是预先训练好的。另外,不同尺度的特征图可以为特征提取器的不同尺度的卷积层的输出。不同尺度的特征图可以表征不同的图像信息(例如,血管信息和病变特征)。
[0069]
在一些示例中,特征提取器可以基于vgg网络。在一些示例中,vgg网络可以为vgg16网络或vgg19网络。在一些示例中,特征提取器也可以基于resnet网络。
[0070]
在一些示例中,可以根据感兴趣的图像信息选择相应的尺度的特征图用于确定第三损失。在这种情况下,在基于第三损失优化修复模型1时,能够降低其他不相关信息(例如,图像上的一些噪点)的干扰,有利于提取感兴趣的图像信息。
[0071]
在一些示例中,可以通过比较相同尺度的卷积层的输出以确定第三损失。在一些示例中,第三损失可以满足以下公式:
[0072][0073]
其中,l
per
(g)可以表示第三损失,g可以表示生成器12,c可以表示清晰眼底图像,c'可以表示参考白内障图像,g(c')可以表示修复图像,φi可以表示特征提取器的第i层卷积层,φi(c)可以表示第i层卷积层输出的针对清晰眼底图像的特征图,φi(g(c'))可以表示第i层卷积层输出的针对修复图像的特征图,mi可以表示特征提取器的第i层特征图的像素点的个数,||||1可以表示l1范数,n可以表示特征提取器的卷积层的层数。
[0074]
在一些示例中,第四损失可以由修复图像与对应的清晰眼底图像之间的结构相似性所确定。
[0075]
在一些示例中,第四损失可以从全局结构分布的层面约束修复图像和清晰眼底图像之间的分布距离(例如,欧氏距离)。在这种情况下,通过对修复图像和清晰眼底图像之间的结构进行约束,能够有利于修复图像中保留输入参考白内障图像的结构和病理特征。
[0076]
在一些示例中,可以基于滑窗获取第四损失。在一些示例中,可以利用预设大小的滑窗以预设步长分别在修复图像和清晰眼底图像上滑动以确定各个窗口内的像素点,通过计算多个窗口中各个窗口内的像素值的统计值(例如,标准差或平均值等)以获取第四损失。在一些示例中,第四损失可以满足公式:
[0077][0078]
其中,l
str
(g)可以表示第四损失,g可以表示生成器12,k可以表示滑窗的个数,可以表示修复图像中第i个滑窗中像素值的标准差,可以表示清晰眼底图像中第i个滑窗中像素值的标准差,可以表示修复图像与清晰眼底图像之间针对第i个滑窗的协方差,m可以表示常数,e[]可以表示数学期望。在一些示例中,m可以表示不为0的常数。由此,能够使得式(1)的分母不为0。
[0079]
图4是示出了本公开示例所涉及的获取第五损失的流程图。
[0080]
在一些示例中,目标损失还可以包括第五损失。第五损失可以由修复图像的局部区域与全局区域之间的光照强度的差异所确定。另外,修复图像的全局区域的尺寸可以大于局部区域的尺寸。在一些示例中,修复图像的全局区域可以表示整幅修复图像的区域。在一些示例中,修复图像的局部区域可以表示修复图像的部分区域。
[0081]
在一些示例中,可以基于修复图像获取多个图像块,各个图像块具有对应的平均光照强度,基于多个图像块对应的多个平均光照强度和修复图像的全局平均强度获取第五损失。为此,本公开示例还提供了一种获取第五损失的方法。具体地,参见图4,获取第五损
失的方法可以包括计算修复图像的全局区域的平均光照强度而获得全局平均强度(步骤s210)、将修复图像分为多个图像块(步骤s220)、通过计算每个图像块的平均光照强度获得光照矩阵(步骤s230)、基于光照矩阵与全局平均强度之间的差值获得光照差异性矩阵(步骤s240)、基于光照差异性矩阵获得光照分布矩阵(步骤s250)、以及基于光照分布矩阵获得第五损失(步骤s260)。
[0082]
在一些示例中,在步骤s210中,可以计算修复图像的全局区域的平均光照强度而获得全局平均强度。在一些示例中,可以遍历修复图像中的像素点并获取像素点的光照强度,对像素点的光照强度进行求平均以获取全局平均强度。在一些示例中,像素点的光照强度可以为像素点的像素值。
[0083]
在一些示例中,在步骤s220中,可以将修复图像分为多个图像块。在另一些示例中,多个图像块之间的区域可以相互独立。在另一些示例中,多个图像块之间的区域可以重叠。由此,能够提高重叠区域对修复图像的光照强度的影响。在一些示例中,多个图像块的大小可以相同。在另一些示例中,多个图像块的大小也可以不同。
[0084]
在一些示例中,在步骤s230中,可以通过计算每个图像块的平均光照强度获得光照矩阵。在一些示例中,可以对每个图像块中像素点的光照强度求平均以获取每个图像块的平均光照强度。在一些示例中,可以将修复图像中相应位置的图像块的平均光照强度作为光照矩阵中对应位置的元素值。由此,能够确定光照矩阵。在这种情况下,通过光照矩阵能够反映修复图像的局部区域的光照强度信息。
[0085]
在一些示例中,在步骤s240中,可以基于光照矩阵与全局平均强度之间的差值获得光照差异性矩阵。在一些示例中,光照差异性矩阵可以由光照矩阵减去全局平均强度而获得。也即,可以将光照差异性矩阵中的每个元素值减去全局平均强度后作为光照差异性矩阵。
[0086]
在一些示例中,在步骤s250中,可以基于光照差异性矩阵获得光照分布矩阵。在一些示例中,可以调整光照差异性矩阵以获得与修复图像的大小相匹配的光照分布矩阵。具体地,可以根据修复图像的大小调整光照差异性矩阵的大小,从而使得光照差异性矩阵的大小能够与修复图像的大小相匹配。在一些示例中,可以通过插值的方式(例如,双三插值的方式)调整光照差异性矩阵的大小。
[0087]
在一些示例中,在步骤s260中,可以基于光照分布矩阵获得第五损失。在一些示例中,可以通过计算光照分布矩阵的平均绝对值而获得第五损失。在一些示例中,可以将光照分布矩阵的平均绝对值作为第五损失。另外,平均绝对值可以为对光照分布矩阵中的元素值求绝对值后的平均值。
[0088]
在一些示例中,第五损失可以满足公式:
[0089][0090]
其中,l
ill
(g)可以表示第五损失,g可以表示生成器12,g(c')可以表示修复图像,e
global
[g(c')]可以表示修复图像的全局平均强度,可以表示由修复图像的多个p
×
p大小的图像块获得的光照矩阵,up{}可以表示调整光照差异性矩阵的大小的函数(即经由up{}可以获得光照分布矩阵),e
gobal
[||]可以表示光照分布矩阵的平均绝对值。另外,如上所述,光照差异性矩阵可以由光照矩阵减去全局平均强度而获得。另外,p可以表示
图像块的边长。
[0091]
在一些示例中,第五损失可以与修复图像的局部区域与全局区域之间的光照强度的差异性呈正相关。在这种情况下,能够平衡修复图像的局部区域与全局区域之间的光照强度的差异,进而能够改善修复图像过暗的问题。
[0092]
如上所述,目标损失可以包括第一损失、第二损失、第三损失和第四损失。在一些示例中,第一损失可以具有第一权重,第二损失可以具有第二权重,第三损失可以具有第三权重,第四损失可以具有第四权重。如上所述,目标损失还可以包括第五损失,第五损失可以具有第五权重。
[0093]
在一些示例中,第三权重可以大于第二权重。在一些示例中,第二权重可以等于第四权重。在一些示例中,第四权重可以大于第五权重。
[0094]
在一些示例中,第五权重可以大于第一权重。在一些示例中,第一权重可以为常数1。
[0095]
以目标损失可以包括第一损失、第二损失、第三损失和第四损失为例,第三权重可以大于第二权重,第二权重可以等于第四权重,第四权重可以大于第五权重,且第五权重可以大于第一权重。在这种情况下,通过设置权重的大小,能够提高第三损失对修复模型1的影响,并平衡第二损失和第四损失对修复模型1的影响,从而在提高判别器14的判别结果影响的基础上,更有利于提取感兴趣的图像信息。
[0096]
以目标损失还包括第五损失为例,目标损失可以满足以下公式:
[0097]
lg=λ1l
cgan
+λ2l1+λ3l
per
+λ4l
str
+λ5l
ill
,
[0098]
其中,lg可以表示目标损失,l
cgan
可以表示第一损失,l1可以表示第二损失,l
per
可以表示第三损失,l
str
可以表示第四损失,l
ill
可以表示第五损失,λ1可以表示第一权重,λ2可以表示第二权重,λ3可以表示第三权重,λ4可以表示第四权重,λ5可以表示第五权重。优选地,在该目标损失中,λ3》λ2,λ2=λ4,λ4》λ5,λ5》λ1,λ1=1。
[0099]
在一些示例中,返回参考图2,在步骤s160中,可以基于目标损失对修复模型1进行训练以获得训练后的修复模型1。在实际应用中,可以利用训练后的修复模型1中的生成器12对白内障图像进行修复以获得修复后的白内障图像。
[0100]
具体地,由于目标损失包括多个不同的损失函数,从而能够从多个方面对修复模型1的训练进行约束,进而能够确定修复模型1训练的优化方向。例如,通过第一损失能够约束生成器12生成的修复图像,使得修复图像不至于过分偏离清晰眼底图像。通过第二损失能够约束修复图像与对应的清晰眼底图像之间的像素距离。通过第三损失能够约束修复图像与对应的清晰眼底图像之间的不同尺度的特征图的差异。通过第四损失能够约束修复图像与对应的清晰眼底图像之间的结构相似性。通过第五损失能够约束修复图像的局部区域与全局区域之间的光照强度的差异。
[0101]
在一些示例中,在修复模型1的训练中,可以采用链式法则和梯度下降法对修复模型1进行逆向传播训练以优化修复模型1,进而获得训练后的修复模型1。
[0102]
图5是示出了本公开示例所涉及的生成参考白内障图像的流程图。
[0103]
如上所述,参考白内障图像可以为基于清晰眼底图像模拟而获得的图像。在一些示例中,参考白内障图像由对应的清晰眼底图像进行光线干扰和模糊处理而获得。在一些示例中,光线干扰可以包括对比度干扰、亮度干扰和饱和度干扰中的至少一种。在一些示例
中,模糊处理可以包括高斯模糊和随机高斯噪声中的至少一种。由此,能够获得与真实白内障眼底图像较接近的参考白内障图像。
[0104]
为此,本公开示例还提供了一种示例性的生成参考白内障图像的方法。具体地,参见图5,生成参考白内障图像的方法可以包括获取清晰眼底图像(步骤s310)、以及对清晰眼底图像进行光线干扰和模糊处理(步骤s320)。
[0105]
在一些示例中,在步骤s310中,可以通过眼底照相机2获取受试者的清晰眼底图像。
[0106]
在一些示例中,在步骤s320中,可以对清晰眼底图像进行光线干扰和模糊处理而生成参考白内障图像。在一些示例中,可以结合白内障病理特征和眼底彩照的退化机制对清晰眼底图像进行光线干扰和模糊处理。在这种情况下,使得参考白内障图像能够具有一般白内障图像的特征(例如,模糊、浑浊和过暗等)。由此,能够提高参考白内障图像的普遍性和适用性。另外,通过清晰眼底图像来模拟与清晰眼底图像对应的参考白内障图像,能够获取大量具有成对对应关系的训练数据,进而提高获取训练数据的便捷性。
[0107]
在一些示例中,光线干扰可以包括对比度干扰、亮度干扰和饱和度干扰中的至少一种。在一些示例中,光线干扰还可以包括不均匀照明。在这种情况下,通过对清晰眼底图像进行光线干扰能够模拟白内障的浑浊(例如,晶状体的浑浊)。
[0108]
在一些示例中,模糊处理可以包括高斯模糊和随机高斯噪声中的至少一种。在这种情况下,通过高斯模糊能够模拟例如眼球引动、颤动或散焦引起的眼底图像的成像模糊。
[0109]
在一些示例中,可以先对清晰眼底图像进行光线干扰,再进行模糊处理以生成参考白内障图像。但本公开的示例并不限于此,在另一些示例中,可以先对清晰眼底图像进行模糊处理,再进行光线干扰以生成参考白内障图像。
[0110]
在一些示例中,一种示例性的生成参考白内障图像的公式可以参见公式(2):
[0111]
c'=clip(α(j
·gl
(r
l
,σ
l
)+c)+β;s)+c
·
gb(rb,σb)+n,
……
式(2)
[0112]
其中,c'可以表示参考白内障图像,c可以表示与参考白内障图像对应的清晰眼底图像。
[0113]
另外,α、β和s可以分别表示对比度函数、亮度函数、和饱和度函数。在一些示例中,对比度函数调整的对比度、亮度函数调整的亮度、以及饱和度函数调整的饱和度可以随机取值。例如,对比度可以在[0.9,1.3]范围内随机取值,亮度可以在[0.9,1.0]范围内随机取值,饱和度可以在[0.9,1.3]范围内随机取值。
[0114]
另外,clip(;s)可以表示clipping函数。在一些示例中,clipping函数可以在饱和度中用于模拟图像全局退化。
[0115]
另外,g
l
(r
l
,σ
l
)和gb(rb,σb)可以表示高斯滤波。在一些示例中,高斯模糊可以利用高斯滤波器完成。例如,高斯模糊可以通过高斯低通滤波获得。
[0116]
在一些示例中,r
l
和rb可以表示高斯模糊的模糊半径。在一些示例中,r
l
可以在集合{1,3,5,7}中任取一个值。在一些示例中,rb可以在集合{1,3,5,7}中任取一个值。
[0117]
在一些示例中,σ
l
和σb可以表示空间常数。在一些示例中,σ
l
可以在[10,30]范围内随机取值。在一些示例中,σb可以在[10,30]范围内随机取值。
[0118]
另外,n可以表示随机高斯噪声。在一些示例中,随机高斯噪声可以是瞬时值的分布为高斯分布的随机噪声。例如,随机高斯噪声可以是高斯白噪声。
[0119]
另外,j可以是一个用于模拟不均光照的传输照明面板(illumination panel)。如上所述,j可以为一个矩阵。在一些示例中,矩阵j的半径r
l
可以满足公式:其中,j
x,y
可以表示矩阵j上坐标为(x,y)的元素与矩阵j的中心的距离,(a,b)可以表示矩阵j的中心,r
l
可以表示矩阵j的半径。在一些示例中,a和b可以随机取整数值。例如,a的取值可以满足a∈[0.2w,0.5w],b的取值可以满足b∈[0.2h,0.5h]。其中,w可以表示清晰眼底图像的宽度,h可以表示清晰眼底图像的高度。
[0120]
图6是示出了本公开示例所涉及的获取第三损失的流程图。
[0121]
如上所述,第三损失可以由基于卷积神经网络的特征提取器提取的修复图像与对应的清晰眼底图像之间的不同尺度的特征图的差异所确定。为此,本公开示例还提供了一种示例性的获取第三损失的方法。具体地,参见图6,获取第三损失的方法可以包括将清晰眼底图像和修复图像分别输入特征提取器(步骤s410)、特征提取器分别输出针对清晰眼底图像的特征图和针对修复图像的特征图(步骤s420)、以及基于清晰眼底图像和修复图像对应尺度的特征图之间的差异获取第三损失(步骤s430)。
[0122]
在一些示例中,在步骤s410中,可以将清晰眼底图像和修复图像分别输入特征提取器。如上所述,可以利用生成器12将参考白内障图像作为输入以生成对应的修复图像。
[0123]
在一些示例中,特征提取器可以具有依次连接的多个卷积层。具体地,在多个卷积层中,上一层卷积层的输出可以作为下一层卷积层的输入。以三个卷积层为例,第一层卷积层的输出可以作为第二层卷积层的输入,第二层卷积层的输出可以作为第三层卷积层的输入。
[0124]
在一些示例中,在步骤s420中,可以通过特征提取器分别输出针对清晰眼底图像的多个特征图(以下简称为清晰特征图集)和针对修复图像的特征图(以下简称为修复特征图集)。如上所述,不同尺度的特征图可以为特征提取器的不同尺度的卷积层输出的特征图。也即,清晰特征图集可以包括针对清晰眼底图像的多个基于不同尺度的卷积层获取的特征图,修复特征图集可以包括针对修复图像的多个基于不同尺度的卷积层获取的特征图。
[0125]
在一些示例中,在步骤s430中,可以基于清晰眼底图像和修复图像对应尺度的特征图之间的差异获取第三损失。具体地,可以通过计算清晰特征图集与修复特征图集之间相同尺度的卷积层的特征图的差异而获取第三损失。例如,特征图的差异可以为特征图中像素的差异。
[0126]
以三个尺度的特征图为例,清晰特征图集和修复特征图集可以包括三个尺度的特征图。三个尺度可以为第一尺度、第二尺度和第三尺度。通过计算清晰特征图集与修复特征图集中第一尺度的两个特征图之间像素的差异而获得针对第一尺度的第一差异。同理,可以获得针对第二尺度的第二差异以及针对第三尺度的第三差异。通过对第一差异、第二差异以及第三差异求平均值而获得第三损失。
[0127]
图7是示出了本公开示例所涉及的基于u-net的生成器12的框图。
[0128]
如上所述,生成器12可以接收参考白内障图像并生成修复图像。在一些示例中,输入生成器12的参考白内障图像可以通过多次下采样获取不同尺度的第一特征图(feature map)。这里尺度可以指第一特征图的尺寸大小,第一特征图的大小可以为尺寸大小乘以通
道数。另外,每个尺度的第一特征图的通道数可以与生成器12的网络层的深度呈正相关。也即,生成器12的网络层数越深,对应尺度的第一特征图的通道数就越大(也即,第一特征图的数量就越多)。由此,能够提取更多的语义信息。
[0129]
在一些示例中,不同尺度的第一特征图可以与相应的经上采样获取的第二特征图进行通道融合而生成修复图像。在一些示例中,通道融合后获得的融合特征图可以作为对应尺度的上采样的输入,进而生成修复图像。在这种情况下,能够将来自下采样的不同尺度的特征细节传递到对应尺度的上采样中以利用更多特征细节来还原修复图像的细节,从而使得修复图像更接近清晰眼底图像。
[0130]
在一些示例中,用于通道融合的不同尺度的第一特征图可以由接收融合特征图的上采样层的通道数确定。具体地,可以将该上采样层的通道数作为标准通道数,进而将通道数不大于该标准通道数的第一特征图与经上采样获取的第二特征图进行通道融合后输入该上采样层。在这种情况下,通过将下采样中小通道数或者相同通道数的特征图在上采样中进行融合,能够在生成修复图像的过程中提供一些特征细节(例如结构、噪声等),有利于更好地还原在连续下采样中丢失的特征细节。
[0131]
在一些示例中,可以将全部通道数中不大于标准通道数的第一特征图用于通道融合。在另一些示例中,可以选择部分通道数不大于标准通道数的第一特征图用于通道融合。
[0132]
在一些示例中,生成器12可以包括编码模块和解码模块。编码模块可以具有多个下采样层,解码模块可以具有多个上采样层。
[0133]
在一些示例中,编码模块可以用于对输入生成器12的参考白内障图像进行多次下采样以获取上述不同尺度的第一特征图。
[0134]
在一些示例中,解码模块的输入可以包括经由尺度归一化的不同尺度的第一特征图、以及对应解码模块中前一个上采样层输出的第二特征图。
[0135]
在一些示例中,多个下采样层与多个上采样层之间可以采用全尺度的跳跃连接。具体地,可以通过对不同尺度的第一特征图进行尺度归一化以实现多个下采样层与多个上采样层之间的全尺度的跳跃连接。由此,使得不同尺度的第一特征图能够传递到对应尺度的上采样层中。
[0136]
为了更好地描述生成器12,本公开的示例还提供了一种示例性的生成器12的网络结构,该生成器12可以基于u-net的网络结构。具体地,参见图7,基于u-net的生成器12可以使用四层结构(也即四层结构的生成器),需要说明的是,四层结构并不表示对本公开涉及的生成器12的限制,优选地,基于u-net的生成器12可以使用八层结构。
[0137]
在一些示例中,生成器12可以包括具有四个下采样层的编码模块和具有三个上采样层的解码模块(参见图7)。例如,四个下采样层可以分别为下采样层e1、下采样层e2、下采样层e3以及下采样层e4,三个上采样层可以分别为上采样层d1、上采样层d2以及上采样层d3。
[0138]
在一些示例中,下采样层e1的输入可以是例如256
×
256
×
3的参考白内障图像(其中,256
×
256可以表示图像的尺寸大小,3可以表示通道数)。下采样层e1的输出可以是128
×
128
×
64的第一特征图(其中,128
×
128可以表示图像的尺寸大小,64可以表示通道数)。下采样层e2的输入可以是下采样层e1的输出。下采样层e2的输出可以是64
×
64
×
128的第一特征图。下采样层e3的输入可以是下采样层e2的输出。下采样层e3的输出可以是32
×
32
×
256的第一特征图。下采样层e4的输入可以是下采样层e3的输出。下采样层e4的输出可以是16
×
16
×
512的第一特征图。
[0139]
另外,上述四个下采样层与三个上采样层之间可以采用全尺度的跳跃连接。
[0140]
在一些示例中,下采样层e1的输出、下采样层e2的输出、下采样层e3的输出以及下采样层e4的输出可以经尺度归一化后作为上采样层d3的输入,通过通道融合传递到上采样层d3(参见图7)。
[0141]
具体地,以上采样层d3为例,若上采样层d3的输入的大小为32
×
32
×
256(即特征图的尺寸大小为32
×
32,通道数为256),则标准通道数可以为256。尺度归一化的过程可以为:通道数不大于标准通道数的第一特征图可以为下采样层e1、下采样层e2和下采样层e3的输出,对通道数小于标准通道数的下采样层e1和下采样层e2输出的第一特征图可以分别做下采样以分别获得第一组特征图和第二组特征图,对通道数等于标准通道数的下采样层e3输出的第一特征图可以直接作为第三组特征图,对下采样层e4输出的第一特征图可以做上采样以获得第二特征图并作为第四组特征图,由此得到四组特征图(每组特征图的大小可以为32
×
32
×
256)经通道融合后再传递到上采样层d3,作为上采样层d3的输入。
[0142]
同理,可以获得上采样层d2和上采样层d1的输入。在这种情况下,通过在四个下采样层与三个上采样层之间采用全尺度的跳跃连接,能够将来自小于标准通道数和等于标准通道数的第一特征图传递到该标准通道数对应的上采样层中。
[0143]
在一些示例中,修复图像可以由上采样层d1输出。在这种情况下,通过结合不同尺度的第一特征图再通过解码模块进行多次上采样,能够还原修复图像的特征细节,从而能够使得生成器12生成的修复图像更接近清晰眼底图像。
[0144]
如上所述,基于u-net的生成器12可以使用八层结构(也即八层结构的生成器),该八层结构的生成器12生成修复图像的过程与上述四层结构的生成器12相同。在这种情况下,通过增加了网络结构的数量,能够结合更多不同尺度的第一特征图进行上采样,从而能够最大限度地还原修复图像的特征细节。
[0145]
以下,结合附图详细描述本公开涉及的白内障眼底图像的修复模型1的训练装置3。训练装置3还可以称为模型训练装置。本公开涉及的训练装置3可以用于实施上述的训练方法。需要说明的是,除非特意说明,针对上述的训练方法的相关描述同样适用于训练装置3。
[0146]
图8是示出了本公开示例所涉及的训练装置3的框图。
[0147]
如图8所示,在一些示例中,训练装置3可以包括构建模块32、生成模块34、判别模块36以及优化模块38。
[0148]
在一些示例中,构建模块32可以用于构建训练数据集。训练数据集可以包括清晰眼底图像以及与清晰眼底图像对应的参考白内障图像。在一些示例中,训练数据集可以包括基于多个受试者获取的多组清晰眼底图像以及对应的参考白内障图像。具体内容参见步骤s100中的相关描述。
[0149]
在一些示例中,生成模块34可以用于生成修复图像。具体地,生成模块34可以利用生成器12将训练数据集中的参考白内障图像作为输入以通过多次下采样获取不同尺度的第一特征图,并将不同尺度的第一特征图与相应的经上采样获取的第二特征图进行融合,进而生成修复图像。具体内容参见步骤s120中的相关描述。
[0150]
在一些示例中,判别模块36可以用于输出针对待判别图像的判别结果。具体地,判别模块36可以利用判别器14将参考白内障图像和对应的清晰眼底图像作为输入以输出针对清晰眼底图像的第一判别结果,并将参考白内障图像和对应的修复图像作为输入以输出针对修复图像的第二判别结果。具体内容参见步骤s120中的相关描述。
[0151]
在一些示例中,优化模块38可以基于训练数据集、第一判别结果和第二判别结果获取目标损失,并基于目标损失对修复模型1进行训练以优化修复模型1,进而获得用于修复白内障眼底图像的训练后的生成器12。在一些示例中,目标损失可以包括第一损失、第二损失、第三损失和第四损失。在一些示例中,第一损失可以由第一判别结果和第二判别结果确定。在一些示例中,第二损失可以由修复图像与对应的清晰眼底图像之间像素的差异所确定。在一些示例中,第三损失可以由基于卷积神经网络的特征提取器提取的修复图像与对应的清晰眼底图像之间的不同尺度的特征图的差异所确定。在一些示例中,第四损失可以由修复图像与对应的清晰眼底图像之间的结构相似性所确定。具体内容参见步骤s140和步骤s160中的相关描述。
[0152]
本公开还提供一种白内障眼底图像的修复方法(也可以简称为修复方法)。具体地,可以利用本公开所涉及的训练方法获得的修复模型1对白内障眼底图像进行修复,从而能够获得与白内障眼底图像对应的修复图像。例如,可以获取白内障眼底图像并输入训练后的修复模型1,修复模型1可以输出修复后的白内障眼底图像。在这种情况下,基于修复模型1获得针对白内障眼底图像的修复图像,能够提高修复图像的细节。
[0153]
为验证本公开示例所涉及的修复模型1对白内障眼底图像的修复效果,本公开还提供了经过白内障手术获得的手术后的白内障眼底图像和利用训练后的修复模型1对白内障眼底图像进行修复获得的修复后的白内障眼底图像。
[0154]
图9a是示出了本公开示例所涉及的白内障眼底图像。图9b是示出了本公开示例所涉及的手术后的白内障眼底图像。图9c是示出了本公开示例所涉及的修复后的白内障眼底图像。
[0155]
在一些示例中,参见图9a,白内障眼底图像的图像质量较低。具体地,白内障眼底图像具有模糊、浑浊和光照过暗等特点。在这种情况下,容易覆盖眼底图像中的一些血管信息或病变特征,从而降低白内障图像的可读性和评估性。
[0156]
在一些示例中,参见图9b,经过白内障手术获得的手术后的白内障眼底图像具有较高的图像质量,能够有效降低因模糊、浑浊和光照过暗对眼底图像造成的干扰。
[0157]
在一些示例中,参见图9c,利用训练后的修复模型1对白内障眼底图像进行修复,获得的修复后的白内障眼底图像可以从多个方面(例如,视杯、血管信息和结构相似性等)最大限度地接近手术后的白内障眼底图像。由此,能够提高白内障眼底图像的可读性和评估性。在这种情况下,通过修复后的白内障眼底图像,能够有利于在白内障手术前对白内障患者的眼底图像中的异常特征进行观察和判断。
[0158]
本公开还提供一种电子设备,包括存储有程序的存储器以及与存储器耦合的处理器。其中,处理器配置为当程序由处理器运行时实现上述训练方法或修复方法中的一个或多个步骤。
[0159]
本公开还提供一种非暂态计算机可读存储介质,该非暂态计算机可读存储介质可以存储有至少一个指令,至少一个指令被处理器执行时可以实现上述训练方法或修复方法
中的一个或多个步骤。
[0160]
本公开的白内障眼底图像的修复方法、修复模型1的训练方法及装置,构建具有成对关系的训练数据集来训练包括生成器12和判别器14的修复模型1。在训练中,融合多次下采样获取的不同尺度的特征图以及相应上采样的特征图,能够将来自下采样的不同尺度的特征细节传递到对应尺度的上采样中以利用更多特征细节来还原修复图像的细节,使得修复图像更接近清晰眼底图像。另外,综合多个损失对修复模型1的训练进行约束,能够使修复模型1生成的修复图像从多个方面尽量接近清晰眼底图像,有利于提高修复效果。另外,通过修复图像与对应的清晰眼底图像之间的不同尺度的特征图的差异优化修复模型1,能够使修复图像与对应的清晰眼底图像之间差异的评估更精准,有利于提取一些感兴趣的图像信息。另外,由修复图像与对应的清晰眼底图像之间的结构相似性优化修复模型1,能够对修复图像和清晰眼底图像之间的结构进行约束。
[0161]
虽然以上结合附图和示例对本公开进行了具体说明,但是可以理解,上述说明不以任何形式限制本公开。本领域技术人员在不偏离本公开的实质精神和范围的情况下可以根据需要对本公开进行变形和变化,这些变形和变化均落入本公开的范围内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1