一种融合用户埋点行为信息的欺诈用户识别算法框架的制作方法
1.本发明涉及信贷反欺诈领域,特别涉及一种融合了埋点行为序列的特征工程算法。
背景技术:
2.信贷反欺诈系统是指通过收集用户的各种行为表现,申请信息,评估用户是否为欺诈用户的一整套系统。目前已经广泛应用在线上线下的金融支付风控体系中。
3.反欺诈系统中的概率预估指的是根据用户的属性、历史行为、物料的属性等信息判断用户未来是否是欺诈用户。当系统将欺诈概率较高的用户识别出后,会交给策略信审通过电话等方式做二次核验,确认用户的真实性。
4.埋点行为序列信息指的是用户在客户端申请借贷时,在一个sessionid内时间序列上的一连串行为,通常由所在页面+点击按钮+停留时长三要素组合;
5.用户的埋点序列行为作为对于识别欺诈用户行为能起到一定的识别作用。比如欺诈用户可能批量输入地址信息,或者操作流程全程没有任何跳转停顿,或者对于团伙欺诈可能存在短期内同一个ip或者同一个时段有很多人有着相同的行为序列信息,就存在团伙欺诈的可能性;
6.传统的序列行为特征工程方法是按照过去xx时间在xx页面的点击次数,停留时长等聚合统计的方式做衍生,这种方法可解释性强,特征定义直观,但是缺点则是缺乏对埋点行为前后关系的衍生;二是统计方法相对宽泛,容易出现特征相似性高导致最终特征预测效果差;
7.所以如何用数据建模的方法量化这类行为信息,又能比传统方法效果更好是本次发明的出发点。
技术实现要素:
8.本发明要解决的技术问题是克服现有技术的缺陷,提供一种融合用户埋点行为信息的欺诈用户识别算法框架,更精准的识别用户欺诈意图;提出了基于随机游走+词向量的方法衍生行为特征,既丰富了行为的多样性又能刻画序列的前后信息。
9.本发明提供了如下的技术方案:
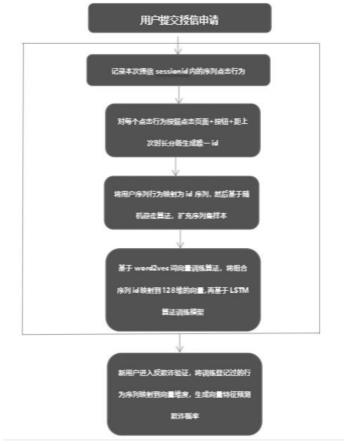
10.本发明提供一种融合用户埋点行为信息的欺诈用户识别算法框架,包括以下步骤:
11.(1)记录用户申请授信前一小时内客户端的点击行为及停留时长,生成页面(p)+点击按钮(b)+停留时长(t)三元组合,其中停留时长需要根据历史数据分析按照正常,太快,太慢三种情况分类,三元组合可以重复出现,比如点击后返回又再次点击,最终行为序列以用户退出授信流程或者提交申请为截止标志。同时记入用户特征信息(如年龄、性别、地域等)、申请时段(几点,星期几等);
12.(2)将用户行为数据转换成《p1b1t1,p2b2t2....pnbntn》的三元序列文本形式,一
共n类三元组合;
13.(3)将每个用户行为序列都拆分成《p1b1t1,p2b2t2》...《p
n-1bn-1
t
n-1
,p
nbn
tn》的节点组合,最终统计训练数据中每个节点的出现频次;
14.(4)按照频次生成每个节点的转移概率,计算公式如下,分母求和项只计算出现过p1b1t1在上个节点的情况
[0015][0016]
从任意页面开始,限定步长为l,按照转移概率权重随机跳转到下一个节点,走完l个节点结束,模拟用户的随机行为,重复模拟m次,生成m条步长为l的用户行为三元序列;
[0017]
(5)利用word2vec算法将m条行为序列数据导入训练生成128维的embedding,通过该方法得到任意三元组合embedding表示,最终将用户行为序列对应的embedding做均值处理,生成128维的均值embedding作为用户行为序列的数值化表征,然后结合用户特征信息、申请时段等特征一起导入lightgbm模型训练,训练目标为是否存在欺诈一般按照首月逾期30+以上即为欺诈用户;
[0018]
(6)将三元组合的embedding映射保存,当新用户进入申请流程,将行为序列映射成三元组合,再匹配对应的embedding向量,最后将向量做均值,组合其他特征,带入训练好的模型计算欺诈概率。
[0019]
与现有技术相比,本发明的有益效果如下:
[0020]
1、本发明相比传统的rfm特征衍生方式,改用当下流行的词向量表征,可以在减少信息损失的同时更好表征序列行为;
[0021]
2、利用随机游走算法解决短期样本量不足的情况,从而生成更多的随机序列行为用于词向量的训练;
[0022]
3、对于序列行为信息中比较关注的时间间隔特征,将行为信息的组合从页面+按钮转换成页面+按钮+停留时长分级,从而更精准的区分正常用户和异常用户的区别即使两人在相同的页面相同的点击行为,但是停留时长不同。
附图说明
[0023]
附图用来提供对本发明的进一步理解,并且构成说明书的一部分,与本发明的实施例一起用于解释本发明,并不构成对本发明的限制。在附图中:
[0024]
图1是本发明的流程图。
具体实施方式
[0025]
以下结合附图对本发明的优选实施例进行说明,应当理解,此处所描述的优选实施例仅用于说明和解释本发明,并不用于限定本发明。其中附图中相同的标号全部指的是相同的部件。
[0026]
实施例1
[0027]
如图1,本发明提供一种融合用户埋点行为信息的欺诈用户识别算法框架,包括以下步骤:
[0028]
(1)记录用户申请授信前一小时内客户端的点击行为及停留时长,生成页面(p)+点击按钮(b)+停留时长(t)三元组合,其中停留时长需要根据历史数据分析按照正常,太快,太慢三种情况分类,三元组合可以重复出现,比如点击后返回又再次点击,最终行为序列以用户退出授信流程或者提交申请为截止标志。同时记入用户特征信息(如年龄、性别、地域等)、申请时段(几点,星期几等);
[0029]
(2)将用户行为数据转换成《p1b1t1,p2b2t2....pnbntn》的三元序列文本形式,一共n类三元组合;
[0030]
(3)将每个用户行为序列都拆分成《p1b1t1,p2b2t2》...《p
n-1bn-1
t
n-1
,p
nbn
tn》的节点组合,最终统计训练数据中每个节点的出现频次;
[0031]
(4)按照频次生成每个节点的转移概率,计算公式如下,分母求和项只计算出现过p1b1t1在上个节点的情况
[0032][0033]
从任意页面开始,限定步长为l,按照转移概率权重随机跳转到下一个节点,走完l个节点结束,模拟用户的随机行为,重复模拟m次,生成m条步长为l的用户行为三元序列;
[0034]
(5)利用word2vec算法将m条行为序列数据导入训练生成128维的embedding,通过该方法得到任意三元组合embedding表示,最终将用户行为序列对应的embedding做均值处理,生成128维的均值embedding作为用户行为序列的数值化表征,然后结合用户特征信息、申请时段等特征一起导入lightgbm模型训练,训练目标为是否存在欺诈一般按照首月逾期30+以上即为欺诈用户;
[0035]
(6)将三元组合的embedding映射保存,当新用户进入申请流程,将行为序列映射成三元组合,再匹配对应的embedding向量,最后将向量做均值,组合其他特征,带入训练好的模型计算欺诈概率。
[0036]
最后应说明的是:以上所述仅为本发明的优选实施例而已,并不用于限制本发明,尽管参照前述实施例对本发明进行了详细的说明,对于本领域的技术人员来说,其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1