一种数据处理方法、装置及设备
本发明实施例涉及数据处理领域,尤其涉及一种数据处理方法、装置及设备。
背景技术:
1、随着信息技术的发展,人们的日常生活和工作中充斥着大量且多样的数据,这些数据中还包括以文本、图片、音频以及视频之类的非结构化数据,所述非结构化数据是指数据排布结构不规则或者不完整,没有预定义的数据模型,不方便用数据库二维逻辑来表现的数据。由于非结构化数据本身具有表征语义的特征数据之间关联性较弱,使得对该数据进行语义特征提取相较于结构化信息难度更大。通常存在多种类非结构化数据混合的情况,例如,一件带有图片信息的非结构化数据文档,也为对非结构化数据信息进行核心内容提取增加了难度。
2、现阶段对于非结构化数据的语义特征提取,通常依赖于经过训练的数据处理模型。现阶段数据处理模型针对待处理的非结构化数据,采用整体识别后,再进行特征提取的方式进行语义特征提取。
3、但是,由于当前数据处理模型对于数据处理的类别较为单一,面对多种类非结构数据混合的情况,无法对全部种类的非结构数据进行识别处理,进而存在对语义特征抽取结果确实的可能,造成最终语义特征提取结果较实际偏差较大。
技术实现思路
1、本技术实施例提供了一种数据处理方法、装置及设备,以解决现有数据处理中应对多类型混合式非结构化数据处理结果不精确的问题。
2、第一方面,本技术实施例提供了一种数据处理方法,所述方法包括:
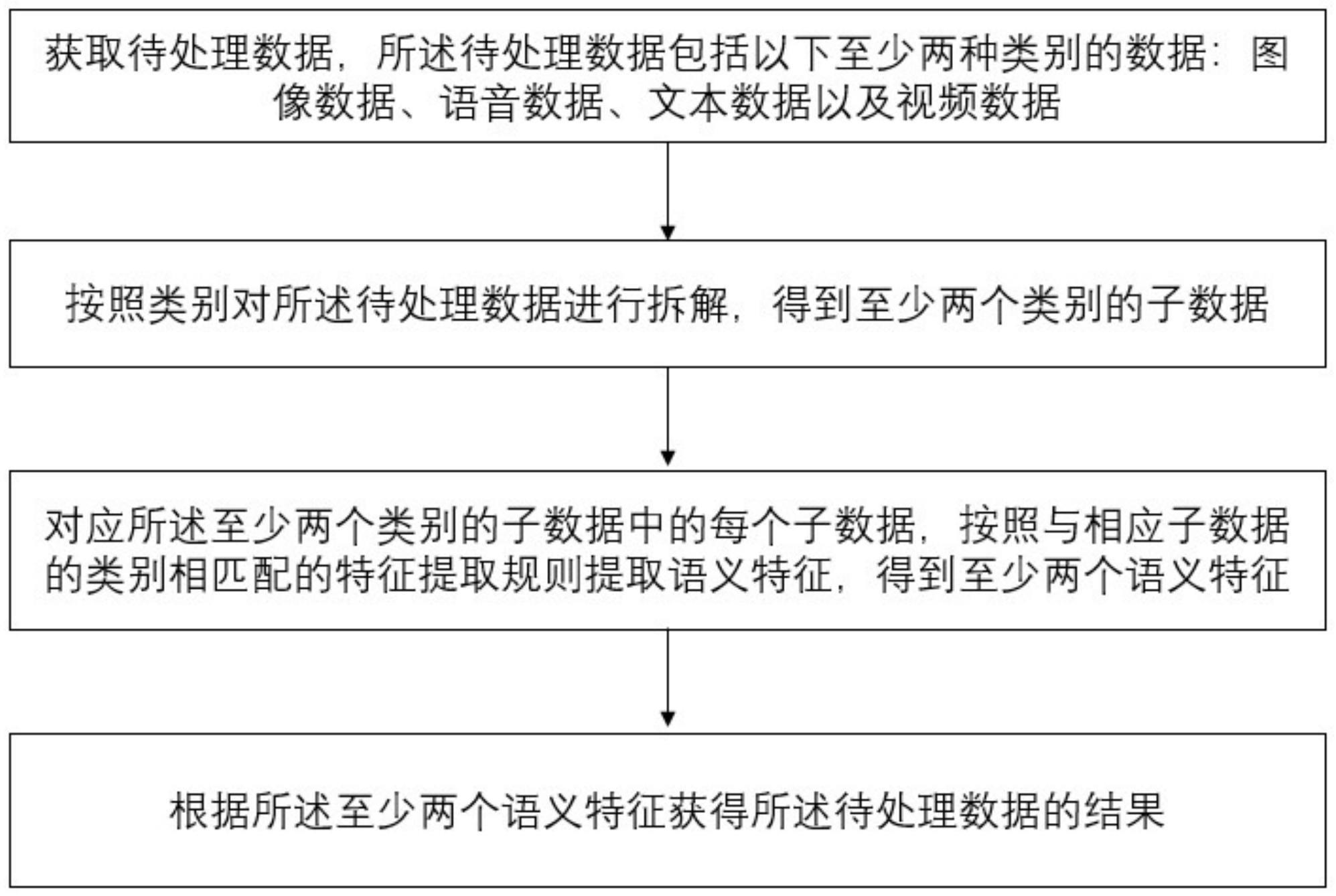
3、获取待处理数据,所述待处理数据包括以下至少两种类别的数据:图像数据、语音数据、文本数据以及视频数据;
4、按照类别对所述待处理数据进行拆解,得到至少两个类别的子数据;
5、对应所述至少两个类别的子数据中的每个子数据,按照与相应子数据的类别相匹配的特征提取规则提取语义特征,得到至少两个语义特征;
6、根据所述至少两个语义特征获得所述待处理数据的结果。
7、可选的,所述待处理数据由预设的非结构化数据库得到,所述非结构化数据库内部存储数据依据数据处理需求实时更新。这样,可以保证数据处理过程的可持续性。
8、可选的,在所述获取待处理数据之后,所述按照类别对所述待处理数据进行拆解之前,所述方法还包括:
9、对获取数据进行预处理,所述预处理内容包括:数据整合、数据去重以及数据编目等。这样,可以提高后续对待处理数据拆解工作的准确度。
10、一种可能的实施方式中,在所述按照类别对所述待处理非结构化数据拆解之前,还包括:
11、调用预设的数据解析模型对所述待处理数据进行内容识别,以得到所述待处理数据中包括的数据类别。这样,通过对待处理数据进行数据混合类别获取,以使后续拆解得到的每个子数据对应的拆解类别更为准确。
12、一种可能的实施方式中,所述按照与相应子数据的类别相匹配的特征提取规则提取语义特征,通过调用至少两个经过所述特征提取规则训练后的预设模型实现,所述预设模型包括:图像处理模型、语音处理模型、文本处理模型以及视频处理模型。这样,可以通过多种类的数据处理模型应对多类型混合式非结构化数据的处理。
13、可选的,所述图像处理模型、语音处理模型、文本处理模型以及视频处理模型均为独立并行关系。这样,在进行多类别非结构化数据处理中,彼此进程不会受到影响。
14、一种可能的实施方式中,用所述文本处理模型按照与相应子数据的类别相匹配的特征提取规则提取语义特征,包括:
15、获取目标文本,所述目标文本由对应文本类别的子数据得到:
16、对所述目标文本进行第一关键特征以及对应的元数据提取,得到第一提取结果,所述第一关键特征包括:事件文本信息;
17、调用预设的语义分析模型,对所述第一提取结果进行语义分析,得到第一关键特征语义分析结果;
18、对所述第一关键特征语义分析结果按照第一预设规则进行相似度比对,得到第一比对结果;
19、若所述第一比对结果大于或等于第一预设阈值,则所述第一比对结果对应的关键特征语义分析结果用于表征所述目标文本的语义特征。这样,可以实现对文本类别的数据的语义提取,实现对文本类非结构化数据的处理,并且对于目标文档对应的元数据进行的单独提取,可以用于为后续检索作业提供数据支撑。
20、可选的,在所述获取目标文本之前,还包括,依据处理需求构建所述目标文本的语义提取规则。这样,可以保证后续第一关键特征语义分析结果满足实际需求,进而提升所述目标文本语义提取结果的准确性。
21、一种可能的实施方式中,调用所述语音处理模型按照与相应子数据的类别相匹配的特征提取规则提取语义特征,包括:
22、获取目标语音,所述目标语音由对应语音类别的子数据得到;
23、调用预设的韵律模型以及预设的语音转文本模型将所述目标语音转化为对应的文本数据;
24、对所述语音进行第二关键特征以及对应的元数据提取,得到第二提取结果,所述第二关键特征包括:语音频率数据、语音振幅数据以及语音波型数据;
25、调用预设的语义分析模型,对所述第二提取结果进行语义分析,得到第二关键特征语义分析结果;
26、对所述第二关键特征语义分析结果按照第二预设规则进行相似度比对,得到第二比对结果;
27、若所述第二比对结果大于或等于第二预设阈值,则所述第二比对结果对应的关键特征语义分析结果用于表征所述目标语音的语义特征。这样,可以通过与语音转文本的方式实现对语音类别的数据的语义提取,实现对语音类非结构化数据的处理,并且对于目标语音对应的元数据进行的单独提取,可以用于为后续检索作业提供数据支撑。
28、可选的,所述目标语音包括:录音文件以及实时语音文件。
29、一种可能的实施方式中,调用所述图像处理模型按照与相应子数据的类别相匹配的特征提取规则提取语义特征,包括:
30、获取目标图像,所述目标图像由对应图像类别的子数据得到;
31、对所述目标图像进行第三关键特征以及对应的元数据提取,得到第三提取结果,所述第三关键特征包括:文字特征数据、目标特征数据以及人脸特征数据;
32、调用预设的语义分析模型,对所述第三提取结果进行语义分析,得到第三关键特征语义分析结果;
33、对所述第三关键特征语义分析结果按照第三预设规则进行相似度比对,得到第三比对结果;
34、若所述第三比对结果大于或等于第三预设阈值,则所述第三比对结果对应的关键特征语义分析结果用于表征所述目标图像的语义特征。这样,可以实现对图像类别的数据的语义提取,实现对图像类非结构化数据的处理,并且对于目标图像对应的元数据进行的单独提取,可以用于为后续检索作业提供数据支撑。
35、可选的,所述目标图像格式包括:jepg、tiff、raw、bmp、gif以及png。
36、可选的,所述图像元数据包括:exif、iptc、xmp、图像时间数据、图像像素数据以及图像位置数据。
37、可选的,所述文字特征数据包括:图像中的文字字体数据以及图像中的文字颜色数据等。
38、可选的,所述目标特征数据包括:图像中所识别的目标特征以及图像中未识别的目标特征。
39、可选的,所述人脸特征数据包括:图像中人脸检测数据。
40、一种可能的实施方式中,调用所述视频处理模型按照与相应子数据的类别相匹配的特征提取规则提取语义特征,包括:
41、获取目标视频,所述目标视频由对应视频类别的子数据得到;
42、对所述目标视频进行特征分割,得到视频流信息以及音频流信息;
43、对所述视频流信息进行第四关键特征以及对应的元数据提取,得到第四提取结果,所述第四关键特征包括:视频元数据、时间数据、场景数据、镜头数据、代表帧数据以及编目数据;
44、调用预设的语义分析模型,对所述第四提取结果进行语义分析,得到第四关键特征语义分析结果;
45、对第四关键特征语义分析结果按照第四预设规则进行相似度比对,得到第四比对结果;
46、若所述第四比对结果大于或等于第四预设阈值,则所述第四比对结果对应的关键特征语义分析结果用于表征所述目标视频的语义特征。这样,可以实现对视频类别的数据的语义提取,实现对视频类非结构化数据的处理,并且对于目标视频对应的元数据进行的单独提取,可以用于为后续检索作业提供数据支撑。
47、可选的,所述目标视频的格式包括:avi、rmvb、flv以及mp4。
48、可选的,所述对所述目标视频进行特征分割,针对所述音频流信息,使用预设的语音识别模型,得到相应的语义特征。
49、第二方面,本技术实施例提供了一种数据处理所述装置,包括:
50、获取模块,用于获取待处理数据,所述待处理数据包括以下至少两种类别的数据:图像数据、语音数据、文本数据以及视频数据;
51、拆解模块,用于按照类别对所述待处理数据进行拆解,得到至少两个类别的子数据;
52、特征提取模块,用于对应所述至少两个类别的子数据中的每个子数据,按照与相应子数据的类别相匹配的特征提取规则提取语义特征,得到至少两个语义特征;
53、处理模块,用于根据所述至少两个语义特征获得所述待处理数据的结果。
54、第三方面,本技术实施例还提供了一种电子设备,所诉电子设备包括:处理器、存储器、通信接口和通信总线,所述处理器、所述存储器和所述通信接口通过所述通信总线完成相互间的通信;
55、所述存储器用于存储可执行指令,所述可执行指令运行时使所述处理器执行第一方面或者第二方面任一可能的实施方式中的数据处理方法。
56、第四方面,本技术实施例还提供了一种计算机可读存储介质,所述存储介质中存储有可执行指令,所述可执行指令运行时使计算设备执行第一方面或者第二方面任一可能的实施方式中的数据处理方法。
57、本技术实施例提供了一种数据处理方法,本方案中,首先,获取待处理数据,所述待处理数据包括以下至少两种类别的数据:图像数据、语音数据、文本数据以及视频数据;然后,按照类别对所述待处理数据进行拆解,得到至少两个类别的子数据;对应所述至少两个类别的子数据中的每个子数据,按照与相应子数据的类别相匹配的特征提取规则提取语义特征,得到至少两个语义特征;最后,根据所述至少两个语义特征获得所述待处理数据的结果。可见,通过对含有多类别待处理数据进行拆解,得到拆解后的子数据,由于拆解后的子数据均为独立类别的数据,将其分别输入至预设的对应类别的数据处理模型中,最后汇总数据处理结果。这样,将处理对象由多类型混合的数据结构转变为单一类型的数据结构,可以降低数据处理难度,进而提高对数据处理结果的准确性。
- 还没有人留言评论。精彩留言会获得点赞!